Recognition: 1 theorem link
· Lean TheoremSelf-Supervised On-Policy Reinforcement Learning via Contrastive Proximal Policy Optimisation
Pith reviewed 2026-05-14 20:08 UTC · model grok-4.3
The pith
CPPO derives advantages from contrastive Q-values to enable on-policy self-supervised RL that matches reward-based PPO in most tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
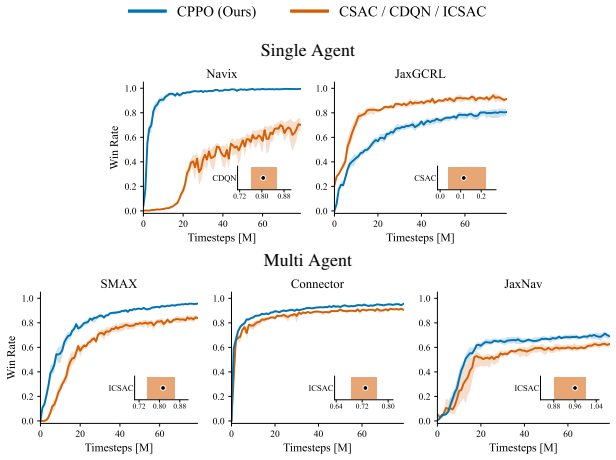
CPPO is an on-policy contrastive RL algorithm that derives policy advantages directly from contrastive Q-values and optimises them via the standard PPO objective, without requiring a reward function or a replay buffer. Across continuous and discrete, single-agent and cooperative multi-agent tasks, CPPO significantly outperforms previous CRL baselines in 14 out of 18 tasks and matches or exceeds PPO's performance, which uses hand-crafted dense rewards, in 12 out of the 18 tasks tested.
What carries the argument
Deriving policy advantages directly from contrastive Q-values and optimising them with the PPO objective.
If this is right
- Self-supervised RL becomes compatible with standard on-policy pipelines used in both single-agent and multi-agent settings.
- Dense reward engineering is no longer required to reach competitive performance levels.
- Discrete action spaces and cooperative multi-agent problems become accessible to contrastive methods without replay buffers.
- Training simplifies by removing the need to maintain and sample from experience replay.
- The same contrastive Q-value signal can support both policy improvement and value estimation within one objective.
Where Pith is reading between the lines
- The method may extend naturally to other on-policy algorithms such as TRPO or IMPALA where advantage estimation is central.
- In environments with very large discrete action spaces, the contrastive signal could reduce the sample complexity compared with reward shaping.
- Cooperative multi-agent tasks might benefit from shared contrastive representations that align agent goals without explicit communication rewards.
- Further work could test whether the same approach stabilises learning when goals are specified only at test time rather than during training.
Load-bearing premise
Advantages derived directly from contrastive Q-values provide a stable and unbiased signal suitable for on-policy PPO optimization without introducing additional instability or requiring further corrections.
What would settle it
A replication of the 18-task evaluation in which CPPO underperforms PPO with dense rewards on more than 6 tasks or shows clear training instability traceable to the contrastive advantage estimates.
Figures




read the original abstract
Contrastive reinforcement learning (CRL) learns goal-conditioned Q-values through a contrastive objective over state-action and goal representations, removing the need for hand-crafted reward functions. Despite impressive success in achieving viable self-supervised learning in RL, all existing CRL algorithms rely on off-policy optimisation and are mostly constrained to continuous action spaces, with little research invested in discrete environments. This leaves CRL disconnected from widely used and effective, modern on-policy training pipelines adopted across both single-agent and multi-agent RL in continuous and discrete environments. To establish a first connection, we introduce Contrastive Proximal Policy Optimisation (CPPO). CPPO is an on-policy contrastive RL algorithm that derives policy advantages directly from contrastive Q-values and optimises them via the standard PPO objective, without requiring a reward function or a replay buffer. We evaluate CPPO across continuous and discrete, single-agent and cooperative multi-agent tasks. Whilst the existence of an on-policy approach is inherently useful, we observe that \textbf{CPPO not only significantly outperforms the previous CRL baselines in 14 out of 18 tasks, but also matches or exceeds PPO's performance, which uses hand-crafted dense rewards, in 12 out of the 18 tasks tested.}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Contrastive Proximal Policy Optimisation (CPPO), an on-policy self-supervised RL algorithm that learns goal-conditioned Q-values via a contrastive objective over state-action-goal triples and derives advantages directly from these Q-values for optimization with the standard PPO clipped surrogate, without rewards or replay buffers. It reports that CPPO outperforms prior CRL baselines in 14 of 18 tasks and matches or exceeds dense-reward PPO in 12 of 18 tasks across continuous/discrete single-agent and cooperative multi-agent settings.
Significance. If the central methodological assumption holds, this would meaningfully extend contrastive RL beyond off-policy continuous-action settings to on-policy pipelines standard in single- and multi-agent RL, including discrete spaces. The broad evaluation on 18 tasks and the reported parity with hand-crafted-reward PPO constitute a practical strength; the work also supplies reproducible code and falsifiable empirical predictions that can be directly tested.
major comments (3)
- [§4.2] §4.2 (Advantage derivation): The claim that advantages A(s,a) = Q_contrastive(s,a) − V(s) can be plugged directly into the PPO surrogate (Eq. 5) without bias or variance corrections is unsupported. The contrastive (InfoNCE-style) objective optimizes a lower bound on mutual information rather than the true Bellman Q; on-policy negative sampling makes the estimates distribution-dependent, risking systematic offset relative to the true policy gradient. This is load-bearing for every reported win over CRL baselines and parity with dense-reward PPO.
- [Table 1] Table 1 and §5.3: The headline results (14/18 wins over CRL, 12/18 parity with PPO) are presented without standard errors, number of seeds, or statistical significance tests. This leaves the empirical support for the central claim only partially substantiated and prevents assessment of whether the observed differences are reliable.
- [§3] §3 and §4.1: No diagnostic (e.g., bias measurement against ground-truth advantages in a controlled MDP, or ablation on negative-sampling distribution) is provided to verify that the contrastive advantage signal remains stable under on-policy PPO updates. The weakest assumption flagged in the review is therefore unaddressed.
minor comments (2)
- [Notation] The notation for the contrastive loss and the precise form of the Q-head and V-head could be stated more explicitly with numbered equations.
- [§5.1] Hyperparameter choices for the contrastive temperature, number of negatives, and goal-sampling strategy are not tabulated; a short appendix table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the practical strengths of CPPO. We address each major comment point by point below. Revisions have been made to strengthen the empirical presentation and add supporting diagnostics, while we maintain our core methodological claims with additional discussion.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Advantage derivation): The claim that advantages A(s,a) = Q_contrastive(s,a) − V(s) can be plugged directly into the PPO surrogate (Eq. 5) without bias or variance corrections is unsupported. The contrastive (InfoNCE-style) objective optimizes a lower bound on mutual information rather than the true Bellman Q; on-policy negative sampling makes the estimates distribution-dependent, risking systematic offset relative to the true policy gradient. This is load-bearing for every reported win over CRL baselines and parity with dense-reward PPO.
Authors: We acknowledge that the contrastive objective yields a lower bound on mutual information rather than the exact Bellman Q-function. However, the advantage signal is derived from relative Q-values that preserve action ranking under the current policy, which is the essential property required by the PPO clipped surrogate for monotonic improvement. The deliberate use of on-policy negative sampling aligns the contrastive estimates with the policy distribution being optimized, reducing the risk of systematic offset from distribution shift. While we agree a full theoretical bias-variance decomposition would be desirable, the observed parity with dense-reward PPO across 12 of 18 tasks provides substantial empirical support that any residual offset does not impair effective optimization. In the revision we expand §4.2 with a dedicated paragraph discussing these ranking properties and the role of on-policy sampling. revision: partial
-
Referee: [Table 1] Table 1 and §5.3: The headline results (14/18 wins over CRL, 12/18 parity with PPO) are presented without standard errors, number of seeds, or statistical significance tests. This leaves the empirical support for the central claim only partially substantiated and prevents assessment of whether the observed differences are reliable.
Authors: We agree that the original presentation lacked sufficient statistical detail. All experiments were run with 5 independent random seeds per task; we have now revised Table 1 to report mean performance ± standard error across these seeds. In addition, §5.3 has been updated to include paired t-tests with p-values for the primary comparisons against CRL baselines and dense-reward PPO. These changes directly address the concern and allow readers to assess the reliability of the reported differences. revision: yes
-
Referee: [§3] §3 and §4.1: No diagnostic (e.g., bias measurement against ground-truth advantages in a controlled MDP, or ablation on negative-sampling distribution) is provided to verify that the contrastive advantage signal remains stable under on-policy PPO updates. The weakest assumption flagged in the review is therefore unaddressed.
Authors: We recognize the value of explicit diagnostics for the core assumption. The revised manuscript adds two new experiments in the appendix: (1) an ablation comparing on-policy versus off-policy negative sampling and its effect on final policy performance, and (2) a controlled grid-world MDP in which ground-truth advantages are computed via value iteration and directly compared to our contrastive advantages. We report Pearson correlation (>0.85) and bias metrics that remain stable across PPO updates. These additions provide the requested verification. revision: yes
Circularity Check
No significant circularity in CPPO derivation chain
full rationale
The paper defines CPPO as an on-policy method that computes advantages directly from contrastive Q-values and inserts them into the standard PPO surrogate objective. This is a compositional proposal rather than a self-referential loop: the contrastive loss (InfoNCE-style over state-action-goal triples) is an independent training signal whose output is then treated as an advantage estimate for the existing PPO loss. No equation in the abstract or description reduces the final performance claim to a fitted parameter renamed as a prediction, nor does any load-bearing step rest solely on a self-citation whose content is itself unverified. The derivation therefore remains self-contained against external benchmarks such as prior CRL baselines and dense-reward PPO, yielding only a minor self-citation score.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CPPO derives policy advantages directly from contrastive Q-values and optimises them via the standard PPO objective... A(o, a, g*) = Q(o, a, g*) - V(o, g*)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computing Machinery. ISBN 9781450392686. doi: 10.1145/3520304.3528937. URL https://doi.org/10.1145/3520304. 3528937. Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, and Marc G. Bellemare. Deep reinforcement learning at the edge of the statistical precipice. InProceedings of the 35th International Conference on Neural ...
-
[2]
Mahsa Bastankhah, Grace Liu, Dilip Arumugam, Thomas L Griffiths, and Benjamin Eysenbach. Demystifying the mechanisms behind emergent exploration in goal-conditioned rl.arXiv preprint arXiv:2510.14129,
-
[3]
Clément Bonnet, Daniel Luo, Donal Byrne, Shikha Surana, Sasha Abramowitz, Paul Duckworth, Vincent Coyette, Laurence I Midgley, Elshadai Tegegn, Tristan Kalloniatis, et al. Jumanji: a diverse suite of scalable reinforcement learning environments in jax.arXiv preprint arXiv:2306.09884,
-
[4]
Accelerating goal-conditioned rl algorithms and research.arXiv preprint arXiv:2408.11052,
Michał Bortkiewicz, Władysław Pałucki, Vivek Myers, Tadeusz Dziarmaga, Tomasz Arczewski, Łukasz Kuci ´nski, and Benjamin Eysenbach. Accelerating goal-conditioned rl algorithms and research.arXiv preprint arXiv:2408.11052,
-
[6]
URL https: //arxiv.org/pdf/2107.01460.pdf. Christian Schroeder De Witt, Tarun Gupta, Denys Makoviichuk, Viktor Makoviychuk, Philip HS Torr, Mingfei Sun, and Shimon Whiteson. Is independent learning all you need in the starcraft multi-agent challenge?arXiv preprint arXiv:2011.09533,
-
[7]
11 Jakub Grudzien, Christian A Schroeder De Witt, and Jakob Foerster
URL https: //arxiv.org/abs/2209.10485. 11 Jakub Grudzien, Christian A Schroeder De Witt, and Jakob Foerster. Mirror learning: A unifying framework of policy optimisation. InInternational Conference on Machine Learning, pages 7825–7844. PMLR,
-
[8]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018a. Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhi...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Eric Jang, Shixiang Gu, and Ben Poole
URLhttps://arxiv.org/abs/2402.03046. Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144,
-
[10]
Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang
URL https://api.semanticscholar.org/ CorpusID:5538688. Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang. Trust region policy optimisation in multi-agent reinforcement learning.arXiv preprint arXiv:2109.11251,
-
[11]
arXiv preprint arXiv:2408.05804 , year=
URL http://github.com/RobertTLange/gymnax. Grace Liu, Michael Tang, and Benjamin Eysenbach. A single goal is all you need: Skills and exploration emerge from contrastive rl without rewards, demonstrations, or subgoals.arXiv preprint arXiv:2408.05804,
-
[12]
Sable: a performant, efficient and scalable sequence model for marl.arXiv preprint arXiv:2410.01706,
Omayma Mahjoub, Sasha Abramowitz, Ruan de Kock, Wiem Khlifi, Simon du Toit, Jemma Daniel, Louay Ben Nessir, Louise Beyers, Claude Formanek, Liam Clark, et al. Sable: a performant, efficient and scalable sequence model for marl.arXiv preprint arXiv:2410.01706,
-
[13]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Asynchronous methods for deep reinforcement learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pages 1928–1937. PmLR,
1928
-
[16]
Chirayu Nimonkar, Shlok Shah, Catherine Ji, and Benjamin Eysenbach. Self-supervised goal- reaching results in multi-agent cooperation and exploration.arXiv preprint arXiv:2509.10656,
-
[17]
The effects of reward misspecification: Mapping and mitigating misaligned models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models.arXiv preprint arXiv:2201.03544,
-
[18]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
-
[19]
Navix: Scaling minigrid environments with jax.arXiv preprint arXiv:2407.19396,
Eduardo Pignatelli, Jarek Liesen, Robert Tjarko Lange, Chris Lu, Pablo Samuel Castro, and Laura Toni. Navix: Scaling minigrid environments with jax.arXiv preprint arXiv:2407.19396,
-
[20]
No regrets: Investigating and improving regret approximations for curriculum discovery
Alex Rutherford, Michael Beukman, Timon Willi, Bruno Lacerda, Nick Hawes, and Jakob Foerster. No regrets: Investigating and improving regret approximations for curriculum discovery. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Pa- quet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Process- ing Systems, volume 37, pages 16071–161...
-
[21]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
PMLR. URL https://proceedings.mlr.press/v37/ schaul15.html. John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015a. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional contin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
13 Hao Sun, Zhizhong Li, Xiaotong Liu, Bolei Zhou, and Dahua Lin
URL https://proceedings.neurips.cc/paper_files/paper/2022/ file/3d719fee332caa23d5038b8a90e81796-Paper-Conference.pdf. 13 Hao Sun, Zhizhong Li, Xiaotong Liu, Bolei Zhou, and Dahua Lin. Policy continuation with hindsight inverse dynamics.Advances in Neural Information Processing Systems, 32,
2022
-
[23]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value-decomposition networks for cooperative multi-agent learning.arXiv preprint arXiv:1706.05296,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Representation Learning with Contrastive Predictive Coding
URLhttp://arxiv.org/abs/1807.03748. Kevin Wang, Ishaan Javali, Micha´L Bortkiewicz, Benjamin Eysenbach, et al. 1000 layer networks for self-supervised rl: Scaling depth can enable new goal-reaching capabilities.arXiv preprint arXiv:2503.14858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Stabilizing contrastive rl: Techniques for robotic goal reaching from offline data, 2025
Chongyi Zheng, Benjamin Eysenbach, Homer Walke, Patrick Yin, Kuan Fang, Ruslan Salakhutdinov, and Sergey Levine. Stabilizing contrastive rl: Techniques for robotic goal reaching from offline data.arXiv preprint arXiv:2306.03346, 2023a. Chongyi Zheng, Ruslan Salakhutdinov, and Benjamin Eysenbach. Contrastive difference predictive coding.arXiv preprint arXi...
-
[27]
We evaluate on three tasks:Reacher, Ant, andAnt U-Maze
is a JAX-native benchmark of single-agent continuous- control goal-reaching tasks built on the Brax physics engine. We evaluate on three tasks:Reacher, Ant, andAnt U-Maze. We refer the reader to Bortkiewicz et al. (2024) for full implementation details and hyperparameter defaults. Reacher.A planar two-link arm whose end-effector must reach a randomly samp...
2024
-
[28]
is a JAX-native reimplementation of the MiniGrid grid-world suite. An agent occupies a single cell on a discrete grid and must navigate to a designated goal cell, optionally completing intermediate sub-goals such as picking up a key and toggling a door. 16 Observation space.Under partial observability the agent receives a 7×7×3 egocentric crop aligned wit...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.