Recognition: unknown
How to Interpret Agent Behavior
Pith reviewed 2026-05-14 18:19 UTC · model grok-4.3
The pith
ACTONOMY taxonomy structures agent behavior into 10 actions and 120 categories for consistent interpretation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
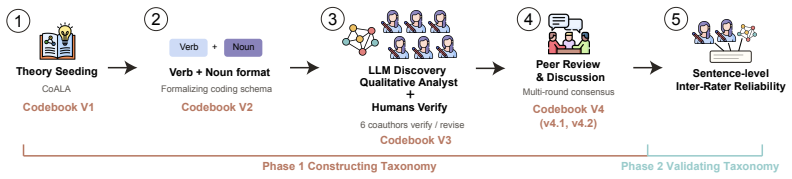
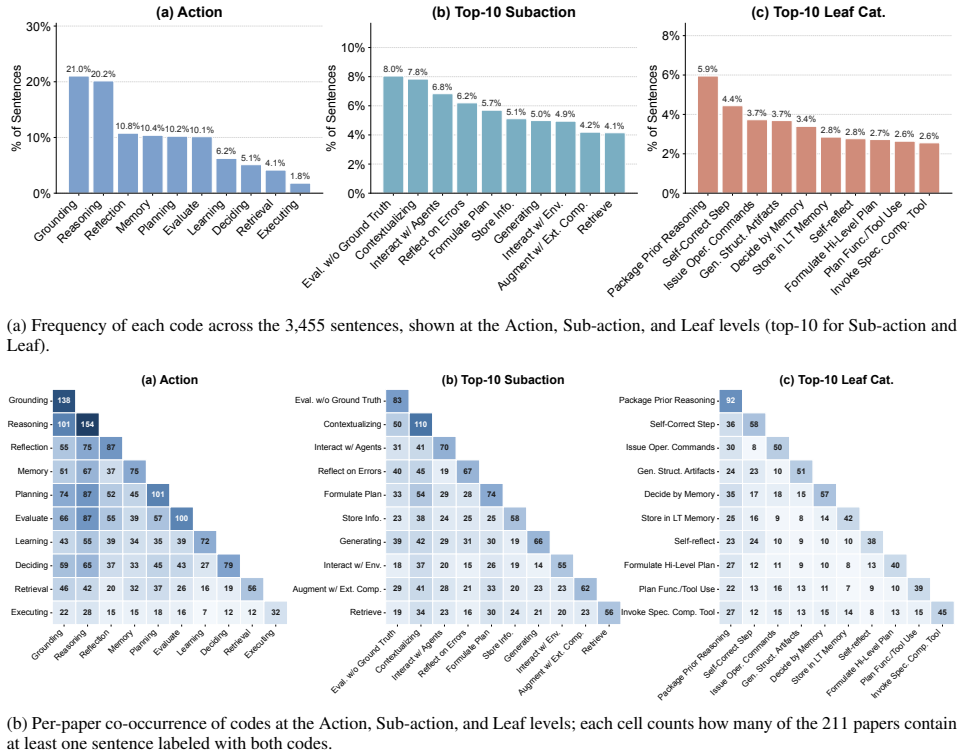
ACTONOMY is a taxonomy developed through Grounded Theory with a three-level hierarchy consisting of 10 actions, 46 subactions, and 120 leaf categories. Paired with an open repository and automated analysis pipeline, it enables systematic description of agent trajectories. The taxonomy supports comparing behavioral profiles across agents and characterizing a single agent's behavior over diverse trajectories to surface patterns linked to failure modes.
What carries the argument
The ACTONOMY taxonomy, a three-level hierarchy of agent actions developed via Grounded Theory, that provides standardized categories for interpreting unstructured natural-language trajectories.
Load-bearing premise
A taxonomy created from Grounded Theory on a limited set of agent traces will stay comprehensive and unbiased for new agents, tasks, and longer trajectories.
What would settle it
If new agent trajectories require introducing many categories outside the existing 120 and beyond what the extension protocol can handle without major revision, the claim of broad applicability would be falsified.
Figures







read the original abstract
Autonomous agents such as Claude Code and Codex now operate for hours or even days. Understanding their runtime behavior has become critical for downstream tasks such as diagnosing inefficiencies, fixing bugs, and ensuring better oversight. A primary way to gain this understanding is analyzing the reasoning trajectories and execution traces these agents generate. Yet such data remains in unstructured natural-language form, making it difficult for humans to interpret at scale. We introduce ACT*ONOMY (a combination of Action and Taxonomy), a taxonomy for describing and analyzing agent behavior at runtime. ACT*ONOMY has two components: (1) the taxonomy itself, developed through Grounded Theory and structured as a three-level hierarchy of 10 actions, 46 subactions, and 120 leaf categories; and (2) an open repository that hosts the living taxonomy, provides an automated analysis pipeline that applies it to agent trajectories analysis, and defines an extension protocol for customization and growth. Our experiments show that ACTONOMY can compare behavioral profiles across agents and characterize a single agent's behavior across diverse trajectories, surfacing patterns indicative of failure modes. By providing a shared vocabulary, ACT*ONOMY helps researchers, agent designers, and end users interpret agent behavior more consistently, enabling better oversight and control.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity; taxonomy is inductively derived
full rationale
The paper's central contribution is a taxonomy (ACTONOMY) constructed bottom-up via Grounded Theory from a set of agent traces, yielding a fixed three-level hierarchy of 10 actions, 46 subactions, and 120 leaf categories. This inductive process does not invoke fitted parameters, self-referential equations, uniqueness theorems, or self-citations as load-bearing premises. The subsequent experiments apply the resulting taxonomy to new trajectories for profiling and failure-mode detection, but the taxonomy itself is not defined in terms of those outputs; the derivation chain remains independent and externally falsifiable against additional traces. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent runtime behavior can be decomposed into a finite, hierarchical set of actions and subactions that are observable in natural-language trajectories.
Reference graph
Works this paper leans on
-
[1]
J. R. Anderson and C. Lebiere. The newell test for a theory of cognition.Behavioral and brain Sciences, 26(5):587–601, 2003
2003
-
[2]
Zhan, Q., Fang, R., Panchal, H
Y . Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, Mar. 2022. doi: 10.1162/coli a 00422. URLhttps: //aclanthology.org/2022.cl-1.7/
-
[3]
V . P. Bhardwaj. Agentassay: Token-efficient regression testing for non-deterministic ai agent workflows, 2026. URLhttps://zenodo.org/doi/10.5281/zenodo.18842011
-
[4]
S. R. Bowman, J. Hyun, E. Perez, E. Chen, C. Pettit, S. Heiner, K. Luko ˇsi¯ut˙e, A. Askell, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, C. Olah, D. Amodei, D. Amodei, D. Drain, D. Li, E. Tran-Johnson, J. Kernion, J. Kerr, J. Mueller, J. Ladish, J. Landau, K. Ndousse, L. Lovitt, N. Elhage, N. Schiefer, N. Joseph, N. Mercado, N. DasSarma, R. ...
-
[5]
Braun and V
V . Braun and V . Clarke. Using thematic analysis in psychology.Qualitative research in psy- chology, 3(2):77–101, 2006
2006
-
[6]
Why Do Multi-Agent LLM Systems Fail?
M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ramchandran, M. Zaharia, J. E. Gonzalez, and I. Stoica. Why do multi-agent llm systems fail?, 2025. URLhttps://arxiv.org/abs/2503.13657
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Charmaz.Constructing grounded theory: A practical guide through qualitative analysis
K. Charmaz.Constructing grounded theory: A practical guide through qualitative analysis. sage, 2006
2006
-
[8]
K. Charmaz. Grounded theory.Qualitative psychology: A practical guide to research methods, 3(2015):53–84, 2015
2015
- [9]
-
[10]
Clarke and V
V . Clarke and V . Braun. Thematic analysis.The journal of positive psychology, 12(3):297–298, 2017
2017
-
[11]
org/posts/baJyjpktzmcmRfosq/ stitching-saes-of-different-sizes
A. Conmy, A. N. Mavor-Parker, A. Lynch, S. Heimersheim, and A. Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability, 2023. URLhttps://arxiv.or g/abs/2304.14997
-
[12]
Cunningham, A
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey. Sparse autoencoders find highly interpretable features in language models, 2023. URLhttps://arxiv.org/abs/23 09.08600
2023
-
[13]
Deshpande, V
D. Deshpande, V . Gangal, H. Mehta, J. Krishnan, A. Kannappan, and R. Qian. Trail: Trace reasoning and agentic issue localization, 2025. URLhttps://arxiv.org/abs/2505.086 38
2025
-
[14]
Desmond, J
M. Desmond, J. Y . Lee, I. Ibrahim, J. M. Johnson, A. Sil, J. MacNair, and R. Puri. Agent trajectory explorer: Visualizing and providing feedback on agent trajectories. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 29634–29636, 2025
2025
-
[15]
T. Fischer and C. Biemann. Exploring large language models for qualitative data analysis. In M. H ¨am¨al¨ainen, E. ¨Ohman, S. Miyagawa, K. Alnajjar, and Y . Bizzoni, editors,Proceedings of the 4th International Conference on Natural Language Processing for Digital Humanities, pages 423–437, Miami, USA, Nov. 2024. Association for Computational Linguistics....
-
[16]
J. Gao, Y . Guo, G. Lim, T. Zhang, Z. Zhang, T. J.-J. Li, and S. T. Perrault. Collabcoder: a lower-barrier, rigorous workflow for inductive collaborative qualitative analysis with large language models. InProceedings of the 2024 CHI conference on human factors in computing systems, pages 1–29, 2024
2024
- [17]
- [18]
-
[19]
F. Jia, Z. Ye, S. Lai, K. Shu, J. Gu, A. Bibi, Z. Hu, D. Jurgens, J. Evans, P. H. Torr, et al. Can large language model agents simulate human trust behavior?Advances in neural information processing systems, 37:15674–15729, 2024
2024
-
[20]
MedVR: Annotation-Free Medical Visual Reasoning via Agentic Reinforcement Learning
Z. Jiang, H. Guo, C. Fang, C. Xiao, X. Hu, L. Sun, and M. Xu. Medvr: Annotation-free medical visual reasoning via agentic reinforcement learning, 2026. URLhttps://arxiv.or g/abs/2604.08203
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learn- ing Representations, volume 2024, pages 54107–54157, 2024
2024
-
[22]
Siegel, Nitya Nadgir, and Arvind Narayanan
S. Kapoor and A. Narayanan. Ai agents that matter.arXiv preprint arXiv:2407.01502, 2024
-
[23]
T. Kwa, B. West, J. Becker, A. Deng, K. Garcia, M. Hasin, S. Jawhar, M. Kinniment, N. Rush, S. V . Arx, R. Bloom, T. Broadley, H. Du, B. Goodrich, N. Jurkovic, L. H. Miles, S. Nix, T. Lin, N. Parikh, D. Rein, L. J. K. Sato, H. Wijk, D. M. Ziegler, E. Barnes, and L. Chan. Measuring ai ability to complete long software tasks, 2026. URLhttps://arxiv.org/abs/...
-
[24]
K. Li, J. Shi, Y . Xiao, M. Jiang, J. Sun, Y . Wu, D. Fu, S. Xia, X. Cai, T. Xu, et al. Agencybench: Benchmarking the frontiers of autonomous agents in 1m-token real-world contexts.arXiv preprint arXiv:2601.11044, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
R. Li, J. Xiong, X. He, J. Zhao, J. Lv, H. Fang, L. Qi, and X. Wang. Chathls: Towards systematic design automation and optimization for high-level synthesis, 2026. URLhttps: //arxiv.org/abs/2507.00642
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [26]
-
[27]
J. Liao, Y . Feng, Y . Zheng, J. Zhao, S. Wang, and J. Zheng. My words imply your opinion: Reader agent-based propagation enhancement for personalized implicit emotion analysis. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16156–16172, 2025
2025
-
[28]
J. Liu, C. Huang, Z. Guan, W. Lei, and Y . Deng. E2edev: Benchmarking large language models in end-to-end software development task, 2025
2025
-
[29]
W. Liu, S. An, J. Lu, M. Wu, T. Li, X. Wang, C. Lv, X. Zheng, D. Yin, X. Sun, and X. Huang. Tell me what you don’t know: Enhancing refusal capabilities of role-playing agents via representation space analysis and editing. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pag...
-
[30]
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yang, et al. Agent- bench: Evaluating llms as agents. InInternational Conference on Learning Representations, volume 2024, pages 52989–53046, 2024. 11
2024
-
[31]
C. Lu, C. Lu, R. T. Lange, J. Foerster, J. Clune, and D. Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URLhttps://arxiv.org/abs/2408.0 6292
2024
-
[32]
C. Ma, J. Zhang, Z. Zhu, C. Yang, Y . Yang, Y . Jin, Z. Lan, L. Kong, and J. He. Agent- board: An analytical evaluation board of multi-turn llm agents. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Infor- mation Processing Systems, volume 37, pages 74325–74362. Curran Associates, Inc., 202...
- [33]
-
[34]
arXiv preprint arXiv:2502.04358 , year=
E. Meyerson and X. Qiu. Position: Scaling llm agents requires asymptotic analysis with llm primitives, 2025. URLhttps://arxiv.org/abs/2502.04358
-
[35]
Newell.Unified theories of cognition
A. Newell.Unified theories of cognition. Harvard University Press, 1994
1994
- [36]
-
[37]
A. Parfenova, A. Marfurt, J. Pfeffer, and A. Denzler. Text annotation via inductive coding: Comparing human experts to LLMs in qualitative data analysis. In L. Chiruzzo, A. Ritter, and L. Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, pages 6471–6484, Albuquerque, New Mexico, Apr. 2025. Association for Computational L...
-
[38]
D. Paul, D. Murphy, M. Gritta, R. Cardenas, V . Prokhorov, L. S. Bolliger, A. Toker, R. Miles, A.-M. Oncescu, J. A. Sivakumar, P. Borchert, I. Elezi, M. Zhang, K. Y . Lee, G. Zhang, J. Wang, and G. Lampouras. A benchmark for deep information synthesis, 2026. URLhttps://arxi v.org/abs/2602.21143
-
[39]
H. N. Phan, T. N. Nguyen, P. X. Nguyen, and N. D. Q. Bui. Hyperagent: Generalist software engineering agents to solve coding tasks at scale, 2025. URLhttps://arxiv.org/abs/24 09.16299
2025
-
[40]
C. Qin, X. Feng, W. Ma, X. Feng, and L. Kong. Implicitmembench: Measuring unconscious behavioral adaptation in large language models, 2026. URLhttps://arxiv.org/abs/26 04.08064
2026
-
[41]
I. Rahwan, M. Cebrian, N. Obradovich, J. Bongard, J.-F. Bonnefon, C. Breazeal, J. W. Cran- dall, N. A. Christakis, I. D. Couzin, M. O. Jackson, N. R. Jennings, E. Kamar, I. M. Kloumann, H. Larochelle, D. Lazer, R. McElreath, A. Mislove, D. C. Parkes, A. S. Pentland, M. E. Roberts, A. Shariff, J. B. Tenenbaum, and M. Wellman. Machine behaviour.Nature, 568 ...
- [42]
- [43]
- [44]
-
[45]
H. Shi, Z. Sun, X. Yuan, M.-A. C ˆot´e, and B. Liu. OPEx: A component-wise analysis of LLM-centric agents in embodied instruction following. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 622–636, Bangkok, Thailand, Aug
-
[46]
doi: 10.18653/v1/2024.acl-long.37
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.37. URL https://aclanthology.org/2024.acl-long.37/. 12
-
[47]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36, 2023
2023
-
[48]
Y . Song, D. Yin, X. Yue, J. Huang, S. Li, and B. Y . Lin. Trial and error: Exploration-based trajectory optimization of LLM agents. In L.-W. Ku, A. Martins, and V . Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7584–7600, Bangkok, Thailand, Aug. 2024. Association ...
-
[49]
K. Sreedhar and L. Chilton. Simulating human strategic behavior: Comparing single and multi-agent llms. 2024. URLhttps://arxiv.org/abs/2402.08189
- [50]
-
[51]
Triantafyllou, A
S. Triantafyllou, A. Sukovic, D. Mandal, and G. Radanovic. Agent-specific effects: A causal effect propagation analysis in multi-agent mdps, 2024. URLhttps://arxiv.org/abs/23 10.11334
2024
-
[52]
Vernon, C
D. Vernon, C. von Hofsten, and L. Fadiga. Desiderata for developmental cognitive architec- tures.Biologically Inspired Cognitive Architectures, 18:116–127, 2016
2016
-
[53]
K. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small, 2022. URLhttps://arxiv.org/ abs/2211.00593
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig. Openhands: An open platform for ai software developers as generalist agents, 2025. URLhttps://arxiv.org/abs/2407.16741
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Y . Wang, R. Xu, K. Zheng, T. Zhang, J. N. Kogundi, S. Hans, and V . Ustun. Gameplayqa: A benchmarking framework for decision-dense pov-synced multi-video understanding of 3d virtual agents, 2026. URLhttps://arxiv.org/abs/2603.24329
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation, 2023. URLhttps://arxiv.org/abs/2308.081 55
2023
- [57]
-
[58]
Y .-A. Xiao, P. Gao, C. Peng, and Y . Xiong. Reducing cost of llm agents with trajectory reduc- tion. 2026. doi: https://doi.org/10.1145/3797084. URLhttps://arxiv.org/abs/2509.2 3586
-
[59]
H. Yang, J. Liu, C. Huang, F. Wu, W. Lei, and S.-K. Ng. Metro: Towards strategy induction from expert dialogue transcripts for non-collaborative dialogues, 2026. URLhttps://arxi v.org/abs/2604.11427
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe- agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[61]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [62]
- [63]
-
[64]
WebArena: A Realistic Web Environment for Building Autonomous Agents
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 14 Contents A Limitations 16 B Broader Impacts 16 C Corpus and Annotation Details 16 D Discovery Qualitative Analyst 17 E Codebook Evolution 18 F Larg...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.