Recognition: no theorem link
Inducing Artificial Uncertainty in Language Models
Pith reviewed 2026-05-14 20:08 UTC · model grok-4.3
The pith
Training probes on artificially induced uncertainty from easy examples improves their detection of genuine uncertainty on hard data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Inducing artificial uncertainty on trivially easy data allows probes trained to detect that signal to recognize and calibrate real uncertainty on hard inputs more effectively than probes trained without such artificial signals, with only minimal impact on performance for easy cases.
What carries the argument
Artificial uncertainty induction on easy data paired with probe training for uncertainty recognition, enabling transfer from synthetic to natural uncertainty patterns.
If this is right
- Uncertainty quantification for language models becomes feasible without needing scarce challenging data at training time.
- Probes maintain high accuracy on simple inputs while improving reliability on difficult ones.
- The method scales as models continue to saturate existing datasets.
- Safety-critical applications gain a practical route to better uncertainty estimates.
Where Pith is reading between the lines
- The same induction technique could extend to other uncertainty quantification approaches beyond linear probes.
- Uncertainty signals may contain transferable structural features that are independent of the specific input difficulty.
- This framework suggests a general strategy for bootstrapping supervision in regimes where natural labels are hard to collect.
Load-bearing premise
The uncertainty patterns created artificially on trivial data share enough structure with natural uncertainty on hard data that probes trained on the former will transfer to the latter.
What would settle it
Running the same probe training on a new held-out set of genuinely hard examples and finding no calibration gain or outright worse performance compared to probes trained without artificial uncertainty would falsify the central claim.
Figures


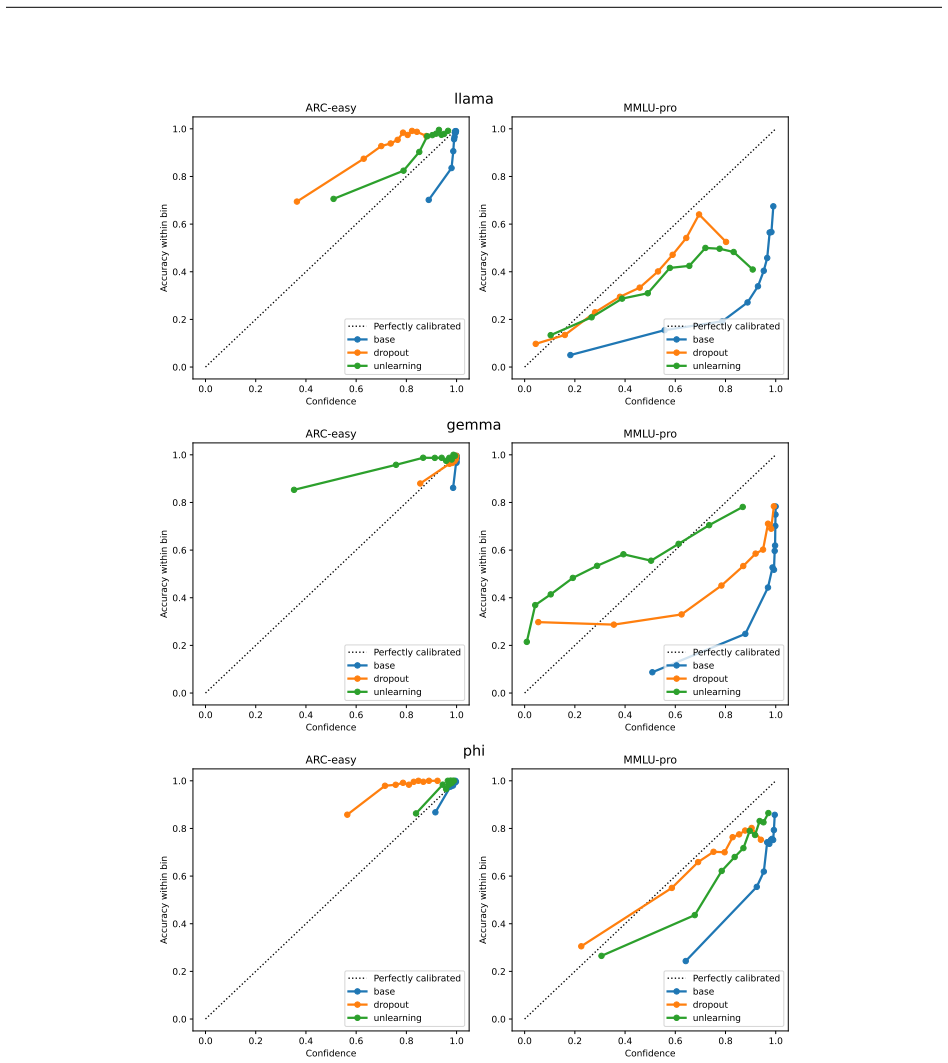

read the original abstract
In safety-critical applications, language models should be able to characterize their uncertainty with meaningful probabilities. Many uncertainty quantification approaches require supervised data; however, finding suitable unseen challenging data is increasingly difficult for large language models trained on vast amounts of scraped data. If the model is consistently (and correctly) confident in its predictions, the uncertainty quantification method may consistently overestimate confidence on new and unfamiliar data. Finding data which exhibits enough uncertainty to train supervised uncertainty quantification methods for high-performance models may therefore be challenging, and will increase in difficulty as LLMs saturate datasets. To address this issue, we first introduce the problem of inducing artificial uncertainty in language models, then investigate methods of inducing artificial uncertainty on trivially easy data in the absence of challenging data at training time. We use probes trained to recognize artificial uncertainty on the original model, and find that these probes trained on artificial uncertainty outperform probes trained without artificial uncertainty in recognizing real uncertainty, achieving notably higher calibration on hard data with minimal loss of performance on easy data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the problem of inducing artificial uncertainty in language models on trivially easy data to enable supervised training of uncertainty quantification probes when challenging data is unavailable. It claims that probes trained to recognize this artificially induced uncertainty outperform probes trained without it when detecting real uncertainty on hard data, yielding notably higher calibration with minimal performance degradation on easy data.
Significance. If the transfer result holds under verification of distributional similarity, the work would be significant for addressing the scalability challenge of obtaining hard data to calibrate increasingly capable LLMs, offering a pathway to reliable uncertainty estimates in safety-critical settings without relying on saturated challenging datasets.
major comments (3)
- [§3.1] §3.1: The induction procedure for artificial uncertainty is described at a high level without equations, pseudocode, or hyperparameter details, preventing assessment of whether the induced logit/hidden-state patterns are distributionally close to natural uncertainty signals on hard inputs.
- [§4.2] §4.2: No quantitative evidence (e.g., uncertainty histograms, KL divergence, or embedding alignment metrics) is provided to support that artificial uncertainty on easy data produces signals similar to real uncertainty on hard data; this similarity is load-bearing for the probe-transfer claim and is not addressed by the reported calibration gains alone.
- [§4.3] §4.3: The experiments lack ablations or controls (e.g., training on random low-confidence labels) to demonstrate that the probe learns uncertainty-specific features rather than a generic low-confidence detector, leaving open the possibility that gains arise from training-data diversity rather than genuine transfer.
minor comments (2)
- [Abstract] Abstract: Specify the exact calibration metrics (e.g., ECE, Brier score) and datasets used to support the 'notably higher calibration' claim.
- [§2] §2: The related-work discussion could reference additional recent LLM uncertainty papers for completeness.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will make the requested revisions to improve reproducibility, provide direct evidence of distributional similarity, and strengthen the experimental controls. These changes will clarify the methodological details without altering the core claims of the work.
read point-by-point responses
-
Referee: [§3.1] §3.1: The induction procedure for artificial uncertainty is described at a high level without equations, pseudocode, or hyperparameter details, preventing assessment of whether the induced logit/hidden-state patterns are distributionally close to natural uncertainty signals on hard inputs.
Authors: We agree that the current description in §3.1 lacks sufficient detail for full reproducibility and direct assessment of distributional closeness. In the revised manuscript we will add the explicit equations governing the logit perturbation and hidden-state modification steps, full pseudocode for the induction algorithm, and the precise hyperparameter settings (including perturbation magnitude, number of samples, and any temperature scaling) used throughout the experiments. This will enable readers to inspect and compare the induced patterns to natural uncertainty signals. revision: yes
-
Referee: [§4.2] §4.2: No quantitative evidence (e.g., uncertainty histograms, KL divergence, or embedding alignment metrics) is provided to support that artificial uncertainty on easy data produces signals similar to real uncertainty on hard data; this similarity is load-bearing for the probe-transfer claim and is not addressed by the reported calibration gains alone.
Authors: We acknowledge that the calibration improvements alone do not constitute direct proof of distributional similarity. In the revision we will augment §4.2 with uncertainty histograms comparing the artificial-uncertainty scores on easy data to the natural-uncertainty scores on hard data, KL-divergence values between the corresponding logit distributions, and cosine-similarity metrics on the probe input embeddings. These quantitative measures will directly support the similarity assumption underlying the transfer result. revision: yes
-
Referee: [§4.3] §4.3: The experiments lack ablations or controls (e.g., training on random low-confidence labels) to demonstrate that the probe learns uncertainty-specific features rather than a generic low-confidence detector, leaving open the possibility that gains arise from training-data diversity rather than genuine transfer.
Authors: This concern is well-taken; an ablation isolating uncertainty-specific learning from generic low-confidence detection or data-diversity effects is needed. We will add a control experiment in which probes are trained on the same easy data but with randomly assigned low-confidence targets (preserving data volume and diversity). The revised results will report the hard-data calibration of this random-label control versus the artificial-uncertainty probes, allowing readers to verify that the observed gains stem from learning genuine uncertainty features rather than from training-data variety alone. revision: yes
Circularity Check
No circularity: empirical probe transfer evaluated on held-out data
full rationale
The paper describes an empirical pipeline that induces artificial uncertainty on trivial inputs, trains probes on the resulting signals, and measures transfer to natural uncertainty on hard inputs via calibration and accuracy metrics. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the provided text; the central result is a comparative experiment whose success is defined externally by probe performance on separate easy/hard splits rather than by construction from the induction procedure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Artificial uncertainty induced on easy data produces patterns sufficiently similar to natural uncertainty on hard data for probe transfer
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2412.08905. Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 967–976, Singapore, December
work page 2023
-
[3]
doi: 10.18653/ v1/2023.findings-emnlp.68
Association for Computational Linguistics. doi: 10.18653/ v1/2023.findings-emnlp.68. URLhttps://aclanthology.org/2023.findings-emnlp.68/. Quentin Bouniot, Pavlo Mozharovskyi, and Florence d’Alché Buc. Tailoring mixup to data for calibration. arXiv preprint arXiv:2311.01434,
-
[4]
doi: 10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2. Khyathi Raghavi Chandu, Linjie Li, Anas Awadalla, Ximing Lu, Jae Sung Park, Jack Hessel, Lijuan Wang, and Yejin Choi. Certainly uncertain: A benchmark and metric for multimodal epistemic and aleatoric awareness.arXiv preprint arXiv:2407.01942,
-
[5]
URLhttps://arxiv.org/abs/2409.12180. 12 Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models,
-
[6]
URLhttps://arxiv.org/abs/2502.11028. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the AI2 reasoning challenge.CoRR, abs/1803.05457,
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
URLhttp://arxiv.org/abs/1803.05457. Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
URLhttps://arxiv.org/abs/1506.02142. Linfeng Gao, Baolong Bi, Zheng Yuan, Le Wang, Zerui Chen, Zhimin Wei, Shenghua Liu, Qinggang Zhang, and Jinsong Su. Probing latent knowledge conflict for faithful retrieval-augmented generation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Beyond Black-Box Interventions: Latent Probing for Faithful Retrieval-Augmented Generation
URL https://arxiv.org/abs/2510.12460. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, et al. The llama 3 herd of models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/2407.21783. Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, pp. 1321–1330. JMLR.org,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DanHendrycks, CollinBurns, StevenBasart, AndyZou, MantasMazeika, DawnSong, andJacobSteinhardt
URLhttps://arxiv.org/abs/2503.14749. DanHendrycks, CollinBurns, StevenBasart, AndyZou, MantasMazeika, DawnSong, andJacobSteinhardt. Measuring massive multitask language understanding.CoRR, abs/2009.03300,
-
[12]
Measuring Massive Multitask Language Understanding
URLhttps:// arxiv.org/abs/2009.03300. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.CoRR, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
URLhttps://arxiv. org/abs/2106.09685. Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Say...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URLhttps://arxiv.org/abs/2310.06825. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Gan- guli, Danny Hernandez, Josh Ja...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Language Models (Mostly) Know What They Know
URL https://arxiv.org/abs/2207.05221. Armen Der Kiureghian and Ove Ditlevsen. Aleatory or epistemic? does it matter?Structural Safety, 31(2):105–112,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
doi: https://doi.org/10.1016/j.strusafe.2008.06.020
ISSN 0167-4730. doi: https://doi.org/10.1016/j.strusafe.2008.06.020. URL https://www.sciencedirect.com/science/article/pii/S0167473008000556. Risk Acceptance and Risk Communication. Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in llms,
-
[17]
URLhttps://arxiv.org/abs/ 2406.15927. Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncer- tainty estimation in natural language generation,
-
[18]
URLhttps://arxiv.org/abs/2302.09664. Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncer- tainty estimation using deep ensembles,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
URLhttps://arxiv.org/abs/1612.01474. 13 Danny D. Leybzon and Corentin Kervadec. Learning, forgetting, remembering: Insights from tracking LLM memorization during training. In Yonatan Belinkov, Najoung Kim, Jaap Jumelet, Hosein Mohebbi, Aaron Mueller, and Hanjie Chen (eds.),Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Netw...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
doi: 10.18653/v1/2024.blackboxnlp-1.4
Association for Computational Linguistics. doi: 10.18653/v1/2024.blackboxnlp-1.4. URLhttps://aclanthology.org/ 2024.blackboxnlp-1.4/. Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann- KathrinDombrowski, ShashwatGoel, LongPhan, GabrielMukobi, NathanHelm-Burger, RassinLababidi, Lennart Justen, Andrew B. L...
-
[21]
URLhttps://arxiv. org/abs/2403.03218. Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. Uncertainty quantification and confidence calibration in large language models: A survey,
-
[22]
Putra Manggala, Atalanti A Mastakouri, Elke Kirschbaum, Shiva Kasiviswanathan, and Aaditya Ramdas
URLhttps://arxiv.org/abs/ 2503.15850. Putra Manggala, Atalanti A Mastakouri, Elke Kirschbaum, Shiva Kasiviswanathan, and Aaditya Ramdas. Qa-calibration of language model confidence scores. InThe Thirteenth International Conference on Learn- ing Representations. Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large languag...
-
[23]
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer
URL https://openreview.net/forum?id=aajyHYjjsk. Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. AmbigQA: Answering ambiguous open-domain questions. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.),Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5783–5797, Online, November
work page 2020
-
[24]
doi: 10.18653/v1/2020.emnlp-main.466
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.466. URL https://aclanthology.org/2020.emnlp-main.466/. Taman Narayan, Heinrich Jiang, Sen Zhao, and Sanjiv Kumar. Predicting on the edge: Identifying where a larger model does better,
-
[25]
URLhttps://arxiv.org/abs/2202.07652. Thanh Tam Nguyen, Thanh Trung Huynh, Zhao Ren, Phi Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, and Quoc Viet Hung Nguyen. A survey of machine unlearning,
-
[26]
URLhttps://arxiv.org/abs/ 2209.02299. Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Summer Yue, Alexandr Wang, Dan Hendrycks, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249,
-
[27]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
URLhttps://arxiv.org/abs/2311.12022. GuillaumeSanchez, HongluFan, AlexanderSpangher, EladLevi, PawanSasankaAmmanamanchi, andStella Biderman. Stay on topic with classifier-free guidance,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
URLhttps://arxiv.org/abs/2306.17806. Thanveer Shaik, Xiaohui Tao, Haoran Xie, Lin Li, Xiaofeng Zhu, and Qing Li. Exploring the landscape of machine unlearning: A comprehensive survey and taxonomy.IEEE Transactions on Neural Networks and Learning Systems, pp. 1–21,
-
[29]
doi: 10.1109/TNNLS.2024.3486109. 14 Maohao Shen, Subhro Das, Kristjan Greenewald, Prasanna Sattigeri, Gregory Wornell, and Soumya Ghosh. Thermometer: Towards universal calibration for large language models. InProceedings of the 41st Inter- national Conference on Machine Learning,
-
[30]
Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, and Shauli Ravfogel
URLhttps://arxiv.org/abs/2403.08819. Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, and Shauli Ravfogel. The curious case of hallucinatory (un)answerability: Finding truths in the hidden states of over-confident large language models,
-
[31]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov
URLhttps://arxiv.org/abs/2310.11877. Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting.Journal of Machine Learning Research, 15(56): 1929–1958,
-
[32]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant
URLhttp://jmlr.org/papers/v15/srivastava14a.html. Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.),Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational...
work page 2019
-
[33]
doi:10.18653/v1/N19-1421 , pages =
Association for Computational Linguistics. doi: 10.18653/v1/N19-1421. URLhttps://aclanthology.org/N19-1421/. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edou...
-
[34]
URLhttps://arxiv.org/abs/2503.19786. 15 Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D. Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
URLhttps://arxiv.org/abs/2305.14975. Cheng Wang. Calibration in deep learning: A survey of the state-of-the-art,
-
[36]
URLhttps://arxiv. org/abs/2308.01222. Peiqi Wang, Barbara D Lam, Yingcheng Liu, Ameneh Asgari-Targhi, Rameswar Panda, William M Wells, Tina Kapur, and Polina Golland. Calibrating expressions of certainty.arXiv preprint arXiv:2410.04315, 2024a. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan ...
-
[37]
URLhttps://arxiv. org/abs/2510.21531. Johannes Welbl, Nelson F. Liu, and Matt Gardner. Crowdsourcing multiple choice science questions.CoRR, abs/1707.06209,
-
[38]
Crowdsourcing Multiple Choice Science Questions
URLhttp://arxiv.org/abs/1707.06209. Mingqi Wu, Zhihao Zhang, Qiaole Dong, Zhiheng Xi, Jun Zhao, Senjie Jin, Xiaoran Fan, Yuhao Zhou, Huijie Lv, Ming Zhang, Yanwei Fu, Qin Liu, Songyang Zhang, and Qi Zhang. Reasoning or memorization? unreliable results of reinforcement learning due to data contamination,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
URLhttps://arxiv.org/ abs/2507.10532. Johnathan Xie, Annie S. Chen, Yoonho Lee, Eric Mitchell, and Chelsea Finn. Calibrating language models with adaptive temperature scaling. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
-
[40]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi
URLhttps://arxiv.org/abs/2409.19817. Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. InThe Twelfth International Conference on Learning Representations,
-
[41]
URLhttps://arxiv.org/abs/2404.05868. Kairan Zhao, Meghdad Kurmanji, George-Octavian Bărbulescu, Eleni Triantafillou, and Peter Triantafillou. What makes unlearning hard and what to do about it,
-
[42]
URLhttps://arxiv.org/abs/2406.01257. A Other unlearning methods We perform initial experiments with several alternate methods of unlearning. A.1 NPO Unlike direct gradient ascent,Negative Preference Optimization(NPO) defines forgetting relative to a frozen referencemodel. Ratherthandirectlyincreasinglossontheforgetset, NPOpenalizesthecurrentmodelwhen it a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.