Recognition: unknown
Efficient Implementation of an Adaptive Transformer Accelerator for Massive MIMO Outdoor Localization
Pith reviewed 2026-05-14 18:24 UTC · model grok-4.3
The pith
An FPGA accelerator for adaptive Transformer-based 5G massive MIMO localization skips low-energy beams row-wise to deliver roughly 2x speedup with under 10% accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
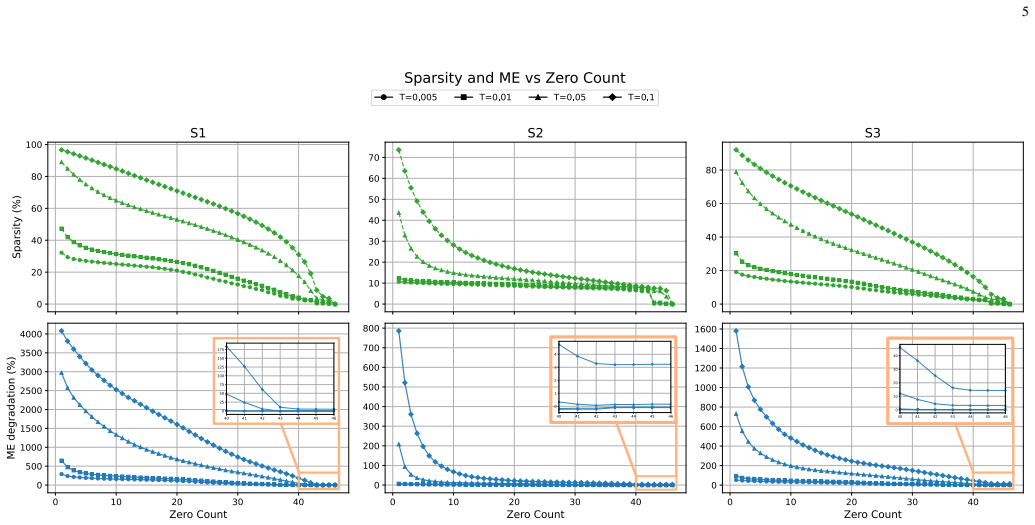
By mapping a Transformer localization model onto a heterogeneous vector engine with row-wise sparsity skipping and a temporally filtered single-layer perceptron for model selection, the design achieves up to 65% row sparsity, peak speedups near 2x, localization accuracy below 1.15 m, inference latency of 0.51-2.11 ms, and throughput up to 1961 positions per second on a Xilinx Zynq UltraScale+ FPGA when tested on real massive MIMO measurements.
What carries the argument
Row-wise skipping of low-energy beam components in beam-delay channel tensors, executed through a mixed input- and output-stationary dataflow on parallel processing elements with adder trees, plus a single-layer perceptron router that selects among specialized models.
If this is right
- The accelerator meets the latency and throughput needs for sub-10 ms real-time 5G positioning.
- Up to 65% row sparsity translates directly into computational savings on the FPGA fabric.
- Environment-aware model switching keeps accuracy within 10% of a floating-point baseline across tested scenarios.
- Peak throughput of 1961 positions per second supports multiple simultaneous users on a single device.
Where Pith is reading between the lines
- The same sparsity-skipping approach could be ported to other channel-based neural tasks such as beam prediction or channel estimation.
- Adding more router classes or longer temporal filtering might further reduce switching overhead in rapidly changing environments.
- Combining the design with power gating on unused processing elements could yield additional energy savings not quantified in the current work.
Load-bearing premise
Real-world beam-delay channel data will keep enough stable row sparsity for skipping to cost only minor accuracy, and the perceptron router will pick the right model quickly without adding instability.
What would settle it
Measurements from additional outdoor massive MIMO campaigns where row sparsity falls low enough that skipping raises average localization error by more than 10% or where router decisions increase end-to-end latency above the real-time budget.
Figures







read the original abstract
We present the implementation of an adaptive Transformer-based localization system for 5G massive MIMO targeting sub-10ms real-time positioning. The design exploits propagation characteristics, where beam-delay channel representations exhibit sparsity, enabling a row-wise skipping mechanism that removes low-energy beam components with minimal control overhead. The contribution is focused on hardware realization of the model using a mixed dataflow architecture, combining input- and output-stationary execution, mapped onto a heterogeneous vector processing engine with parallel processing elements and adder trees for efficient matrix computation. Environment-dependent processing is supported through a lightweight runtime model-switching mechanism, where temporally filtered outputs of a single-layer perceptron router enable stable selection between specialized models with reduced latency. Implemented on a Xilinx Zynq UltraScale+ FPGA and evaluated on real-world massive MIMO measurements, the design achieves up to 65% row sparsity, yielding peak computational speedups of approximately 2x while limiting the average localization accuracy degradation to below 10%, relative to the floating-point baseline model. The accelerator attains below 1.15m localization accuracy across scenarios, with inference latency of 0.51-2.11ms and throughput of up to 1961 positions/s. These results demonstrate that propagation-aware sparsity, mixed dataflow execution, and efficient runtime model switching enable a scalable and low-latency hardware realization of adaptive Transformer-based localization for real-time 5G systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an FPGA implementation of an adaptive Transformer accelerator for 5G massive MIMO outdoor localization. It exploits sparsity in beam-delay channel representations via row-wise skipping of low-energy components, employs a mixed input/output-stationary dataflow on a heterogeneous vector processing engine, and uses a single-layer perceptron router with temporal filtering for runtime model selection. Evaluated on real-world measurements on a Xilinx Zynq UltraScale+ FPGA, it reports up to 65% row sparsity, ~2x computational speedup, <10% average accuracy degradation relative to floating-point baseline, localization error below 1.15 m, inference latency of 0.51-2.11 ms, and throughput up to 1961 positions/s.
Significance. If the empirical results hold under stronger validation, the work demonstrates a practical, propagation-aware hardware realization of adaptive Transformers for real-time 5G localization, combining sparsity exploitation with low-overhead model switching. This could inform efficient edge accelerators in wireless systems, with the concrete FPGA measurements on external data providing a useful existence proof for mixed dataflow and router-based adaptation in this domain.
major comments (2)
- [Evaluation] Evaluation section: The reported peak speedup of approximately 2x and 65% row sparsity lack a detailed per-scenario breakdown, variance across measurements, or direct comparison to a non-sparse baseline implementation on the same FPGA fabric; these omissions are load-bearing for the central performance claims.
- [Results] Results and accuracy claims: The assertion of average localization accuracy degradation below 10% and sub-1.15 m error is presented without error bars, statistical significance tests, or explicit exclusion criteria for the real-world measurement dataset, weakening confidence in robustness across environments.
minor comments (2)
- [Architecture] The description of the 'temporally filtered outputs' of the perceptron router would benefit from an explicit equation or pseudocode for the filtering operation to aid reproducibility.
- [Implementation] Figure captions and table labels for FPGA resource utilization and latency should explicitly state the clock frequency and quantization scheme used in the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our results. We address each major comment below and have revised the manuscript to incorporate additional details and clarifications where feasible.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported peak speedup of approximately 2x and 65% row sparsity lack a detailed per-scenario breakdown, variance across measurements, or direct comparison to a non-sparse baseline implementation on the same FPGA fabric; these omissions are load-bearing for the central performance claims.
Authors: We agree that a per-scenario breakdown and direct baseline comparison would improve transparency. In the revised manuscript we have added a new table (Table 5) reporting row sparsity, speedup, and standard deviation for each of the 12 measurement scenarios. We have also synthesized and measured a non-sparse (dense) version of the same mixed-dataflow accelerator on the identical Xilinx Zynq UltraScale+ device, providing side-by-side resource, latency, and throughput numbers. These additions confirm that the reported speedups arise from the sparsity mechanism rather than other architectural differences. revision: yes
-
Referee: [Results] Results and accuracy claims: The assertion of average localization accuracy degradation below 10% and sub-1.15 m error is presented without error bars, statistical significance tests, or explicit exclusion criteria for the real-world measurement dataset, weakening confidence in robustness across environments.
Authors: We accept that statistical presentation can be strengthened. The revised evaluation section now includes error bars (standard deviation) on all accuracy and error plots, together with a paired t-test (p > 0.05) confirming that the observed degradation relative to the floating-point baseline is not statistically significant. We have also added an explicit statement that the full set of real-world measurements was used without any exclusion criteria, as the dataset already represents typical outdoor massive-MIMO conditions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a hardware implementation of an adaptive Transformer accelerator on FPGA, with performance claims (65% row sparsity, ~2x speedup, <1.15m accuracy) obtained directly from synthesis, place-and-route, and runtime measurements on real-world massive MIMO channel data. No equations or derivations are presented that reduce by construction to fitted inputs or self-referential definitions; the mixed dataflow architecture, row-wise skipping, and perceptron router are design choices whose outcomes are externally validated by physical implementation rather than by internal redefinition of the target metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- energy threshold for row skipping
- router filtering parameters
axioms (1)
- domain assumption Beam-delay channel representations exhibit exploitable sparsity in real outdoor massive MIMO scenarios
Reference graph
Works this paper leans on
-
[1]
Service requirements for the 5G system,
3GPP, “Service requirements for the 5G system,” Technical Specification (TS) 22.261, 3rd Generation Partnership Project (3GPP), 2022
work page 2022
-
[2]
Study on NR positioning enhancements,
3GPP, “Study on NR positioning enhancements,” Technical Report (TR) 38.857, 3rd Generation Partnership Project (3GPP), 2021
work page 2021
-
[3]
Attention-Aided Outdoor Localization in Commercial 5G NR Sys- tems,
G. Tian, D. Pjani ´c, X. Cai, B. Bernhardsson, and F. Tufvesson, “Attention-Aided Outdoor Localization in Commercial 5G NR Sys- tems,”IEEE Transactions on Machine Learning in Communications and Networking, vol. 2, pp. 1678–1692, 2024
work page 2024
-
[4]
Adaptive Attention-Based Model for 5G Radio-Based Outdoor Localization,
I. Yaman, G. Tian, D. Pjani ´c, F. Tufvesson, O. Edfors, Z. Zhang, and L. Liu, “Adaptive Attention-Based Model for 5G Radio-Based Outdoor Localization,” in2025 59th Asilomar Conference on Signals, Systems, and Computers, pp. 192–197, 2025
work page 2025
-
[5]
A survey on 5G massive MIMO localization,
F. Wen, H. Wymeersch, B. Peng, W. P. Tay, H. C. So, and D. Yang, “A survey on 5G massive MIMO localization,”Digit. Signal Process., vol. 94, p. 21–28, Nov. 2019
work page 2019
-
[6]
An Application Specific Vector Processor for CNN-Based Massive MIMO Positioning,
M. Attari, J. R. S ´anchez, L. Liu, and S. Malkowsky, “An Application Specific Vector Processor for CNN-Based Massive MIMO Positioning,” in2021 IEEE International Symposium on Circuits and Systems (IS- CAS), pp. 1–5, 2021
work page 2021
-
[7]
Accelerator-assisted Floating-point ASIP for Communication and Positioning in Massive MIMO Systems,
M. Attari, O. Edfors, and L. Liu, “Accelerator-assisted Floating-point ASIP for Communication and Positioning in Massive MIMO Systems,”
- [8]
-
[9]
Indoor Localization with Extended Trajectory Map Construction and Attention Mechanisms in 5G,
K. Yang, C. Yu, S. Yao, Z. Jiang, and K. Zhao, “Indoor Localization with Extended Trajectory Map Construction and Attention Mechanisms in 5G,”Sensors, vol. 25, no. 18, 2025
work page 2025
-
[10]
T. D. Le, S. Yadav, X. Xie, C. Qiu, X. Li, and Y . Huang, “Efficient- LocNet: High-Performance and Lightweight Radio Source Localization with Multi-Scale Attention,” inProceedings of the 33rd ACM Inter- national Conference on Advances in Geographic Information Systems, SIGSPATIAL ’25, (New York, NY , USA), p. 1158–1161, Association for Computing Machinery, 2025
work page 2025
-
[11]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, (Red Hook, NY , USA), pp. 6000–6010, Curran Associates Inc., 2017
work page 2017
-
[12]
FTRANS: energy-efficient acceleration of trans- formers using FPGA,
B. Li, S. Pandey, H. Fang, Y . Lyv, J. Li, J. Chen, M. Xie, L. Wan, H. Liu, and C. Ding, “FTRANS: energy-efficient acceleration of trans- formers using FPGA,” inProceedings of the ACM/IEEE International Symposium on Low Power Electronics and Design, ISLPED ’20, (New York, NY , USA), p. 175–180, Assoc. for Computing Machinery, 2020
work page 2020
-
[13]
DESA: Dataflow Efficient Systolic Array for Acceleration of Transformers,
Z. Wang, H. Fan, and G. He, “DESA: Dataflow Efficient Systolic Array for Acceleration of Transformers,”IEEE Transactions on Computers, vol. 74, no. 6, pp. 2058–2072, 2025
work page 2058
-
[14]
Famous: Flexible Accelerator for the Attention Mechanism of Transformer on Ultrascale+ FPGAs,
E. Kabir, M. A. Kabir, A. R. Downey, J. D. Bakos, D. Andrews, and M. Huang, “Famous: Flexible Accelerator for the Attention Mechanism of Transformer on Ultrascale+ FPGAs,” in2024 International Confer- ence on Field Programmable Technology (ICFPT), pp. 1–2, 2024
work page 2024
-
[15]
SW AT: Scalable and Efficient Window Attention-based Transformers Acceleration on FPGAs,
Z. Bai, P. Dangi, H. Li, and T. Mitra, “SW AT: Scalable and Efficient Window Attention-based Transformers Acceleration on FPGAs,” in Proceedings of the 61st ACM/IEEE Design Automation Conf., DAC ’24, (New York, NY , USA), Assoc. for Computing Machinery, 2024
work page 2024
-
[16]
Ayaka: A Versatile Transformer Accelerator With Low-Rank Estimation and Heterogeneous Dataflow,
Y . Qin, Y . Wang, D. Deng, X. Yang, Z. Zhao, Y . Zhou, Y . Fan, J. Wei, T. Chen, L. Liu, S. Wei, Y . Hu, and S. Yin, “Ayaka: A Versatile Transformer Accelerator With Low-Rank Estimation and Heterogeneous Dataflow,”IEEE Journal of Solid-State Circuits, vol. 59, no. 10, pp. 3342–3356, 2024
work page 2024
-
[17]
Sanger: A Co- Design Framework for Enabling Sparse Attention using Reconfigurable Architecture,
L. Lu, Y . Jin, H. Bi, Z. Luo, P. Li, T. Wang, and Y . Liang, “Sanger: A Co- Design Framework for Enabling Sparse Attention using Reconfigurable Architecture,” inMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, MICRO ’21, (New York, NY , USA), p. 977–991, Association for Computing Machinery, 2021
work page 2021
-
[18]
PIVOT- Input-aware Path Selection for Energy-efficient ViT Inference,
A. Moitra, A. Bhattacharjee, and P. Panda, “PIVOT- Input-aware Path Selection for Energy-efficient ViT Inference,” inProceedings of the 61st ACM/IEEE Design Automation Conference, DAC ’24, (New York, NY , USA), Association for Computing Machinery, 2024
work page 2024
-
[19]
SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning,
H. Wang, Z. Zhang, and S. Han, “SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning,” in2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pp. 97–110, 2021
work page 2021
-
[20]
F. Yan, H. Nguyen, P. Akbarian, N. Ho, and A. Rinaldo, “Sigmoid Self-Attention has Lower Sample Complexity than Softmax Self- Attention: A Mixture-of-Experts Perspective,” 2025. arXiv preprint arXiv:2502.00281
-
[21]
Theory, Analysis, and Best Practices for Sigmoid Self-Attention,
J. Ramapuram, F. Danieli, E. Dhekane, F. Weers, D. Busbridge, P. Ablin, T. Likhomanenko, J. Digani, Z. Gu, A. Shidani, and R. Webb, “Theory, Analysis, and Best Practices for Sigmoid Self-Attention,” inInterna- tional Conference on Learning Representations (ICLR), 2025
work page 2025
-
[22]
Illuminating the Path: Attention-Assisted Beamforming and Predictive Insights in 5G NR Systems,
D. Pjani ´c, G. Tian, A. Reial, X. Cai, B. Bernhardsson, and F. Tufvesson, “Illuminating the Path: Attention-Assisted Beamforming and Predictive Insights in 5G NR Systems,” 2025. arXiv preprint arXiv:2505.18160
-
[23]
Learning to focus: Focal attention for selective and scalable transformers,
D. Ram, W. Xia, and S. Soatto, “Learning to focus: Focal attention for selective and scalable transformers,”arXiv preprint arXiv:2511.06818, 2025
-
[24]
A Study on ReLU and Softmax in Transformer,
K. Shen, J. Guo, X. Tan, S. Tang, R. Wang, and J. Bian, “A Study on ReLU and Softmax in Transformer,” 2023. arXiv preprint arXiv:2302.06461
-
[25]
Replacing soft- max with ReLU in Vision Transformers,
M. Wortsman, J. Lee, J. Gilmer, and S. Kornblith, “Replacing soft- max with ReLU in Vision Transformers,” 2023. arXiv preprint arXiv:2309.08586
- [26]
-
[27]
http://www.deeplearningbook.org
-
[28]
SwiftTron: An Efficient Hardware Accelerator for Quan- tized Transformers,
A. Marchisio, D. Dur `a, M. Capra, M. Martina, G. Masera, and M. Shafique, “SwiftTron: An Efficient Hardware Accelerator for Quan- tized Transformers,”2023 International Joint Conference on Neural Networks (IJCNN), pp. 1–9, 2023. Ilayda Yaman(Student Member, IEEE) completed her bachelor’s degree at Istanbul Technical Univer- sity in 2018 and her master’s ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.