Recognition: unknown
Mistletoe: Stealthy Acceleration-Collapse Attacks on Speculative Decoding
Pith reviewed 2026-05-15 05:36 UTC · model grok-4.3
The pith
Mistletoe attacks collapse speculative decoding speedup by slashing average accepted draft length while leaving output quality unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
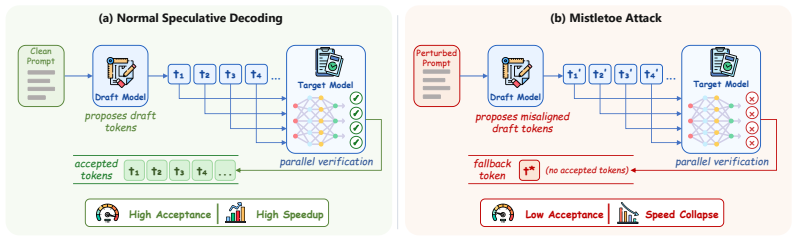
Mistletoe jointly optimizes a degradation objective that decreases drafter-target agreement and a semantic-preservation objective that constrains the target model's output distribution. It resolves the conflict by projecting degradation gradients into the null space away from the local semantic-preserving direction, suppressing draft acceptance while minimizing semantic drift. Experiments on various speculative decoding systems show that this substantially reduces average accepted length τ, collapses speedup, and lowers averaged token throughput, while preserving output quality and perplexity.
What carries the argument
Null-space projection mechanism that projects degradation gradients away from the local semantic-preserving direction to suppress draft acceptance while minimizing semantic drift.
If this is right
- Speculative decoding efficiency can be degraded by attacks that specifically target the acceptance mechanism rather than output semantics.
- Average accepted length τ becomes a critical but fragile metric for measuring real speedup.
- Standard quality metrics like perplexity fail to detect these attacks.
- LLM acceleration systems expose a mechanism-level attack surface that goes beyond conventional output robustness.
- Deployed speculative decoding requires new defenses focused on drafter-target agreement under perturbation.
Where Pith is reading between the lines
- The same projection technique could be tested against other draft-based acceleration methods such as speculative sampling variants.
- Real-time monitoring of sudden drops in acceptance rates might serve as a practical detection signal in production systems.
- Future drafter training could incorporate adversarial examples that simulate this style of degradation gradient to build robustness.
- Hardware-level mitigations, such as enforcing stricter acceptance thresholds, might limit the attack impact at the cost of some baseline speedup.
Load-bearing premise
Small perturbations can preserve the target model's visible behavior while substantially reducing draft-token acceptability via null-space projection of degradation gradients.
What would settle it
A controlled test finding that no perturbations reduce average accepted length τ by more than a small margin without also raising perplexity or shifting the target output distribution would falsify the central claim.
Figures


read the original abstract
Speculative decoding has become a widely adopted technique for accelerating large language model (LLM) inference by drafting multiple candidate tokens and verifying them with a target model in parallel. Its efficiency, however, critically depends on the average accepted length $\tau$, i.e., how many draft tokens survive each verification step. In this work, we identify a new mechanism-level vulnerability in model-based speculative decoding: the drafter is trained to approximate the target model distribution, but this approximation is inevitably imperfect. Such a drafter-target mismatch creates a hidden attack surface where small perturbations can preserve the target model's visible behavior while substantially reducing draft-token acceptability. We propose Mistletoe, a stealthy acceleration-collapse attack against speculative decoding. Mistletoe directly targets the acceptance mechanism of speculative decoding. It jointly optimizes a degradation objective that decreases drafter-target agreement and a semantic-preservation objective that constrains the target model's output distribution. To resolve the conflict between these objectives, we introduce a null-space projection mechanism, where degradation gradients are projected away from the local semantic-preserving direction, suppressing draft acceptance while minimizing semantic drift. Experiments on various speculative decoding systems show that Mistletoe substantially reduces average accepted length $\tau$, collapses speedup, and lowers averaged token throughput, while preserving output quality and perplexity. Our work highlights that speculative decoding introduces a mechanism-level attack surface beyond existing output robustness, calling for more robust designs of LLM acceleration systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mistletoe, a stealthy attack on model-based speculative decoding in LLMs. It exploits the inevitable drafter-target distribution mismatch by jointly optimizing a degradation objective (to reduce average accepted length τ) and a semantic-preservation objective, resolved via null-space projection of degradation gradients away from the local semantic direction. Experiments across various speculative decoding systems claim to show substantial drops in τ, collapsed speedup, and reduced token throughput while preserving output quality and perplexity.
Significance. If the central claims hold under rigorous validation, the work is significant because it identifies a new mechanism-level attack surface in widely deployed LLM acceleration techniques that goes beyond standard output robustness. The null-space projection is a technically interesting way to handle conflicting objectives without explicit parameter fitting. Demonstrating preservation of perplexity alongside attack success would be a notable strength, potentially motivating more robust speculative decoding designs.
major comments (2)
- [Method (null-space projection)] The null-space projection mechanism (described after the joint optimization objectives) is load-bearing for the stealth claim: it must exactly (or to machine precision) remove the component of the degradation gradient aligned with the semantic-preservation direction. The description implies a single projection per update, but does not specify whether the semantic direction is estimated from one forward pass (introducing noise) or how repeated projections over token sequences avoid cumulative distribution shift. If orthogonality is only approximate, the reported preservation of perplexity and output quality cannot be guaranteed.
- [Experiments section] The experimental claims of substantial reductions in τ, speedup collapse, and throughput (while preserving quality) lack supporting details on implementation, datasets, number of runs, error bars, or statistical significance tests. This is central to the main result and leaves the quantitative evidence with limited verifiable support.
minor comments (1)
- [Abstract] The abstract introduces τ as average accepted length without an explicit equation or reference to the standard speculative decoding formulation (e.g., the acceptance probability product), which may reduce accessibility for readers outside the subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, outlining clarifications and planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (null-space projection)] The null-space projection mechanism (described after the joint optimization objectives) is load-bearing for the stealth claim: it must exactly (or to machine precision) remove the component of the degradation gradient aligned with the semantic-preservation direction. The description implies a single projection per update, but does not specify whether the semantic direction is estimated from one forward pass (introducing noise) or how repeated projections over token sequences avoid cumulative distribution shift. If orthogonality is only approximate, the reported preservation of perplexity and output quality cannot be guaranteed.
Authors: We thank the referee for this observation on the null-space projection. The projection is formulated to be exact: at each update, the semantic-preservation direction is obtained directly from the current forward pass through the target model, and the degradation gradient is projected onto the orthogonal complement via standard linear algebra (subtracting the component along the normalized direction vector). We acknowledge that the manuscript description is concise and does not explicitly discuss recomputation frequency or potential accumulation of floating-point errors. In the revision we will insert a dedicated paragraph plus pseudocode that (i) states the direction is recomputed from a fresh forward pass at every token position, (ii) provides a short error-bound argument showing that per-step orthogonality is maintained to machine precision, and (iii) reports an empirical check confirming that cumulative distribution shift remains negligible across long sequences. These additions will directly support the claim that perplexity and output quality are preserved. revision: yes
-
Referee: [Experiments section] The experimental claims of substantial reductions in τ, speedup collapse, and throughput (while preserving quality) lack supporting details on implementation, datasets, number of runs, error bars, or statistical significance tests. This is central to the main result and leaves the quantitative evidence with limited verifiable support.
Authors: We agree that the current experimental reporting lacks the necessary detail for independent verification. In the revised manuscript we will add a new “Experimental Setup” subsection that specifies: (a) exact model pairs and drafter-target configurations, (b) the concrete datasets and evaluation splits employed, (c) the number of independent runs (five per configuration), (d) error bars reported as standard deviation across runs, and (e) the statistical tests performed (paired Wilcoxon signed-rank tests with p-values). Corresponding tables will be updated to include these metrics alongside the reported τ, speedup, and throughput figures. This expansion will make the quantitative evidence fully reproducible and address the referee’s concern. revision: yes
Circularity Check
No significant circularity; attack method is an independent optimization proposal
full rationale
The paper proposes Mistletoe as a novel joint optimization of degradation and semantic-preservation objectives, resolved by a null-space projection step. No equations, claims, or results reduce by construction to fitted parameters, self-citations, or renamed inputs. The central mechanism (projecting degradation gradients orthogonal to semantic direction) is introduced as a new technique rather than derived from prior work by the same authors. Experimental outcomes on τ reduction and quality preservation are presented as empirical findings, not forced predictions. This is a standard non-circular contribution for an attack paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Drafter is trained to approximate target model distribution but approximation is inevitably imperfect
Reference graph
Works this paper leans on
-
[1]
Hydra: Sequentially-dependent draft heads for medusa decoding
Zachary Ankner, Rishab Parthasarathy, Aniruddha Nrusimha, Christopher Rinard, Jonathan Ragan- Kelley, and William Brandon. Hydra: Sequentially-dependent draft heads for medusa decoding. arXiv preprint arXiv:2402.05109,
-
[2]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6,
work page 2023
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, March 2025
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Shi Jie, Xiang Wang, Xiangnan He, and Tat-Seng Chua. Alphaedit: Null-space constrained knowledge editing for language models.arXiv preprint arXiv:2410.02355,
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Shijing Hu, Jingyang Li, Xingyu Xie, Zhihui Lu, Kim-Chuan Toh, and Pan Zhou. Griffin: Effective token alignment for faster speculative decoding.arXiv preprint arXiv:2502.11018, 2025a. Yunhai Hu, Zining Liu, Zhenyuan Dong, Tianfan Peng, Bradley McDanel, and Sai Qian Zhang. Spec- ulative decoding and beyond: An in-depth survey of techniques.arXiv preprint a...
-
[10]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077, 2024a. Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees. InProceedings of the 2024 conference on empirical methods in natural...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Secdecoding: Steerable decoding for safer llm generation
Jiayou Wang, Rundong Liu, Yue Hu, Huijia Wu, and Zhaofeng He. Secdecoding: Steerable decoding for safer llm generation. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 20504–20521, 2025a. 10 Xuekang Wang, Shengyu Zhu, and Xueqi Cheng. Speculative safety-aware decoding. InProceedings of the 2025 Conference on Empirical Method...
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
11 A More Experimental Configuration We generate adversarial suffixes for text-based prompts to disrupt the efficiency of speculative decoding systems. We evaluate MISTLETOEon several widely used speculative decoding frameworks and describe their implementation settings below. Unless otherwise specified, all systems use their standard speculative decoding...
work page 2025
-
[15]
The null-space rejection weight is fixed to λ= 2.0 , corresponding to Eq
The semantic-preservation objective is estimated over 20 predictive positions. The null-space rejection weight is fixed to λ= 2.0 , corresponding to Eq. (10). The optimized suffix is directly appended to the clean input prompt. Dataset-specific KL bounds.To bound target-distribution drift during discrete candidate selection, we use dataset-specific KL thr...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.