Recognition: 2 theorem links
· Lean TheoremSceneGraphVLM: Dynamic Scene Graph Generation from Video with Vision-Language Models
Pith reviewed 2026-05-14 20:36 UTC · model grok-4.3
The pith
SceneGraphVLM generates complete scene graphs from videos in about one second using compact vision-language models and targeted reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
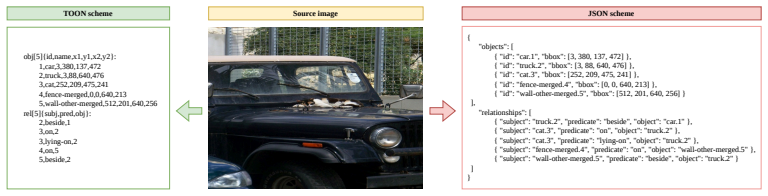
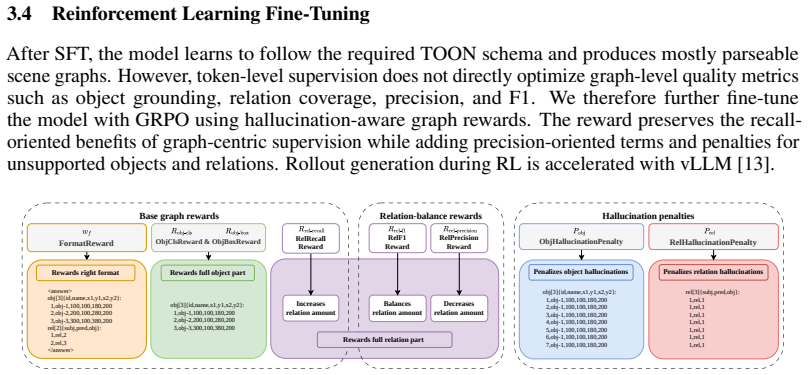
SceneGraphVLM serializes graphs in a token-efficient TOON format and trains the model in two stages: supervised fine-tuning followed by reinforcement learning with hallucination-aware rewards that balance relation coverage and precision while penalizing unsupported objects and relations. For videos, the model can optionally condition each frame on the previously generated graph, providing lightweight short-term context without tracking or post-processing. With compact VLMs and vLLM-accelerated decoding, SceneGraphVLM improves precision-oriented SGG metrics while preserving reasonable recall and generates complete scene graphs with approximately one-second latency on PSG, PVSG, and Action Gen
What carries the argument
Two-stage training that combines supervised fine-tuning with reinforcement learning using hallucination-aware rewards, plus TOON serialization and optional conditioning on the prior frame's graph for video input.
If this is right
- Precision-oriented scene-graph metrics improve while recall remains reasonable across PSG, PVSG, and Action Genome.
- Complete graphs are produced at approximately one-second latency using compact VLMs and accelerated decoding.
- Video frames receive lightweight context by conditioning on the immediately preceding graph without added tracking modules.
- The same pipeline applies to both static images and dynamic video without separate architectures.
Where Pith is reading between the lines
- The short-term previous-graph conditioning could be extended to multi-frame memory buffers for longer video clips at modest extra cost.
- The same reward formulation might transfer to other structured output tasks such as visual question answering or dense captioning.
- Direct comparison against larger VLMs on identical benchmarks would quantify how much of the speed gain is retained when model size increases.
Load-bearing premise
The hallucination-aware RL rewards successfully balance coverage and precision on the target benchmarks without introducing new failure modes or requiring dataset-specific tuning.
What would settle it
Evaluating the trained model on a new video dataset outside PSG, PVSG, and Action Genome and checking whether precision metrics fall below existing baselines or unsupported objects appear at higher rates than reported.
Figures






read the original abstract
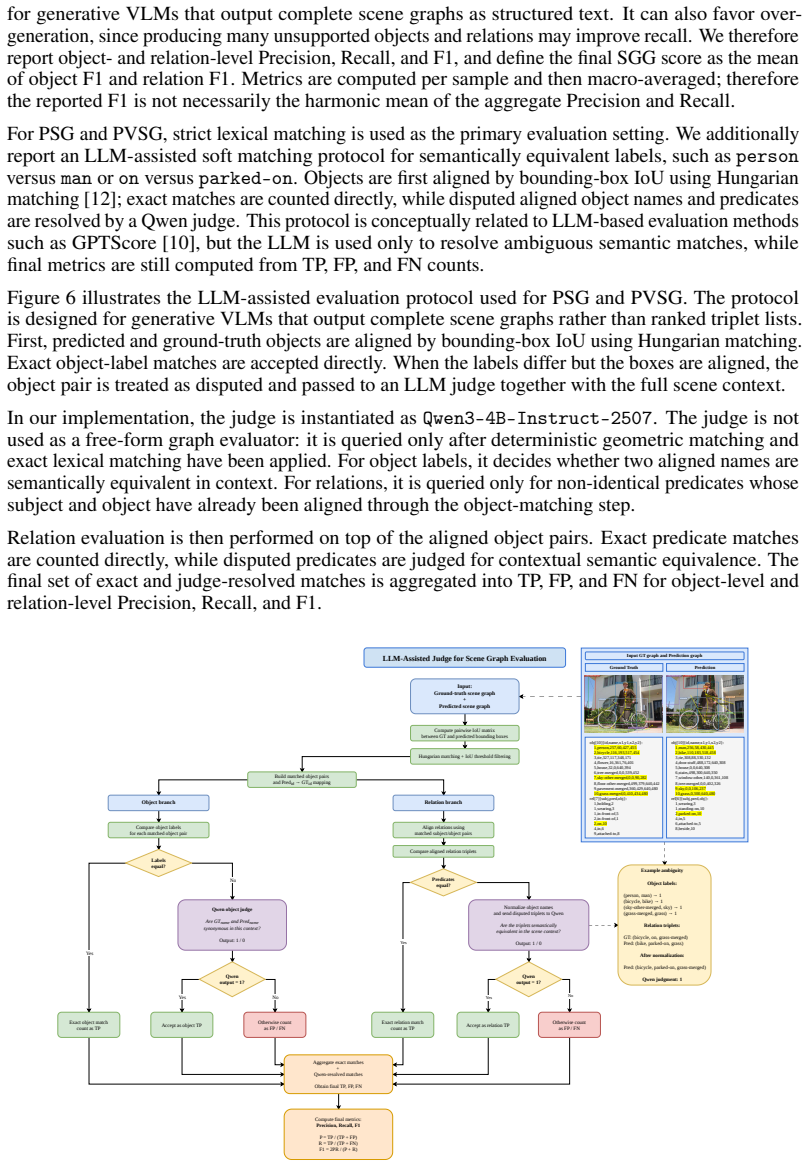
Scene graph generation provides a compact structured representation for visual perception, but accurate and fast graph prediction from images and videos remains challenging. Recent VLM-based methods can generate scene graphs end-to-end as structured text, yet often produce long outputs with irrelevant objects and relations. We present SceneGraphVLM, a compact method for image and video scene graph generation with small visual language models. SceneGraphVLM serializes graphs in a token-efficient TOON format and trains the model in two stages: supervised fine-tuning followed by reinforcement learning with hallucination-aware rewards that balance relation coverage and precision while penalizing unsupported objects and relations. For videos, the model can optionally condition each frame on the previously generated graph, providing lightweight short-term context without tracking or post-processing. We evaluate SceneGraphVLM on PSG, PVSG, and Action Genome. With compact VLMs and vLLM-accelerated decoding, SceneGraphVLM achieves a strong quality-speed trade-off, improves precision-oriented SGG metrics while preserving reasonable recall, and generates complete scene graphs with approximately one-second latency. Code and implementation details are available at: https://github.com/markus0440/SceneGraphVLM.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SceneGraphVLM, a compact VLM-based method for dynamic scene graph generation from images and videos. Graphs are serialized in a token-efficient TOON format; training proceeds in two stages (supervised fine-tuning followed by RL with hallucination-aware rewards that balance coverage/precision and penalize unsupported objects/relations). For video, each frame can optionally condition on the prior graph for lightweight context without explicit tracking. Evaluations on PSG, PVSG, and Action Genome are claimed to yield improved precision-oriented SGG metrics with reasonable recall and ~1 s latency via compact VLMs and vLLM decoding.
Significance. If the empirical claims hold, the work offers a practical quality-speed trade-off for structured visual output using small VLMs, potentially enabling real-time applications without heavy post-processing. The RL reward design and optional temporal conditioning address hallucination and context issues in VLM-based SGG.
major comments (2)
- Abstract: the abstract states improvements on PSG, PVSG, and Action Genome benchmarks with precision gains and one-second latency, but provides no quantitative metrics, ablation details, or error analysis; central performance claims therefore rest on unverified assertions.
- Method (RL stage): the hallucination-aware rewards are described as balancing relation coverage and precision while penalizing unsupported objects/relations, yet the specific reward formulation, coefficient values, and any dataset-specific tuning are not provided, leaving the weakest assumption (successful balance without new failure modes) untestable.
minor comments (1)
- Abstract: the TOON serialization format is introduced as token-efficient but its exact syntax, token count savings relative to JSON, and implementation details are not specified, hindering immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each major comment below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: Abstract: the abstract states improvements on PSG, PVSG, and Action Genome benchmarks with precision gains and one-second latency, but provides no quantitative metrics, ablation details, or error analysis; central performance claims therefore rest on unverified assertions.
Authors: We agree with the referee that the abstract should provide concrete quantitative support for the claimed improvements. While the full manuscript includes detailed metrics, ablations, and error analysis in the Experiments section, the abstract was overly concise. In the revised manuscript, we will expand the abstract to include specific key results, such as the precision gains on PSG, PVSG, and Action Genome, along with the reported latency. This will make the central claims verifiable from the abstract alone. revision: yes
-
Referee: Method (RL stage): the hallucination-aware rewards are described as balancing relation coverage and precision while penalizing unsupported objects/relations, yet the specific reward formulation, coefficient values, and any dataset-specific tuning are not provided, leaving the weakest assumption (successful balance without new failure modes) untestable.
Authors: We acknowledge that the specific formulation of the hallucination-aware reward, including the exact mathematical expression, coefficient values, and tuning procedure, was not fully specified in the submitted manuscript. This limits the ability to reproduce and verify the RL stage. In the revision, we will add a detailed description of the reward function in the Method section, including the formulas for coverage, precision, and hallucination penalties, the specific coefficient values used (e.g., weights for each component), and the dataset-specific tuning process based on validation performance. This will address the concern and allow testing of the balance achieved. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical ML method: two-stage training (supervised fine-tuning then RL with hallucination-aware rewards) on public benchmarks (PSG, PVSG, Action Genome), followed by empirical measurement of precision/recall, latency, and quality-speed trade-off. No mathematical derivation chain, equations, or predictions are present that reduce by construction to fitted inputs, self-citations, or renamed ansatzes. All claims rest on standard training objectives and external benchmark evaluation rather than internal self-definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward balance coefficients
axioms (1)
- domain assumption Small vision-language models can learn to output accurate structured scene graphs after supervised fine-tuning and RL
invented entities (1)
-
TOON format
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearSceneGraphVLM serializes graphs in a token-efficient TOON format and trains the model in two stages: supervised fine-tuning followed by reinforcement learning with hallucination-aware rewards that balance relation coverage and precision while penalizing unsupported objects and relations.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce hallucination-aware GRPO training with graph-oriented rewards that balance relation recall and precision and penalize unsupported objects and relations.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Qwen2.5-vl technical report,
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[3]
URLhttps://arxiv.org/abs/2502.13923. 15
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Compile scene graphs with reinforcement learning, 2025
Zuyao Chen, Jinlin Wu, Zhen Lei, Marc Pollefeys, and Chang Wen Chen. Compile scene graphs with reinforcement learning, 2025. URLhttps://arxiv.org/abs/2504.13617
-
[6]
Spatial-temporal transformer for dynamic scene graph generation
Yuren Cong, Wentong Liao, Hanno Ackermann, Bodo Rosenhahn, and Michael Ying Yang. Spatial-temporal transformer for dynamic scene graph generation. InProceedings of the IEEE/CVF international conference on computer vision, pages 16372–16382, 2021
2021
-
[7]
Reltr: Relation transformer for scene graph generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9): 11169–11183, 2023
Yuren Cong, Michael Ying Yang, and Bodo Rosenhahn. Reltr: Relation transformer for scene graph generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9): 11169–11183, 2023
2023
-
[8]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Maruf, Ismini Lourentzou, Arka Daw, and Anuj Karpatne
Amartya Dutta, Kazi Sajeed Mehrab, Medha Sawhney, Abhilash Neog, Mridul Khurana, Sepideh Fatemi, Aanish Pradhan, M. Maruf, Ismini Lourentzou, Arka Daw, and Anuj Karpatne. Open world scene graph generation using vision language models, 2025. URL https:// arxiv.org/abs/2506.08189
-
[10]
Exploiting long-term dependencies for generating dynamic scene graphs
Shengyu Feng, Hesham Mostafa, Marcel Nassar, Somdeb Majumdar, and Subarna Tripathi. Exploiting long-term dependencies for generating dynamic scene graphs. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 5130–5139, 2023
2023
-
[11]
Gptscore: Evaluate as you desire
Jinlan Fu, See Kiong Ng, Zhengbao Jiang, and Pengfei Liu. Gptscore: Evaluate as you desire. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6556–6576, 2024
2024
-
[12]
Action genome: Actions as compositions of spatio-temporal scene graphs
Jingwei Ji, Ranjay Krishna, Li Fei-Fei, and Juan Carlos Niebles. Action genome: Actions as compositions of spatio-temporal scene graphs. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10236–10247, 2020
2020
-
[13]
The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97, 1955
Harold W Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97, 1955
1955
-
[14]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[15]
From pixels to graphs: Open-vocabulary scene graph generation with vision-language models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, and Xuming He. From pixels to graphs: Open-vocabulary scene graph generation with vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 28076–28086, 2024
2024
-
[16]
Scene graph generation from objects, phrases and region captions
Yikang Li, Wanli Ouyang, Bolei Zhou, Kun Wang, and Xiaogang Wang. Scene graph generation from objects, phrases and region captions. InProceedings of the IEEE international conference on computer vision, pages 1261–1270, 2017
2017
-
[17]
Dynamic scene graph generation via anticipa- tory pre-training
Yiming Li, Xiaoshan Yang, and Changsheng Xu. Dynamic scene graph generation via anticipa- tory pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13874–13883, 2022
2022
-
[18]
Gps-net: Graph property sensing network for scene graph generation
Xin Lin, Changxing Ding, Jinquan Zeng, and Dacheng Tao. Gps-net: Graph property sensing network for scene graph generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3746–3753, 2020
2020
-
[19]
Visual relationship detection with language priors
Cewu Lu, Ranjay Krishna, Michael Bernstein, and Li Fei-Fei. Visual relationship detection with language priors. InEuropean conference on computer vision, pages 852–869. Springer, 2016. 16
2016
- [20]
-
[21]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. Smolvlm: Redefining small and efficient multimodal models, 2025. URL https: //arxiv.org/abs/2504.05299
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Unbiased scene graph generation in videos
Sayak Nag, Kyle Min, Subarna Tripathi, and Amit K Roy-Chowdhury. Unbiased scene graph generation in videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22803–22813, 2023
2023
-
[23]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[24]
Zero: Memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimiza- tions toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[25]
TOON: Token-oriented object notation, 2025
Johann Schopplich and contributors. TOON: Token-oriented object notation, 2025. URLhttps: //github.com/toon-format/toon. Official reference implementation and specification. MIT License. Accessed: 2026-05-01
2025
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Learning to compose dynamic tree structures for visual contexts
Kaihua Tang, Hanwang Zhang, Baoyuan Wu, Wenhan Luo, and Wei Liu. Learning to compose dynamic tree structures for visual contexts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6619–6628, 2019
2019
-
[29]
Qwen3.5-omni technical report, 2026
Qwen Team. Qwen3.5-omni technical report, 2026. URL https://arxiv.org/abs/2604. 15804
2026
-
[30]
Make tracking your machine learning experiments easy
Team Comet. Make tracking your machine learning experiments easy. https://www.comet. com/site/blog/make-tracking-your-machine-learning-experiments-easy/ , April 2022. Accessed: 2026-05-06
2022
-
[31]
Target adaptive context aggregation for video scene graph generation
Yao Teng, Limin Wang, Zhifeng Li, and Gangshan Wu. Target adaptive context aggregation for video scene graph generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13688–13697, 2021
2021
-
[32]
Oed: Towards one-stage end-to-end dynamic scene graph generation
Guan Wang, Zhimin Li, Qingchao Chen, and Yang Liu. Oed: Towards one-stage end-to-end dynamic scene graph generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 27938–27947, 2024
2024
-
[33]
Jingyi Wang, Jinfa Huang, Can Zhang, and Zhidong Deng. Cross-modality time-variant relation learning for generating dynamic scene graphs.arXiv preprint arXiv:2305.08522, 2023
-
[34]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Dy- namic scene graph generation via temporal prior inference
Shuang Wang, Lianli Gao, Xinyu Lyu, Yuyu Guo, Pengpeng Zeng, and Jingkuan Song. Dy- namic scene graph generation via temporal prior inference. InProceedings of the 30th ACM International Conference on Multimedia, pages 5793–5801, 2022
2022
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Huggingface’s transformers: St...
2020
-
[38]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision- language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Scene graph generation by iterative message passing
Danfei Xu, Yuke Zhu, Christopher B Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5410–5419, 2017
2017
-
[40]
Llava-spacesgg: Visual instruct tuning for open-vocabulary scene graph generation with enhanced spatial re- lations
Mingjie Xu, Mengyang Wu, Yuzhi Zhao, Jason Chun Lok Li, and Weifeng Ou. Llava-spacesgg: Visual instruct tuning for open-vocabulary scene graph generation with enhanced spatial re- lations. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6362–6372. IEEE, 2025
2025
-
[41]
Panoptic scene graph generation
Jingkang Yang, Yi Zhe Ang, Zujin Guo, Kaiyang Zhou, Wayne Zhang, and Ziwei Liu. Panoptic scene graph generation. InEuropean conference on computer vision, pages 178–196. Springer, 2022
2022
-
[42]
Panoptic video scene graph generation
Jingkang Yang, Wenxuan Peng, Xiangtai Li, Zujin Guo, Liangyu Chen, Bo Li, Zheng Ma, Kaiyang Zhou, Wayne Zhang, Chen Change Loy, et al. Panoptic video scene graph generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18675–18685, 2023
2023
-
[44]
Neural motifs: Scene graph parsing with global context
Rowan Zellers, Mark Yatskar, Sam Thomson, and Yejin Choi. Neural motifs: Scene graph parsing with global context. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5831–5840, 2018
2018
-
[45]
Tatiana Zemskova, Solomon Andryushenko, Ilya Obrubov, Viktoriia Khoruzhaia, Ekaterina Eroshenko, Ekaterina Derevyanka, and Dmitry Yudin. Focusgraph: Graph-structured frame selection for embodied long video question answering.arXiv preprint arXiv:2603.04349, 2026
-
[46]
Graphical contrastive losses for scene graph parsing
Ji Zhang, Kevin J Shih, Ahmed Elgammal, Andrew Tao, and Bryan Catanzaro. Graphical contrastive losses for scene graph parsing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11535–11543, 2019
2019
-
[47]
Li Zhang, Youhe Jiang, Guoliang He, Xin Chen, Han Lv, Qian Yao, Fangcheng Fu, and Kai Chen. Efficient mixed-precision large language model inference with turbomind.arXiv preprint arXiv:2508.15601, 2025
-
[48]
Swift: a scalable lightweight infrastructure for fine-tuning
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, et al. Swift: a scalable lightweight infrastructure for fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 29733–29735, 2025. 18
2025
-
[49]
Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024
2024
-
[50]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.