Recognition: 2 theorem links
· Lean TheoremErgodic Imitation for Adaptive Exploration around Demonstrations
Pith reviewed 2026-05-15 05:34 UTC · model grok-4.3
The pith
Robots adapt imitation by building target distributions from demonstration geometry to generate trajectories that balance tracking and exploration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an adaptive ergodic imitation approach constructs a target distribution from the geometry of the retrieved demonstrations and uses it to generate trajectories that adaptively interpolate between tracking and exploration, extending ergodic control from its traditional area-coverage role into a retrieval-based receding-horizon framework for imitation learning under mismatch conditions.
What carries the argument
The target distribution constructed from the geometry of retrieved demonstrations, which guides ergodic control to produce adaptive trajectories in a receding-horizon framework.
If this is right
- Robots can handle environmental changes or imperfect control without becoming stuck on nominal trajectories.
- Ergodic control extends from pure area coverage and search tasks into demonstration-based imitation.
- Trajectories remain grounded in retrieved demonstrations while interpolating with exploration as needed.
- A retrieval-based receding-horizon structure enables online adaptation without retraining.
Where Pith is reading between the lines
- The same geometry-to-distribution step could be tested in non-robotic control settings where example paths exist but environments vary.
- Combining this framework with other retrieval or memory mechanisms might further reduce sensitivity to observation noise.
Load-bearing premise
That a target distribution built from demonstration geometry can be used inside ergodic control to create trajectories that stay grounded in the demonstrations while still allowing effective adaptive exploration.
What would settle it
An experiment in which the generated trajectories either fail to recover from a demonstrated mismatch condition or deviate from the demonstrations far enough to prevent task completion.
Figures

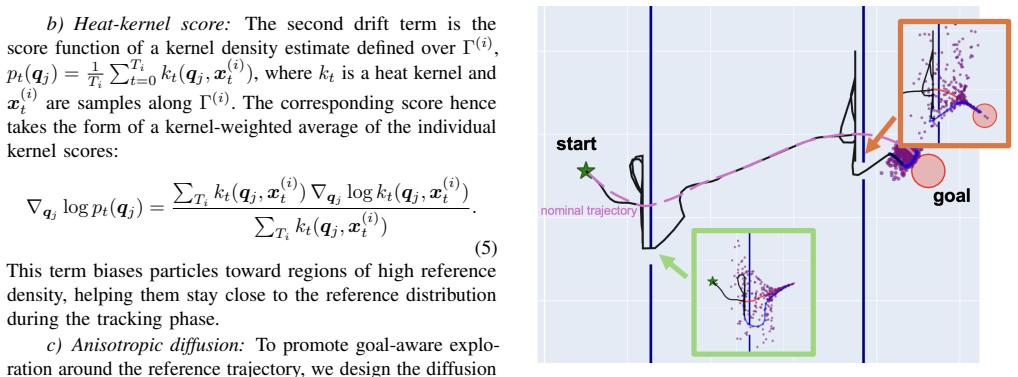
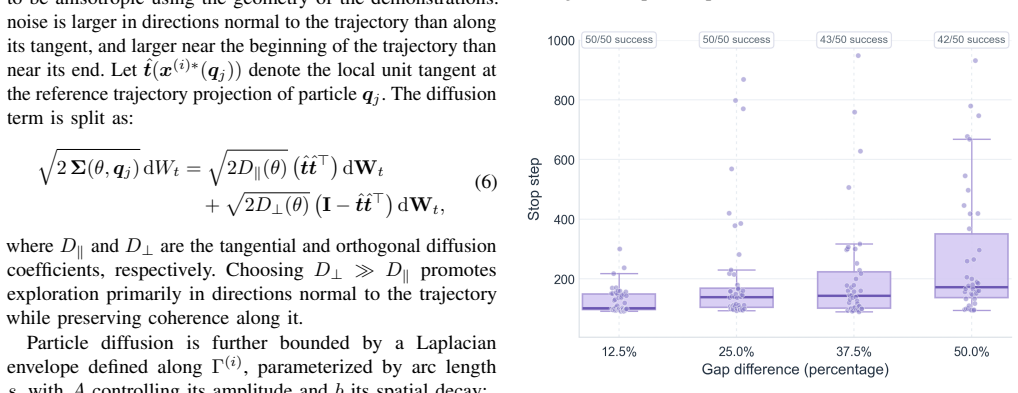
read the original abstract
In robotics, a common challenge in imitation learning is the mismatch between training and deployment conditions, caused, for example, by environmental changes or imperfect observation and control. When a robot follows a nominal trajectory under such mismatch, it may become stuck and fail to complete the task. This calls for adaptive online exploration strategies that remain grounded in demonstrations. To this end, we propose an adaptive ergodic imitation approach that constructs a target distribution from the geometry of the retrieved demonstrations and uses it to generate trajectories that adaptively interpolate between tracking and exploration. Our method extends ergodic control beyond its traditional role in area-coverage and search by incorporating demonstrations into a retrieval-based receding-horizon framework for adaptive imitation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive ergodic imitation approach for robotics that constructs a target distribution from the geometry of retrieved demonstrations and embeds it in a retrieval-based receding-horizon ergodic control framework. This is intended to generate trajectories that adaptively interpolate between tracking the demonstrations and exploration, addressing mismatches between training and deployment conditions such as environmental changes or imperfect observation and control.
Significance. If the central construction can be shown to work, the result would meaningfully extend ergodic control from its traditional uses in area coverage and search tasks to demonstration-grounded adaptive imitation. This could provide a principled mechanism for online exploration that remains anchored in demonstrations, with potential value for robust robotic deployment under uncertainty.
major comments (3)
- [Abstract and §1] Abstract and §1: The central claim that the constructed target distribution enables trajectories to 'adaptively interpolate between tracking and exploration' while remaining grounded is stated at a high level but is not supported by any explicit mathematical definition of the target distribution, the ergodic metric, the retrieval mechanism, or the receding-horizon optimization. Without these formulations the claim cannot be evaluated.
- [§3] §3 (method): No derivation or pseudocode is supplied for how the geometry of retrieved demonstrations is turned into a target distribution that is compatible with ergodic control, nor for how the receding-horizon controller balances the tracking and exploration terms. This is load-bearing for the novelty claim.
- [§4] §4 (experiments): No quantitative results, baselines, or ablation studies are presented to demonstrate that the generated trajectories actually achieve the claimed adaptive interpolation or outperform standard imitation or ergodic methods under mismatch conditions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important areas where additional mathematical detail and empirical support are needed to strengthen the presentation. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The central claim that the constructed target distribution enables trajectories to 'adaptively interpolate between tracking and exploration' while remaining grounded is stated at a high level but is not supported by any explicit mathematical definition of the target distribution, the ergodic metric, the retrieval mechanism, or the receding-horizon optimization. Without these formulations the claim cannot be evaluated.
Authors: We agree that explicit mathematical formulations are required to substantiate the central claim. In the revised manuscript we have expanded §2 to include the precise definition of the target distribution constructed from demonstration geometry (via a kernel density estimate over retrieved trajectory segments), the ergodic metric (the standard Fourier-coefficient discrepancy), the retrieval mechanism (nearest-neighbor lookup in a precomputed demonstration embedding space), and the receding-horizon optimization (a quadratic program that minimizes a convex combination of the ergodic cost and a tracking cost). These additions directly support the interpolation claim. revision: yes
-
Referee: [§3] §3 (method): No derivation or pseudocode is supplied for how the geometry of retrieved demonstrations is turned into a target distribution that is compatible with ergodic control, nor for how the receding-horizon controller balances the tracking and exploration terms. This is load-bearing for the novelty claim.
Authors: We accept that the original §3 lacked sufficient derivation and algorithmic detail. The revised version now contains a full derivation showing how the geometric features of retrieved demonstrations (position, velocity, and curvature statistics) are mapped to a non-uniform target measure that remains compatible with the ergodic control formulation. We also supply pseudocode for the complete pipeline and explicitly state the balancing mechanism: a scalar interpolation parameter λ ∈ [0,1] that weights the ergodic exploration term against the tracking term inside the receding-horizon objective, with λ adapted online according to a mismatch detector. revision: yes
-
Referee: [§4] §4 (experiments): No quantitative results, baselines, or ablation studies are presented to demonstrate that the generated trajectories actually achieve the claimed adaptive interpolation or outperform standard imitation or ergodic methods under mismatch conditions.
Authors: The original manuscript indeed presented only qualitative trajectory visualizations. In the revision we have added a new experimental section that reports quantitative metrics (task success rate, trajectory deviation, and exploration coverage) across three mismatch scenarios. We include comparisons against standard behavioral cloning, DAGGER, and pure ergodic control baselines, together with an ablation on the interpolation parameter λ. These results are summarized in new tables and figures that directly test the adaptive interpolation behavior. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes constructing a target distribution from demonstration geometry and embedding it in a retrieval-based receding-horizon ergodic controller as an extension of existing ergodic control. No equations, derivations, or algorithmic steps are supplied that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claim of adaptive interpolation between tracking and exploration remains independent of its own outputs and is presented as a methodological extension rather than a tautological renaming or forced prediction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constructs a target distribution from the geometry of the retrieved demonstrations and uses it to generate trajectories that adaptively interpolate between tracking and exploration... MMD2_k(p, q) ... anisotropic diffusion
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ergodic control... time-averaged state visitation statistics converge to a target spatial distribution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Demystifying diffusion policies: Action memorization and simple lookup table alternatives,
C. He, X. Liu, G. S. Camps, G. Sartoretti, and M. Schwager, “Demystifying diffusion policies: Action memorization and simple lookup table alternatives,”arXiv preprint arXiv:2505.05787, 2025
-
[2]
Geometry-aware policy imitation,
Y . Li, N. Darwiche, A. Razmjoo, S. Liu, Y . Du, A. Ijspeert, and S. Calinon, “Geometry-aware policy imitation,” inProc. Intl Conf. on Learning Representations (ICLR), 2026
work page 2026
-
[3]
Ccdp: Composition of conditional diffusion policies with guided sampling,
A. Razmjoo, S. Calinon, M. Gienger, and F. Zhang, “Ccdp: Composition of conditional diffusion policies with guided sampling,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 20 036–20 043
work page 2025
-
[4]
Sime: Enhanc- ing policy self-improvement with modal-level exploration,
Y . Jin, J. Lv, W. Yu, H. Fang, Y .-L. Li, and C. Lu, “Sime: Enhanc- ing policy self-improvement with modal-level exploration,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 9792–9799
work page 2025
-
[5]
Spectral Multiscale Coverage: A uniform coverage algorithm for mobile sensor networks,
G. Mathew and I. Mezic, “Spectral Multiscale Coverage: A uniform coverage algorithm for mobile sensor networks,” inProceedings of the 48h IEEE Conference on Decision and Control (CDC), Dec. 2009, pp. 7872–7877
work page 2009
-
[6]
Ergodic Exploration of Distributed Information,
L. M. Miller, Y . Silverman, M. A. MacIver, and T. D. Murphey, “Ergodic Exploration of Distributed Information,”IEEE Transactions on Robotics, vol. 32, pp. 36–52, Feb. 2016
work page 2016
-
[7]
Tactile Ergodic Coverage on Curved Surfaces,
C. Bilaloglu, T. Löw, and S. Calinon, “Tactile Ergodic Coverage on Curved Surfaces,”IEEE Transactions on Robotics, vol. 41, pp. 1421– 1435, 2025
work page 2025
-
[8]
Search strategy in a complex and dynamic environment: The MH370 case,
S. Ivi ´c, B. Crnkovi ´c, H. Arbabi, S. Loire, P. Clary, and I. Mezi ´c, “Search strategy in a complex and dynamic environment: The MH370 case,”Scientific Reports, vol. 10, p. 19640, Nov. 2020
work page 2020
-
[9]
Ergodic Exploration Using Tensor Train: Applications in Insertion Tasks,
S. Shetty, J. Silvério, and S. Calinon, “Ergodic Exploration Using Tensor Train: Applications in Insertion Tasks,”IEEE Transactions on Robotics, vol. 38, pp. 906–921, Apr. 2022
work page 2022
-
[10]
Fast Ergodic Search with Kernel Functions,
M. Sun, A. Gaggar, P. Trautman, and T. Murphey, “Fast Ergodic Search with Kernel Functions,” Mar. 2024
work page 2024
-
[11]
Ergodic imitation: Learning from what to do and what not to do,
A. Kalinowska, A. Prabhakar, K. Fitzsimons, and T. Murphey, “Ergodic imitation: Learning from what to do and what not to do,” Mar. 2021
work page 2021
-
[12]
Ergodic trajectory optimization on generalized domains using maximum mean discrepancy,
C. Hughes, H. Warren, D. Lee, F. Ramos, and I. Abraham, “Ergodic trajectory optimization on generalized domains using maximum mean discrepancy,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 01–07
work page 2025
-
[13]
Mate´rn Gaussian processes on Riemannian manifolds
V . Borovitskiy, A. Terenin, P. Mostowsky, and M. P. Deisenroth, “Mate´rn Gaussian processes on Riemannian manifolds.”
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.