Recognition: 3 theorem links
· Lean TheoremPolitNuggets: Benchmarking Agentic Discovery of Long-Tail Political Facts
Pith reviewed 2026-05-15 05:50 UTC · model grok-4.3
The pith
Current AI agents struggle with fine-grained long-tail political facts and show wide variation in discovery efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce PolitNuggets, a multilingual benchmark for agentic information synthesis via constructing political biographies for 400 global elites, covering over 10000 political facts. We standardize evaluation with an optimized multi agent system and propose FactNet, an evidence conditional protocol that scores discovery, fine-grained accuracy, and efficiency. Across models and settings, we find that current systems often struggle with fine-grained details, and vary substantially in efficiency. Finally, using benchmark diagnostics, we relate agent performance to underlying model capabilities, highlighting the importance of short-context extraction, multilingual robustness, and reliable tool
What carries the argument
PolitNuggets benchmark and FactNet evidence-conditional scoring protocol, which turn biography construction into a standardized test of open-ended fact discovery from dispersed sources.
Load-bearing premise
The more than 10,000 political facts collected for the 400 biographies represent accurate ground-truth long-tail information drawn correctly from scattered sources, and the FactNet protocol accurately measures genuine agentic discovery ability in the real world.
What would settle it
Independent fact-checking of the biographies revealing substantial errors in the assembled facts, or live agent tests outside the benchmark showing no correlation with FactNet scores.
Figures






read the original abstract
Large Reasoning Models (LRMs) embedded in agentic frameworks have transformed information retrieval from static, long context question answering into open-ended exploration. Yet real world use requires models to discover and synthesize "long-tail" facts from dispersed sources, a capability that remains under-evaluated. We introduce PolitNuggets, a multilingual benchmark for agentic information synthesis via constructing political biographies for 400 global elites, covering over 10000 political facts. We standardize evaluation with an optimized multi agent system and propose FactNet, an evidence conditional protocol that scores discovery, fine-grained accuracy, and efficiency. Across models and settings, we find that current systems often struggle with fine-grained details, and vary substantially in efficiency. Finally, using benchmark diagnostics, we relate agent performance to underlying model capabilities, highlighting the importance of short-context extraction, multilingual robustness, and reliable tool use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolitNuggets, a multilingual benchmark for agentic discovery of long-tail political facts, constructed from over 10,000 facts across biographies of 400 global elites. It proposes the FactNet evidence-conditional protocol to evaluate agentic systems on discovery, fine-grained accuracy, and efficiency using an optimized multi-agent setup. The work reports that current LRMs struggle with fine-grained details and vary substantially in efficiency, while linking performance diagnostics to underlying capabilities such as short-context extraction, multilingual robustness, and reliable tool use.
Significance. If the assembled facts constitute reliable ground truth, PolitNuggets would provide a useful benchmark for evaluating open-ended agentic information synthesis in a high-stakes domain, moving beyond static QA to dispersed-source discovery. The capability diagnostics could inform targeted improvements in tool use and context handling for LRMs.
major comments (3)
- [Benchmark construction] Benchmark construction section: the claim that the >10,000 facts are accurate long-tail ground truth extracted from dispersed primary sources is load-bearing for all accuracy and diagnostic results, yet no verification procedure, inter-annotator agreement, or independent cross-check is described; without this the reported struggles with fine-grained details cannot be interpreted.
- [FactNet protocol] FactNet protocol section: the evidence-conditional scoring mechanism for distinguishing successful discovery from hallucination or partial matches is not fully specified (e.g., how evidence is matched or partial credit assigned), which directly affects the validity of the efficiency and accuracy metrics reported across models.
- [Evaluation setup] Evaluation setup: the 'optimized multi-agent system' used for standardization is referenced but its architecture, optimization objective, and hyper-parameters are not detailed, making it impossible to assess whether the reported performance gaps are attributable to the agents or to the benchmark itself.
minor comments (2)
- [Abstract] Abstract: the phrase 'optimized multi agent system' is used without defining the optimization criteria or baseline comparison.
- [Introduction] Notation: 'FactNet' and 'PolitNuggets' are introduced as new entities; ensure consistent capitalization and acronym expansion on first use in the main text.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. We address each major comment point by point below and will revise the manuscript to improve clarity, reproducibility, and transparency.
read point-by-point responses
-
Referee: Benchmark construction section: the claim that the >10,000 facts are accurate long-tail ground truth extracted from dispersed primary sources is load-bearing for all accuracy and diagnostic results, yet no verification procedure, inter-annotator agreement, or independent cross-check is described; without this the reported struggles with fine-grained details cannot be interpreted.
Authors: We agree that the verification details require expansion for full interpretability. The facts were assembled via a multi-stage human curation process drawing from primary sources (official records, verified archives, and biographical databases), with cross-validation by multiple annotators. We will add a dedicated subsection to the benchmark construction section that specifies the annotation protocol, reports inter-annotator agreement, and describes the independent cross-check procedure. This revision will directly support the validity of the accuracy and diagnostic findings. revision: yes
-
Referee: FactNet protocol section: the evidence-conditional scoring mechanism for distinguishing successful discovery from hallucination or partial matches is not fully specified (e.g., how evidence is matched or partial credit assigned), which directly affects the validity of the efficiency and accuracy metrics reported across models.
Authors: We acknowledge that the precise matching and credit-assignment rules need fuller specification. FactNet employs hybrid evidence matching (exact string match for entities and numbers; embedding-based semantic similarity for descriptive content) and assigns partial credit proportionally to the fraction of verified facts while penalizing unsupported claims. We will revise the FactNet protocol section to include explicit matching criteria, the partial-credit formula, and worked examples, ensuring the efficiency and accuracy metrics can be properly evaluated. revision: yes
-
Referee: Evaluation setup: the 'optimized multi-agent system' used for standardization is referenced but its architecture, optimization objective, and hyper-parameters are not detailed, making it impossible to assess whether the reported performance gaps are attributable to the agents or to the benchmark itself.
Authors: We agree that the multi-agent system description is insufficiently detailed. The system uses a coordinator-retriever-synthesizer architecture optimized to maximize fact coverage while constraining tool-call cost. We will expand the evaluation setup section and add an appendix that fully specifies the agent roles, the reward function used for optimization, and all relevant hyper-parameters and prompt templates. This will allow readers to attribute performance differences correctly. revision: yes
Circularity Check
No circularity detected in benchmark construction or evaluation
full rationale
The paper introduces PolitNuggets and the FactNet protocol as new artifacts for benchmarking agentic discovery of long-tail facts, with evaluation results presented as direct empirical measurements on the constructed dataset of 400 biographies and 10,000+ facts. No equations, predictions, or first-principles derivations are claimed that reduce by construction to fitted inputs, self-definitions, or self-citations. The reported struggles with fine-grained details and efficiency variations are observational outcomes on the benchmark rather than quantities forced by the protocol's own definitions. The ground-truth assembly is treated as an external input to the evaluation, with no load-bearing step that renames or recycles the benchmark's own outputs as independent evidence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Political facts for global elites can be accurately assembled from dispersed sources as long-tail information
- domain assumption Multi-agent systems can be optimized to provide standardized evaluation of discovery tasks
invented entities (2)
-
PolitNuggets
no independent evidence
-
FactNet
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce PolitNuggets, a multilingual benchmark for agentic information synthesis via constructing political biographies for 400 global elites, covering over 10,000 political facts... FactNet, an evidence-conditional protocol that scores discovery, fine-grained accuracy, and efficiency.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We conceptualize political biography reconstruction not as single-shot retrieval, but as traversing a latent fact network... optimization trilemma over correctness, coverage, and cost.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
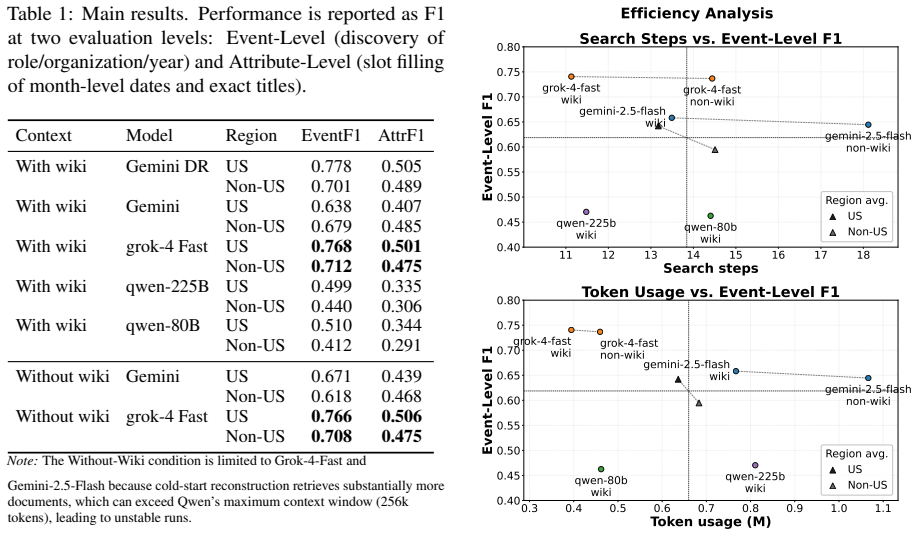
Finding 3: Wiki removal reveals efficiency gap... Grok typically achieves comparable F1 with fewer steps.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
WebGPT: Browser-assisted question-answering with human feedback
GAIA: a benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations (ICLR). Accessed: 2026-01-06. Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin B...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
InThe Twelfth In- ternational Conference on Learning Representations (ICLR)
WebArena: A Realistic Web Environment for Building Autonomous Agents. InThe Twelfth In- ternational Conference on Learning Representations (ICLR). 9 Limitations First, due to budget constraints and practical model selection, we do not evaluate the largest and most expensive frontier-scale models. Such models may reveal a clearer connection (or a different...
-
[3]
Consolidated Ground Truth (CGT).The final pooled, evidence-verified biography nuggets for all 400 entities (including the Wikipedia-coverage filter We), which define the evaluation target G and the dynamic nov- elty setG ′
-
[4]
Cached webpages.The raw retrieved web pages collected during our agentic runs, fix- ing the search snapshot used for all reported numbers and enabling offline re-evaluation
-
[5]
LRM evaluation package.A curated static- context dataset (Archive-style short context and long-context corpora derived from the cached pages) for evaluating long-context bi- ography extraction without interactive search, enabling controlled comparison of “Reason- inginContext” across models. All LRM-baseline and FactNet evaluation proce- dures are fully s...
-
[6]
Update ‘global_summary‘ so it is a readable, self-contained summary of all solid facts found so far
-
[7]
Update ‘todo_list‘ so it reflects the remaining important gaps
-
[8]
Decide to either CONTINUE (delegate one focused next task) or FINISH (no more search). OUTPUT FORMAT (JSON ONLY, no extra text, no markdown fences): { "todo_list": "...", "next_task_instruction": "... or null", "global_summary": "..." } Field rules: - ‘global_summary‘: - Treat as the single evolving research summary. - Start from the previous global_summa...
-
[9]
Search web for relevant information, Retrieve for detailed review, Archive relevant information
-
[10]
Handoff to the supervisor if collected enough information. ### Execute Search - Call ‘web_search(search_intent=...)‘ with a structured search plan - ‘any_of‘ means at least one of the terms in the list should appear in results. - ‘must_include‘ means all of the terms in the list must appear in results. - ‘must_not_include‘ means none of the terms in the l...
-
[11]
Execute broad searches for "{current_name}" to gather a holistic view: basic biographical details (birth/death, family), main career milestones, education, and political affiliations simultaneously
-
[12]
Construct an initial timeline skeleton from the broad results, capturing all immediately available years, roles, and organizations
-
[13]
# Phase 2: Targeted Expansion & Detail Enrichment
Identify unique identifiers (e.g., specific keywords, middle names, known associations) to disambiguate from homonyms. # Phase 2: Targeted Expansion & Detail Enrichment
- [14]
-
[15]
- Party History: Clarify roles and affiliation periods
Specifically expand on known entities to get granular details: - Education: Verify degrees, majors, and institutions. - Party History: Clarify roles and affiliation periods. - Career: Flesh out concurrent roles and specific job titles using organization-specific keywords. # Phase 3: Gap Analysis & Narrative Synthesis
-
[16]
Analyze the timeline for chronological gaps (especially within age 18-65). Perform specific queries to fill these gaps (e.g., check for private sector work or unlisted periods)
-
[17]
Re-verify any ambiguous data points (e.g., relatives, death date if unclear) and finalize the dataset
-
[18]
Synthesize all verified data into a cohesive narrative biography (>=600 characters). A.5.3 Evaluation prompts Fact-checking (related-content judge) prompt. You are a careful fact-checking assistant. Your task is to evaluate **one biographical fact** about a person using ONLY the provided related content (snippets aggregated from multiple URLs). Person ide...
-
[19]
**Be consistent**: Apply the same standards across all entries
- [20]
-
[21]
**Empty lines**: Ignore empty lines when counting and evaluating
-
[22]
current date is 2025-11-25 --- ## Input Data ### CGT BIOGRAPHY (Ground Truth): ‘‘‘text {cgt_biography} ‘‘‘ ### CANDIDATE BIOGRAPHY (Experiment: {experiment_type}): ‘‘‘text {experiment_biography} ‘‘‘ --- ## Output Format Produce a JSON object with exactly these fields: - ‘official_id‘: string (copy from input: "{official_id}") - ‘official_name‘: string (co...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.