Recognition: unknown
Robot Squid Game: Quadrupedal Locomotion for Traversing Narrow Tunnels
Pith reviewed 2026-05-14 18:16 UTC · model grok-4.3
The pith
Quadruped robots learn to traverse narrow tunnels by distilling specialized policies from procedurally generated environments into one unified policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By synthesizing diverse tunnel structures during training and distilling navigation strategies into a generalizable policy, the method achieves consistent traversal across complex spatial constraints where conventional approaches fail.
What carries the argument
Teacher-student policy distillation in which specialized expert policies trained on procedurally generated tunnel geometries transfer knowledge to a single student policy.
If this is right
- Eliminates the need for complex reward shaping in end-to-end RL training.
- Enables consistent performance across multiple distinct tunnel geometries.
- Supports direct deployment from simulation to physical robots in confined spaces.
- Breaks navigation into smaller subtasks that each expert policy learns more readily.
Where Pith is reading between the lines
- The same procedural-plus-distillation pattern could be applied to other confined locomotion settings such as caves or collapsed structures.
- Reducing manual reward design may shorten the time to field a new robot morphology for inspection tasks.
- Extending the procedural generator with additional parameters like varying friction or lighting could further improve real-world robustness.
Load-bearing premise
Policies trained only on procedurally generated tunnel geometries will transfer directly to real-world tunnel shapes without further adaptation.
What would settle it
Real-world trials in which the distilled student policy fails to complete traversal through tunnels whose cross-sections, curvatures, or obstacle placements fall outside the procedural generation distribution used in training.
Figures


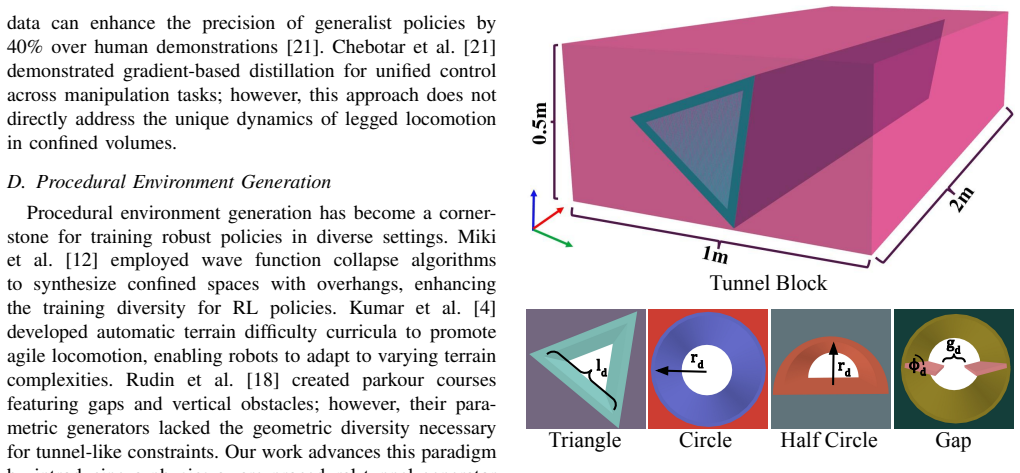




read the original abstract
Quadruped robots demonstrate exceptional potential for navigating complex terrain in critical applications such as search and rescue missions and infrastructure inspection However autonomous traversal of confined 3D environments including tunnels caves and collapsed structures remains a significant challenge Existing methods often struggle with rigid gait patterns limited adaptability to diverse geometries and reliance on oversimplified environmental assumptions This paper introduces a Reinforcement Learning RL framework that combines procedural environment generation with policy distillation to enable robust locomotion across various tunnel configurations Our approach leverages a teacher student training paradigm where specialized expert policies trained on procedurally generated tunnel geometries transfer their knowledge to a unified student policy This strategy eliminates the need for complex reward shaping in end-to-end RL training simplifying the process by breaking down complicated tasks into smaller more manageable components that are easier for the robot to learn By synthesizing diverse tunnel structures during training and distilling navigation strategies into a generalizable policy our method achieves consistent traversal across complex spatial constraints where conventional approaches fail We demonstrate through both simulation and real world experiments that our method enables quadruped robots to successfully traverse challenging confined tunnel environments
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a reinforcement learning framework for quadrupedal locomotion in narrow tunnels that combines procedural generation of diverse tunnel geometries with a teacher-student policy distillation paradigm. Expert policies are trained on procedurally generated environments and distilled into a single student policy, with the claim that this yields a generalizable controller capable of consistent traversal in complex confined spaces. Success is asserted in both simulation and real-world experiments, eliminating the need for complex end-to-end reward shaping.
Significance. If the empirical claims hold, the approach could advance sim-to-real transfer techniques for constrained 3D navigation in robotics, particularly for search-and-rescue and inspection tasks. The procedural diversity plus distillation strategy offers a scalable alternative to hand-crafted rewards or extensive domain randomization, potentially reducing training complexity while improving adaptability to varied tunnel geometries.
major comments (2)
- [Abstract] Abstract: The central claim that the method 'achieves consistent traversal across complex spatial constraints where conventional approaches fail' and succeeds in 'simulation and real world experiments' is unsupported by any quantitative metrics, success rates, traversal times, failure modes, or baseline comparisons. Without these data the empirical contribution cannot be evaluated.
- [Abstract] Abstract and Methods (procedural generation section): The assumption that procedurally generated tunnels adequately span real-world geometric and contact variations (width, curvature, surface irregularities, friction) is load-bearing for the sim-to-real claim, yet no parameter ranges, validation against physical tunnels, or ablation on generation fidelity are provided.
minor comments (1)
- [Abstract] Abstract: Missing punctuation and run-on sentences (e.g., 'inspection However autonomous' and 'missions and infrastructure inspection') impair readability.
Circularity Check
No significant circularity in empirical RL training pipeline
full rationale
The paper presents an RL framework that trains expert policies on procedurally generated tunnels and distills them into a student policy, validated via simulation and real-world experiments. No equations, derivations, or parameter-fitting steps appear that would reduce any claimed result to its inputs by construction. The approach follows standard teacher-student distillation without self-definitional loops, fitted-input predictions, or load-bearing self-citations that collapse the central claim. Experimental outcomes serve as independent evidence rather than tautological restatements of the training procedure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Procedurally generated tunnel geometries are representative of real-world confined environments
Reference graph
Works this paper leans on
-
[1]
Learning to navigate sidewalks in outdoor environments,
M. Sorokin, J. Tan, C. K. Liu, and S. Ha, “Learning to navigate sidewalks in outdoor environments,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3906–3913, 2022
work page 2022
-
[2]
Barkour: Benchmarking animal-level agility with quadruped robots,
K. Caluwaerts, A. Iscen, J. C. Kew, W. Yu, T. Zhang, D. Freeman, K.-H. Lee, L. Lee, S. Saliceti, V . Zhuang, N. Batchelor, S. Bohez, F. Casarini, J. E. Chen, O. Cortes, E. Coumans, A. Dostmohamed, G. Dulac-Arnold, A. Escontrela, E. Frey, R. Hafner, D. Jain, B. Jyenis, Y . Kuang, E. Lee, L. Luu, O. Nachum, K. Oslund, J. Powell, D. Reyes, F. Romano, F. Sade...
-
[3]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,”Science Robotics, vol. 5, no. 47, 2020
work page 2020
-
[4]
Rma: Rapid motor adaptation for legged robots,
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,” inRobotics: Science and Systems, 2021
work page 2021
-
[5]
Learning dynamic bipedal walking across stepping stones,
H. Duan, A. Malik, M. S. Gadde, J. Dao, A. Fern, and J. Hurst, “Learning dynamic bipedal walking across stepping stones,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 6746–6752
work page 2022
-
[6]
Learning vision-based bipedal locomotion for challenging terrain,
H. Duan, B. Pandit, M. S. Gadde, B. Van Marum, J. Dao, C. Kim, and A. Fern, “Learning vision-based bipedal locomotion for challenging terrain,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 56–62
work page 2024
-
[7]
Legged locomotion in challenging terrains using egocentric vision,
A. Agarwal, A. Kumar, J. Malik, and D. Pathak, “Legged locomotion in challenging terrains using egocentric vision,” inConference on Robot Learning (CoRL), 2022
work page 2022
-
[8]
Terrain recogni- tion and contact force estimation through a sensorized paw for legged robots,
A. Vangen, T. Barnwal, J. A. Olsen, and K. Alexis, “Terrain recogni- tion and contact force estimation through a sensorized paw for legged robots,”arXiv preprint arXiv:2311.03855, 2023
-
[9]
Terrain-perception-free quadrupedal spinning locomotion on versatile terrains: Modeling, analysis, and experimental validation,
H. Zhu, D. Wang, N. Boyd, Z. Zhou, L. Ruan, A. Zhang, N. Ding, Y . Zhao, and J. Luo, “Terrain-perception-free quadrupedal spinning locomotion on versatile terrains: Modeling, analysis, and experimental validation,”Frontiers in Robotics and AI, vol. 8, Oct. 2021
2021
-
[10]
Walking with terrain reconstruction: Learning to traverse risky sparse footholds,
R. Yu, Q. Wang, Y . Wang, Z. Wang, J. Wu, and Q. Zhu, “Walking with terrain reconstruction: Learning to traverse risky sparse footholds,” arXiv preprint arXiv:2409.15692, 2024
-
[11]
Walking posture adaptation for legged robot navigation in confined spaces,
R. Buchanan, T. Bandyopadhyay, M. Bjelonic, L. Wellhausen, M. Hut- ter, and N. Kottege, “Walking posture adaptation for legged robot navigation in confined spaces,”IEEE Robotics and Automation Letters, vol. 4, no. 2, pp. 2148–2155, 2019
work page 2019
-
[12]
Learning to walk in confined spaces using 3d representation,
T. Miki, J. Lee, L. Wellhausen, and M. Hutter, “Learning to walk in confined spaces using 3d representation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024
work page 2024
-
[13]
Dexterous legged locomotion in confined 3d spaces with reinforcement learning,
Z. Xu, A. H. Raj, X. Xiao, and P. Stone, “Dexterous legged locomotion in confined 3d spaces with reinforcement learning,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 11 474–11 480
work page 2024
-
[14]
A. A. Rusu, S. G. Colmenarejo, C ¸ aglar G ¨ulc ¸ehre, G. Desjardins, J. Kirkpatrick, R. Pascanu, V . Mnih, K. Kavukcuoglu, and R. Hadsell, “Policy distillation,”CoRR, vol. abs/1511.06295, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:1923568
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
Artplanner: Robust legged robot navigation in the field,
L. Wellhausen and M. Hutter, “Artplanner: Robust legged robot navigation in the field,”arXiv preprint arXiv:2303.01420, 2023
-
[16]
Global planning methods for legged robots on rough terrain,
J. Chestnutt, J. Kuffner, K. Nishiwaki, S. Kagami, K. Kaneko, M. Fukushi, K. Nagasaka, M. Inaba, and H. Inoue, “Global planning methods for legged robots on rough terrain,” inProceedings of the 2009 IEEE International Conference on Robotics and Automation. IEEE, 2009, pp. 1245–1252
work page 2009
-
[17]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,”Science Robotics, vol. 7, no. 62, p. eabk2822, 2022
2022
-
[18]
Learning to perform dynamic legged manoeuvres on flipper steps: A parkour approach,
N. Rudin, D. Hoeller, L. Wellhausen, and M. Hutter, “Learning to perform dynamic legged manoeuvres on flipper steps: A parkour approach,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6789–6796, 2022
2022
-
[19]
Agile but safe: Learning collision-free high-speed legged locomotion,
T. He, C. Zhang, W. Xiao, G. He, C. Liu, and G. Shi, “Agile but safe: Learning collision-free high-speed legged locomotion,” inProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[20]
Learning agile and dynamic motor skills for legged robots,
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter, “Learning agile and dynamic motor skills for legged robots,”Science Robotics, vol. 4, no. 26, p. eaau5872, 2019
work page 2019
-
[21]
Reinforcement learning with demonstrations and guidance: A unified framework for robotic manipulation,
Y . Chebotar, K. Hausman, Y . Lu, T. Xiao, D. Kalashnikov, J. Varley, A. Irpan, P. Pastor, C. Finn, and S. Levine, “Reinforcement learning with demonstrations and guidance: A unified framework for robotic manipulation,” inProceedings of the 2021 Conference on Robot Learning, 2021, pp. 1309–1318
2021
-
[22]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. J. Gordon, and J. A. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, vol. 15. PMLR, 2011, pp. 627–635. [Online]. Available: https://proceedings.mlr.press/v15/ross11a.html
work page 2011
-
[23]
Isaac gym: High performance gpu based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Mack- lin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State, “Isaac gym: High performance gpu based physics simulation for robot learning,” inNeurIPS 2021 Track Datasets and Benchmarks, 2021
work page 2021
-
[24]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” inProceedings of the 34th International Conference on Machine Learning, vol. 70. PMLR, 2017, pp. 3057–3065
work page 2017
-
[25]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
work page 1998
-
[26]
Neural machine translation by jointly learning to align and translate,
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,” inInternational Conference on Learning Representations (ICLR), 2015
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.