Recognition: unknown
Unlocking Patch-Level Features for CLIP-Based Class-Incremental Learning
Pith reviewed 2026-05-14 19:08 UTC · model grok-4.3
The pith
Aligning CLIP patch features to semantic descriptions improves class-incremental learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that semantic-guided selection of patch-level visual features from CLIP, followed by optimal transport alignment between those patches and tokens from GPT-5-generated class descriptions, produces a richer cross-modal representation; when combined with task-specific projectors and calibration via stored class-wise Gaussian statistics, this representation yields higher accuracy and lower forgetting than global-embedding baselines in class-incremental settings.
What carries the argument
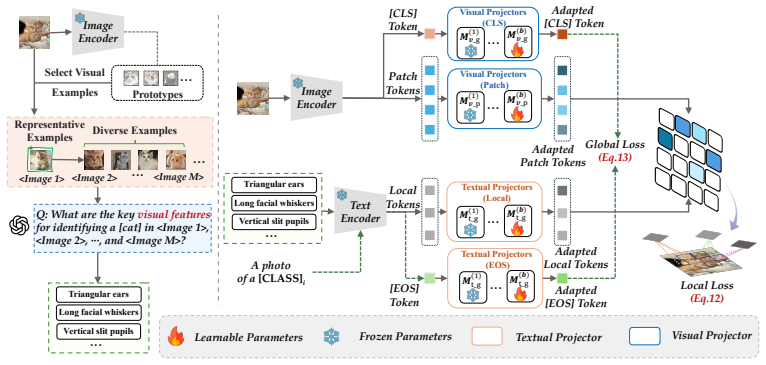
Semantic-guided Patch-level Alignment (SPA), which uses GPT-5 descriptions to pick discriminative patches and optimal transport to match those patches to semantic tokens.
If this is right
- Patch features supply complementary local evidence that global embeddings alone miss during recognition of new and old classes.
- Optimal transport produces structured alignments between visual patches and text tokens that support better matching in incremental tasks.
- Task-specific projectors allow the model to adapt to each new task while the Gaussian pseudo-feature sampling keeps old-class statistics intact.
- The resulting system reaches state-of-the-art accuracy on standard class-incremental benchmarks.
Where Pith is reading between the lines
- The same patch-to-semantic alignment could be tested on other vision-language backbones to check whether local features help beyond CLIP.
- Replacing GPT-5 with an open model for description generation would test whether the gains depend on a proprietary language model.
- The method suggests that explicit semantic guidance may be necessary to make patch features useful in any continual learning pipeline.
Load-bearing premise
GPT-5 descriptions generated from a few representative images reliably point to the most useful patches in the visual encoder for every class.
What would settle it
An ablation that replaces semantic-guided patch selection with random patch selection and shows no drop in incremental accuracy would indicate the guidance step adds no value.
Figures








read the original abstract
Class-Incremental Learning (CIL) enables models to continuously integrate new knowledge while mitigating catastrophic forgetting. Driven by the remarkable generalization of CLIP, leveraging pre-trained vision-language models has become a dominant paradigm in CIL. However, current work primarily focuses on aligning global image embeddings (i.e., [CLS] token) with their corresponding text prompts (i.e., [EOS] token). Despite their good performance, we find that they discard the rich patch-level semantic information inherent in CLIP's encoders. For instance, when recognizing a rabbit, local patches may encode its distinctive cues, such as long ears and a fluffy tail, which can provide complementary evidence for recognition. Based on the above observation, we propose SPA (Semantic-guided Patch-level Alignment) for CLIP-based CIL, which aims to awaken long-neglected local representations within CLIP. Specifically, for each class, we first construct representative and diverse visual samples and feed them to GPT-5 as visual guidance to generate class-wise semantic descriptions. These descriptions are used to guide the selection of discriminative patch-level visual features. Building upon these selected patches, we further employ optimal transport to align selected patch tokens with semantic tokens from class-wise descriptions, yielding a structured cross-modal alignment that improves recognition. Furthermore, we introduce task-specific projectors for effective adaptation to downstream incremental tasks, and sample pseudo-features from stored class-wise Gaussian statistics to calibrate old-class representations, thereby mitigating catastrophic forgetting. Extensive experiments demonstrate that SPA achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SPA (Semantic-guided Patch-level Alignment) for CLIP-based class-incremental learning. It constructs representative and diverse visual samples per class, feeds them to GPT-5 to generate class-wise semantic descriptions that guide selection of discriminative patch-level features from CLIP encoders, aligns the selected patch tokens with semantic tokens via optimal transport, introduces task-specific projectors for downstream adaptation, and uses Gaussian pseudo-feature replay from stored class statistics to mitigate catastrophic forgetting. The central claim is that this pipeline unlocks patch-level information neglected by global [CLS] embeddings and achieves state-of-the-art CIL performance on standard benchmarks.
Significance. If the reported gains are reproducible and the ablations isolate the contribution of patch-level OT alignment, the work would be a meaningful advance in CLIP-based continual learning by demonstrating that local semantic cues (e.g., ears and tail for a rabbit) provide complementary evidence beyond global embeddings. The use of external semantic guidance and structured cross-modal alignment is a concrete, testable idea that could influence subsequent methods.
major comments (2)
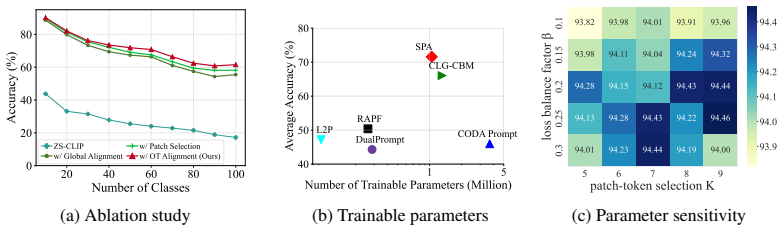
- [§3.3] §3.3 (Optimal Transport Alignment): the claim that OT alignment between selected patches and GPT-5 semantic tokens yields a structured improvement beyond global embeddings is load-bearing for the central contribution, yet the manuscript provides no ablation that isolates OT from the preceding patch-selection step (e.g., random patches + OT vs. guided patches + OT). Without this comparison the source of the reported accuracy lift remains ambiguous.
- [Table 2] Table 2 (main results): the SOTA claim rests on average accuracy and last-task accuracy, but the table does not report standard deviation across the standard 5–10 random class-order runs used in CIL literature; this omission weakens the statistical support for superiority over recent CLIP-based baselines.
minor comments (3)
- [Abstract] Abstract: the sentence asserting 'extensive experiments demonstrate SOTA' should be expanded to name the primary datasets (e.g., CIFAR-100, ImageNet-100) and the key metric (average accuracy) for immediate clarity.
- [§3.1] §3.1 (Representative Sample Construction): the criterion for selecting 'representative and diverse' samples is described only qualitatively; a short pseudocode or explicit diversity metric (e.g., k-means on CLIP features) would aid reproducibility.
- [Figure 2] Figure 2 caption: the pipeline diagram would benefit from explicit labels on the OT cost matrix and the task-projector blocks to match the text description.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive suggestions. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Optimal Transport Alignment): the claim that OT alignment between selected patches and GPT-5 semantic tokens yields a structured improvement beyond global embeddings is load-bearing for the central contribution, yet the manuscript provides no ablation that isolates OT from the preceding patch-selection step (e.g., random patches + OT vs. guided patches + OT). Without this comparison the source of the reported accuracy lift remains ambiguous.
Authors: We agree that an ablation isolating the contribution of OT alignment from the patch-selection step would strengthen the central claim. In the revised manuscript we will add experiments comparing random patch selection followed by OT alignment against our semantic-guided patch selection with OT alignment. This comparison will clarify the source of the gains. revision: yes
-
Referee: [Table 2] Table 2 (main results): the SOTA claim rests on average accuracy and last-task accuracy, but the table does not report standard deviation across the standard 5–10 random class-order runs used in CIL literature; this omission weakens the statistical support for superiority over recent CLIP-based baselines.
Authors: We acknowledge that reporting standard deviations over multiple random class orders is standard practice in CIL. In the revised manuscript we will rerun the main experiments with 5 random class orders and report mean ± standard deviation in Table 2 (and other key tables) to provide statistical support for the results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a pipeline using external components (GPT-5 for semantic descriptions, standard optimal transport for patch-semantic alignment, task projectors, and Gaussian pseudo-feature replay) without any equations or derivations that reduce claimed gains to fitted parameters or self-referential quantities by construction. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear; the central claim rests on direct experimental evaluation against CIL benchmarks rather than internal redefinitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European conference on computer vision (ECCV), pages 139–154, 2018
2018
-
[2]
Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2(1):1, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2(1):1, 2023
2023
-
[3]
Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models.Advances in neural information processing systems, 32, 2019
Andrei Barbu, David Mayo, Julian Alverio, William Luo, Christopher Wang, Dan Gutfreund, Josh Tenenbaum, and Boris Katz. Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models.Advances in neural information processing systems, 32, 2019
2019
-
[4]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InEuropean conference on computer vision, pages 446–461. Springer, 2014
2014
-
[5]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem.arXiv preprint arXiv:1812.00420, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Guangyi Chen, Weiran Yao, Xiangchen Song, Xinyue Li, Yongming Rao, and Kun Zhang. Plot: Prompt learning with optimal transport for vision-language models.arXiv preprint arXiv:2210.01253, 2022
-
[7]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
2013
-
[8]
A continual learning survey: Defying forgetting in classification tasks
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks. IEEE transactions on pattern analysis and machine intelligence, 44(7):3366–3385, 2021
2021
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4): 128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4): 128–135, 1999
1999
-
[11]
Adapter merging with centroid prototype mapping for scalable class-incremental learning
Takuma Fukuda, Hiroshi Kera, and Kazuhiko Kawamoto. Adapter merging with centroid prototype mapping for scalable class-incremental learning. InProceedings of the computer vision and pattern recognition conference, pages 4884–4893, 2025
2025
-
[12]
The geometry of optimal transportation
Wilfrid Gangbo and Robert J McCann. The geometry of optimal transportation. 1996
1996
-
[13]
Clip-adapter: Better vision-language models with feature adapters.International journal of computer vision, 132(2):581–595, 2024
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters.International journal of computer vision, 132(2):581–595, 2024
2024
-
[14]
R-dfcil: Relation-guided representation learning for data-free class incremental learning
Qiankun Gao, Chen Zhao, Bernard Ghanem, and Jian Zhang. R-dfcil: Relation-guided representation learning for data-free class incremental learning. InEuropean Conference on Computer Vision, pages 423–439. Springer, 2022
2022
-
[15]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[16]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, pages 8340–8349, 2021
2021
-
[17]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Tao Hu, Lan Li, Zhen-Hao Xie, and Da-Wei Zhou. Hierarchical semantic tree anchoring for clip-based class-incremental learning.arXiv preprint arXiv:2511.15633, 2025
-
[19]
Class-incremental learning with clip: Adaptive representation adjustment and parameter fusion
Linlan Huang, Xusheng Cao, Haori Lu, and Xialei Liu. Class-incremental learning with clip: Adaptive representation adjustment and parameter fusion. InEuropean Conference on Computer Vision, pages 214–231. Springer, 2024. 10
2024
-
[20]
Mind the gap: Preserving and compensating for the modality gap in clip-based continual learning
Linlan Huang, Xusheng Cao, Haori Lu, Yifan Meng, Fei Yang, and Xialei Liu. Mind the gap: Preserving and compensating for the modality gap in clip-based continual learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3777–3786, 2025
2025
-
[21]
Openclip.Zenodo, 2021
Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, et al. Openclip.Zenodo, 2021
2021
-
[22]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021
2021
-
[23]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[24]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InProceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013
2013
-
[25]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[26]
Gallop: Learning global and local prompts for vision-language models
Marc Lafon, Elias Ramzi, Clément Rambour, Nicolas Audebert, and Nicolas Thome. Gallop: Learning global and local prompts for vision-language models. InEuropean Conference on Computer Vision, pages 264–282. Springer, 2024
2024
-
[27]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[28]
Lan Li, Da-Wei Zhou, Han-Jia Ye, and De-Chuan Zhan. Addressing imbalanced domain-incremental learning through dual-balance collaborative experts.arXiv preprint arXiv:2507.07100, 2025
-
[29]
Bofa: Bridge-layer orthogo- nal low-rank fusion for clip-based class-incremental learning
Lan Li, Tao Hu, Da-Wei Zhou, Jia-Qi Yang, Han-Jia Ye, and De-Chuan Zhan. Bofa: Bridge-layer orthogo- nal low-rank fusion for clip-based class-incremental learning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 22967–22975, 2026
2026
-
[30]
Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
2017
-
[31]
Adaptive aggregation networks for class-incremental learning
Yaoyao Liu, Bernt Schiele, and Qianru Sun. Adaptive aggregation networks for class-incremental learning. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 2544– 2553, 2021
2021
-
[32]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of the IEEE international conference on computer vision, pages 3730–3738, 2015
2015
-
[33]
Class-incremental exemplar compression for class-incremental learning
Zilin Luo, Yaoyao Liu, Bernt Schiele, and Qianru Sun. Class-incremental exemplar compression for class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11371–11380, 2023
2023
-
[34]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[35]
Class-incremental learning: survey and performance evaluation on image classification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):5513–5533, 2022
Marc Masana, Xialei Liu, Bartłomiej Twardowski, Mikel Menta, Andrew D Bagdanov, and Joost Van De Weijer. Class-incremental learning: survey and performance evaluation on image classification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):5513–5533, 2022
2022
-
[36]
Learning to remember: A synaptic plasticity driven framework for continual learning
Oleksiy Ostapenko, Mihai Puscas, Tassilo Klein, Patrick Jahnichen, and Moin Nabi. Learning to remember: A synaptic plasticity driven framework for continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11321–11329, 2019
2019
-
[37]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[38]
Adaptive adapter routing for long-tailed class-incremental learning.Machine Learning, 114(3):68, 2025
Zhi-Hong Qi, Da-Wei Zhou, Yiran Yao, Han-Jia Ye, and De-Chuan Zhan. Adaptive adapter routing for long-tailed class-incremental learning.Machine Learning, 114(3):68, 2025. 11
2025
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[40]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[41]
Overcoming catastrophic forgetting with hard attention to the task
Joan Serra, Didac Suris, Marius Miron, and Alexandros Karatzoglou. Overcoming catastrophic forgetting with hard attention to the task. InInternational conference on machine learning, pages 4548–4557. PMLR, 2018
2018
-
[42]
Overcoming catastrophic forgetting in incremental few-shot learning by finding flat minima.Advances in neural information processing systems, 34:6747–6761, 2021
Guangyuan Shi, Jiaxin Chen, Wenlong Zhang, Li-Ming Zhan, and Xiao-Ming Wu. Overcoming catastrophic forgetting in incremental few-shot learning by finding flat minima.Advances in neural information processing systems, 34:6747–6761, 2021
2021
-
[43]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Coda-prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. Coda-prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11909–11919, 2023
2023
-
[45]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[46]
C3box: A clip-based class-incremental learning toolbox.arXiv preprint arXiv:2601.20852, 2026
Hao Sun and Da-Wei Zhou. C3box: A clip-based class-incremental learning toolbox.arXiv preprint arXiv:2601.20852, 2026
-
[47]
Semantically-shifted incremental adapter-tuning is a continual vitransformer
Yuwen Tan, Qinhao Zhou, Xiang Xiang, Ke Wang, Yuchuan Wu, and Yongbin Li. Semantically-shifted incremental adapter-tuning is a continual vitransformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23252–23262, 2024
2024
-
[48]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011
2011
-
[49]
Beef: Bi- compatible class-incremental learning via energy-based expansion and fusion
Fu-Yun Wang, Da-Wei Zhou, Liu Liu, Han-Jia Ye, Yatao Bian, De-Chuan Zhan, and Peilin Zhao. Beef: Bi- compatible class-incremental learning via energy-based expansion and fusion. InThe eleventh international conference on learning representations, 2022
2022
-
[50]
S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning.Advances in Neural Information Processing Systems, 35: 5682–5695, 2022
Yabin Wang, Zhiwu Huang, and Xiaopeng Hong. S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning.Advances in Neural Information Processing Systems, 35: 5682–5695, 2022
2022
-
[51]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean conference on computer vision, pages 631–648. Springer, 2022
2022
-
[52]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 139–149, 2022
2022
-
[53]
Llm2clip: Powerful language model unlock richer visual representation
Aoqi Wu, Yifan Yang, Xufang Luo, Yuqing Yang, Chunyu Wang, Liang Hu, Xiyang Dai, Dongdong Chen, Chong Luo, Lili Qiu, et al. Llm2clip: Powerful language model unlock richer visual representation. In NeurIPS 2024 Workshop: Self-Supervised Learning-Theory and Practice, 2024
2024
-
[54]
Controlmllm: Training-free visual prompt learning for multimodal large language models
Mingrui Wu, Xinyue Cai, Jiayi Ji, Jiale Li, Oucheng Huang, Hao Fei, Guannan Jiang, Xiaoshuai Sun, and Rongrong Ji. Controlmllm: Training-free visual prompt learning for multimodal large language models. Advances in Neural Information Processing Systems, 37:45206–45234, 2024
2024
-
[55]
Incremental learning using conditional adversarial networks
Ye Xiang, Ying Fu, Pan Ji, and Hua Huang. Incremental learning using conditional adversarial networks. InProceedings of the IEEE/CVF international conference on computer vision, pages 6619–6628, 2019
2019
-
[56]
Sun database: Large- scale scene recognition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large- scale scene recognition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010. 12
2010
-
[57]
Reinforced continual learning.Advances in neural information processing systems, 31, 2018
Ju Xu and Zhanxing Zhu. Reinforced continual learning.Advances in neural information processing systems, 31, 2018
2018
-
[58]
Pevl: Position-enhanced pre-training and prompt tuning for vision-language models
Yuan Yao, Qianyu Chen, Ao Zhang, Wei Ji, Zhiyuan Liu, Tat-Seng Chua, and Maosong Sun. Pevl: Position-enhanced pre-training and prompt tuning for vision-language models. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 11104–11117, 2022
2022
-
[59]
Lifelong Learning with Dynamically Expandable Networks
Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks.arXiv preprint arXiv:1708.01547, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[60]
Boosting continual learning of vision-language models via mixture-of-experts adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23219–23230, 2024
2024
-
[61]
Language guided concept bottleneck models for interpretable continual learning
Lu Yu, Haoyu Han, Zhe Tao, Hantao Yao, and Changsheng Xu. Language guided concept bottleneck models for interpretable continual learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14976–14986, 2025
2025
-
[62]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. In International conference on machine learning, pages 3987–3995. Pmlr, 2017
2017
-
[63]
Maintaining discrimination and fairness in class incremental learning
Bowen Zhao, Xi Xiao, Guojun Gan, Bin Zhang, and Shu-Tao Xia. Maintaining discrimination and fairness in class incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13208–13217, 2020
2020
-
[64]
Task-agnostic guided feature expansion for class-incremental learning
Bowen Zheng, Da-Wei Zhou, Han-Jia Ye, and De-Chuan Zhan. Task-agnostic guided feature expansion for class-incremental learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10099–10109, 2025
2025
-
[65]
Continual learning with pre-trained models: a survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, and De-Chuan Zhan. Continual learning with pre-trained models: a survey. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 8363–8371, 2024
2024
-
[66]
Class-incremental learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9851–9873, 2024
Da-Wei Zhou, Qi-Wei Wang, Zhi-Hong Qi, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Class-incremental learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9851–9873, 2024
2024
-
[67]
Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need.International Journal of Computer Vision, 133(3):1012–1032, 2025
Da-Wei Zhou, Zi-Wen Cai, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need.International Journal of Computer Vision, 133(3):1012–1032, 2025
2025
-
[68]
External know- ledge injection for clip-based class-incremental learning
Da-Wei Zhou, Kai-Wen Li, Jingyi Ning, Han-Jia Ye, Lijun Zhang, and De-Chuan Zhan. External know- ledge injection for clip-based class-incremental learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3314–3325, 2025
2025
-
[69]
Learning without forgetting for vision-language models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Da-Wei Zhou, Yuanhan Zhang, Yan Wang, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Learning without forgetting for vision-language models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[70]
Conditional prompt learning for vision- language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision- language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16816–16825, 2022
2022
-
[71]
Learning to prompt for vision-language models.International journal of computer vision, 130(9):2337–2348, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International journal of computer vision, 130(9):2337–2348, 2022
2022
-
[72]
a photo of a [CLASS]
Fei Zhu, Xu-Yao Zhang, Chuang Wang, Fei Yin, and Cheng-Lin Liu. Prototype augmentation and self- supervision for incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5871–5880, 2021. 13 Appendix In this supplementary material, we provide more details about SPA, including more implementation detai...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.