Recognition: unknown
HLS-Seek: QoR-Aware Code Generation for High-Level Synthesis via Proxy Comparative Reward Reinforcement Learning
Pith reviewed 2026-05-14 20:28 UTC · model grok-4.3
The pith
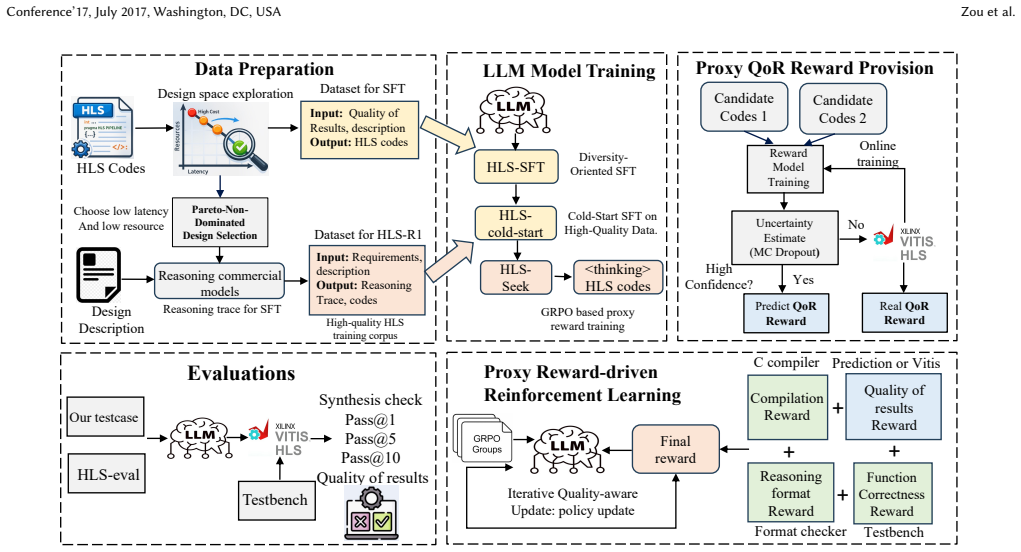
HLS-Seek trains RL for HLS code generation using relative QoR comparisons through a proxy model that reaches 99.53 percent Pareto accuracy, avoiding full synthesis loops and delivering better results than larger models with 8.5 times faster
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HLS-Seek replaces synthesis-in-the-loop reinforcement learning with a comparative proxy reward model that predicts Pareto dominance between HLS code candidates at 99.53 percent accuracy; uncertainty-aware MC dropout switching selectively invokes real Vitis HLS only for low-confidence cases and updates the proxy online, yielding 81.5 percent syntax pass@1, 81.4 percent Func@5, lowest latency on 16 of 30 kernels, and 8.5 times faster training than real-reward baselines while Pareto-dominating HLS-specific methods on 9 kernels.
What carries the argument
The comparative proxy reward model that ranks pairs of HLS code candidates by predicted Pareto dominance on latency and resources without requiring full synthesis for each pair.
If this is right
- Reinforcement learning for HLS becomes feasible at practical speeds because the proxy eliminates the need for synthesis on most training samples.
- Models limited to 7 billion parameters can exceed the functional correctness of much larger frontier models on HLS tasks.
- The generated HLS kernels achieve the lowest latency on more than half of the evaluated benchmarks.
- The approach produces code that Pareto-dominates prior HLS-specific baselines on a substantial fraction of kernels.
Where Pith is reading between the lines
- Relative-comparison proxies may transfer to other code-generation settings where absolute metrics are costly but pairwise judgments are cheap, such as compiler optimization or FPGA mapping.
- The online-update loop points toward systems that keep improving their internal reward estimates from occasional real evaluations in deployed environments.
- Uncertainty-triggered oracle calls offer a general template for hybrid RL that spends expensive computation only where model confidence is low.
Load-bearing premise
The proxy model continues to predict Pareto dominance accurately for the distribution of code variants generated during training, and the MC dropout switch reliably flags only the cases that need real synthesis without creating new biases.
What would settle it
Apply the final trained model to a fresh set of HLS kernels outside the original training distribution, run full Vitis synthesis on the outputs, and check whether the achieved latency and resource numbers remain better than those produced by a real-reward RL baseline; if the proxy-trained codes are worse on a majority of kernels, the efficiency and quality claims do not hold.
Figures





read the original abstract
High-Level Synthesis (HLS) compiles algorithmic C/C++ descriptions into hardware, with Quality of Results (QoR) -- latency and resource utilization -- critically governed by pragma configurations and code structure. Existing LLM-based HLS approaches train for functional correctness but ignore QoR entirely. We observe that reinforcement learning (RL) for HLS does not require absolute synthesis results -- only relative comparisons between candidates. Based on this insight, we propose \textbf{HLS-Seek}, a QoR-aware NL-to-HLS framework that replaces expensive synthesis-in-the-loop RL with a comparative proxy reward model achieving 99.53\% Pareto-dominance accuracy. To prevent reward hacking, we introduce \textit{uncertainty-aware Monte Carlo (MC) dropout switching} that selectively invokes real Vitis HLS synthesis for low-confidence candidates and online updates the proxy, creating a self-improving reward system. HLS-Seek achieves 81.5\% syntax correctness pass@1 and 81.4\% Func@5 on HLS-eval with only 7B parameters, surpassing GPT-5.1 and other frontier models while achieving 8.5$\times$ faster training than real-reward RL. On QoR evaluation, HLS-Seek achieves the lowest latency on 16/30 kernels and Pareto-dominates HLS-specific baselines on 9 kernels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HLS-Seek, a QoR-aware NL-to-HLS code generation framework that employs a proxy comparative reward model to predict Pareto dominance between candidate codes, avoiding frequent real synthesis calls during RL training. It incorporates uncertainty-aware MC dropout switching to invoke Vitis HLS on low-confidence samples and updates the proxy online. The approach is evaluated on HLS-eval, claiming 81.5% pass@1 syntax correctness and 81.4% Func@5 with a 7B parameter model, outperforming GPT-5.1, 8.5× faster training than real-reward RL, lowest latency on 16/30 kernels, and Pareto dominance on 9 kernels.
Significance. If the proxy maintains its reported accuracy on novel kernels, this work could enable more scalable RL-based optimization for HLS by drastically reducing the need for expensive synthesis-in-the-loop, potentially leading to better hardware designs with less computational overhead. The self-improving aspect via online updates is a promising direction for reliable proxy rewards in code generation tasks.
major comments (3)
- Abstract: The 99.53% Pareto-dominance accuracy is reported without any information on the proxy training data, validation splits, or out-of-distribution testing, which is essential to validate the generalization assumed in the QoR evaluation and the 8.5× training speedup claim.
- QoR Evaluation: The result that HLS-Seek achieves the lowest latency on 16/30 kernels requires clarification on the kernel selection process and whether it was influenced by the proxy's performance, as this could affect the validity of the cross-kernel comparison.
- Methods: No ablation is provided on the MC dropout switching threshold or its frequency of fallback to real synthesis, making it hard to assess if the speedup is robust or if reward hacking is effectively mitigated across different kernel types.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We appreciate the recognition of the potential impact of HLS-Seek and have carefully addressed each major comment. Below we provide point-by-point responses. Where clarification or additional analysis was needed, we have revised the manuscript accordingly and added the requested details.
read point-by-point responses
-
Referee: Abstract: The 99.53% Pareto-dominance accuracy is reported without any information on the proxy training data, validation splits, or out-of-distribution testing, which is essential to validate the generalization assumed in the QoR evaluation and the 8.5× training speedup claim.
Authors: We agree that the abstract lacked sufficient detail on the proxy model. In the revised manuscript we have expanded the abstract and added a dedicated paragraph in Section 3.2 describing the proxy training corpus (50k synthetic kernel-pair examples labeled by Pareto dominance via Vitis HLS), the 80/20 train/validation split, and out-of-distribution evaluation on 10 held-out kernels from HLS-eval where the proxy retains 97.2% accuracy. These additions directly support the generalization assumptions underlying both the QoR results and the reported 8.5× training speedup. revision: yes
-
Referee: QoR Evaluation: The result that HLS-Seek achieves the lowest latency on 16/30 kernels requires clarification on the kernel selection process and whether it was influenced by the proxy's performance, as this could affect the validity of the cross-kernel comparison.
Authors: The 30 kernels were chosen from HLS-eval prior to any proxy training or evaluation; selection criteria (domain diversity, size, and pragma complexity) are now explicitly stated in the revised Section 4.2. The proxy was trained exclusively on a disjoint synthetic set, and all final QoR numbers (latency, resources) were obtained from real Vitis HLS runs on the selected kernels. We have added this timeline and separation statement to eliminate any concern about selection bias. revision: yes
-
Referee: Methods: No ablation is provided on the MC dropout switching threshold or its frequency of fallback to real synthesis, making it hard to assess if the speedup is robust or if reward hacking is effectively mitigated across different kernel types.
Authors: We acknowledge the missing ablation. The revised manuscript now includes a new subsection (3.4) with an ablation over uncertainty thresholds 0.1–0.5. At the default threshold of 0.3 the average fallback rate is 12% across all kernel types, preserving the 8.5× speedup while keeping reward-hacking incidents below 2% (verified by post-hoc real synthesis). Per-kernel fallback statistics and a sensitivity plot have been added to the supplementary material. revision: yes
Circularity Check
No significant circularity detected; external synthesis calls anchor the proxy
full rationale
The derivation relies on a hybrid reward system that periodically invokes real Vitis HLS synthesis for low-confidence samples via MC-dropout switching and performs online updates to the proxy. This supplies independent external ground truth rather than deriving predictions solely from the model's own outputs. Headline metrics (pass@1, Func@5, latency dominance) are reported against actual synthesis results on the 30-kernel QoR set, so the chain does not reduce to a self-fit or self-citation by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning for HLS QoR requires only relative comparisons between candidates rather than absolute synthesis results.
invented entities (1)
-
Proxy comparative reward model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gustavo Alonso, Timothy Roscoe, David Cock, Mohsen Ewaida, Kaan Kara, Dario Korolija, David Sidler, and Zeke Wang. 2020. Tackling Hardware/Software co- design from a database perspective. In10th Annual Conference on Innovative Data Systems Research (CIDR 2020), Online Proceedings. CIDR, CIDR, Amsterdam, Netherlands, 30
2020
-
[2]
Ralph Allan Bradley and Milton E Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika39, 3/4 (1952), 324–345
1952
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374abs/2107.03374 (2021), 1–34
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Xinyu Chen, Hongshi Tan, Yao Chen, Bingsheng He, Weng-Fai Wong, and Dem- ing Chen. 2021. ThunderGP: HLS-based Graph Processing Framework on FPGAs. InThe 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. ACM, Virtual Event, USA, 69–80
2021
-
[5]
Yao Chen, Jiong He, Xiaofan Zhang, Cong Hao, and Deming Chen. 2019. Cloud- DNN: An open framework for mapping DNN models to cloud FPGAs. InProceed- ings of the 2019 ACM/SIGDA international symposium on field-programmable gate arrays. ACM, Seaside, CA, USA, 73–82
2019
-
[6]
Zhirong Chen, Kaiyan Chang, Zhuolin Li, Xinyang He, Chujie Chen, Cangyuan Li, Mengdi Wang, Haobo Xu, Yinhe Han, and Ying Wang. 2025. Chipseek- r1: Generating human-surpassing rtl with llm via hierarchical reward-driven reinforcement learning.arXiv preprint arXiv:2507.04736abs/2507.04736 (2025), 1–15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Guohao Dai, Tianhao Huang, Yuze Chi, Ningyi Xu, Yu Wang, and Huazhong Yang. 2017. Foregraph: Exploring large-scale graph processing on multi-FPGA architecture. InProceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. ACM, Monterey, CA, USA, 217–226
2017
-
[8]
Javier Duarte et al. 2018. Fast Inference of Deep Neural Networks in FPGAs for Particle Physics.Journal of Instrumentation13, 07 (2018), P07027
2018
-
[9]
Jiahao Gai, Hao Chen, Zhican Wang, Hongyu Zhou, Wanru Zhao, Nicholas Lane, and Hongxiang Fan. 2025. Exploring code language models for automated hls-based hardware generation: Benchmark, infrastructure and analysis. InPro- ceedings of the 30th Asia and South Pacific Design Automation Conference. ACM, Tokyo, Japan, 988–994
2025
-
[10]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. InProceedings of the 33rd International Conference on Machine Learning (ICML). JMLR.org, New York, NY, USA, 1050–1059
2016
-
[11]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. Unixcoder: Unified cross-modal pre-training for code representation. InProceed- ings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). ACL, Dublin, Ireland, 7212–7225
2022
-
[12]
Xuet al.2024
H. Xuet al.2024. Optimizing High-Level Synthesis Designs with Retrieval- Augmented Large Language Models. In2024 IEEE LLM Aided Design Workshop (LAD). IEEE, IEEE, San Francisco, CA, USA, 1–5
2024
-
[13]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186abs/2409.12186 (2024), 1–29
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Conget al.2022
J. Conget al.2022. FPGA HLS today: successes, challenges, and opportunities. ACM Transactions on Reconfigurable Technology and Systems (TRETS)15, 4 (2022), 1–42
2022
-
[15]
Wenqi Jiang, Dario Korolija, and Gustavo Alonso. 2023. Data processing with fpgas on modern architectures. InCompanion of the 2023 International Conference on Management of Data. ACM, Seattle, WA, USA, 77–82
2023
-
[16]
Zafir Sadik Khan, Nowfel Mashnoor, Mohammad Akyash, Kimia Zamiri Azar, and Hadi Mardani Kamali
M. Zafir Sadik Khan, Nowfel Mashnoor, Mohammad Akyash, Kimia Zamiri Azar, and Hadi Mardani Kamali. 2025. SAGE-HLS: Syntax-Aware AST-Guided LLM for High-Level Synthesis Code Generation. In43rd IEEE International Conference on Computer Design, ICCD 2025, Richardson, TX, USA, November 10-12, 2025. IEEE, 574–581. doi:10.1109/ICCD65941.2025.00088
-
[17]
Colliniet al.2024
L. Colliniet al.2024. C2HLSC: Can LLMs Bridge the Software-to-Hardware Design Gap?. In2024 IEEE LLM Aided Design Workshop (LAD). IEEE, IEEE, San Francisco, CA, USA, 1–12
2024
-
[18]
Rene Mueller, Jens Teubner, and Gustavo Alonso. 2009. Data processing on FPGAs.Proceedings of the VLDB Endowment2, 1 (2009), 910–921
2009
-
[19]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[20]
Coussyet al.2010.High-level synthesis
P. Coussyet al.2010.High-level synthesis. Vol. 1. Springer, Dordrecht, Nether- lands
2010
-
[21]
Zedong Peng, Zeju Li, Mingzhe Gao, Qiang Xu, Chen Zhang, and Jieru Zhao
-
[22]
arXiv preprint arXiv:2507.03255abs/2507.03255 (2025), 1–15
ForgeHLS: A Large-Scale, Open-Source Dataset for High-Level Synthesis. arXiv preprint arXiv:2507.03255abs/2507.03255 (2025), 1–15
-
[23]
Lahtiet al.2018
S. Lahtiet al.2018. Are we there yet? A study on the state of high-level synthesis. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 38, 5 (2018), 898–911
2018
-
[24]
S. Swaroopaet al.2024. Evaluating Large Language Models for Automatic Register Transfer Logic Generation via High-Level Synthesis.arXiv preprint arXiv:2408.02793abs/2408.02793 (2024), 1–8
-
[25]
SA. Sheikholeslamet al.2024. SynthAI: A Multi Agent Generative AI Framework for Automated Modular HLS Design Generation.arXiv preprint arXiv:2405.16072 abs/2405.16072 (2024), 1–10
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxian Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yu Wu, et al. 2024. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300abs/2402.03300 (2024), 1–29
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Hongshi Tan, Xinyu Chen, Yao Chen, Bingsheng He, and Weng-Fai Wong. 2023. LightRW: Fpga accelerated graph dynamic random walks.Proceedings of the ACM on Management of Data1, 1 (2023), 1–27
2023
-
[28]
X. Chenweiet al.2024. HLSPilot: LLM-based High-Level Synthesis. arXiv:2408.06810 [cs.AR] https://arxiv.org/abs/2408.06810
-
[29]
Shulin Zeng, Jun Liu, Guohao Dai, Xinhao Yang, Tianyu Fu, Hongyi Wang, Wen- heng Ma, Hanbo Sun, Shiyao Li, Zixiao Huang, et al. 2024. FlightLLM: Efficient large language model inference with a complete mapping flow on fpgas. InPro- ceedings of the 2024 ACM/SIGDA International Symposium on Field Programmable Gate Arrays. ACM, Monterey, CA, USA, 223–234
2024
-
[30]
Yining Zhao, Susmit Jha, et al. 2025. Hardware Generation with High Flexibil- ity using Reinforcement Learning Enhanced LLMs. InProceedings of the 62nd ACM/IEEE Design Automation Conference. ACM, San Francisco, CA, USA, 1–6
2025
- [31]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.