Recognition: no theorem link
Bidirectional Empowerment of Metamorphic Testing and Large Language Models: A Systematic Survey
Pith reviewed 2026-05-15 05:12 UTC · model grok-4.3
The pith
Metamorphic testing and large language models form a reciprocal relationship that addresses the oracle problem in AI systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that metamorphic testing and large language models empower each other bidirectionally: metamorphic testing supplies a practical way to check LLM behavior across hallucination, fairness, robustness, retrieval-augmented generation, dialogue, and agents, while LLMs reduce the manual labor of finding relations, transforming inputs, writing executable tests, and running agentic test loops.
What carries the argument
The bidirectional empowerment taxonomy that partitions interactions into MT-for-LLMs (verification tasks) and LLMs-for-MT (automation tasks).
If this is right
- Metamorphic relations can be used to test LLM outputs for consistency in autonomous-agent scenarios without needing ground-truth answers.
- LLMs can generate candidate metamorphic relations and executable test scripts, lowering the cost of applying MT to new domains.
- The combination supports closed-loop testing pipelines that iterate between generation and verification for dialogue and retrieval systems.
- Quality assurance methodologies for AI can become more rigorous by treating MT as a core technique rather than an ad-hoc supplement.
- Scalable assessment of code reliability in LLM-generated programs becomes feasible through relation-based checks.
Where Pith is reading between the lines
- The same pattern of mutual assistance could be explored between metamorphic testing and other generative models such as diffusion or multimodal systems.
- Integration into continuous-integration pipelines might allow routine metamorphic checks on LLM outputs during development.
- The taxonomy could guide empirical studies that measure concrete reductions in testing effort when LLMs assist metamorphic relation discovery.
- Safety-critical domains may adopt hybrid MT-LLM procedures to gain both formal relation guarantees and automated coverage.
Load-bearing premise
The 93 selected primary studies are representative of the field and the proposed taxonomy captures the main interactions without major selection or categorization bias.
What would settle it
A follow-up review that identifies a large body of work on MT and LLMs whose techniques fall outside the two directions or demonstrate no mutual improvement.
Figures



read the original abstract
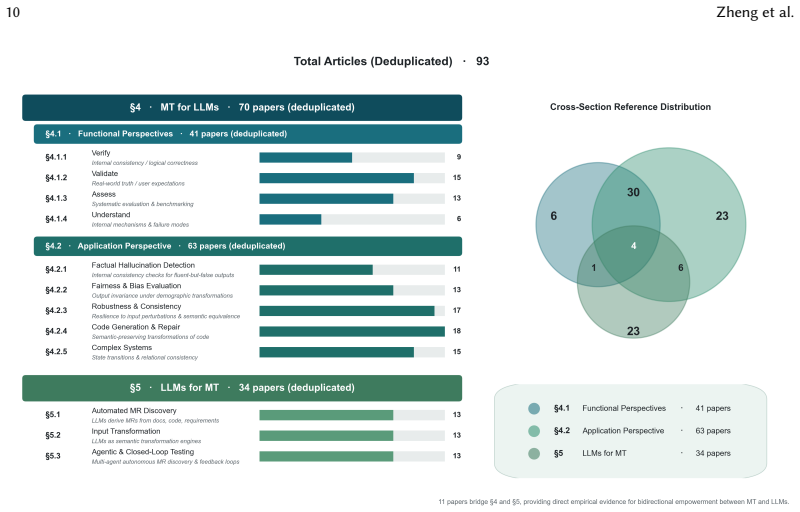
Large language models (LLMs) have introduced substantial challenges to software quality assurance due to their generative, probabilistic, and open-ended nature, which intensifies the oracle problem and limits the applicability of traditional testing methods. Metamorphic testing (MT), which checks necessary relations among multiple related executions rather than relying on exact expected outputs, has emerged as a promising approach for testing LLMs and other oracle-deficient systems. At the same time, the strong semantic understanding, reasoning, and code generation capabilities of LLMs create new opportunities to automate the traditionally labor-intensive phases of MT. This survey systematically reviews 93 primary studies and characterizes this reciprocal relationship as the bidirectional empowerment of MT and LLMs. We propose a taxonomy spanning two complementary directions: MT for LLMs, which uses MT to verify, validate, assess, and understand LLMs and LLM-based systems across issues such as hallucination, fairness, robustness, code reliability, retrieval-augmented generation, dialogue, and autonomous agents; and LLMs for MT, which leverages LLMs to support metamorphic relation discovery, input transformation and synthesis, executable test implementation, and agentic closed-loop testing. By synthesizing these developments, this survey provides a structured foundation for understanding the evolving synergy between MT and LLMs and highlights future directions for building more rigorous, scalable, and trustworthy AI quality assurance methodologies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic survey of 93 primary studies on the bidirectional empowerment between Metamorphic Testing (MT) and Large Language Models (LLMs). It characterizes the relationship through a taxonomy with two directions: (1) MT for LLMs, applying MT to address challenges in LLMs such as hallucination, fairness, robustness, code reliability, RAG, dialogue, and autonomous agents; and (2) LLMs for MT, using LLMs to aid in metamorphic relation discovery, input transformation, test implementation, and agentic closed-loop testing. The survey synthesizes these to provide a foundation for future AI quality assurance methods.
Significance. This survey is significant because it offers the first comprehensive overview of the synergies between MT and LLMs, two important areas in software engineering and AI. By mapping how MT can help with the oracle problem in LLMs and how LLMs can automate MT, it highlights opportunities for more reliable AI systems. The proposed taxonomy structures the field and identifies gaps, which could guide researchers in developing better testing methodologies for generative AI.
major comments (2)
- [Abstract and Methodology section] Abstract and Methodology section: The abstract states that 93 primary studies were reviewed, but provides no information on the search strategy, databases used, search strings, inclusion/exclusion criteria, date ranges, or quality assessment process (e.g., no PRISMA flow diagram). This omission is load-bearing because the central claim of bidirectional empowerment and the accuracy of the proposed taxonomy rest on the representativeness of the selected studies; without these details, selection bias cannot be ruled out.
- [§4 (Taxonomy and Synthesis)] §4 (Taxonomy and Synthesis): The two-direction taxonomy is introduced without a quantitative breakdown of how many of the 93 studies fall into each subcategory (e.g., hallucination vs. robustness under MT for LLMs) or an explicit description of how categories were derived from the primary studies. This weakens the claim that the taxonomy accurately captures the distribution of evidence rather than reflecting post-hoc grouping.
minor comments (2)
- [Introduction] Introduction: A few illustrative citations to specific primary studies could be added when first describing each subcategory in the taxonomy to improve concreteness.
- [Conclusion] Conclusion: The future directions could be strengthened by listing 3-4 concrete open research questions explicitly tied to gaps identified in the 93 studies.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us improve the transparency and rigor of our systematic survey. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Methodology section] Abstract and Methodology section: The abstract states that 93 primary studies were reviewed, but provides no information on the search strategy, databases used, search strings, inclusion/exclusion criteria, date ranges, or quality assessment process (e.g., no PRISMA flow diagram). This omission is load-bearing because the central claim of bidirectional empowerment and the accuracy of the proposed taxonomy rest on the representativeness of the selected studies; without these details, selection bias cannot be ruled out.
Authors: We agree that the abstract should provide a high-level summary of the methodology and that a PRISMA flow diagram would strengthen transparency. Although the full Methodology section describes the search strategy, databases (IEEE Xplore, ACM DL, Scopus, arXiv), search strings, inclusion/exclusion criteria, date ranges, and quality assessment, we have now added a concise overview of these elements to the abstract and inserted a PRISMA flow diagram in the revised manuscript to explicitly document the study selection process and mitigate concerns about selection bias. revision: yes
-
Referee: [§4 (Taxonomy and Synthesis)] §4 (Taxonomy and Synthesis): The two-direction taxonomy is introduced without a quantitative breakdown of how many of the 93 studies fall into each subcategory (e.g., hallucination vs. robustness under MT for LLMs) or an explicit description of how categories were derived from the primary studies. This weakens the claim that the taxonomy accurately captures the distribution of evidence rather than reflecting post-hoc grouping.
Authors: We acknowledge that making the derivation process and quantitative distribution explicit would better support the taxonomy. The categories were developed inductively through thematic synthesis of the primary studies during data extraction. In the revision, we have expanded §4 with an explicit description of the derivation method and added tables/figures providing quantitative breakdowns of the 93 studies across all subcategories under both directions of the taxonomy. revision: yes
Circularity Check
Survey synthesis shows no circularity
full rationale
This is a literature survey paper that reviews and taxonomizes 93 external primary studies on metamorphic testing and LLMs. No derivations, equations, predictions, or fitted parameters appear in the abstract or described content. The bidirectional empowerment characterization and proposed taxonomy are presented as syntheses of the reviewed studies rather than self-defined constructs or results forced by the paper's own inputs. No self-citation chains, ansatz smuggling, or renaming of known results as novel derivations are identifiable. The paper is self-contained as a review and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLM assisted coding with metamorphic specification mutation agent,
Mostafijur Rahman Akhond and Gias Uddin. LLM assisted coding with metamorphic specification mutation agent,
-
[2]
arXiv: 2511.18249. ACM Comput. Surv., Vol. 1, No. 1, Article . Publication date: May 2026. Bidirectional Empowerment of Metamorphic Testing and Large Language Models: A Systematic Survey 31
-
[3]
Ali Asgari, Milan de Koning, Pouria Derakhshanfar, and Annibale Panichella. Metamorphic testing of deep code models: a systematic literature review.ACM Transactions on Software Engineering and Methodology, 2025
work page 2025
-
[4]
Large language models for software testing: a research roadmap, 2025
Cristian Augusto, Antonia Bertolino, Guglielmo de Angelis, Francesca Lonetti, and Jesús Morán. Large language models for software testing: a research roadmap, 2025. arXiv: 2509.25043
-
[5]
Md Abdul Awal, Mrigank Rochan, and Chanchal K Roy. A metamorphic testing perspective on knowledge distillation for language models of code: does the student deeply mimic the teacher?, 2025. arXiv: 2511.05476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
LLM-augmented driving behavior planning for autonomous vehicle
Aidana Baimbetova, Haruki Yonekura, Hamada Rizk, and Hirozumi Yamaguchi. LLM-augmented driving behavior planning for autonomous vehicle. InCompanion Proceedings of the International Conference on Distributed Computing and Networking, pages 5–6, 2026
work page 2026
-
[7]
Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo
Earl T. Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. The oracle problem in software testing: a survey.IEEE Transactions on Software Engineering, 41(5):507–525, 2015
work page 2015
-
[8]
AgentAssay: token-efficient regression testing for non-deterministic AI agent workflows,
Varun Pratap Bhardwaj. AgentAssay: token-efficient regression testing for non-deterministic AI agent workflows,
-
[9]
Dibyendu Brinto Bose, Yoseph Berhanu Alebachew, and Chris Brown. LLMs in debate: does arguing make them better at detecting metamorphic relations? In2025 IEEE/ACM International Conference on Automated Software Engineering Workshops, pages 43–50, 2025
work page 2025
-
[10]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
work page 1901
-
[11]
Pablo C Cañizares, Pablo Gómez-Abajo, Esther Guerra, and Juan de Lara. Towards metamorphic testing with LLM- based workflows: metamorphic relation inference and follow-up test case generation.Information and Software Technology, 196:108150, 2026
work page 2026
-
[12]
Application of metamorphic testing in numerical analysis
Fun ting Chan, Tsong Yueh Chen, Shing Chi Cheung, Manfei Lau, and Shiu Ming Yiu. Application of metamorphic testing in numerical analysis. InIASTED International Conference on Software Engineering, pages 191–197, 1998
work page 1998
-
[13]
A symmetric metamorphic relations approach supporting LLM for education technology
Pak Yuen Patrick Chan and Jacky Keung. A symmetric metamorphic relations approach supporting LLM for education technology. InInternational Symposium on Educational Technology, pages 39–43, 2024
work page 2024
-
[14]
Pak Yuen Patrick Chan and Jacky Keung. Validating pretrained language models for content quality classification with semantic-preserving metamorphic relations.Natural Language Processing Journal, 9:100114, 2024
work page 2024
-
[15]
Pak Yuen Patrick Chan, Jacky Keung, and Zhen Yang. Effectiveness of symmetric metamorphic relations on validating the stability of code generation LLM.Journal of Systems and Software, 222:112330, 2025
work page 2025
-
[16]
Metamorphic testing: a new approach for generating next test cases, 1998
Tsong Yueh Chen, Shing Chi Cheung, and Shiu Ming Yiu. Metamorphic testing: a new approach for generating next test cases, 1998. Technical Report HKUST-CS98-01
work page 1998
-
[17]
Tsong Yueh Chen, Fei-Ching Kuo, Huai Liu, Pak-Lok Poon, Dave Towey, T H Tse, and Zhi Quan Zhou. Metamorphic testing: a review of challenges and opportunities.ACM Computing Surveys, 51(1):1–27, 2018
work page 2018
-
[18]
LLMORPH: automated metamorphic testing of large language models
Steven Cho, Stefano Ruberto, and Valerio Terragni. LLMORPH: automated metamorphic testing of large language models. InIEEE/ACM International Conference on Automated Software Engineering, pages 4102–4105, 2025
work page 2025
-
[19]
Metamorphic testing of large language models for natural language processing
Steven Cho, Stefano Ruberto, and Valerio Terragni. Metamorphic testing of large language models for natural language processing. InIEEE International Conference on Software Maintenance and Evolution, pages 174–186, 2025
work page 2025
-
[20]
J. de Curtò and I. de Zarzà. Metamorphic testing for semantic invariance in large language models.IEEE Access, 13:214772–214791, 2025
work page 2025
-
[21]
PhD thesis, Delft University of Technology, 2025
Milan de Koning.Metamorphic testing for LLM-based code repair. PhD thesis, Delft University of Technology, 2025
work page 2025
-
[22]
A Metamorphic Testing Approach to Diagnosing Memorization in LLM-Based Program Repair
Milan de Koning, Ali Asgari, Pouria Derakhshanfar, and Annibale Panichella. A metamorphic testing approach to diagnosing memorization in LLM-based program repair, 2026. arXiv: 2604.21579
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Juan de Lara, Alejandro del Pozzo, Esther Guerra, and Jesús Sánchez Cuadrado. Automated end-to-end testing for conversational agents.Journal of Systems and Software, page 112685, 2025
work page 2025
-
[24]
Matheus Vinicius da Silva de Oliveira, Jonathan de Andrade Silva, and Awdren de Lima Fontao. Fairness testing in retrieval-augmented generation: how small perturbations reveal bias in small language models, 2025. arXiv: 2509.26584
-
[25]
Automated repair of programs from large language models
Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan. Automated repair of programs from large language models. InIEEE/ACM International Conference on Software Engineering, pages 1469–1481, 2023
work page 2023
-
[26]
Drive like a human: rethinking autonomous driving with large language models
Daocheng Fu, Xin Li, Licheng Wen, Min Dou, Pinlong Cai, Botian Shi, and Yu Qiao. Drive like a human: rethinking autonomous driving with large language models. InIEEE/CVF Winter Conference on Applications of Computer Vision Workshops, pages 910–919, 2024
work page 2024
-
[27]
ASSURE: metamorphic testing for ai-powered browser extensions, 2025
Xuanqi Gao, Juan Zhai, Shiqing Ma, Siyi Xie, and Chao Shen. ASSURE: metamorphic testing for ai-powered browser extensions, 2025. arXiv: 2507.05307
-
[28]
Suavis Giramata, Madhusudan Srinivasan, Venkat Naidu Gudivada, and Upulee Kanewala. Efficient fairness testing in large language models: prioritizing metamorphic relations for bias detection. InIEEE International Conference on ACM Comput. Surv., Vol. 1, No. 1, Article . Publication date: May 2026. 32 Zheng et al. Artificial Intelligence Testing, pages 191...
work page 2026
-
[29]
Technical challenges in maintaining tax prep software with large language models
Sina Gogani-Khiabani, Varsha Dewangan, Nina Olson, Ashutosh Trivedi, and Saeid Tizpaz-Niari. Technical challenges in maintaining tax prep software with large language models. InProceedings of the Annual IRS/TPC Joint Research Conference on Tax Administration, 2024
work page 2024
-
[30]
An LLM agentic approach for legal-critical software: a case study for tax prep software, 2025
Sina Gogani-Khiabani, Ashutosh Trivedi, Diptikalyan Saha, and Saeid Tizpaz-Niari. An LLM agentic approach for legal-critical software: a case study for tax prep software, 2025
work page 2025
-
[31]
Mortar: Multi-turn metamorphic testing for LLM-based dialogue systems
Guoxiang Guo, Aldeida Aleti, Neelofar Neelofar, Chakkrit Tantithamthavorn, Yuanyuan Qi, and Tsong Yueh Chen. Mortar: Multi-turn metamorphic testing for LLM-based dialogue systems. 2025. arXiv:2412.15557v3
-
[32]
ReliabilityBench: evaluating LLM agent reliability under production-like stress conditions, 2026
Aayush Gupta. ReliabilityBench: evaluating LLM agent reliability under production-like stress conditions, 2026. arXiv: 2601.06112
-
[33]
LLM-assisted metamorphic testing of embedded graphics libraries
Christoph Hazott and Daniel Große. LLM-assisted metamorphic testing of embedded graphics libraries. InForum on Specification and Design Languages, pages 1–10, 2025
work page 2025
-
[34]
MTF: an open-source metamorphic testing framework for LLM-based systems
Theis Henry, Sian Savourat, Lydie du Bousquet, and Masahide Nakamura. MTF: an open-source metamorphic testing framework for LLM-based systems. InProceedings of the International Conference on Artificial Intelligence and Application Technologies, pages 62–66, 2025
work page 2025
-
[35]
Shahin Honarvar, Mark van der Wilk, and Alastair F Donaldson. Turbulence: systematically and automatically testing instruction-tuned large language models for code. InIEEE Conference on Software Testing, Verification and Validation, pages 80–91, 2025
work page 2025
-
[36]
Max Hort, Linas Vidziunas, and Leon Moonen. Semantic-preserving transformations as mutation operators: a study on their effectiveness in defect detection. InIEEE International Conference on Software Testing, Verification and Validation Workshops, pages 337–346, 2025
work page 2025
-
[37]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large language models for software engineering: a systematic literature review.ACM Transactions on Software Engineering and Methodology, 33(8):1–79, 2024
work page 2024
-
[38]
Jun Huang, Meng Li, Xiaohua Yang, Jie Liu, and Shiyu Yan. SVPrompt-MR: an LLM-based metamorphic relation identification method with self-verification mechanism. InProceedings of the Asia-Pacific Software Engineering Conference, pages 503–514, 2025
work page 2025
-
[39]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
work page 2025
-
[40]
Sangwon Hyun, Shaukat Ali, and M Ali Babar. Search-based selection of metamorphic relations for optimized robustness testing of large language models, 2025. arXiv: 2507.05565
-
[41]
Metal: metamorphic testing framework for analyzing large-language model qualities
Sangwon Hyun, Mingyu Guo, and M Ali Babar. Metal: metamorphic testing framework for analyzing large-language model qualities. InIEEE Conference on Software Testing, Verification and Validation, pages 117–128, 2024
work page 2024
-
[42]
Guna Sekaran Jaganathan, Indika Kahanda, and Upulee Kanewala. Metamorphic testing for robustness and fairness evaluation of LLM-based automated ICD coding applications.Smart Health, 36:100564, 2025
work page 2025
-
[43]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
work page 2023
-
[44]
Mingyue Jiang, Bintao Hu, and Xiao-Yi Zhang. Metamorphic testing for textual and visual entailment: a unified framework for model evaluation and explanation.Information and Software Technology, page 107855, 2025
work page 2025
-
[45]
Shan Jiang, Chenguang Zhu, and Sarfraz Khurshid. OBsmith: LLM-powered JavaScript obfuscator testing.Proceedings of the ACM on Programming Languages, 10:1–29, 2026
work page 2026
-
[46]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. arXiv: 2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[47]
Examining LLMs ability to summarize code through mutation-analysis, 2026
Lara Khatib, Micheal Pu, Bogdan Vasilescu, and Meiyappan Nagappan. Examining LLMs ability to summarize code through mutation-analysis, 2026. arXiv: 2602.17838
-
[48]
Metamorphic evaluation of ChatGPT as a recommender system, 2024
Madhurima Khirbat, Yongli Ren, Pablo Castells, and Mark Sanderson. Metamorphic evaluation of ChatGPT as a recommender system, 2024. arXiv: 2411.12121
-
[49]
Procedures for performing systematic reviews
Barbara Kitchenham. Procedures for performing systematic reviews. Technical report, Keele University, 2004
work page 2004
-
[50]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems, volume 35, pages 22199–22213, 2022
work page 2022
-
[51]
Hyeonseok Lee, Gabin An, and Shin Yoo. Metamon: finding inconsistencies between program documentation and behavior using metamorphic LLM queries. InIEEE/ACM International Workshop on Large Language Models for Code, pages 120–127, 2025
work page 2025
-
[52]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, ACM Comput. Surv., V...
work page 2026
-
[53]
Ningke Li, Yuekang Li, Yi Liu, Ling Shi, Kailong Wang, and Haoyu Wang. Drowzee: metamorphic testing for fact- conflicting hallucination detection in large language models.Proceedings of the ACM on Programming Languages, 8:1843–1872, 2024
work page 2024
-
[54]
Detecting LLM fact-conflicting hallucinations enhanced by temporal-logic-based reasoning, 2025
Ningke Li, Yahui Song, Kailong Wang, Yuekang Li, Ling Shi, Yi Liu, and Haoyu Wang. Detecting LLM fact-conflicting hallucinations enhanced by temporal-logic-based reasoning, 2025. arXiv: 2502.13416
-
[55]
Rui Li, Huai Liu, Pak-Lok Poon, Dave Towey, Chang-Ai Sun, Zheng Zheng, Zhi Quan Zhou, and Tsong Yueh Chen. Metamorphic relation generation: state of the art and research directions.ACM Transactions on Software Engineering and Methodology, 34(5):1–25, 2025
work page 2025
-
[56]
Detecting bias in LLMs’ natural language inference using metamorphic testing
Zhahao Li, Jinfu Chen, Haibo Chen, Leyang Xu, and Wuhao Guo. Detecting bias in LLMs’ natural language inference using metamorphic testing. InIEEE International Conference on Software Quality, Reliability, and Security Companion, pages 31–37, 2024
work page 2024
-
[57]
Evaluating LLM’s code reading abilities in big data contexts using metamorphic testing
Ziyu Li, Zhendu Li, Kaiming Xiao, and Xuan Li. Evaluating LLM’s code reading abilities in big data contexts using metamorphic testing. InInternational Conference on Big Data and Information Analytics, pages 232–239, 2023
work page 2023
-
[58]
Zongjie Li, Wenying Qiu, Pingchuan Ma, Yichen Li, You Li, Sijia He, Baozheng Jiang, Shuai Wang, and Weixi Gu. An empirical study on large language models in accuracy and robustness under chinese industrial scenarios, 2024. arXiv: 2402.01723
-
[59]
VRPTEST: evaluating visual referring prompting in large multimodal models, 2023
Zongjie Li, Chaozheng Wang, Chaowei Liu, Pingchuan Ma, Daoyuan Wu, Shuai Wang, and Cuiyun Gao. VRPTEST: evaluating visual referring prompting in large multimodal models, 2023. arXiv: 2312.04087
-
[60]
Cctest: testing and repairing code completion systems
Zongjie Li, Chaozheng Wang, Zhibo Liu, Haoxuan Wang, Dong Chen, Shuai Wang, and Cuiyun Gao. Cctest: testing and repairing code completion systems. InIEEE/ACM International Conference on Software Engineering, pages 1238–1250, 2023
work page 2023
-
[61]
Linfeng Liang, Chenkai Tan, Yao Deng, Yingfeng Cai, Tsong Yueh Chen, and Xi Zheng. AutoMT: a multi-agent LLM framework for automated metamorphic testing of autonomous driving systems, 2025. arXiv: 2510.19438
-
[62]
Li Lin, Qinglin Zhu, Hongqiao Chen, Zhuangda Wang, Rongxin Wu, and Xiaoheng Xie. QTRAN: extending metamorphic-oracle based logical bug detection techniques for multiple-dbms dialect support.Proceedings of the ACM on Software Engineering, 2:731–752, 2025
work page 2025
-
[63]
Li Lin, Qinglin Zhu, Jintai Hong, Chong Wang, Yang Liu, and Rongxin Wu. Validating LLM-generated SQL queries through metamorphic prompting.Proceedings of the ACM on Software Engineering, 3:1–23, 2026
work page 2026
-
[64]
Testing question answering software with context-driven question generation, 2025
Shuang Liu, Zhirun Zhang, Jinhao Dong, Zan Wang, Qingchao Shen, Junjie Chen, Wei Lu, and Xiaoyong Du. Testing question answering software with context-driven question generation, 2025. arXiv: 2511.07924
-
[65]
Can ChatGPT advance software testing intelligence? an experience report on metamorphic testing, 2023
Quang-Hung Luu, Huai Liu, and Tsong Yueh Chen. Can ChatGPT advance software testing intelligence? an experience report on metamorphic testing, 2023. arXiv: 2310.19204
-
[66]
Pingchuan Ma, Zhaoyu Wang, Zongjie Li, Zhenlan Ji, Ao Sun, Juergen Rahmel, and Shuai Wang. Reeq: testing and mitigating ethically inconsistent suggestions of large language models with reflective equilibrium.ACM Transactions on Software Engineering and Methodology, 35(1):1–27, 2025
work page 2025
-
[67]
Potsawee Manakul, Adian Liusie, and Mark J. F Gales. SelfCheckGPT: zero-resource black-box hallucination detection for generative large language models, 2023. arXiv: 2303.08896
work page internal anchor Pith review arXiv 2023
-
[68]
Multi-level testing of conversational ai systems, 2026
Elena Masserini. Multi-level testing of conversational ai systems, 2026. arXiv: 2602.03311
-
[69]
DILLEMA: metamorphic testing for deep learning using diffusion and large language models
Muhammad Irfan Mas’udi. DILLEMA: metamorphic testing for deep learning using diffusion and large language models. Master’s thesis, Politecnico di Milano, 2023
work page 2023
-
[70]
Facundo Molina, Alessandra Gorla, and Marcelo d’Amorim. Test oracle automation in the era of LLMs.ACM Transactions on Software Engineering and Methodology, 34(5):1–24, 2025
work page 2025
-
[71]
Automating bias testing of LLMs
Sergio Morales, Robert Clarisó, and Jordi Cabot. Automating bias testing of LLMs. InIEEE/ACM International Conference on Automated Software Engineering, pages 1705–1707, 2023
work page 2023
-
[72]
StaAgent: an agentic framework for testing static analyzers, 2025
Elijah Nnorom, Md Basim Uddin Ahmed, Jiho Shin, Hung Viet Pham, and Song Wang. StaAgent: an agentic framework for testing static analyzers, 2025. arXiv: 2507.15892
-
[73]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. ...
work page 2022
-
[74]
Metamorphic-based many-objective distillation of LLMs for code-related tasks
Annibale Panichella. Metamorphic-based many-objective distillation of LLMs for code-related tasks. InIEEE/ACM International Conference on Software Engineering, pages 766–766, 2025
work page 2025
-
[75]
Generative agents: interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: interactive simulacra of human behavior. InACM Symposium on User Interface Software and Technology, pages 1–22, 2023. ACM Comput. Surv., Vol. 1, No. 1, Article . Publication date: May 2026. 34 Zheng et al
work page 2023
-
[76]
Alessandra Parziale, Gianmario Voria, Valeria Pontillo, Gemma Catolino, Andrea De Lucia, and Fabio Palomba. Toward systematic counterfactual fairness evaluation of large language models: the CAFFE framework, 2025. arXiv: 2512.16816
-
[77]
Harishwar Reddy, Madhusudan Srinivasan, and Upulee Kanewala. Metamorphic testing for fairness evaluation in large language models: identifying intersectional bias in LLaMA and GPT. InIEEE/ACIS International Conference on Software Engineering Research, Management and Applications, pages 239–246, 2025
work page 2025
-
[78]
Beyond accuracy: behavioral testing of nlp models with CheckList
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: behavioral testing of nlp models with CheckList. InProceedings of the Annual Meeting of the Association for Computational Linguistics, pages 4902–4912, 2020
work page 2020
-
[79]
Meta-Fair: metamorphic testing of fairness in large language models
Miguel Romero-Arjona, José A Parejo, Juan C Alonso, Ana B Sánchez, Aitor Arrieta, and Sergio Segura. Meta-Fair: metamorphic testing of fairness in large language models. InJornadas de Ingenierıa del Software y Bases de Datos, 2025
work page 2025
-
[80]
Revealing the fairness issues of text-to-image generation models based on metamorphic testing
MengYao Ruan, Ya Pan, and Yong Fan. Revealing the fairness issues of text-to-image generation models based on metamorphic testing. InInternational Congress on Image and Signal Processing, BioMedical Engineering and Informatics, pages 1–6, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.