Recognition: unknown
FlowCompile: An Optimizing Compiler for Structured LLM Workflows
Pith reviewed 2026-05-14 19:44 UTC · model grok-4.3
The pith
FlowCompile optimizes structured LLM workflows by profiling sub-agents at compile time and composing estimates into reusable configuration sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowCompile decomposes a workflow into sub-agents, profiles each under diverse configurations, and composes the measurements through a structure-aware proxy to identify a reusable set of workflow-level configurations that balance accuracy and latency without retraining or online adaptation.
What carries the argument
The structure-aware proxy that composes individual sub-agent measurements into estimates of full workflow accuracy and latency.
If this is right
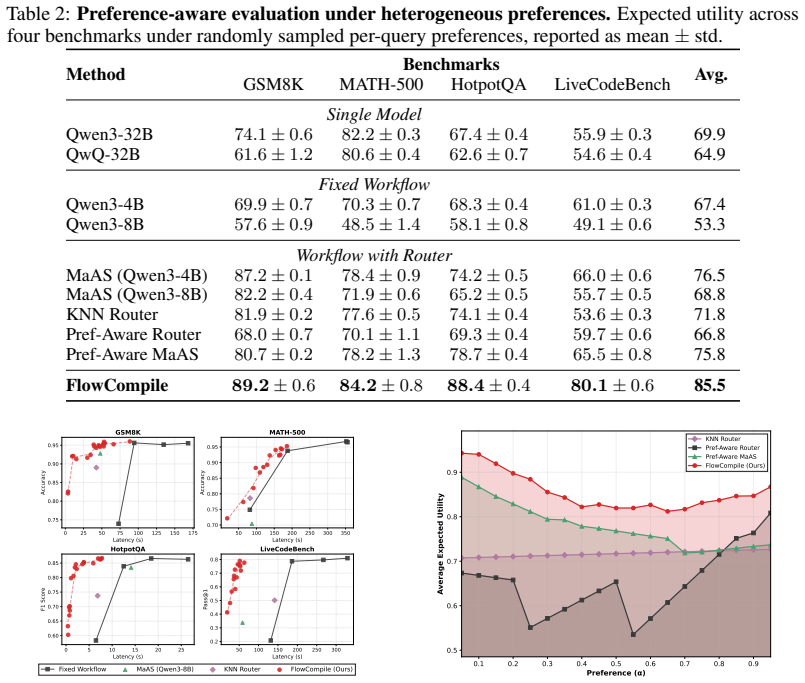
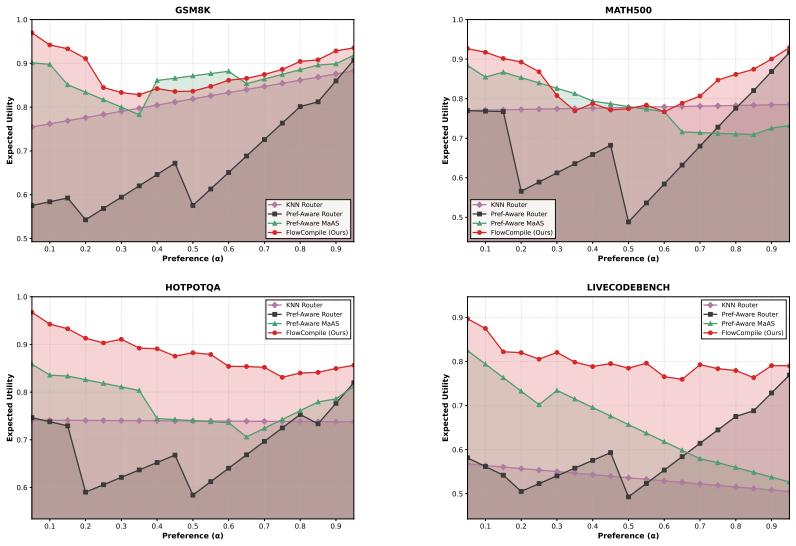
- Compiled configuration sets deliver up to 6.4 times speedup over heuristic and routing baselines on diverse workflows and benchmarks.
- A single compile-time pass produces reusable artifacts that support flexible deployment under changing accuracy or latency preferences.
- Downstream systems can select or route among the precomputed configurations without additional training.
Where Pith is reading between the lines
- The same decompose-profile-compose pattern could apply to other structured AI systems whose performance composes across modules.
- If the proxy generalizes across workflow graphs, repeated recompilation might become unnecessary for modest structural changes.
- The method trades compile-time compute for reduced inference-time overhead, shifting cost from runtime to deployment preparation.
Load-bearing premise
The structure-aware proxy can accurately estimate full workflow accuracy and latency by composing sub-agent measurements without executing the complete workflow.
What would settle it
Measure actual accuracy and latency of the compiled configurations on held-out queries; systematic gaps larger than the reported margins between proxy estimates and real runs would falsify the central claim.
Figures








read the original abstract
Structured LLM workflows, where specialized LLM sub-agents execute according to a predefined graph, have become a powerful abstraction for solving complex tasks. Optimizing such workflows, i.e., selecting configurations for each sub-agent to balance accuracy and latency, is challenging due to the combinatorial design space over model choices, reasoning budgets, and workflow structures. Existing cost-aware methods largely treat workflow optimization as a routing problem, selecting a configuration at inference time for each query according to the accuracy-latency objective used during training. We argue that structured LLM workflows can also be optimized from a compilation perspective: before deployment, the system can globally explore the workflow design space and construct a reusable set of workflow-level configurations spanning diverse accuracy-latency trade-offs. Drawing inspiration from machine learning compilers, we introduce FlowCompile, a structured LLM workflow compiler that performs compile-time design space exploration to identify a high-quality, reusable trade-off set. FlowCompile decomposes a workflow into sub-agents, profiles each sub-agent under diverse configurations, and composes these measurements through a structure-aware proxy to estimate workflow-level accuracy and latency. It then identifies diverse high-quality configurations in a single compile-time pass, without retraining or online adaptation. Experiments across diverse workflows and challenging benchmarks show that FlowCompile consistently outperforms heuristically optimized workflow configurations and routing-based baselines, delivering up to 6.4x speedup. The compiled configuration set further serves as a reusable optimization artifact, enabling flexible deployment under varying runtime preferences and supporting downstream selection or routing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowCompile, an optimizing compiler for structured LLM workflows. It decomposes a workflow into sub-agents, profiles each under diverse configurations (model choice, reasoning budget), and composes the measurements via a structure-aware proxy to estimate workflow-level accuracy and latency. A single compile-time search then produces a reusable set of high-quality configurations spanning accuracy-latency trade-offs. Experiments claim consistent outperformance over heuristically optimized workflows and routing baselines, with up to 6.4x speedup.
Significance. If the proxy estimates are shown to be reliable, the compile-time perspective offers a reusable optimization artifact that decouples configuration selection from inference-time routing and supports flexible deployment. This is a distinct angle from existing cost-aware routing methods and could reduce repeated online adaptation costs.
major comments (2)
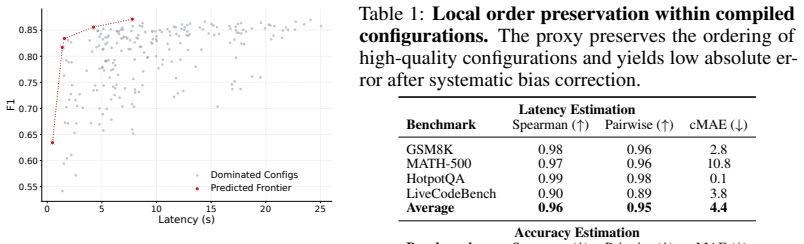
- [Experiments] The central claim (consistent outperformance and up to 6.4x speedup) depends on the proxy correctly ranking configurations, yet no section reports direct validation: there are no correlation coefficients, mean absolute error, or scatter plots comparing proxy-predicted accuracy/latency against actual end-to-end executions on the same configurations.
- [Section 3.2] Section 3.2 describes the structure-aware proxy as composing independent sub-agent profiles, but does not model or bound non-additive interactions (error propagation along workflow edges, context carry-over, or latency non-linearities). Without such modeling or empirical bounds, the proxy's ranking fidelity remains unestablished.
minor comments (2)
- [Abstract] The abstract states 'up to 6.4x speedup' without naming the exact baseline configuration or the operating point (e.g., latency at fixed accuracy).
- Table or figure captions should explicitly state whether reported numbers use proxy estimates or measured full-workflow runs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger validation of the structure-aware proxy. We address each major comment below and will revise the manuscript to incorporate direct empirical validation and explicit discussion of proxy limitations.
read point-by-point responses
-
Referee: [Experiments] The central claim (consistent outperformance and up to 6.4x speedup) depends on the proxy correctly ranking configurations, yet no section reports direct validation: there are no correlation coefficients, mean absolute error, or scatter plots comparing proxy-predicted accuracy/latency against actual end-to-end executions on the same configurations.
Authors: We agree that direct validation of the proxy is essential to substantiate the ranking fidelity underlying our claims. While the reported end-to-end results provide indirect support via consistent outperformance, we acknowledge the absence of explicit proxy-vs-actual metrics in the current manuscript. In the revised version, we will add a new subsection to the Experiments section that reports Pearson and Spearman correlation coefficients, mean absolute error for both accuracy and latency, and scatter plots comparing proxy predictions to actual workflow executions on held-out configuration sets. These additions will empirically confirm the proxy's reliability for the evaluated workflows. revision: yes
-
Referee: [Section 3.2] Section 3.2 describes the structure-aware proxy as composing independent sub-agent profiles, but does not model or bound non-additive interactions (error propagation along workflow edges, context carry-over, or latency non-linearities). Without such modeling or empirical bounds, the proxy's ranking fidelity remains unestablished.
Authors: We acknowledge that Section 3.2 presents the proxy as a structure-aware composition of independent sub-agent profiles without explicitly modeling or bounding non-additive interactions such as error propagation, context carry-over, or latency non-linearities. In the revision, we will extend Section 3.2 with a dedicated paragraph discussing these potential interactions, their impact on proxy assumptions, and empirical bounds derived from the new validation experiments (e.g., observed maximum deviation between proxy and actual measurements). We will also note workflow characteristics where the additive approximation holds and where additional calibration may be needed. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core process decomposes workflows into sub-agents, profiles them independently, composes estimates via a structure-aware proxy, and performs compile-time search for configurations. No equations, fitted parameters, or self-citations reduce the claimed speedups or outperformance to inputs by construction. Experimental results on benchmarks are presented as external validation rather than tautological outputs. The proxy's composition assumption is stated explicitly but does not create definitional equivalence with the final claims.
Axiom & Free-Parameter Ledger
invented entities (1)
-
structure-aware proxy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agent workflow memory , author=. arXiv preprint arXiv:2409.07429 , year=
work page internal anchor Pith review arXiv
-
[2]
arXiv preprint arXiv:2410.10762 , year=
Aflow: Automating agentic workflow generation , author=. arXiv preprint arXiv:2410.10762 , year=
-
[3]
RouteLLM: Learning to Route LLMs with Preference Data
Routellm: Learning to route llms with preference data , author=. arXiv preprint arXiv:2406.18665 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2506.13752 , year=
Steering LLM Thinking with Budget Guidance , author=. arXiv preprint arXiv:2506.13752 , year=
-
[5]
Masrouter: Learning to route llms for multi-agent systems.arXiv preprint arXiv:2502.11133, 2025
Masrouter: Learning to route llms for multi-agent systems , author=. arXiv preprint arXiv:2502.11133 , year=
-
[6]
arXiv preprint arXiv:2511.21572 , year=
BAMAS: Structuring Budget-Aware Multi-Agent Systems , author=. arXiv preprint arXiv:2511.21572 , year=
-
[7]
Journal of the ACM (JACM) , volume=
On finding the maxima of a set of vectors , author=. Journal of the ACM (JACM) , volume=. 1975 , publisher=
1975
-
[8]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[10]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle=
-
[11]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
QwenTeam , month =. QwQ-32B: Embracing the Power of Reinforcement Learning , url =
-
[14]
2025 , howpublished =
LLMRouter: An Open-Source Library for LLM Routing , author =. 2025 , howpublished =
2025
-
[15]
arXiv preprint arXiv:2502.04180 , year=
Multi-agent architecture search via agentic supernet , author=. arXiv preprint arXiv:2502.04180 , year=
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[17]
arXiv preprint arXiv:2410.03834 , year=
Graphrouter: A graph-based router for llm selections , author=. arXiv preprint arXiv:2410.03834 , year=
-
[18]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[19]
M as R outer: Learning to Route LLM s for Multi-Agent Systems
Yue, Yanwei and Zhang, Guibin and Liu, Boyang and Wan, Guancheng and Wang, Kun and Cheng, Dawei and Qi, Yiyan. M as R outer: Learning to Route LLM s for Multi-Agent Systems. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.757
-
[20]
arXiv preprint arXiv:2511.21689 , year=
Toolorchestra: Elevating intelligence via efficient model and tool orchestration , author=. arXiv preprint arXiv:2511.21689 , year=
-
[21]
arXiv preprint arXiv:2103.09568 , year=
A practical guide to multi-objective reinforcement learning and planning , author=. arXiv preprint arXiv:2103.09568 , year=
-
[22]
Advances in neural information processing systems , volume=
A generalized algorithm for multi-objective reinforcement learning and policy adaptation , author=. Advances in neural information processing systems , volume=
-
[23]
Evolutionary computation , volume=
HypE: An algorithm for fast hypervolume-based many-objective optimization , author=. Evolutionary computation , volume=. 2011 , publisher=
2011
-
[24]
arXiv preprint arXiv:2408.08435 , year=
Automated design of agentic systems , author=. arXiv preprint arXiv:2408.08435 , year=
-
[25]
arXiv preprint arXiv:2509.11079 , year=
Difficulty-Aware Agentic Orchestration for Query-Specific Multi-Agent Workflows , author=. arXiv preprint arXiv:2509.11079 , year=
-
[26]
arXiv preprint arXiv:2505.16997 , year=
X-MAS: Towards Building Multi-Agent Systems with Heterogeneous LLMs , author=. arXiv preprint arXiv:2505.16997 , year=
-
[27]
13th USENIX symposium on operating systems design and implementation (OSDI 18) , pages=
\ TVM \ : An automated \ End-to-End \ optimizing compiler for deep learning , author=. 13th USENIX symposium on operating systems design and implementation (OSDI 18) , pages=
-
[28]
arXiv preprint arXiv:2504.07247 , year=
Resource-efficient Inference with Foundation Model Programs , author=. arXiv preprint arXiv:2504.07247 , year=
-
[29]
ICML 2025 Workshop on Collaborative and Federated Agentic Workflows , year=
LLMSELECTOR: Learning to select models in compound ai systems , author=. ICML 2025 Workshop on Collaborative and Federated Agentic Workflows , year=
2025
-
[30]
arXiv preprint arXiv:2501.07834 , year=
Flow: Modularized agentic workflow automation , author=. arXiv preprint arXiv:2501.07834 , year=
-
[31]
arXiv preprint arXiv:2502.07373 , year=
Evoflow: Evolving diverse agentic workflows on the fly , author=. arXiv preprint arXiv:2502.07373 , year=
-
[32]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[33]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[35]
Advances in Neural Information Processing Systems , volume=
Learning to optimize tensor programs , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
14th USENIX symposium on operating systems design and implementation (OSDI 20) , pages=
Ansor: Generating \ High-Performance \ tensor programs for deep learning , author=. 14th USENIX symposium on operating systems design and implementation (OSDI 20) , pages=
-
[37]
Proceedings of the 27th ACM Symposium on Operating Systems Principles , pages=
TASO: optimizing deep learning computation with automatic generation of graph substitutions , author=. Proceedings of the 27th ACM Symposium on Operating Systems Principles , pages=
-
[38]
Proceedings of Machine Learning and Systems , volume=
Equality saturation for tensor graph superoptimization , author=. Proceedings of Machine Learning and Systems , volume=
-
[39]
2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO) , pages=
MLIR: Scaling compiler infrastructure for domain specific computation , author=. 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO) , pages=. 2021 , organization=
2021
-
[40]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[41]
Glow: Graph Lowering Compiler Techniques for Neural Networks
Glow: Graph lowering compiler techniques for neural networks , author=. arXiv preprint arXiv:1805.00907 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
XLA : Compiling Machine Learning for Peak Performance ,author =
-
[43]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Dspy: Compiling declarative language model calls into self-improving pipelines , author=. arXiv preprint arXiv:2310.03714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.