Recognition: unknown
SpurAudio: A Benchmark for Studying Shortcut Learning in Few-Shot Audio Classification
Pith reviewed 2026-05-14 20:28 UTC · model grok-4.3
The pith
A new benchmark shows few-shot audio classifiers suffer sharp drops when background correlations are broken, even in large pretrained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpurAudio uses the natural separability of foreground events and background environments in audio to construct controlled, multi-level contextual shifts. When these shifts are introduced, state-of-the-art few-shot methods exhibit severe performance degradation even though they achieve comparable accuracy under conventional evaluation protocols. The same vulnerability appears in large pretrained audio foundation models, showing that the problem is not explained by limited backbone capacity. Different methods display distinct sensitivities that trace to the interaction between learned representations and inference-time classifier heads.
What carries the argument
The SpurAudio benchmark, which exploits natural separability of foreground events and background environments to create controlled multi-level contextual shifts between support and query sets.
If this is right
- Methods that appear equivalent on standard benchmarks can reveal large differences in robustness once background correlations are removed.
- Sensitivity to spurious context is determined by how feature representations interact with the classifier head at inference time.
- Large-scale pretraining alone does not remove dependence on background cues in few-shot audio settings.
- Evaluation protocols must include explicit context-disruption tests to measure generalization beyond shortcut exploitation.
Where Pith is reading between the lines
- Similar controlled-separation benchmarks could be developed for image and video few-shot tasks where context is harder to isolate.
- Methods that explicitly decouple foreground from background signals may show greater robustness across domains.
- Real-world audio systems should be stress-tested on context-shift benchmarks before deployment in variable environments.
Load-bearing premise
Foreground audio events and background environments can be cleanly separated to produce realistic and controlled contextual variations.
What would settle it
Demonstrating that every tested few-shot method maintains its original accuracy when backgrounds are swapped in a dataset where foreground and background signals are verifiably independent of each other.
Figures












read the original abstract
Few-shot classification (FSC) is widely used for learning from limited labeled data, yet most evaluations implicitly assume that target concepts are independent of contextual cues. In real-world settings, however, examples often appear within rich contexts, allowing models to exploit spurious correlations between foreground content and background signals. While such effects have been studied in few-shot image classification, their role in few-shot audio classification remains largely unexplored, and existing audio benchmarks offer limited control over contextual structure. We introduce SpurAudio, a benchmark that leverages the natural separability of foreground events and background environments in audio to enable controlled, multi-level evaluation of contextual shifts across support and query sets. Using this benchmark, we show that many state-of-the-art few-shot methods suffer severe performance degradation when background correlations are disrupted, despite achieving similar accuracy under standard evaluation protocols. Crucially, this vulnerability persists even in large pretrained audio foundation models, ruling out limited backbone capacity as an explanation. Moreover, methods that appear comparable under conventional benchmarks can exhibit markedly different sensitivity to spurious correlations, revealing systematic algorithmic strengths and vulnerabilities tied to how feature representations interact with classifier heads at inference time. These findings provide new insight into the behavior of few-shot methods in audio and highlight the need for benchmarks that explicitly probe context dependence when evaluating FSC models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpurAudio, a benchmark for few-shot audio classification that exploits the separability of foreground events and background environments to create controlled multi-level contextual shifts between support and query sets. It evaluates state-of-the-art few-shot methods and large pretrained audio foundation models, showing severe performance degradation when background correlations are disrupted despite comparable accuracy under standard protocols, and attributes differences to how feature representations interact with classifier heads.
Significance. If the benchmark construction successfully isolates shortcut learning without confounding acoustic domain shifts, the results would demonstrate that context dependence is a systematic vulnerability in audio FSC methods, including foundation models, and motivate more robust evaluation protocols. The work extends image-based shortcut studies to audio and provides a controlled testbed for algorithmic differences that standard benchmarks obscure.
major comments (3)
- [§3] §3 (Benchmark Construction): The central claim attributes performance drops solely to disruption of background correlations, but the manuscript provides no quantitative verification that acoustic properties (SNR distributions, reverberation times, spectral tilt, or event masking) are matched between standard and disrupted splits after overlaying events onto new backgrounds. Without such controls or statistics, degradation could reflect increased task difficulty or domain mismatch rather than shortcut vulnerability, which is load-bearing for the interpretation of results on both conventional methods and pretrained models.
- [§4.2–4.3] §4.2–4.3 (Experimental Results): The reported degradations for few-shot methods and foundation models lack statistical significance tests, confidence intervals, or multiple random seeds with variance measures. This makes it difficult to determine whether observed differences between methods (e.g., sensitivity tied to classifier-head interaction) are reliable or could arise from split variability.
- [§3.1] §3.1 (Multi-level Shifts): The description of how foreground/background separation is performed and how multi-level contextual shifts are generated does not include explicit details on the mixing procedure, event duration alignment, or verification that foreground events remain perceptually unchanged. This detail is required to confirm that the benchmark isolates the intended spurious correlations.
minor comments (2)
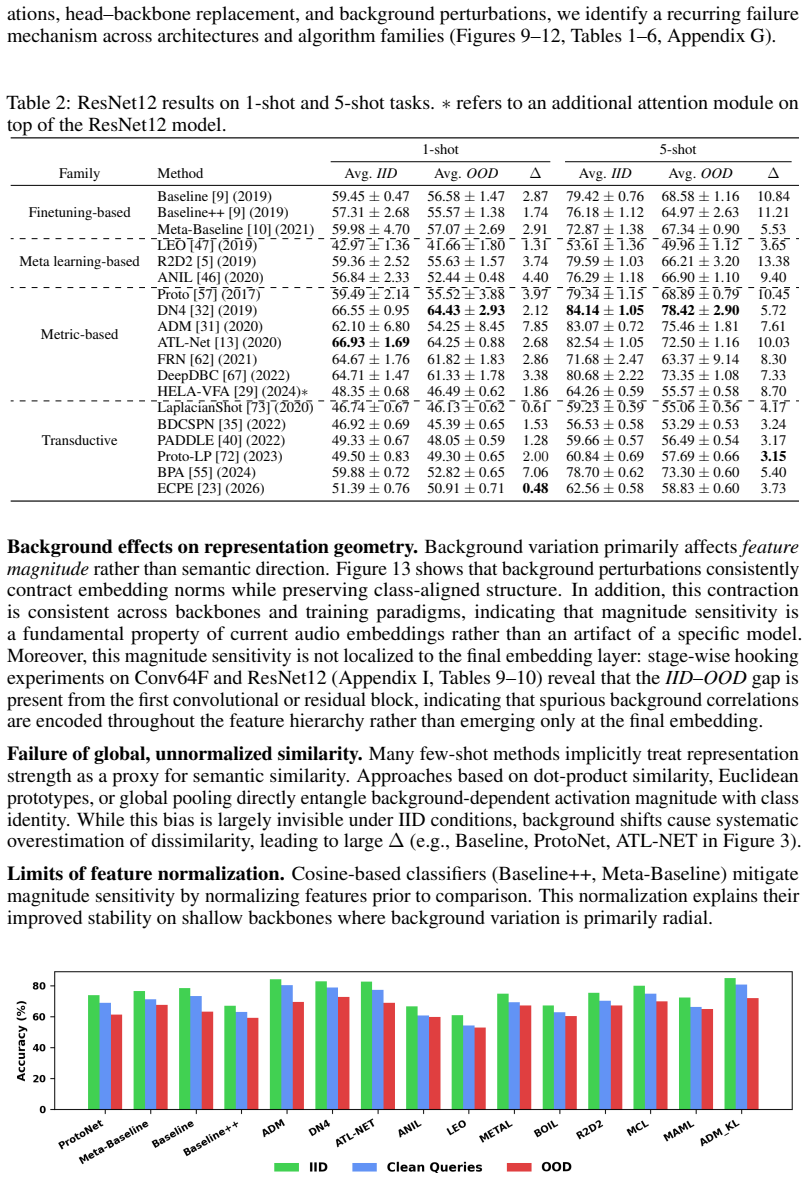
- [Tables/Figures] Table 1 and Figure 2 captions could more explicitly state the exact number of classes, shots, and background conditions per split to aid reproducibility.
- [§2] The related-work section omits several recent audio domain-adaptation papers that also study environmental context, which would strengthen positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the suggested additions will improve the rigor and clarity of the manuscript and plan to incorporate them in the revision.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The central claim attributes performance drops solely to disruption of background correlations, but the manuscript provides no quantitative verification that acoustic properties (SNR distributions, reverberation times, spectral tilt, or event masking) are matched between standard and disrupted splits after overlaying events onto new backgrounds. Without such controls or statistics, degradation could reflect increased task difficulty or domain mismatch rather than shortcut vulnerability, which is load-bearing for the interpretation of results on both conventional methods and pretrained models.
Authors: We agree that quantitative verification of acoustic property matching is essential to isolate shortcut effects from potential confounds. In the revised manuscript we will add a dedicated analysis (new table and/or appendix) reporting SNR distributions, reverberation times, spectral tilt, and event-masking statistics for both the standard and disrupted splits. These statistics will confirm that the splits are matched on these acoustic dimensions, thereby supporting the interpretation that observed degradations stem from the disruption of background correlations. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (Experimental Results): The reported degradations for few-shot methods and foundation models lack statistical significance tests, confidence intervals, or multiple random seeds with variance measures. This makes it difficult to determine whether observed differences between methods (e.g., sensitivity tied to classifier-head interaction) are reliable or could arise from split variability.
Authors: We acknowledge the need for statistical rigor. In the revision we will rerun all experiments across at least five independent random seeds, report mean performance with standard deviation, include 95% confidence intervals, and add paired statistical significance tests (e.g., t-tests) between methods and between standard versus disrupted conditions in §§4.2–4.3. revision: yes
-
Referee: [§3.1] §3.1 (Multi-level Shifts): The description of how foreground/background separation is performed and how multi-level contextual shifts are generated does not include explicit details on the mixing procedure, event duration alignment, or verification that foreground events remain perceptually unchanged. This detail is required to confirm that the benchmark isolates the intended spurious correlations.
Authors: We will expand §3.1 with a precise description of the mixing procedure, including the linear mixing formula with controlled SNR, the event-duration alignment strategy (zero-padding or truncation to match background length), and verification steps (objective SNR preservation metrics plus a small-scale perceptual listening test confirming that foreground events remain perceptually unaltered after mixing). revision: yes
Circularity Check
No circularity: empirical benchmark with independent evaluations
full rationale
The paper introduces SpurAudio as an empirical benchmark for shortcut learning in few-shot audio classification and evaluates existing methods on it. No derivations, predictions, or first-principles results are claimed; performance claims rest on direct experimental comparisons across standard and disrupted splits. The construction of the benchmark relies on external audio datasets with natural foreground/background separability, not on any self-referential fitting or self-citation chain that reduces the central claim to its own inputs. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Target concepts in audio examples are independent of contextual background cues under standard evaluation protocols
Reference graph
Works this paper leans on
-
[1]
Classifying sounds in polyphonic urban sound scenes.AES E-Library
Jakob Abeßer. Classifying sounds in polyphonic urban sound scenes.AES E-Library. Online resource, 2022
work page 2022
-
[2]
Jakob Abeßer, Sascha Grollmisch, and Meinard Müller. How robust are audio embeddings for polyphonic sound event tagging?IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2658–2667, 2023
work page 2023
-
[3]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations.Advances in neural information processing systems, 33:12449–12460, 2020
work page 2020
-
[4]
Meta-learning with task-adaptive loss function for few-shot learning
Sungyong Baik, Janghoon Choi, Heewon Kim, Dohee Cho, Jaesik Min, and Kyoung Mu Lee. Meta-learning with task-adaptive loss function for few-shot learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 9465–9474, 2021
work page 2021
-
[5]
Meta-learning with differentiable closed-form solvers
Luca Bertinetto, Joao F Henriques, Philip HS Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers.arXiv preprint arXiv:1805.08136, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Semi-supervised learning (chapelle, o
Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning (chapelle, o. et al., eds.; 2006)[book reviews].IEEE Transactions on Neural Networks, 20(3):542–542, 2009
work page 2006
-
[7]
Beats: Audio pre-training with acoustic tokenizers.arXiv preprint arXiv:2212.09058, 2022
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, and Furu Wei. Beats: Audio pre-training with acoustic tokenizers.arXiv preprint arXiv:2212.09058, 2022
-
[8]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[9]
A closer look at few-shot classification.arXiv preprint arXiv:1904.04232, 2019
Wei-Yu Chen, Yen-Cheng Liu, Zsolt Kira, Yu-Chiang Frank Wang, and Jia-Bin Huang. A closer look at few-shot classification.arXiv preprint arXiv:1904.04232, 2019
-
[10]
Meta-baseline: Exploring simple meta-learning for few-shot learning
Yinbo Chen, Zhuang Liu, Huijuan Xu, Trevor Darrell, and Xiaolong Wang. Meta-baseline: Exploring simple meta-learning for few-shot learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 9062–9071, 2021. 10
work page 2021
-
[11]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report. arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Cough classification using few-shot learning.arXiv e-prints, pages arXiv–2509, 2025
Yoga Disha Sendhil Kumar, Manas V Shetty, and Sudip Vhaduri. Cough classification using few-shot learning.arXiv e-prints, pages arXiv–2509, 2025
work page 2025
-
[13]
Learning task-aware local rep- resentations for few-shot learning
Chuanqi Dong, Wenbin Li, Jing Huo, Zheng Gu, and Yang Gao. Learning task-aware local rep- resentations for few-shot learning. InProceedings of the twenty-ninth international conference on international joint conferences on artificial intelligence, pages 716–722, 2021
work page 2021
-
[14]
Clap learning audio concepts from natural language supervision
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. Clap learning audio concepts from natural language supervision. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[16]
Model-agnostic meta-learning for fast adap- tation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adap- tation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
work page 2017
-
[17]
Exploring finetuned audio-llm on heart murmur features.Smart Health, page 100557, 2025
Adrian Florea, Xilin Jiang, Nima Mesgarani, and Xiaofan Jiang. Exploring finetuned audio-llm on heart murmur features.Smart Health, page 100557, 2025
work page 2025
-
[18]
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra. Fsd50k: an open dataset of human-labeled sound events.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:829–852, 2021
work page 2021
-
[19]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
work page 2020
- [20]
-
[21]
Ast: Audio spectrogram transformer,
Yuan Gong, Yu-An Chung, and James Glass. Ast: Audio spectrogram transformer.arXiv preprint arXiv:2104.01778, 2021
-
[22]
V ocalsound: A dataset for improving human vocal sounds recognition
Yuan Gong, Jin Yu, and James Glass. V ocalsound: A dataset for improving human vocal sounds recognition. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 151–155, 2022
work page 2022
-
[23]
Mengfei Guo, Jiahui Wang, Qin Xu, Bo Jiang, and Bin Luo. Entropy calibrated prototype embedding for transductive few-shot learning.Pattern Recognition Letters, 2026
work page 2026
-
[24]
Metaaudio: A few-shot audio classification benchmark
Calum Heggan, Sam Budgett, Timothy Hospedales, and Mehrdad Yaghoobi. Metaaudio: A few-shot audio classification benchmark. InInternational Conference on Artificial Neural Networks, pages 219–230. Springer, 2022
work page 2022
-
[25]
Po-Yao Huang, Hu Xu, Juncheng Li, Alexei Baevski, Michael Auli, Wojciech Galuba, Florian Metze, and Christoph Feichtenhofer. Masked autoencoders that listen.Advances in neural information processing systems, 35:28708–28720, 2022
work page 2022
-
[26]
Nouman Ijaz, Farhad Banoori, and Insoo Koo. Reshaping bioacoustics event detection: Leverag- ing few-shot learning (fsl) with transductive inference and data augmentation.Bioengineering, 11(7):685, 2024
work page 2024
-
[27]
Abhishek Jana, Moeumu Uili, James Atherton, Mark O’Brien, Joe Wood, and Leandra Brickson. An automated pipeline for few-shot bird call classification: A case study with the tooth-billed pigeon.arXiv preprint arXiv:2504.16276, 2025
-
[28]
Efficient training of audio transformers with patchout.arXiv preprint arXiv:2110.05069, 2021
Khaled Koutini, Jan Schlüter, Hamid Eghbal-Zadeh, and Gerhard Widmer. Efficient training of audio transformers with patchout.arXiv preprint arXiv:2110.05069, 2021. 11
-
[29]
Gao Yu Lee, Tanmoy Dam, Daniel Puiu Poenar, Vu N Duong, and Md Meftahul Ferdaus. Hela- vfa: A hellinger distance-attention-based feature aggregation network for few-shot classification. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2173–2183, 2024
work page 2024
-
[30]
Are fewer labels possible for few-shot learning?arXiv preprint arXiv:2012.05899, 2020
Suichan Li, Dongdong Chen, Yinpeng Chen, Lu Yuan, Lei Zhang, Qi Chu, and Nenghai Yu. Are fewer labels possible for few-shot learning?arXiv preprint arXiv:2012.05899, 2020
-
[31]
Asymmetric distribution measure for few-shot learning.arXiv preprint arXiv:2002.00153, 2020
Wenbin Li, Lei Wang, Jing Huo, Yinghuan Shi, Yang Gao, and Jiebo Luo. Asymmetric distribution measure for few-shot learning.arXiv preprint arXiv:2002.00153, 2020
-
[32]
Revisiting local descriptor based image-to-class measure for few-shot learning
Wenbin Li, Lei Wang, Jinglin Xu, Jing Huo, Yang Gao, and Jiebo Luo. Revisiting local descriptor based image-to-class measure for few-shot learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7260–7268, 2019
work page 2019
-
[33]
Wenbin Li, Ziyi Wang, Xuesong Yang, Chuanqi Dong, Pinzhuo Tian, Tiexin Qin, Jing Huo, Yinghuan Shi, Lei Wang, Yang Gao, et al. Libfewshot: A comprehensive library for few-shot learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):14938– 14955, 2023
work page 2023
-
[34]
Yingying Liang, Peng Zhao, and Yimeng Wang. Federated few-shot learning-based machinery fault diagnosis in the industrial internet of things.Applied Sciences, 13(18):10458, 2023
work page 2023
-
[35]
Prototype rectification for few-shot learning
Jinlu Liu, Liang Song, and Yongqiang Qin. Prototype rectification for few-shot learning. In European conference on computer vision, pages 741–756. Springer, 2020
work page 2020
-
[36]
Few-shot bioacoustic event detection at the dcase 2024 challenge.Recall, 1:F1_PB, 2024
Wei Liu, Hy Liu, Fl Lin, Hs Liu, Tian Gao, Xin Fang, Jh Liu, Xuyao Deng, Yanjie Sun, Kele Xu, et al. Few-shot bioacoustic event detection at the dcase 2024 challenge.Recall, 1:F1_PB, 2024
work page 2024
-
[37]
Learning to affiliate: Mutual centralized learning for few-shot classification
Yang Liu, Weifeng Zhang, Chao Xiang, Tu Zheng, Deng Cai, and Xiaofei He. Learning to affiliate: Mutual centralized learning for few-shot classification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14411–14420, 2022
work page 2022
-
[38]
Yin-Long Liu, Rui Feng, Jia-Hong Yuan, and Zhen-Hua Ling. Clever hans effect found in automatic detection of alzheimer’s disease through speech.arXiv preprint arXiv:2406.07410, 2024
-
[39]
Whamr!: Noisy and reverberant single-channel speech separation
Matthew Maciejewski, Gordon Wichern, Emmett McQuinn, and Jonathan Le Roux. Whamr!: Noisy and reverberant single-channel speech separation. InICASSP 2020-2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 696–700. IEEE, 2020
work page 2020
-
[40]
Ségolène Martin, Malik Boudiaf, Emilie Chouzenoux, Jean-Christophe Pesquet, and Ismail Ayed. Towards practical few-shot query sets: Transductive minimum description length infer- ence.Advances in Neural Information Processing Systems, 35:34677–34688, 2022
work page 2022
-
[41]
Ben McEwen, Kaspar Soltero, Stefanie Gutschmidt, Andrew Bainbridge-Smith, James Atlas, and Richard Green. Active few-shot learning for rare bioacoustic feature annotation.Ecological Informatics, 82:102734, 2024
work page 2024
-
[42]
Ilyass Moummad, Romain Serizel, and Nicolas Farrugia. Pretraining representations for bioacoustic few-shot detection using supervised contrastive learning.arXiv preprint arXiv:2309.00878, 2023
-
[43]
Learning to detect an animal sound from five examples.Ecological informatics, 77:102258, 2023
Ines Nolasco, Shubhr Singh, Veronica Morfi, Vincent Lostanlen, Ariana Strandburg-Peshkin, Ester Vidaña-Vila, Lisa Gill, Hanna Pamuła, Helen Whitehead, Ivan Kiskin, et al. Learning to detect an animal sound from five examples.Ecological informatics, 77:102258, 2023
work page 2023
-
[44]
Boil: Towards representation change for few-shot learning.arXiv preprint arXiv:2008.08882, 2020
Jaehoon Oh, Hyungjun Yoo, ChangHwan Kim, and Se-Young Yun. Boil: Towards representation change for few-shot learning.arXiv preprint arXiv:2008.08882, 2020
-
[45]
Karol J. Piczak. ESC: Dataset for Environmental Sound Classification. InProceedings of the 23rd Annual ACM Conference on Multimedia, pages 1015–1018. ACM Press. 12
-
[46]
Rapid learning or feature reuse? towards understanding the effectiveness of maml,
Aniruddh Raghu, Maithra Raghu, Samy Bengio, and Oriol Vinyals. Rapid learning or feature reuse? towards understanding the effectiveness of maml.arXiv preprint arXiv:1909.09157, 2019
-
[47]
Meta-Learning with Latent Embedding Optimization
Andrei A Rusu, Dushyant Rao, Jakub Sygnowski, Oriol Vinyals, Razvan Pascanu, Simon Osindero, and Raia Hadsell. Meta-learning with latent embedding optimization.arXiv preprint arXiv:1807.05960, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Shiori Sagawa and Pang Wei Koh. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization
-
[49]
J. Salamon, C. Jacoby, and J. P. Bello. A dataset and taxonomy for urban sound research. In 22nd ACM International Conference on Multimedia (ACM-MM’14), pages 1041–1044, Orlando, FL, USA, Nov. 2014
work page 2014
-
[50]
Justin Salamon and Juan Pablo Bello. Deep convolutional neural networks and data augmen- tation for environmental sound classification.IEEE Signal processing letters, 24(3):279–283, 2017
work page 2017
-
[51]
Faisal Saleem, Muhammad Umar, and Jong-Myon Kim. An optimized few-shot learning framework for fault diagnosis in milling machines.Machines, 13(11):1010, 2025
work page 2025
-
[52]
Wav2vec: Unsupervised pre-training for speech recognition,
Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre-training for speech recognition.arXiv preprint arXiv:1904.05862, 2019
-
[53]
Ramaneswaran Selvakumar, Sonal Kumar, Hemant Kumar Giri, Nishit Anand, Ashish Seth, Sreyan Ghosh, and Dinesh Manocha. Do audio-language models understand linguistic varia- tions? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers)...
work page 2025
-
[54]
Prototypical contrastive learning for improved few shot audio classification
Christos Sgouropoulos, Christos Nikou, Stefanos Vlachos, Vasileios Theiou, Christos Foukanelis, and Theodoros Giannakopoulos. Prototypical contrastive learning for improved few shot audio classification. In2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP), pages 1–6. IEEE, 2025
work page 2025
-
[55]
University of Haifa (Israel), 2024
Daniel Shalam.The balanced-pairwise-affinities feature transform. University of Haifa (Israel), 2024
work page 2024
-
[56]
Farhan Md Siraj, Syed Tasnimul Karim Ayon, and Jia Uddin. A few-shot learning based fault diagnosis model using sensors data from industrial machineries.Vibration, 6(4):1004–1029, 2023
work page 2023
-
[57]
Prototypical networks for few-shot learning
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30, 2017
work page 2017
-
[58]
Learning to compare: Relation network for few-shot learning
Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip HS Torr, and Timothy M Hospedales. Learning to compare: Relation network for few-shot learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1199–1208, 2018
work page 2018
-
[59]
Sound event detection and separation: a benchmark on desed synthetic soundscapes
Nicolas Turpault, Romain Serizel, Scott Wisdom, Hakan Erdogan, John R Hershey, Eduardo Fonseca, Prem Seetharaman, and Justin Salamon. Sound event detection and separation: a benchmark on desed synthetic soundscapes. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 840–844. IEEE, 2021
work page 2021
-
[60]
Matching networks for one shot learning.Advances in neural information processing systems, 29, 2016
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning.Advances in neural information processing systems, 29, 2016
work page 2016
-
[61]
Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. Generalizing from a few examples: A survey on few-shot learning.ACM computing surveys (CSUR), 53(3):1–34, 2020
work page 2020
-
[62]
Few-shot classification with feature map reconstruction networks
Davis Wertheimer, Luming Tang, and Bharath Hariharan. Few-shot classification with feature map reconstruction networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8012–8021, 2021. 13
work page 2021
-
[63]
WHAM!: Extending Speech Separation to Noisy Environments
Gordon Wichern, Joe Antognini, Michael Flynn, Licheng Richard Zhu, Emmett McQuinn, Dwight Crow, Ethan Manilow, and Jonathan Le Roux. Wham!: Extending speech separation to noisy environments.arXiv preprint arXiv:1907.01160, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[64]
Yu-Hsiang Wu, Elizabeth Stangl, Octav Chipara, Syed Shabih Hasan, Anne Welhaven, and Jacob Oleson. Characteristics of real-world signal to noise ratios and speech listening situations of older adults with mild to moderate hearing loss.Ear and hearing, 39(2):293–304, 2018
work page 2018
-
[65]
Yusong Wu*, Ke Chen*, Tianyu Zhang*, Yuchen Hui*, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword- to-caption augmentation. InIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2023
work page 2023
-
[66]
Yang Xiao and Rohan Kumar Das. Wilddesed: an llm-powered dataset for wild domestic environment sound event detection system.arXiv preprint arXiv:2407.03656, 2024
-
[67]
Joint distribution matters: Deep brownian distance covariance for few-shot classification
Jiangtao Xie, Fei Long, Jiaming Lv, Qilong Wang, and Peihua Li. Joint distribution matters: Deep brownian distance covariance for few-shot classification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7972–7981, 2022
work page 2022
-
[68]
Transformer- based bioacoustic sound event detection on few-shot learning tasks
Liwen You, Erika Pelaez Coyotl, Suren Gunturu, and Maarten Van Segbroeck. Transformer- based bioacoustic sound event detection on few-shot learning tasks. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[69]
Mahe Zabin, Syed Tasnimul Karim Ayon, Farhan Md Siraj, Mehedi Hasan Shuvo, Ho-Jin Choi, and Jia Uddin. Few-shot learning-based machine fault diagnosis using emd-gammatone spectrogram with limited labeled audio dataset. In2025 IEEE International Conference on Big Data and Smart Computing (BigComp), pages 183–190. IEEE, 2025
work page 2025
-
[70]
Y . Zhang and et al. Metacoco: A benchmark for spurious correlation in few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
-
[71]
Based on user prompt description
-
[72]
Kaipeng Zheng, Huishuai Zhang, and Weiran Huang. Diffkendall: A novel approach for few- shot learning with differentiable kendall’s rank correlation.Advances in Neural Information Processing Systems, 36:49403–49415, 2023
work page 2023
-
[73]
Hao Zhu and Piotr Koniusz. Transductive few-shot learning with prototype-based label propa- gation by iterative graph refinement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23996–24006, 2023
work page 2023
-
[74]
Laplacian regularized few-shot learning
Imtiaz Ziko, Jose Dolz, Eric Granger, and Ismail Ben Ayed. Laplacian regularized few-shot learning. InInternational conference on machine learning, pages 11660–11670. PMLR, 2020
work page 2020
-
[75]
Imtiaz Masud Ziko, Malik Boudiaf, Jose Dolz, Eric Granger, and Ismail Ben Ayed. Transductive few-shot learning: Clustering is all you need?arXiv preprint arXiv:2106.09516, 2021. 14 Supplementary Material Contents Appendix Contents AExperimental Setup. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[76]
Magnitude (Radial Component): r=∥z∥ 2, representing the activation intensity or "signal energy."
-
[77]
Direction (Angular Component): ˆz= z ∥z∥2 , representing the semantic identity on the hypersphereS d−1. To quantify the semantic alignment, we compute theCosine Similaritybetween a sample’s direction ˆz and its corresponding clean (without backgrounds) class prototype pc. The prototype is defined as the mean direction of the clean, foreground-only samples...
-
[78]
Failure of Euclidean Metrics (e.g., ProtoNet):Euclidean distance is sensitive to magnitude differences. For a queryqand prototypep: ∥q−p∥ 2 =∥q∥ 2 +∥p∥ 2 | {z } Magnitude Term −2∥q∥∥p∥cosθ| {z } Interaction Term (4) The "Magnitude Contraction" observed in mixed samples (∥q∥ ↓ ) reduces the interaction term and alters the magnitude term, creating a large E...
-
[79]
Robustness of Cosine Metrics (e.g., Baseline++, Meta-Baseline):Cosine-based heads explicitly normalize feature vectors during inference: Score(q, p) = qT p ∥q∥∥p∥ = cosθ(5) By projecting all embeddings onto the unit hypersphere, these algorithms mathematically nullify the magnitude axis. Since the background information is sequestered primarily in the mag...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.