Recognition: 2 theorem links
· Lean TheoremToward AI-Driven Digital Twins for Metropolitan Floods: A Conditional Latent Dynamics Network Surrogate of the Shallow Water Equations
Pith reviewed 2026-05-14 19:30 UTC · model grok-4.3
The pith
CLDNet uses a rainfall-driven latent neural ODE and terrain-conditioned decoder to surrogate the shallow water equations, producing 96-hour metropolitan flood forecasts in 29 seconds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLDNet is a conditional latent dynamics network that pairs a low-dimensional latent neural ODE driven by rainfall forcing with a coordinate-based decoder conditioned on static terrain features to reconstruct depth and discharge at arbitrary query locations. On the Des Plaines River basin case study with 114 real rainfall events, the model halves the relative RMSE of an unconditional baseline, achieves a critical success index of approximately 86 percent at the 0.5 m inundation threshold, and completes a full 96-hour basin-wide forecast in roughly 29 seconds for a 115-fold speedup over the reference simulator.
What carries the argument
The Conditional Latent Dynamics Network (CLDNet), a rainfall-conditioned latent neural ODE whose outputs are decoded pointwise by a network that receives static terrain coordinates and values.
If this is right
- Ensemble forecasting and data assimilation become feasible at metropolitan scale because a single 96-hour run now costs seconds instead of nearly an hour.
- Direct point queries at exact gauge locations remove the need for raster snapping or grid alignment.
- Training on single compute nodes becomes practical for basins with millions of active cells because memory scales with latent dimension rather than grid size.
- The same architecture can be retrained on additional simulator runs to incorporate new terrain or roughness data without rebuilding a full grid model.
- Irregular watershed boundaries are handled natively, removing the preprocessing steps required by Cartesian-grid methods such as FNO or ConvLSTM.
Where Pith is reading between the lines
- The pointwise decoder could be extended to output uncertainty estimates at each query point, supporting probabilistic flood maps for decision support.
- Because the decoder is conditioned on static fields, the same trained dynamics model might be reused across multiple nearby basins that share similar rainfall statistics but differ in terrain.
- Coupling CLDNet with real-time gauge assimilation loops could produce continuously updated digital twins that correct for model bias during an ongoing event.
- The latent ODE structure invites stability analysis techniques from dynamical systems theory to predict and mitigate long-horizon error growth before deployment.
Load-bearing premise
The learned latent dynamics will continue to track the true shallow-water behavior accurately for unseen rainfall sequences and varied terrain without drifting over multi-day forecast windows.
What would settle it
Apply the trained CLDNet to a held-out set of real rainfall events on a second metropolitan basin and measure whether the 96-hour critical success index at 0.5 m inundation falls below 75 percent when compared to the reference simulator.
Figures


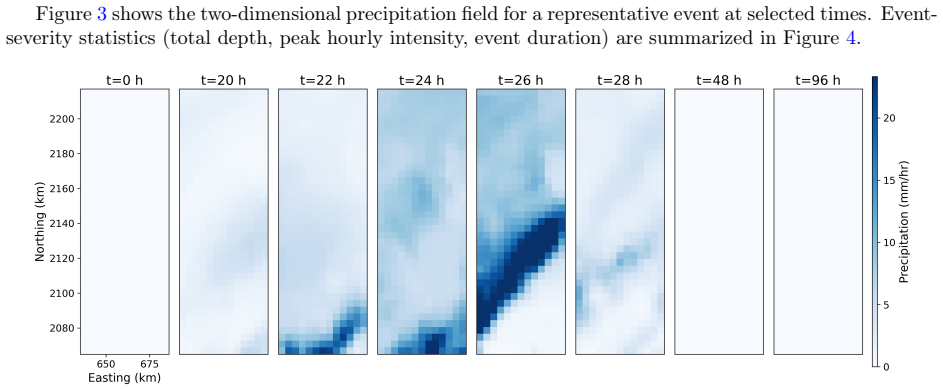
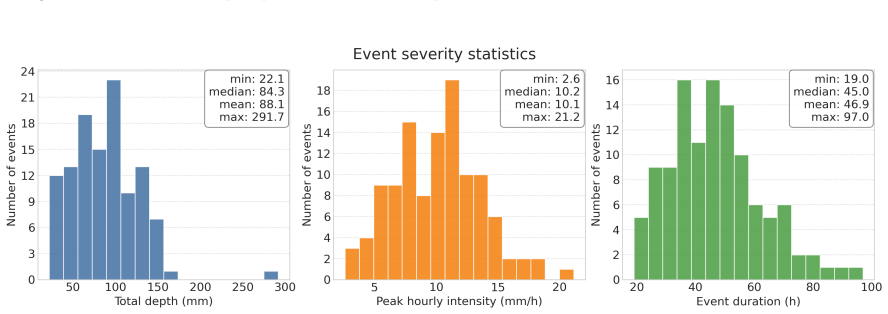








read the original abstract
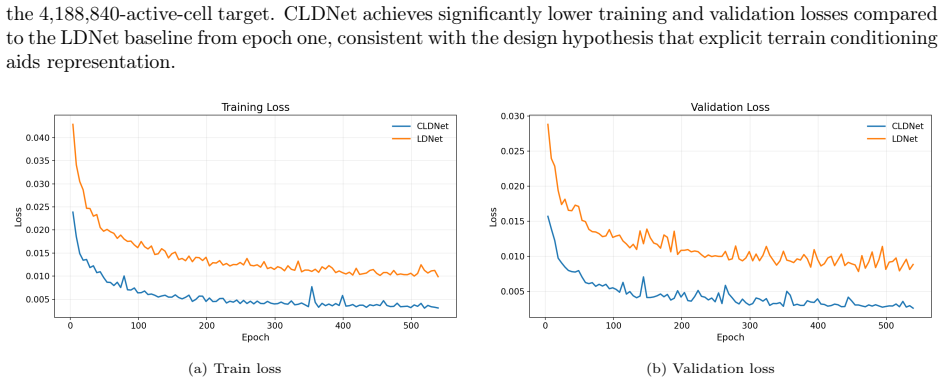
AI-driven flood digital twins demand fast hydrodynamic surrogates for ensemble forecasting and observation assimilation. Yet even GPU-accelerated two-dimensional shallow water equation (SWE) solvers still require $\sim 55$ minutes per $96$-hour run on a $\sim 4.2$-million-active-cell metropolitan basin (the Des~Plaines River basin at $30\,\mathrm{m}$ resolution), making such workloads prohibitive at native resolution. We present the Conditional Latent Dynamics Network (CLDNet): a low-dimensional latent neural ODE driven by rainfall, paired with a coordinate-based decoder conditioned on static terrain (elevation, slope, Manning roughness) that reconstructs depth and discharge at arbitrary query points. Pointwise decoding decouples memory from grid size and handles irregular watersheds natively, enabling metropolitan-scale training on a single compute node and direct queries at exact gauge coordinates without raster snapping. We evaluate CLDNet on a synthetic $250{,}000$-cell Texas benchmark and on a new Des~Plaines case study of $114$ real-rainfall Stage~IV storms whose reference simulator we validate against United States Geological Survey (USGS) gauges at the April~2013 flood-of-record (Nash--Sutcliffe efficiency $0.57$--$0.94$ on mean-recentered water-surface elevation). CLDNet roughly halves the relative root-mean-squared error of an unconditional baseline, outperforms regular-grid VAE--ConvLSTM and FNO baselines on the Texas benchmark (both presuppose a Cartesian grid and do not apply to the irregular Des~Plaines watershed), reaches a critical success index of $\approx 86\%$ at the $0.5\,\mathrm{m}$ inundation threshold, and produces a full $96$-hour basin-wide forecast in $\sim 29$ seconds -- a $\sim 115\times$ speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Conditional Latent Dynamics Network (CLDNet), a surrogate model for the 2D shallow water equations consisting of a rainfall-conditioned latent neural ODE paired with a coordinate-based decoder that reconstructs depth and discharge from static terrain features (elevation, slope, Manning roughness). It reports evaluation on a 250,000-cell Texas benchmark and a Des Plaines River basin case study of 114 real Stage-IV rainfall events, claiming a 115× speedup (full 96-hour forecast in ~29 s), CSI of ~86% at the 0.5 m inundation threshold, and roughly halved relative RMSE versus an unconditional baseline, with reference simulator validation against USGS gauges yielding NSE 0.57–0.94.
Significance. If the generalization and long-horizon stability claims are substantiated, CLDNet would enable practical ensemble forecasting and data assimilation for metropolitan-scale flood digital twins, directly addressing the prohibitive runtime of native-resolution SWE solvers on basins with millions of active cells.
major comments (3)
- [Abstract and §4] The Des Plaines evaluation (abstract and §4) reports aggregate metrics on 114 Stage-IV storms but provides no train/test split, no description of how many events were held out, and no indication of whether test storms share rainfall statistics with the training set. This directly undermines the central claim of generalization to unseen rainfall patterns.
- [Results] No time-resolved error curves or drift analysis for the latent neural ODE integration are shown over the full 96-hour horizon (results section). Without this, the reported CSI and RMSE cannot confirm stability against error accumulation in the latent dynamics.
- [Methods and Results] The manuscript contains no ablation on latent dimension, no regularization details, and no error bars or uncertainty quantification on the NSE, CSI, or RMSE values (methods and results). These omissions make the quantitative performance claims difficult to interpret or reproduce.
minor comments (2)
- [Abstract] The NSE range 0.57–0.94 should be linked to specific gauges or flood conditions for interpretability.
- [Methods] Clarify whether the coordinate-based decoder queries are performed exactly at gauge locations or interpolated, and state any assumptions about terrain feature normalization.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of clarity and completeness. We address each major comment point by point below and will revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract and §4] The Des Plaines evaluation (abstract and §4) reports aggregate metrics on 114 Stage-IV storms but provides no train/test split, no description of how many events were held out, and no indication of whether test storms share rainfall statistics with the training set. This directly undermines the central claim of generalization to unseen rainfall patterns.
Authors: We acknowledge that the manuscript does not currently provide explicit details on the train/test split for the 114 events. In the revised version, we will expand §4 to specify the partitioning strategy (a chronological hold-out of the final 23 events for testing, with the remaining 91 used for training), confirm the number held out, and include comparative rainfall statistics (e.g., histograms and Kolmogorov-Smirnov tests on intensity distributions) demonstrating that test events exhibit distinct patterns from the training set. This addition will directly support the generalization claims. revision: yes
-
Referee: [Results] No time-resolved error curves or drift analysis for the latent neural ODE integration are shown over the full 96-hour horizon (results section). Without this, the reported CSI and RMSE cannot confirm stability against error accumulation in the latent dynamics.
Authors: We agree that time-resolved analysis is necessary to substantiate long-horizon stability. The current results report only aggregate metrics. We will revise the results section to include new figures plotting CSI, relative RMSE, and mean absolute error as functions of forecast lead time across the full 96-hour horizon for representative events. These curves will show that error growth remains bounded, consistent with the stabilizing effect of the rainfall-conditioned latent ODE. revision: yes
-
Referee: [Methods and Results] The manuscript contains no ablation on latent dimension, no regularization details, and no error bars or uncertainty quantification on the NSE, CSI, or RMSE values (methods and results). These omissions make the quantitative performance claims difficult to interpret or reproduce.
Authors: The referee correctly notes the absence of these elements. We will revise the methods section to add an ablation study on latent dimension (reporting CSI and RMSE for dimensions 16, 32, 64, and 128), specify all regularization (L2 weight decay of 1e-4 together with gradient clipping), and include error bars (standard deviation across the 114 events) plus confidence intervals for NSE, CSI, and RMSE. These changes will improve interpretability and reproducibility. revision: yes
Circularity Check
No circularity: CLDNet is a data-driven surrogate trained on independent simulator output
full rationale
The paper trains a latent neural ODE and coordinate-based decoder on outputs from a reference SWE simulator (validated against USGS gauges). Reported metrics (CSI, RMSE, speedup) are empirical results on the Des Plaines Stage-IV storms and Texas benchmark; no equation, ansatz, or self-citation reduces these quantities to fitted parameters by construction. The model architecture and training procedure are standard and self-contained against external simulator data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CLDNet: low-dimensional latent neural ODE driven by rainfall, paired with a coordinate-based decoder conditioned on static terrain (elevation, slope, Manning roughness)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
latent state evolved by explicit forward-Euler step of a neural ordinary differential equation (5)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Rentschler, M. Salhab, B. A. Jafino, Flood exposure and poverty in 188 countries, Nature Commu- nications 13 (1) (2022) 3527.doi:10.1038/s41467-022-30727-4
-
[2]
B. Tellman, J. A. Sullivan, C. Kuhn, A. J. Kettner, C. S. Doyle, G. R. Brakenridge, T. A. Erickson, D. A. Slayback, Satellite imaging reveals increased proportion of population exposed to floods, Nature 596 (7870) (2021) 80–86.doi:10.1038/s41586-021-03695-w
-
[3]
P. D. Bates, M. S. Horritt, T. J. Fewtrell, A simple inertial formulation of the shallow water equations for efficient two-dimensional flood inundation modelling, Journal of Hydrology 387 (1–2) (2010) 33–45. doi:10.1016/j.jhydrol.2010.03.027
-
[4]
X. Xia, Q. Liang, X. Ming, J. Hou, An efficient and stable hydrodynamic model with novel source term discretization schemes for overland flow and flood simulations, Water resources research 53 (5) (2017) 3730–3759.doi:10.1002/2016WR020055
-
[5]
X. Xia, Q. Liang, A new efficient implicit scheme for discretising the stiff friction terms in the shallow water equations, Advances in water resources 117 (2018) 87–97.doi:10.1016/j.advwatres.2018.05. 004
-
[6]
X. Xia, Q. Liang, X. Ming, A full-scale fluvial flood modelling framework based on a high-performance integrated hydrodynamic modelling system (HiPIMS), Advances in Water Resources 132 (2019) 103392. doi:10.1016/j.advwatres.2019.103392
-
[7]
R. Bentivoglio, E. Isufi, S. N. Jonkman, R. Taormina, Rapid spatio-temporal flood modelling via hydraulics-based graph neural networks, Hydrology and Earth System Sciences 27 (23) (2023) 4227– 4246.doi:10.5194/hess-27-4227-2023
-
[8]
Bentivoglio, E
R. Bentivoglio, E. Isufi, S. N. Jonkman, R. Taormina, Multi-scale hydraulic graph neural networks for flood modelling, Natural Hazards and Earth System Sciences 25 (1) (2025) 335–351.doi:10.5194/ nhess-25-335-2025
2025
-
[9]
A. N. Kazadi, J. Doss-Gollin, A. Silva, Pluvial flood emulation with hydraulics-informed message pass- ing, in: Proceedings of the 41st International Conference on Machine Learning (ICML), Vol. 235 of Proceedings of Machine Learning Research, PMLR, 2024, pp. 23367–23390
2024
- [10]
-
[11]
F. Yang, W. Ding, J. Zhao, L. Song, D. Yang, X. Li, Rapid urban flood inundation forecasting using a physics-informed deep learning approach, Journal of Hydrology 643 (2024) 131998.doi:10.1016/j. jhydrol.2024.131998. 30
work page doi:10.1016/j 2024
-
[12]
C. Li, Z. Han, Y. Li, M. Li, W. Wang, J. Dou, L. Xu, G. Chen, Physical information-fused deep learning model ensembled with a subregion-specific sampling method for predicting flood dynamics, Journal of Hydrology 620 (2023) 129465.doi:10.1016/j.jhydrol.2023.129465
-
[13]
A. Bihlo, R. O. Popovych, Physics-informed neural networks for the shallow-water equations on the sphere, Journal of Computational Physics 456 (2022) 111024.doi:10.1016/j.jcp.2022.111024
-
[14]
R. Brecht, E. Cardoso-Bihlo, A. Bihlo, Physics-informed neural networks for tsunami inundation mod- eling, Journal of Computational Physics 536 (2025) 114066.doi:10.1016/j.jcp.2025.114066
-
[15]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, in: International Conference on Learning Representations (ICLR), 2021.arXiv:2010.08895
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nature Machine Intelligence 3 (3) (2021) 218–229. doi:10.1038/s42256-021-00302-5
-
[17]
Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Azizzadenesheli, A. Anandkumar, Physics- informed neural operator for learning partial differential equations, ACM/IMS Journal of Data Science 1 (3) (2024) 1–27.doi:10.1145/3648506
-
[18]
T. O’Leary-Roseberry, U. Villa, P. Chen, O. Ghattas, Derivative-informed projected neural networks for high-dimensional parametric maps governed by PDEs, Computer Methods in Applied Mechanics and Engineering 388 (2022) 114199.doi:10.1016/j.cma.2021.114199
-
[19]
T. O’Leary-Roseberry, P. Chen, U. Villa, O. Ghattas, Derivative-informed neural operator: An efficient framework for high-dimensional parametric derivative learning, Journal of Computational Physics 496 (2024) 112555.doi:10.1016/j.jcp.2023.112555
-
[20]
Y. Qiu, N. Bridges, P. Chen, Derivative-enhanced deep operator network, in: Advances in Neu- ral Information Processing Systems (NeurIPS), 2024, pp. 20945–20981.arXiv:2402.19242,doi: 10.52202/079017-0660
-
[21]
J. Go, P. Chen, Sequential infinite-dimensional Bayesian optimal experimental design with derivative- informed latent attention neural operator, Journal of Computational Physics 532 (2025) 113976.arXiv: 2409.09141,doi:10.1016/j.jcp.2025.113976
- [22]
-
[23]
A. Y. Sun, Z. Li, W. Lee, Q. Huang, B. R. Scanlon, C. Dawson, Rapid flood inundation forecast using Fourier neural operator, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2023, pp. 3733–3739
2023
-
[24]
L. Brocca, S. Barbetta, S. Camici, L. Ciabatta, J. Dari, P. Filippucci, C. Massari, S. Modanesi, A. Tarpanelli, et al., A digital twin of the terrestrial water cycle: a glimpse into the future through high-resolution Earth observations, Frontiers in Science 1 (2024) 1190191.doi:10.3389/fsci.2023. 1190191
-
[25]
Y. Yang, C. Xie, Z. Fan, Z. Xu, B. W. Melville, G. Liu, L. Hong, Digital twinning of river basins towards full-scale, sustainable and equitable water management and disaster mitigation, npj Natural Hazards 1 (1) (2024) 43.doi:10.1038/s44304-024-00047-2
-
[26]
L. M. C. Rápalo, M. N. Gomes Jr., E. M. Mendiondo, Developing an open-source flood forecasting sys- tem adapted to data-scarce regions: A digital twin coupled with hydrologic-hydrodynamic simulations, Journal of Hydrology 644 (2024) 131929.doi:10.1016/j.jhydrol.2024.131929. 31
-
[27]
T. H. Nguyen, S. Bhattacharya, J. S. Wong, Y. Didry, D. L. Phan, T. Tamisier, P. Matgen, Towards digital twin in flood forecasting with data assimilation satellite earth observations — a proof-of-concept in the Alzette catchment, arXiv preprint arXiv:2505.08553 (2025).doi:10.48550/arXiv.2505.08553
-
[28]
B. Liu, Y. Li, M. Ma, B. Mao, A comprehensive review of machine learning approaches for flood depth estimation, International Journal of Disaster Risk Science 16 (3) (2025) 433–445.doi:10.1007/ s13753-025-00639-0
2025
-
[29]
F. Regazzoni, S. Pagani, M. Salvador, L. Dede’, A. Quarteroni, Learning the intrinsic dynamics of spatio-temporal processes through latent dynamics networks, Nature Communications 15 (2024) 1834. doi:10.1038/s41467-024-45323-x
- [30]
-
[31]
P. Xiao, P. Si, P. Chen, LD-EnSF: Synergizing latent dynamics with ensemble score filters for fast data assimilation with sparse observations, in: International Conference on Learning Representations (ICLR), 2026
2026
- [32]
-
[33]
T. Chegini, H.-Y. Li, L. R. Leung, HyRiver: Hydroclimate Data Retriever, Journal of Open Source Software 6 (66) (2021) 3175.doi:10.21105/joss.03175
- [34]
-
[35]
Tancik, P
M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoor- thi, J. T. Barron, R. Ng, Fourier features let networks learn high frequency functions in low dimensional domains, in: Advances in Neural Information Processing Systems, Vol. 33, 2020, pp. 7537–7547
2020
-
[36]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10684–10695
2022
-
[37]
X. Shi, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, W.-c. Woo, Convolutional LSTM network: A machine learning approach for precipitation nowcasting, Advances in neural information processing systems 28 (2015)
2015
-
[38]
N. Vyas, D. Morwani, R. Zhao, I. Shapira, D. Brandfonbrener, L. Janson, S. Kakade, SOAP: Improving and stabilizing Shampoo using Adam, arXiv preprint arXiv:2409.11321 (2024)
work page internal anchor Pith review arXiv 2024
-
[39]
M. Tan, Q. Le, EfficientNet: Rethinking model scaling for convolutional neural networks, in: Interna- tional conference on machine learning, PMLR, 2019, pp. 6105–6114
2019
-
[40]
J. Go, P. Chen, Accurate, scalable, and efficient Bayesian optimal experimental design with derivative- informed neural operators, Computer Methods in Applied Mechanics and Engineering 438 (2025) 117845.doi:10.1016/j.cma.2025.117845
- [41]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.