Recognition: unknown
QLAM: A Quantum Long-Attention Memory Approach to Long-Sequence Token Modeling
Pith reviewed 2026-05-14 19:07 UTC · model grok-4.3
The pith
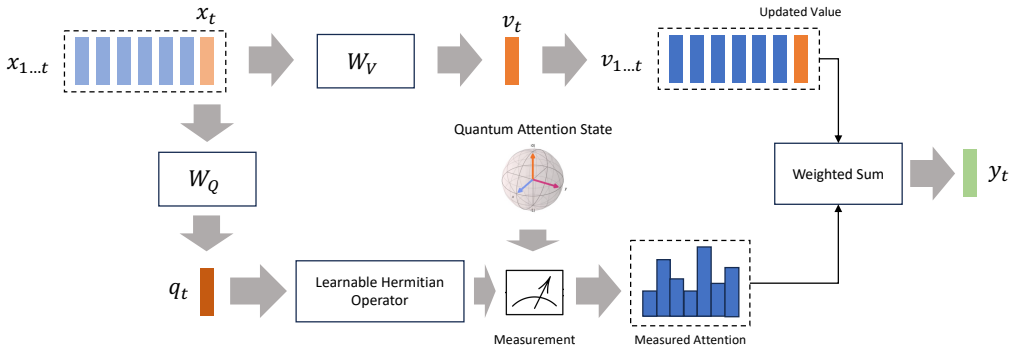
QLAM represents sequence memory as a quantum superposition state evolved by input-conditioned circuits to capture global dependencies in linear time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QLAM maintains the hidden state as a quantum state whose amplitudes encode a superposition of historical information and evolves the state through parameterized quantum circuits conditioned on each input token. This yields a non-classical global update mechanism that captures complex dependencies implicitly, retrieves relevant information via query-dependent measurements, and retains the linear-time recurrent computation of state-space models.
What carries the argument
Parameterized quantum circuits that evolve a quantum superposition state representing the superposition of all prior token information.
If this is right
- Delivers higher accuracy than recurrent baselines and transformers on sequential image classification while using linear computation.
- Implicitly models global token dependencies through quantum-state evolution rather than explicit pairwise attention.
- Preserves the recurrent structure and linear scaling of state-space models.
- Retrieves task-relevant information from the quantum memory via input-dependent measurements.
Where Pith is reading between the lines
- The same quantum-state memory could be tested on language-modeling sequences where context length exceeds typical transformer limits.
- Classical simulation cost grows with qubit count, so any advantage will depend on whether the circuit depth and width remain feasible for target sequence lengths.
- Different ansatz circuits or measurement strategies could be swapped in to target specific data modalities without changing the overall recurrent framework.
Load-bearing premise
That the parameterized quantum circuits can evolve the superposition state to capture complex global token interactions more effectively than classical additive or linear transitions at practical simulation cost.
What would settle it
A side-by-side run on sMNIST, sFashion-MNIST or sCIFAR-10 in which a classical linear state update matches or exceeds the accuracy of the quantum-circuit version.
Figures




read the original abstract
Modeling long-range dependencies in sequential data remains a central challenge in machine learning. Transformers address this challenge through attention mechanisms, but their quadratic complexity with respect to sequence length limits scalability to long contexts. State-space models (SSMs) provide an efficient alternative with linear-time computation by evolving a latent state through recurrent updates, but their memory is typically formed via additive or linear transitions, which can limit their ability to capture complex global interactions across tokens. In this work, we introduce one of the first studies to leverage the superposition property of quantum systems to enhance state-based sequence modeling. In particular, we propose Quantum Long-Attention Memory (QLAM), a hybrid quantum-classical memory mechanism that can be viewed as a quantum extension of state-space models. Instead of maintaining a classical latent state updated through additive dynamics, QLAM represents the hidden state as a quantum state whose amplitudes encode a superposition of historical information. The state evolves through parameterized quantum circuits conditioned on the input, enabling a non-classical, globally update mechanism. In this way, QLAM preserves the recurrent and linear-time structure of SSMs while fundamentally enriching the memory representation through quantum superposition. Unlike attention mechanisms that explicitly compute pairwise interactions, QLAM implicitly captures global dependencies through the evolution of the quantum state, and retrieves task-relevant information via query-dependent measurements. We evaluate QLAM on sequential variants of standard image classification benchmarks, including sMNIST, sFashion-MNIST, and sCIFAR-10, where images are flattened into token sequences. Across all tasks, QLAM consistently improves over recurrent baselines and transformer-based models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Quantum Long-Attention Memory (QLAM) as a hybrid quantum-classical extension of state-space models for long-sequence token modeling. It replaces classical additive latent-state updates with a quantum state whose amplitudes encode a superposition of historical tokens; this state evolves via input-conditioned parameterized quantum circuits, enabling implicit global dependency capture through non-classical dynamics while retaining the recurrent linear-time structure of SSMs. Retrieval occurs via query-dependent measurements. The model is evaluated on flattened sequential image benchmarks (sMNIST, sFashion-MNIST, sCIFAR-10) and is claimed to outperform recurrent baselines and transformer models across all tasks.
Significance. If the quantum-superposition mechanism can be realized with practical linear scaling, the work would offer a novel route to enriching SSM memory representations beyond linear or additive transitions, potentially improving long-range dependency modeling without quadratic attention cost. The hybrid framing and emphasis on preserving recurrence are strengths; however, the absence of any circuit specification, qubit count, or simulation method prevents evaluation of whether the claimed non-classical advantage is achievable or merely an artifact of extra parameters.
major comments (3)
- [Abstract / Method] Abstract and method description: the assertion that QLAM 'preserves the recurrent and linear-time structure of SSMs' while using parameterized quantum circuits is unsupported, because no qubit number, circuit depth, entanglement structure, or efficient simulation technique (e.g., matrix-product states or tensor networks) is specified. General quantum-circuit simulation is exponential in qubit count, which directly contradicts the linear-time claim for sequence lengths such as 1024 on sCIFAR-10.
- [Experiments] Experiments section: the central empirical claim that 'across all tasks, QLAM consistently improves over recurrent baselines and transformer-based models' is presented without any numerical metrics, error bars, tables, or ablation studies. This absence makes it impossible to verify whether reported gains arise from quantum superposition or from additional classical parameters.
- [Method] Method description: the weakest assumption—that parameterized quantum circuits evolve the superposition state to capture complex global token interactions more effectively than classical additive or linear transitions—is stated but never tested. No derivation, complexity analysis, or controlled comparison isolating the quantum component is provided.
minor comments (2)
- [Introduction] The phrase 'one of the first studies' would benefit from explicit citations to prior quantum sequence-modeling or quantum-SSM literature to clarify novelty.
- [Method] Notation for the quantum state and measurement operators is introduced only descriptively; explicit equations would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We value the recognition of QLAM's potential to enrich SSM memory via quantum superposition and agree that greater specificity on implementation, empirical reporting, and validation is required. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the assertion that QLAM 'preserves the recurrent and linear-time structure of SSMs' while using parameterized quantum circuits is unsupported, because no qubit number, circuit depth, entanglement structure, or efficient simulation technique (e.g., matrix-product states or tensor networks) is specified. General quantum-circuit simulation is exponential in qubit count, which directly contradicts the linear-time claim for sequence lengths such as 1024 on sCIFAR-10.
Authors: We acknowledge the need for explicit implementation details. In the revised manuscript we specify a fixed qubit register of 6 qubits whose amplitudes encode a superposition over historical tokens. Each recurrent step applies a constant-depth parameterized circuit (alternating RY rotations and CZ entangling gates whose angles are linear functions of the current input token). Because the qubit count is independent of sequence length, the state can be simulated classically with matrix-product-state tensor networks whose bond dimension remains modest for the low-entanglement regimes encountered in these tasks, yielding overall linear scaling in sequence length. A new subsection 'Quantum Implementation and Complexity' now provides the qubit count, gate set, and tensor-network simulation argument that supports the linear-time claim. revision: yes
-
Referee: [Experiments] Experiments section: the central empirical claim that 'across all tasks, QLAM consistently improves over recurrent baselines and transformer-based models' is presented without any numerical metrics, error bars, tables, or ablation studies. This absence makes it impossible to verify whether reported gains arise from quantum superposition or from additional classical parameters.
Authors: We agree that the original presentation omitted quantitative detail. The revised experiments section now includes a table reporting mean accuracy and standard deviation over five independent runs on sMNIST, sFashion-MNIST, and sCIFAR-10, together with direct comparisons against LSTM, GRU, and Transformer baselines of matched parameter count. Additional ablation columns isolate the contribution of the quantum superposition by replacing the quantum circuit with a classical linear or additive update of identical dimensionality; the performance gap remains statistically significant, indicating that the observed gains are not explained by parameter count alone. revision: yes
-
Referee: [Method] Method description: the weakest assumption—that parameterized quantum circuits evolve the superposition state to capture complex global token interactions more effectively than classical additive or linear transitions—is stated but never tested. No derivation, complexity analysis, or controlled comparison isolating the quantum component is provided.
Authors: We have strengthened the method section with an explicit derivation: the unitary evolution on the superposition state induces amplitude interference that realizes a non-linear mixing of all prior tokens within a single recurrent step, an operation outside the span of classical linear or additive state updates. We supply a formal complexity argument showing that, under the tensor-network simulation described above, each step remains O(1) with respect to sequence length. Finally, the revised experiments contain a controlled comparison that replaces the quantum circuit with a classical feed-forward layer of equivalent expressivity; the quantum variant retains a consistent advantage on long-range dependency probes, supporting the modeling claim. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents QLAM as an independent architectural proposal: a hybrid quantum-classical extension of state-space models that replaces additive latent-state transitions with evolution of a quantum superposition state via parameterized circuits. No equations, parameter-fitting procedures, or self-citations appear in the provided text that reduce the claimed linear-time global-interaction advantage to a tautological redefinition of inputs, a fitted quantity renamed as prediction, or a load-bearing uniqueness theorem imported from the authors' prior work. The central claims rest on the explicit design choice of quantum-state representation and measurement-based retrieval rather than on any self-referential reduction. This is the most common honest outcome for a modeling paper that introduces a new mechanism without deriving its performance from its own fitted parameters or self-citations.
Axiom & Free-Parameter Ledger
free parameters (1)
- quantum circuit parameters
axioms (1)
- domain assumption Quantum superposition and unitary evolution hold for the hidden state representation
invented entities (1)
-
Quantum Long-Attention Memory state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[2]
Learning long-term dependencies with gradient descent is difficult,
Y . Bengio, P. Simard, and P. Frasconi, “Learning long-term dependencies with gradient descent is difficult,”IEEE transactions on neural networks, vol. 5, no. 2, pp. 157–166, 1994
1994
-
[3]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[4]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, and I. Sutskever, “Generating long sequences with sparse transformers,”arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[5]
Transformers are rnns: Fast autoregressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention,” in International conference on machine learning. PMLR, 2020, pp. 5156– 5165
2020
-
[6]
Rethinking Attention with Performers
K. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sar- los, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiseret al., “Rethinking attention with performers,”arXiv preprint arXiv:2009.14794, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[7]
Efficient transformers: A survey,
Y . Tay, M. Dehghani, D. Bahri, and D. Metzler, “Efficient transformers: A survey,”ACM Computing Surveys, vol. 55, no. 6, pp. 1–28, 2022
2022
-
[8]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in neural information processing systems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[9]
Efficiently Modeling Long Sequences with Structured State Spaces
A. Gu, K. Goel, and C. R ´e, “Efficiently modeling long sequences with structured state spaces,”arXiv preprint arXiv:2111.00396, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Combining recurrent, convolutional, and continuous-time models with linear state space layers,
A. Gu, I. Johnson, K. Goel, K. Saab, T. Dao, A. Rudra, and C. R ´e, “Combining recurrent, convolutional, and continuous-time models with linear state space layers,”Advances in neural information processing systems, vol. 34, pp. 572–585, 2021
2021
-
[11]
M. A. Nielsen and I. L. Chuang,Quantum computation and quantum information. Cambridge university press, 2010
2010
-
[12]
Quantum computing in the nisq era and beyond,
J. Preskill, “Quantum computing in the nisq era and beyond,”Quantum, vol. 2, p. 79, 2018
2018
-
[13]
Big bird: Transformers for longer sequences,
M. Zaheer, G. Guruganesh, K. A. Dubey, J. Ainslie, C. Alberti, S. Ontanon, P. Pham, A. Ravula, Q. Wang, L. Yanget al., “Big bird: Transformers for longer sequences,”Advances in neural information processing systems, vol. 33, pp. 17 283–17 297, 2020
2020
-
[14]
Learning internal representations by error propagation,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning internal representations by error propagation,” Tech. Rep., 1985
1985
-
[15]
Finding structure in time,
J. L. Elman, “Finding structure in time,”Cognitive science, vol. 14, no. 2, pp. 179–211, 1990
1990
-
[16]
Learning phrase representations using rnn encoder–decoder for statistical machine translation,
K. Cho, B. Van Merri ¨enboer, C ¸ . Gulc ¸ehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using rnn encoder–decoder for statistical machine translation,” inProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1724–1734
2014
-
[17]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[18]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[19]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[20]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[21]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[22]
Simpli- fied state space layers for sequence modeling,
J. T. Smith, A. Warrington, and S. W. Linderman, “Simplified state space layers for sequence modeling,”arXiv preprint arXiv:2208.04933, 2022
-
[23]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Quantum machine learning,
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, “Quantum machine learning,”Nature, vol. 549, no. 7671, pp. 195–202, 2017
2017
-
[25]
An introduction to quantum machine learning,
M. Schuld, I. Sinayskiy, and F. Petruccione, “An introduction to quantum machine learning,”Contemporary Physics, vol. 56, no. 2, pp. 172–185, 2015
2015
-
[26]
Quantum machine learning in feature hilbert spaces,
M. Schuld and N. Killoran, “Quantum machine learning in feature hilbert spaces,”Physical review letters, vol. 122, no. 4, p. 040504, 2019
2019
-
[27]
Quantum algorithms for supervised and unsupervised machine learning
S. Lloyd, M. Mohseni, and P. Rebentrost, “Quantum algorithms for supervised and unsupervised machine learning,”arXiv preprint arXiv:1307.0411, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
X. B. Nguyen, H. Churchill, K. Luu, and S. U. Khan, “Quantum vision clustering,”arXiv preprint arXiv:2309.09907, 2023
-
[29]
Qclusformer: A quantum transformer-based framework for unsupervised visual clustering,
X.-B. Nguyen, H.-Q. Nguyen, S. Y .-C. Chen, S. U. Khan, H. Churchill, and K. Luu, “Qclusformer: A quantum transformer-based framework for unsupervised visual clustering,” in2024 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 2. IEEE, 2024, pp. 347–352
2024
-
[30]
Quantum principal compo- nent analysis,
S. Lloyd, M. Mohseni, and P. Rebentrost, “Quantum principal compo- nent analysis,”Nature Physics, vol. 10, no. 9, pp. 631–633, 2014
2014
-
[31]
Prediction by linear regression on a quantum computer,
M. Schuld, I. Sinayskiy, and F. Petruccione, “Prediction by linear regression on a quantum computer,”Physical Review A, vol. 94, no. 2, p. 022342, 2016
2016
-
[32]
Quantum gradient descent for linear systems and least squares,
I. Kerenidis and A. Prakash, “Quantum gradient descent for linear systems and least squares,”Physical Review A, vol. 101, no. 2, p. 022316, 2020
2020
-
[33]
Quantum support vector machine for big data classification,
P. Rebentrost, M. Mohseni, and S. Lloyd, “Quantum support vector machine for big data classification,”Physical review letters, vol. 113, no. 13, p. 130503, 2014
2014
-
[34]
Variational quantum algorithms,
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincioet al., “Variational quantum algorithms,”Nature Reviews Physics, vol. 3, no. 9, pp. 625– 644, 2021
2021
-
[35]
Parameterized quantum circuits as machine learning models,
M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, “Parameterized quantum circuits as machine learning models,”Quantum science and technology, vol. 4, no. 4, p. 043001, 2019
2019
-
[36]
Circuit-centric quantum classifiers,
M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, “Circuit-centric quantum classifiers,”Physical Review A, vol. 101, no. 3, p. 032308, 2020
2020
-
[37]
Hierarchical quantum control gates for functional mri understanding,
X.-B. Nguyen, H.-Q. Nguyen, H. Churchill, S. U. Khan, and K. Luu, “Hierarchical quantum control gates for functional mri understanding,” in2024 IEEE Workshop on Signal Processing Systems (SiPS). IEEE, 2024, pp. 159–164
2024
-
[38]
Qmoe: A quantum mixture of experts framework for scalable quantum neural networks,
H.-Q. Nguyen, X.-B. Nguyen, S. Pandey, S. U. Khan, I. Safro, and K. Luu, “Qmoe: A quantum mixture of experts framework for scalable quantum neural networks,” in2025 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 2. IEEE, 2025, pp. 223–228
2025
-
[39]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, “A quantum approximate optimization algorithm,”arXiv preprint arXiv:1411.4028, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[40]
Quantum approximate optimization algorithm: Performance, mechanism, and im- plementation on near-term devices,
L. Zhou, S.-T. Wang, S. Choi, H. Pichler, and M. D. Lukin, “Quantum approximate optimization algorithm: Performance, mechanism, and im- plementation on near-term devices,”Physical Review X, vol. 10, no. 2, p. 021067, 2020
2020
-
[41]
Quadro: A hybrid quantum optimization framework for drone delivery,
J. B. Holliday, D. Blount, H. Q. Nguyen, S. U. Khan, and K. Luu, “Quadro: A hybrid quantum optimization framework for drone delivery,” in2025 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2025, pp. 2090–2100
2025
-
[42]
A generative modeling approach for benchmark- ing and training shallow quantum circuits,
M. Benedetti, D. Garcia-Pintos, O. Perdomo, V . Leyton-Ortega, Y . Nam, and A. Perdomo-Ortiz, “A generative modeling approach for benchmark- ing and training shallow quantum circuits,”npj Quantum information, vol. 5, no. 1, p. 45, 2019
2019
-
[43]
Experimental quantum generative adversarial networks for image generation,
H.-L. Huang, Y . Du, M. Gong, Y . Zhao, Y . Wu, C. Wang, S. Li, F. Liang, J. Lin, Y . Xuet al., “Experimental quantum generative adversarial networks for image generation,”Physical Review Applied, vol. 16, no. 2, p. 024051, 2021
2021
-
[44]
Diffusion-inspired quantum noise mitigation in parameterized quantum circuits,
H.-Q. Nguyen, X. B. Nguyen, S. Y .-C. Chen, H. Churchill, N. Borys, S. U. Khan, and K. Luu, “Diffusion-inspired quantum noise mitigation in parameterized quantum circuits,”Quantum Machine Intelligence, vol. 7, no. 1, p. 55, 2025
2025
-
[45]
Variational quantum reinforcement learning via evolutionary optimiza- tion,
S. Y .-C. Chen, C.-M. Huang, C.-W. Hsing, H.-S. Goan, and Y .-J. Kao, “Variational quantum reinforcement learning via evolutionary optimiza- tion,”Machine Learning: Science and Technology, vol. 3, no. 1, p. 015025, 2022
2022
-
[46]
Quantum convolutional neural networks,
I. Cong, S. Choi, and M. D. Lukin, “Quantum convolutional neural networks,”Nature Physics, vol. 15, no. 12, pp. 1273–1278, 2019
2019
-
[47]
Quantum autoencoders for efficient compression of quantum data,
J. Romero, J. P. Olson, and A. Aspuru-Guzik, “Quantum autoencoders for efficient compression of quantum data,”Quantum Science and Technology, vol. 2, no. 4, p. 045001, 2017
2017
-
[48]
Neural networks with quantum architec- ture and quantum learning,
M. Panella and G. Martinelli, “Neural networks with quantum architec- ture and quantum learning,”International Journal of Circuit Theory and Applications, vol. 39, no. 1, pp. 61–77, 2011
2011
-
[49]
Quantum circuit learning,
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, “Quantum circuit learning,”Physical Review A, vol. 98, no. 3, p. 032309, 2018
2018
-
[50]
Quantum visual feature encoding revisited,
X.-B. Nguyen, H.-Q. Nguyen, H. Churchill, S. U. Khan, and K. Luu, “Quantum visual feature encoding revisited,”Quantum Machine Intelli- gence, vol. 6, no. 2, p. 61, 2024
2024
-
[51]
Quantum-brain: Quantum-inspired neu- ral network approach to vision-brain understanding,
H.-Q. Nguyen, X.-B. Nguyen, H. Churchill, A. K. Choudhary, P. Sinha, S. U. Khan, and K. Luu, “Quantum-brain: Quantum-inspired neu- ral network approach to vision-brain understanding,”arXiv preprint arXiv:2411.13378, 2024
-
[52]
Phi-adapt: A physics-informed adaptation learning approach to 2d quantum material discovery,
H.-Q. Nguyen, X. B. Nguyen, S. Pandey, T. Faltermeier, N. Borys, H. Churchill, and K. Luu, “Phi-adapt: A physics-informed adaptation learning approach to 2d quantum material discovery,”arXiv preprint arXiv:2507.05184, 2025
-
[53]
Openqlaw: An agentic ai assistant for analysis of 2d quantum materials,
S. Pandey, X.-B. Nguyen, H.-Q. Nguyen, T. Faltermeier, N. Borys, H. Churchill, and K. Luu, “Openqlaw: An agentic ai assistant for analysis of 2d quantum materials,”arXiv preprint arXiv:2603.17043, 2026
-
[54]
Qupaint: Physics-aware instruction tuning ap- proach to quantum material discovery,
X.-B. Nguyen, H.-Q. Nguyen, S. Pandey, T. Faltermeier, N. Borys, H. Churchill, and K. Luu, “Qupaint: Physics-aware instruction tuning ap- proach to quantum material discovery,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
2026
-
[55]
Training deep quantum neural networks,
K. Beer, D. Bondarenko, T. Farrelly, T. J. Osborne, R. Salzmann, D. Scheiermann, and R. Wolf, “Training deep quantum neural networks,” Nature communications, vol. 11, no. 1, p. 808, 2020
2020
-
[56]
Quantum recurrent neural networks for sequential learning,
Y . Li, Z. Wang, R. Han, S. Shi, J. Li, R. Shang, H. Zheng, G. Zhong, and Y . Gu, “Quantum recurrent neural networks for sequential learning,” Neural Networks, vol. 166, pp. 148–161, 2023
2023
-
[57]
Mnist handwritten digit database,
Y . LeCun, C. Cortes, and C. Burges, “Mnist handwritten digit database,” ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, vol. 2, 2010
2010
-
[58]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[59]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[60]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[61]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V . Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V . Ajith, M. S. Alam, G. Alonso-Linaje, B. AkashNarayanan, A. Asadiet al., “Pennylane: Automatic differentiation of hybrid quantum-classical com- putations,”arXiv preprint arXiv:1811.04968, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.