Recognition: unknown
MARLIN: Multi-Agent Game-Theoretic Reinforcement Learning for Sustainable LLM Inference in Cloud Datacenters
Pith reviewed 2026-05-14 18:07 UTC · model grok-4.3
The pith
MARLIN uses multi-agent game-theoretic reinforcement learning to cut TTFT by 18 percent, carbon emissions by 33 percent, water usage by 43 percent, and energy costs by 11 percent for LLM inference in cloud datacenters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
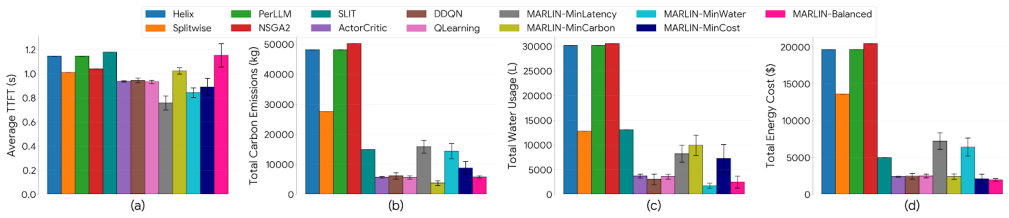
MARLIN is a multi-agent game-theoretic reinforcement learning framework that co-optimizes time-to-first-token, carbon emissions, water usage, and energy costs for LLM inference serving, delivering at least 18 percent lower TTFT, 33 percent lower carbon emissions, 43 percent lower water usage, and 11 percent lower energy costs than state-of-the-art frameworks.
What carries the argument
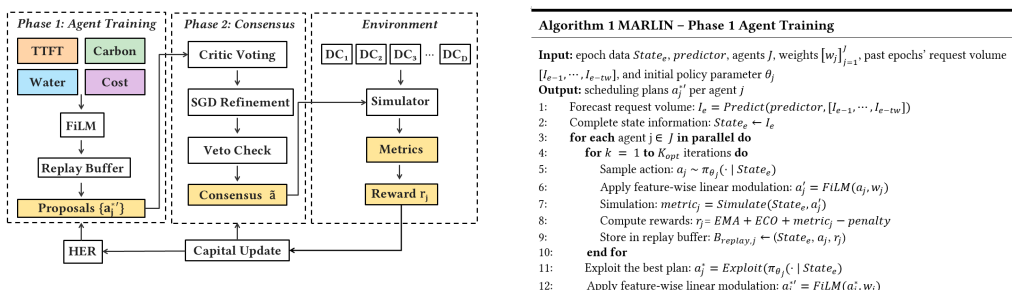
The multi-agent game-theoretic reinforcement learning system in which agents learn coordinated policies for request scheduling and resource allocation under joint sustainability objectives.
If this is right
- Cloud operators can reduce the environmental footprint of AI services while preserving or improving user-perceived response times.
- LLM deployment at larger scale becomes more feasible without proportional growth in carbon, water, or energy demands.
- Automated multi-objective optimization replaces manual tuning for balancing latency and sustainability targets.
- The same coordination approach could be applied to other cloud workloads that share inference-like request patterns.
Where Pith is reading between the lines
- If the simulated gains transfer to production, operators could use similar agent systems to satisfy emerging regulatory requirements on datacenter emissions.
- Adding hardware heterogeneity or variable electricity pricing as additional agent objectives would test whether the framework remains stable under richer real-world conditions.
- Decentralized versions in which each agent represents a separate stakeholder might reduce the need for centralized control in multi-tenant clouds.
Load-bearing premise
The simulation environment and workload traces used for training and evaluation accurately reflect the dynamics, constraints, and measurement noise of real cloud datacenters running production LLM inference.
What would settle it
A controlled deployment of MARLIN on live production LLM workloads in an actual cloud datacenter, with direct measurement of TTFT, carbon emissions, water usage, and energy costs compared against baseline frameworks.
Figures




read the original abstract
Large Language Models (LLMs) have become increasingly prevalent in cloud-based platforms, propelled by the introduction of AI-based consumer and enterprise services. LLM inference requests in particular account for up to 90% of total LLM lifecycle energy use, dwarfing training energy costs. The rising volume of LLM inference requests is increasing environmental footprints, particularly carbon emissions and water consumption. To improve sustainability for LLM inference serving in cloud datacenter environments, we propose a novel multi-agent game-theoretic reinforcement learning framework called MARLIN to co-optimize time-to-first token (TTFT), carbon emissions, water usage, and energy costs associated with LLM inference. MARLIN demonstrates a reduction of at least 18% in TTFT, 33% in carbon emissions, 43% in water usage, and 11% in energy costs compared to state-of-the-art LLM inference management frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MARLIN, a multi-agent game-theoretic reinforcement learning framework for co-optimizing TTFT, carbon emissions, water usage, and energy costs during LLM inference serving in cloud datacenters. It claims quantitative gains of at least 18% lower TTFT, 33% lower carbon emissions, 43% lower water usage, and 11% lower energy costs relative to state-of-the-art LLM inference management frameworks.
Significance. If the simulation results hold under realistic production conditions, the work would offer a practical multi-objective control method for reducing the environmental footprint of the dominant phase of LLM lifecycle energy use. The combination of game-theoretic incentives with multi-agent RL is a plausible direction for handling competing latency and sustainability objectives in shared infrastructure.
major comments (2)
- [Abstract] Abstract and Evaluation section: the headline deltas (≥18% TTFT, 33% carbon, 43% water, 11% energy) are obtained exclusively from simulation; the manuscript supplies no equations, workload-generation procedure, power-model parameters, carbon-intensity traces, or validation against production traces, so the transferability of the learned policies cannot be assessed.
- [Evaluation] Evaluation section: the central assumption that the modeled request-arrival processes, per-GPU power curves, cooling-water models, and carbon traces are faithful enough for policy transfer is load-bearing; without sensitivity analysis or real-hardware cross-validation, the reported gains risk being simulator artifacts.
minor comments (2)
- Clarify the precise game-theoretic payoff structure and communication topology among agents; the abstract mentions both but does not define the utility functions or information exchange.
- Add error bars, number of random seeds, and statistical significance tests for all reported percentage improvements.
Circularity Check
No circularity: MARLIN rests on standard multi-agent RL applied to simulation
full rationale
The paper proposes MARLIN, a multi-agent game-theoretic RL framework for co-optimizing TTFT, carbon, water, and energy in LLM inference serving. No equations, derivations, or self-referential definitions appear in the abstract or described claims. Performance deltas are reported from simulation runs against baselines; these are empirical outputs rather than quantities that reduce by construction to fitted parameters or self-citations. No load-bearing step matches any of the enumerated circularity patterns (self-definitional, fitted-input-as-prediction, uniqueness imported from authors, etc.). The work is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- reward weights for TTFT, carbon, water, energy
- number of agents and communication topology
axioms (1)
- domain assumption Datacenter power and water consumption can be accurately modeled from server utilization and cooling parameters
Reference graph
Works this paper leans on
-
[1]
Llm statistics 2026: Comprehensive insights into market trends and integration,
A. Muhammad, “Llm statistics 2026: Comprehensive insights into market trends and integration, ” 2026. Accessed on Mar.31.2026
work page 2026
-
[2]
Chatgpt users statistics (2026) – active users & global growth data,
S. Singh, “Chatgpt users statistics (2026) – active users & global growth data, ”
work page 2026
-
[3]
Accessed on Mar.31.2026
work page 2026
-
[4]
The unseen ai disruptions for power grids: Llm-induced transients,
Y. Liet al., “The unseen ai disruptions for power grids: Llm-induced transients, ” 2024
work page 2024
-
[5]
What we know about energy use at u.s. data centers amid the ai boom,
R. Leppert, “What we know about energy use at u.s. data centers amid the ai boom, ” 2026. Accessed on Mar.31.2026
work page 2026
-
[6]
How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference,
N. Jeghamet al., “How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference, ” 2025
work page 2025
-
[7]
T. Xiaoet al., “Environmental impact and net-zero pathways for sustainable artificial intelligence servers in the usa, ”Nature Sustainability, pp. 1–13, 2025
work page 2025
-
[8]
Future global urban water scarcity and potential solutions,
C. He, Z. Liu, J. Wu,et al., “Future global urban water scarcity and potential solutions, ”Nature communications, vol. 12, no. 1, p. 4667, 2021
work page 2021
-
[9]
Energy and network aware workload management for geographically distributed data centers,
N. Hogade, S. Pasricha, and H. J. Siegel, “Energy and network aware workload management for geographically distributed data centers, ”IEEE Transactions on Sustainable Computing, vol. 7, no. 2, pp. 400–413, 2022
work page 2022
-
[10]
Power and thermal-aware virtual machine scheduling optimiza- tion in cloud data center,
R. Chenet al., “Power and thermal-aware virtual machine scheduling optimiza- tion in cloud data center, ”Future Generation Computer Systems, vol. 145, pp. 578– 589, 2023
work page 2023
-
[11]
S. Qi, H. Moore, N. Hogade, D. Milojicic, C. Bash, and S. Pasricha, “Casa: A framework for slo- and carbon-aware autoscaling and scheduling in serverless cloud computing, ” in2024 IEEE 15th IGSC, pp. 1–6, 2024
work page 2024
-
[12]
B. M. Beenaet al., “A green cloud-based framework for energy-efficient task scheduling using carbon intensity data for heterogeneous cloud servers, ”IEEE Access, vol. 13, pp. 73916–73938, 2025
work page 2025
-
[13]
S. Qi, H. Moore, D. Milojicic, C. Bash, and S. Pasricha, “Shield-eb: Sustainable hybrid evolutionary-boosting framework for carbon, wastewater, and cost-aware datacenter management, ”IEEE Access, vol. 14, pp. 40878–40898, 2026
work page 2026
-
[14]
Helix: Serving large language models over heterogeneous gpus and network via max-flow,
Y. Meiet al., “Helix: Serving large language models over heterogeneous gpus and network via max-flow, ” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, ASPLOS ’25, (New York, NY, USA), p. 586–602, Association for Computing Machinery, 2025
work page 2025
-
[15]
Splitwise: Efficient generative llm inference using phase splitting,
P. Patelet al., “Splitwise: Efficient generative llm inference using phase splitting, ” in2024 ACM/IEEE 51st ISCA, pp. 118–132, 2024
work page 2024
-
[16]
Perllm: Personalized inference scheduling with edge-cloud col- laboration for diverse llm services,
Z. Yanget al., “Perllm: Personalized inference scheduling with edge-cloud col- laboration for diverse llm services, ” 2024
work page 2024
-
[17]
Sustainable carbon-aware and water-efficient llm scheduling in geo-distributed cloud data- centers,
H. Moore, S. Qi, N. Hogade, D. Milojicic, C. Bash, and S. Pasricha, “Sustainable carbon-aware and water-efficient llm scheduling in geo-distributed cloud data- centers, ” inProceedings of the GLSVLSI 2025, GLSVLSI ’25, (New York, NY, USA), p. 929–934, Association for Computing Machinery, 2025
work page 2025
-
[18]
Burstgpt: A real-world workload dataset to optimize llm serv- ing systems,
Y. Wanget al., “Burstgpt: A real-world workload dataset to optimize llm serv- ing systems, ” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, KDD ’25, (New York, NY, USA), p. 5831–5841, Association for Computing Machinery, 2025
work page 2025
-
[19]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvronet al., “Llama 2: Open foundation and fine-tuned chat models, ” 2023
work page 2023
-
[20]
Delay-sensitive multicast in inter-datacenter wan using compressive latency monitoring,
T. Y. Cheng and X. Jia, “Delay-sensitive multicast in inter-datacenter wan using compressive latency monitoring, ”IEEE Transactions on Cloud Computing, vol. 8, no. 1, pp. 86–96, 2020
work page 2020
-
[21]
Mind the memory gap: Unveiling gpu bottlenecks in large-batch llm inference,
P. G. Recasenset al., “Mind the memory gap: Unveiling gpu bottlenecks in large-batch llm inference, ” in2025 IEEE 18th CLOUD, pp. 277–287, 2025
work page 2025
-
[22]
Alternating cold and hot aisles provides more reliable cooling for server farms,
R. F. Sullivan, “Alternating cold and hot aisles provides more reliable cooling for server farms, ”White Paper, Uptime Institute, 2000
work page 2000
-
[23]
Q. Zhanget al., “A survey on data center cooling systems: Technology, power consumption modeling and control strategy optimization, ”Journal of Systems Architecture, vol. 119, p. 102253, 2021
work page 2021
-
[24]
A review of data centers energy consumption and relia- bility modeling,
K. M. U. Ahmedet al., “A review of data centers energy consumption and relia- bility modeling, ”IEEE Access, vol. 9, pp. 152536–152563, 2021
work page 2021
-
[25]
The environmental footprint of data centers in the united states,
M. A. B. Siddiket al., “The environmental footprint of data centers in the united states, ”Environmental Research Letters, vol. 16, p. 064017, may 2021
work page 2021
-
[26]
Water use of electricity technologies: A global meta-analysis,
Y. Jinet al., “Water use of electricity technologies: A global meta-analysis, ”Re- newable and Sustainable Energy Reviews, vol. 115, p. 109391, 2019
work page 2019
-
[27]
Advanced weighted round robin procedure for load balanc- ing in cloud computing environment,
M. Kushwahaet al., “Advanced weighted round robin procedure for load balanc- ing in cloud computing environment, ” in2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), pp. 215–219, 2021
work page 2021
-
[28]
Mu: An efficient, fair and responsive serverless framework for resource-constrained edge clouds,
V. Mittalet al., “Mu: An efficient, fair and responsive serverless framework for resource-constrained edge clouds, ” inProceedings of the ACM Symposium on Cloud Computing, SoCC ’21, (New York, NY, USA), p. 168–181, Association for Computing Machinery, 2021
work page 2021
-
[29]
Film: Visual reasoning with a general conditioning layer,
E. Perezet al., “Film: Visual reasoning with a general conditioning layer, ” in Proceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
work page 2018
-
[30]
M. Andrychowiczet al., “Hindsight experience replay, ” inAdvances in Neural Information Processing Systems(I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, eds.), vol. 30, Curran Associates, Inc., 2017
work page 2017
-
[31]
An overview of gradient descent optimization algorithms,
S. Ruder, “An overview of gradient descent optimization algorithms, ” 2017
work page 2017
-
[32]
Theory of games and economic behavior, 2nd rev,
J. Von Neumann and O. Morgenstern, “Theory of games and economic behavior, 2nd rev, ” 1947
work page 1947
-
[33]
A fast and elitist multiobjective genetic algorithm: Nsga-ii,
K. Debet al., “A fast and elitist multiobjective genetic algorithm: Nsga-ii, ”IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182–197, 2002
work page 2002
-
[34]
Q-learning-based workload consolidation for data centers with composable architecture,
C. Guoet al., “Q-learning-based workload consolidation for data centers with composable architecture, ”IEEE Transactions on Industrial Informatics, vol. 21, no. 3, pp. 2324–2333, 2025
work page 2025
-
[35]
L. Alsalem and K. Djemame, “Task scheduling in edge computing environments: a hierarchical cluster-based federated deep reinforcement learning approach, ” inProceedings of the 18th IEEE/ACM International Conference on Utility and Cloud Computing, UCC ’25, (New York, NY, USA), Association for Computing Machinery, 2026
work page 2026
-
[36]
T. Hidayatet al., “Reinforcement learning-driven hybrid precopy/postcopy vm migration for energy-efficient data centers, ”IEEE Access, vol. 13, pp. 169521– 169533, 2025. 8
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.