Recognition: 2 theorem links
· Lean TheoremDywave: Event-Aligned Dynamic Tokenization for Heterogeneous IoT Sensing Signal
Pith reviewed 2026-05-15 05:40 UTC · model grok-4.3
The pith
Dywave uses wavelet decomposition to align tokens with semantic events in IoT signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
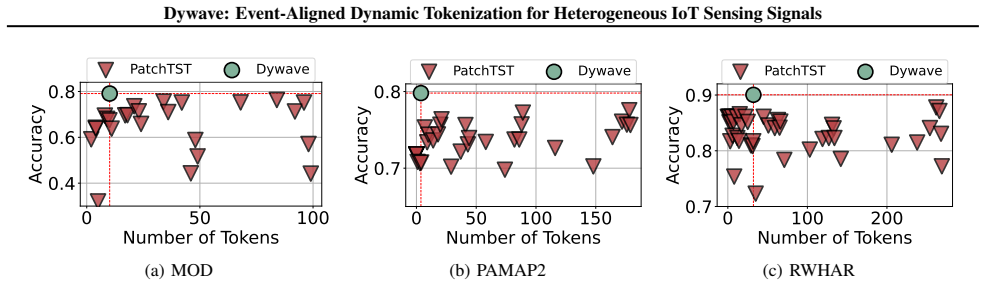
Dywave constructs compact input representations for heterogeneous IoT sensing signals by leveraging wavelet-based hierarchical decomposition to identify meaningful temporal boundaries that correspond to underlying semantic events, adaptively compresses redundant intervals while preserving temporal coherence, and thereby improves accuracy up to 12 percent while reducing token lengths up to 75 percent on activity recognition, stress assessment, and nearby object detection tasks.
What carries the argument
Wavelet-based hierarchical decomposition that identifies event-aligned temporal boundaries and adaptively compresses redundant intervals in non-stationary signals.
If this is right
- Mainstream sequence models receive shorter inputs and achieve up to 12 percent higher accuracy on IoT sensing tasks.
- Computational cost drops because token length is reduced by up to 75 percent.
- The same framework maintains performance across domain shifts and varying sequence lengths without retraining the tokenizer.
- One set of wavelet rules works across activity recognition, stress assessment, and object detection.
Where Pith is reading between the lines
- The same boundary-finding principle could be tested on other non-stationary time series such as audio or physiological recordings.
- Edge devices could run longer monitoring sessions with the shorter token streams before needing to offload data.
- Replacing fixed wavelets with signal-adaptive basis selection might further reduce token length on particular sensor types.
Load-bearing premise
Wavelet-based hierarchical decomposition can reliably identify meaningful temporal boundaries that correspond to underlying semantic events in heterogeneous IoT signals without task-specific tuning.
What would settle it
A controlled experiment on signals where wavelet boundaries are forced to misalign with known semantic events, checking whether the reported accuracy and efficiency gains disappear.
Figures











read the original abstract
Internet of Things (IoT) systems continuously collect heterogeneous sensing signals from ubiquitous sensors to support intelligent applications such as human activity analysis, emotion monitoring, and environmental perception. These signals are inherently non-stationary and multi-scale, posing unique challenges for standard tokenization techniques. This paper proposes Dywave, a dynamic tokenization framework for IoT sensing signals that constructs compact input representations aligned with intrinsic temporal structures and underlying physical events. Dywave leverages wavelet-based hierarchical decomposition, identifies meaningful temporal boundaries corresponding to underlying semantic events, and adaptively compresses redundant intervals while preserving temporal coherence. Extensive evaluations on five real-world IoT sensing datasets across activity recognition, stress assessment, and nearby object detection demonstrate that Dywave outperforms state-of-the-art methods by up to 12% in accuracy, while improving computational efficiency by reducing input token lengths by up to 75% across mainstream sequence models. Moreover, Dywave exhibits improved robustness to domain shifts and varying sequence lengths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dywave, an event-aligned dynamic tokenization framework for heterogeneous IoT sensing signals. It employs wavelet-based hierarchical decomposition to detect meaningful temporal boundaries corresponding to semantic events and adaptively compresses redundant intervals to create compact representations for sequence models. The approach is evaluated on five real-world datasets for tasks including activity recognition, stress assessment, and nearby object detection, claiming up to 12% accuracy improvement and 75% reduction in token lengths compared to state-of-the-art methods.
Significance. If the results hold and the method proves to be general without heavy task-specific tuning, it would represent a meaningful advance in handling non-stationary multi-scale signals in IoT applications by improving both accuracy and efficiency of downstream models. The emphasis on automatic alignment with physical events is a strength, but the current presentation lacks the necessary details to fully assess its novelty and robustness.
major comments (3)
- [Method section (likely §3)] The description of how wavelet hierarchical decomposition identifies temporal boundaries lacks specific details on the wavelet family used, decomposition levels, thresholding criteria, and boundary merging rules. Without these, it is unclear whether the process is fully automatic or involves implicit per-dataset choices that could limit the claimed generality.
- [Experiments (likely §5)] The reported performance gains (up to 12% accuracy, 75% token reduction) are given without error bars, p-values from statistical tests, details on train/validation/test splits, or ablation studies isolating the contribution of the event alignment component. This makes it difficult to determine if the improvements are statistically significant and attributable to the proposed method.
- [§4 or related] There is no analysis or sensitivity study on the impact of different wavelet choices or decomposition depths on the boundary detection, which is central to the weakest assumption in the approach.
minor comments (2)
- [Abstract] The abstract does not specify the names of the five IoT datasets or provide citations to them.
- [Throughout] Some notation for token lengths and compression ratios could be clarified with equations for better reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve reproducibility, statistical rigor, and analysis of design choices.
read point-by-point responses
-
Referee: The description of how wavelet hierarchical decomposition identifies temporal boundaries lacks specific details on the wavelet family used, decomposition levels, thresholding criteria, and boundary merging rules. Without these, it is unclear whether the process is fully automatic or involves implicit per-dataset choices that could limit the claimed generality.
Authors: We agree that the current description is insufficient for full reproducibility. In the revised Section 3 we will explicitly state the wavelet family (Daubechies db4), decomposition depth (4 levels), thresholding rule (universal threshold scaled by median absolute deviation of the detail coefficients), and boundary merging criterion (merge adjacent intervals shorter than 8 samples). These parameters are fixed once for the entire framework and applied uniformly to all five datasets with no per-dataset retuning, thereby supporting the generality claim. Pseudocode for the full boundary detection procedure will also be added. revision: yes
-
Referee: The reported performance gains (up to 12% accuracy, 75% token reduction) are given without error bars, p-values from statistical tests, details on train/validation/test splits, or ablation studies isolating the contribution of the event alignment component. This makes it difficult to determine if the improvements are statistically significant and attributable to the proposed method.
Authors: We accept that stronger statistical evidence is required. The revised experiments section will report mean accuracy and token length together with standard deviation over five independent runs using different random seeds. Paired t-test p-values will be provided for all comparisons against baselines. Dataset splits will be documented as 60/20/20 chronological partitions (train/val/test) to preserve temporal structure. We will also add ablation experiments that disable the event-alignment stage while keeping all other components fixed, thereby isolating its contribution to the observed gains. revision: yes
-
Referee: There is no analysis or sensitivity study on the impact of different wavelet choices or decomposition depths on the boundary detection, which is central to the weakest assumption in the approach.
Authors: We will insert a dedicated sensitivity subsection in the experiments. It will evaluate boundary-detection F1 score against human-annotated events and downstream task accuracy for three wavelet families (Haar, db4, Symlet-4) and decomposition depths ranging from 2 to 6. The study will show that performance remains stable for depths 3–5 and that db4 at depth 4 yields the best trade-off, while still documenting the modest degradation outside this range. This analysis will directly address the robustness of the core assumption. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents Dywave as a framework that applies standard wavelet-based hierarchical decomposition to identify temporal boundaries in IoT signals, followed by adaptive compression. No equations, derivations, or first-principles results are described that reduce the claimed accuracy gains or token reductions to quantities defined by fitted parameters or self-referential definitions. The central claims rest on empirical evaluations across five real-world datasets rather than any closed-loop mathematical construction or load-bearing self-citation chain. The approach is characterized as leveraging existing wavelet tools plus adaptive rules without evidence of per-dataset tuning being smuggled in as an automatic property by construction. This is a standard empirical proposal with no detectable circularity in its stated method.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dywave leverages wavelet-based hierarchical decomposition, identifies meaningful temporal boundaries corresponding to underlying semantic events, and adaptively compresses redundant intervals while preserving temporal coherence.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
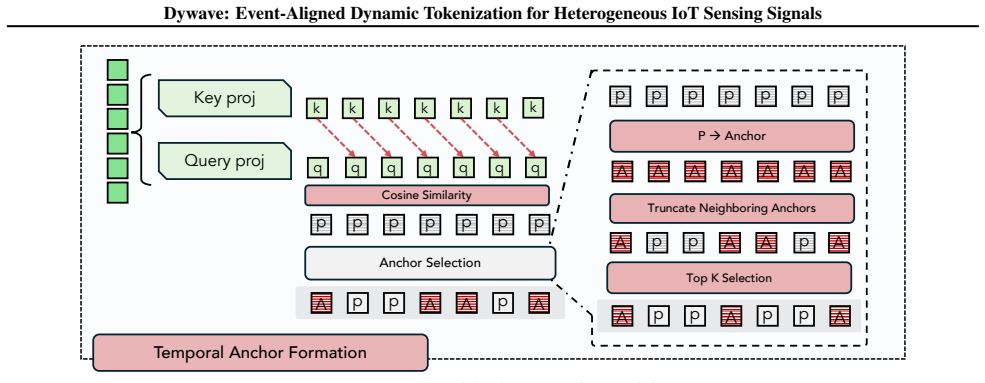
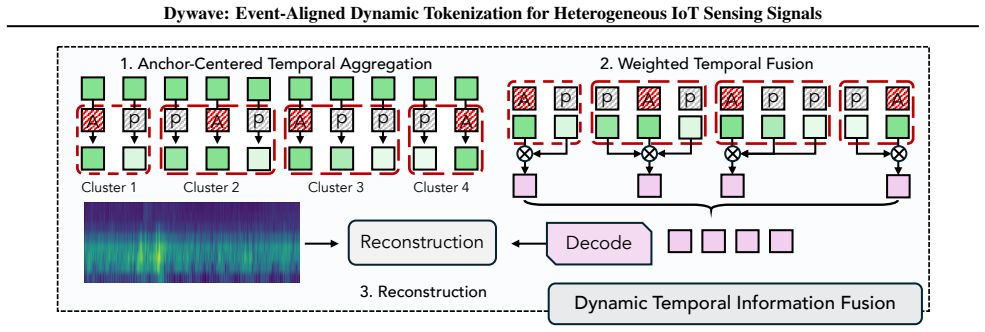
MODWT yields {dX1, …, dXJ, A} … Detail Embedding … Context Embedding … Temporal Anchor Formation … saliency Pt = 1−sim(Fk(EFt−1), Fq(EFt)) … Anchor Allocation A=TopK(NMS(P, wnms), ⌈τ·L⌉)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ahia, O., Kumar, S., Gonen, H., Kasai, J., Mortensen, D. R., Smith, N. A., and Tsvetkov, Y. Do all languages cost the same? tokenization in the era of commercial language models
-
[2]
Alharbi, R., Shahi, S., Cruz, S., Li, L., Sen, S., Pedram, M., Romano, C., Hester, J., Katsaggelos, A. K., and Alshurafa, N. Smokemon: unobtrusive extraction of smoking topography using wearable energy-efficient thermal. Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies, 6 0 (4): 0 1--25, 2023
work page 2023
-
[3]
Ansari, A. F., Stella, L., Turkmen, A. C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., et al. Chronos: Learning the language of time series. Transactions on Machine Learning Research
-
[4]
Foundation models for cps-iot: Opportunities and challenges
Baris, O., Chen, Y., Dong, G., Han, L., Kimura, T., Quan, P., Wang, R., Wang, T., Abdelzaher, T., Berg \'e s, M., et al. Foundation models for cps-iot: Opportunities and challenges. arXiv preprint arXiv:2501.16368, 2025
-
[5]
A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. On the opportunities and risks of foundation models. arXiv e-prints, pp.\ arXiv--2108, 2021
work page 2021
-
[6]
O., Pfister, T., Zheng, Y., Ye, W., and Liu, Y
Cao, D., Jia, F., Arik, S. O., Pfister, T., Zheng, Y., Ye, W., and Liu, Y. Tempo: Prompt-based generative pre-trained transformer for time series forecasting. In The Twelfth International Conference on Learning Representations
-
[7]
Mspatch: A multi-scale patch mixing framework for multivariate time series forecasting
Cao, Y., Tian, Z., Guo, W., and Liu, X. Mspatch: A multi-scale patch mixing framework for multivariate time series forecasting. Expert Systems with Applications, 273: 0 126849, 2025
work page 2025
-
[8]
Llm4ts: Aligning pre-trained llms as data-efficient time-series forecasters
Chang, C., Wang, W.-Y., Peng, W.-C., and Chen, T.-F. Llm4ts: Aligning pre-trained llms as data-efficient time-series forecasters. ACM Transactions on Intelligent Systems and Technology, 16 0 (3): 0 1--20, 2025
work page 2025
-
[9]
L., Akther, S., Ertin, E., Fagundes, C
Chatterjee, S., Moreno, A., Lizotte, S. L., Akther, S., Ertin, E., Fagundes, C. P., Lam, C., Rehg, J. M., Wan, N., Wetter, D. W., et al. Smokingopp: Detecting the smoking'opportunity'context using mobile sensors. Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies, 4 0 (1): 0 1--26, 2020
work page 2020
-
[10]
Chen, L., Hu, R., Wu, M., and Zhou, X. Hmgan: A hierarchical multi-modal generative adversarial network model for wearable human activity recognition. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7 0 (3): 0 1--27, 2023
work page 2023
- [11]
-
[12]
A decoder-only foundation model for time-series forecasting
Das, A., Kong, W., Sen, R., and Zhou, Y. A decoder-only foundation model for time-series forecasting. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[13]
Deldari, S., Xue, H., Saeed, A., Smith, D. V., and Salim, F. D. Cocoa: Cross modality contrastive learning for sensor data. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 6 0 (3): 0 1--28, 2022
work page 2022
-
[14]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2020
work page 2020
-
[15]
Tsmixer: Lightweight mlp-mixer model for multivariate time series forecasting
Ekambaram, V., Jati, A., Nguyen, N., Sinthong, P., and Kalagnanam, J. Tsmixer: Lightweight mlp-mixer model for multivariate time series forecasting. In Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining, pp.\ 459--469, 2023
work page 2023
-
[16]
Englhardt, Z., Ma, C., Morris, M. E., Chang, C.-C., Xu, X. O., Qin, L., McDuff, D., Liu, X., Patel, S., and Iyer, V. From classification to clinical insights: Towards analyzing and reasoning about mobile and behavioral health data with large language models. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8 0 (2): 0 1-...
work page 2024
-
[17]
Mmtsa: Multi-modal temporal segment attention network for efficient human activity recognition
Gao, Z., Wang, Y., Chen, J., Xing, J., Patel, S., Liu, X., and Shi, Y. Mmtsa: Multi-modal temporal segment attention network for efficient human activity recognition. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7 0 (3): 0 1--26, 2023
work page 2023
-
[18]
G \"o tz, L., Kollovieh, M., G \"u nnemann, S., and Schwinn, L. Byte pair encoding for efficient time series forecasting. arXiv preprint arXiv:2505.14411, 2025
-
[19]
Graps, A. An introduction to wavelets. IEEE computational science and engineering, 2 0 (2): 0 50--61, 1995
work page 1995
-
[20]
Ego4d: Around the world in 3,000 hours of egocentric video
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Hamburger, J., Jiang, H., Liu, M., Liu, X., et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 18995--19012, 2022
work page 2022
-
[21]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp.\ 770--778, 2016
work page 2016
-
[22]
Openmae: efficient masked autoencoder for vibration sensing with open-domain data enrichment
Hu, C., Chen, Y., Kara, D., Liu, S., Abdelzaher, T., Wu, F., and Chen, G. Openmae: efficient masked autoencoder for vibration sensing with open-domain data enrichment. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 9 0 (2): 0 1--29, 2025
work page 2025
-
[23]
Y., Shi, X., Chen, P.-Y., Liang, Y., Li, Y.-F., Pan, S., et al
Jin, M., Wang, S., Ma, L., Chu, Z., Zhang, J. Y., Shi, X., Chen, P.-Y., Liang, Y., Li, Y.-F., Pan, S., et al. Time-llm: Time series forecasting by reprogramming large language models. In The Twelfth International Conference on Learning Representations
-
[24]
Phymask: An adaptive masking paradigm for efficient self-supervised learning in iot
Kara, D., Kimura, T., Chen, Y., Li, J., Wang, R., Chen, Y., Wang, T., Liu, S., and Abdelzaher, T. Phymask: An adaptive masking paradigm for efficient self-supervised learning in iot. In Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems, pp.\ 97--111, 2024 a
work page 2024
-
[25]
Freqmae: Frequency-aware masked autoencoder for multi-modal iot sensing
Kara, D., Kimura, T., Shengzhong, L., Jinyang, L., Dongxin, L., Tianshi, W., Ruijie, W., Yizhuo, C., Yigong, H., and Tarek, A. Freqmae: Frequency-aware masked autoencoder for multi-modal iot sensing. In The World Wide Web Conference, 2024 b
work page 2024
-
[26]
Kawano, H., Okamoto, M., and Murao, K. Estimating sampling rate of human activity data from accelerometer using transformer-based regression model. In Adjunct Proceedings of the 2023 ACM International Joint Conference on Pervasive and Ubiquitous Computing & the 2023 ACM International Symposium on Wearable Computing, pp.\ 200--201, 2023
work page 2023
-
[27]
What and when to explain? on-road evaluation of explanations in highly automated vehicles
Kim, G., Yeo, D., Jo, T., Rus, D., and Kim, S. What and when to explain? on-road evaluation of explanations in highly automated vehicles. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7 0 (3): 0 1--26, 2023
work page 2023
-
[28]
Vibrofm: Towards micro foundation models for robust multimodal iot sensing
Kimura, T., Li, J., Wang, T., Chen, Y., Wang, R., Kara, D., Wigness, M., Bhattacharyya, J., Srivatsa, M., Liu, S., et al. Vibrofm: Towards micro foundation models for robust multimodal iot sensing. In 2024 IEEE 21st International Conference on Mobile Ad-Hoc and Smart Systems (MASS), pp.\ 10--18. IEEE, 2024
work page 2024
-
[29]
Infomae: Pair-efficient cross-modal alignment for multimodal time-series sensing signals
Kimura, T., Li, X., Hanna, O., Chen, Y., Chen, Y., Kara, D., Wang, T., Li, J., Ouyang, X., Liu, S., et al. Infomae: Pair-efficient cross-modal alignment for multimodal time-series sensing signals. In Proceedings of the ACM on Web Conference 2025, pp.\ 3084--3095, 2025
work page 2025
-
[30]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[31]
Korany, B., Karanam, C. R., Cai, H., and Mostofi, Y. Xmodal-id: Using wifi for through-wall person identification from candidate video footage. In The 25th Annual International Conference on Mobile Computing and Networking, MobiCom '19, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450361699. doi:10.1145/3300061.3345437. URL https...
-
[32]
Kudo, T. and Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. EMNLP 2018, pp.\ 66, 2018
work page 2018
-
[33]
Larrubia, L. F., Morettin, P. A., and Chiann, C. The maximal overlap discrete wavelet scattering transform and its application in classification tasks. arXiv preprint arXiv:2506.12039, 2025
-
[34]
Pywavelets: A python package for wavelet analysis
Lee, G., Gommers, R., Waselewski, F., Wohlfahrt, K., and O'Leary, A. Pywavelets: A python package for wavelet analysis. Journal of Open Source Software, 4 0 (36): 0 1237, 2019
work page 2019
-
[35]
Lina, J.-M. and Mayrand, M. Complex daubechies wavelets. Applied and Computational Harmonic Analysis, 2 0 (3): 0 219--229, 1995
work page 1995
-
[36]
Liu, S., Kimura, T., Liu, D., Wang, R., Li, J., Diggavi, S., Srivastava, M., and Abdelzaher, T. Focal: Contrastive learning for multimodal time-series sensing signals in factorized orthogonal latent space. Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[37]
F., Han, B., Zhang, X., Faloutsos, C., Mahoney, M
Masserano, L., Ansari, A. F., Han, B., Zhang, X., Faloutsos, C., Mahoney, M. W., Wilson, A. G., Park, Y., Rangapuram, S. S., Maddix, D. C., et al. Enhancing foundation models for time series forecasting via wavelet-based tokenization. In Forty-second International Conference on Machine Learning, 2025
work page 2025
-
[38]
Naghashi, V., Boukadoum, M., and Diallo, A. B. A multiscale model for multivariate time series forecasting. Scientific Reports, 15 0 (1): 0 1565, 2025
work page 2025
-
[39]
a rv \"a inen, J., Pettersson, K., and M \
Nath, R. K., Tervonen, J., N \"a rv \"a inen, J., Pettersson, K., and M \"a ntyj \"a rvi, J. Towards self-supervised learning of ecg signal representation for the classification of acute stress types. In Proceedings of the Great Lakes Symposium on VLSI 2023, pp.\ 85--90, 2023
work page 2023
-
[40]
Hierarchical transformers are more efficient language models
Nawrot, P., Tworkowski, S., Tyrolski, M., Kaiser, ., Wu, Y., Szegedy, C., and Michalewski, H. Hierarchical transformers are more efficient language models
-
[41]
H., Sinthong, P., and Kalagnanam, J
Nie, Y., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[42]
W., Xie, Z., Xing, G., and Huang, J
Ouyang, X., Shuai, X., Zhou, J., Shi, I. W., Xie, Z., Xing, G., and Huang, J. Cosmo: Contrastive fusion learning with small data for multimodal human activity recognition. In International Conference on Mobile Computing And Networking (MobiCom), 2022
work page 2022
-
[43]
Percival, D. B. and Walden, A. T. Wavelet methods for time series analysis, volume 4. Cambridge university press, 2000
work page 2000
-
[44]
Language model tokenizers introduce unfairness between languages
Petrov, A., La Malfa, E., Torr, P., and Bibi, A. Language model tokenizers introduce unfairness between languages. Advances in neural information processing systems, 36: 0 36963--36990, 2023
work page 2023
-
[45]
Fredformer: Frequency debiased transformer for time series forecasting
Piao, X., Chen, Z., Murayama, T., Matsubara, Y., and Sakurai, Y. Fredformer: Frequency debiased transformer for time series forecasting. In Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pp.\ 2400--2410, 2024
work page 2024
-
[46]
Enhancing masked time-series modeling via dropping patches
Qiu, T., Xie, Y., Niu, H., Xiong, Y., and Gao, X. Enhancing masked time-series modeling via dropping patches. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 20077--20085, 2025
work page 2025
-
[47]
Dynamicvit: Efficient vision transformers with dynamic token sparsification
Rao, Y., Zhao, W., Liu, B., Lu, J., Zhou, J., and Hsieh, C.-J. Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems, 34: 0 13937--13949, 2021
work page 2021
-
[48]
Reiss, A. and Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In International Symposium on Wearable Computers (ISWC), 2012
work page 2012
-
[49]
Motion2press: Cross model learning from imu to plantar pressure for gait analysis
Ren, J., Zheng, R., Zhang, W., She, D., Bai, Y., Jin, Z., and Gao, Y. Motion2press: Cross model learning from imu to plantar pressure for gait analysis. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 9 0 (3): 0 1--33, 2025
work page 2025
-
[50]
Tokenlearner: Adaptive space-time tokenization for videos
Ryoo, M., Piergiovanni, A., Arnab, A., Dehghani, M., and Angelova, A. Tokenlearner: Adaptive space-time tokenization for videos. Advances in neural information processing systems, 34: 0 12786--12797, 2021
work page 2021
-
[51]
A., Mao, W., Neupane, S., Rehg, J
Saha, M., Xu, M. A., Mao, W., Neupane, S., Rehg, J. M., and Kumar, S. Pulse-ppg: An open-source field-trained ppg foundation model for wearable applications across lab and field settings. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 9 0 (3): 0 1--35, 2025
work page 2025
-
[52]
Introducing wesad, a multimodal dataset for wearable stress and affect detection
Schmidt, P., Reiss, A., Duerichen, R., Marberger, C., and Van Laerhoven, K. Introducing wesad, a multimodal dataset for wearable stress and affect detection. In Proceedings of the 20th ACM international conference on multimodal interaction, pp.\ 400--408, 2018 a
work page 2018
-
[53]
Schmidt, P., Reiss, A., D \" u richen, R., Marberger, C., and Laerhoven, K. V. Introducing wesad, a multimodal dataset for wearable stress and affect detection. In ICMI 2018, pp.\ 400--408. ACM , 2018 b . doi:10.1145/3242969.3242985
-
[54]
Neural machine translation of rare words with subword units
Sennrich, R., Haddow, B., and Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1715--1725, 2016
work page 2016
-
[55]
S., Jiang, X., and Mesgarani, N
Shams, S., Dindar, S. S., Jiang, X., and Mesgarani, N. Ssamba: Self-supervised audio representation learning with mamba state space model. In 2024 IEEE Spoken Language Technology Workshop (SLT), pp.\ 1053--1059. IEEE, 2024
work page 2024
-
[56]
Sztyler, T. and Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In IEEE International Conference on Pervasive Computing and Communications (PerCom), 2016
work page 2016
-
[57]
Scaling laws with vocabulary: Larger models deserve larger vocabularies
Tao, C., Liu, Q., Dou, L., Muennighoff, N., Wan, Z., Luo, P., Lin, M., and Wong, N. Scaling laws with vocabulary: Larger models deserve larger vocabularies. Advances in Neural Information Processing Systems, 37: 0 114147--114179, 2024
work page 2024
-
[58]
Selective review of offline change point detection methods
Truong, C., Oudre, L., and Vayatis, N. Selective review of offline change point detection methods. Signal processing, 167: 0 107299, 2020
work page 2020
-
[59]
A., Chatterjee, S., Fagundes, C
Ullah, M. A., Chatterjee, S., Fagundes, C. P., Lam, C., Nahum-Shani, I., Rehg, J. M., Wetter, D. W., and Kumar, S. mrisk: continuous risk estimation for smoking lapse from noisy sensor data with incomplete and positive-only labels. Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies, 6 0 (3): 0 1--29, 2022
work page 2022
-
[60]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. In Advances in neural information processing systems, pp.\ 5998--6008, 2017
work page 2017
-
[61]
Loear: Push the range limit of acoustic sensing for vital sign monitoring
Wang, L., Li, W., Sun, K., Zhang, F., Gu, T., Xu, C., and Zhang, D. Loear: Push the range limit of acoustic sensing for vital sign monitoring. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 6 0 (3): 0 1--24, 2022
work page 2022
-
[62]
Contrastive learning of stress-specific word embedding for social media based stress detection
Wang, X., Zhang, H., Cao, L., Zeng, K., Li, Q., Li, N., and Feng, L. Contrastive learning of stress-specific word embedding for social media based stress detection. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp.\ 5137--5149, 2023 a
work page 2023
-
[63]
Medformer: A multi-granularity patching transformer for medical time-series classification
Wang, Y., Huang, N., Li, T., Yan, Y., and Zhang, X. Medformer: A multi-granularity patching transformer for medical time-series classification. Advances in Neural Information Processing Systems, 37: 0 36314--36341, 2024
work page 2024
-
[64]
Lightgts: A lightweight general time series forecasting model
Wang, Y., Qiu, Y., Chen, P., Shu, Y., Rao, Z., Pan, L., Yang, B., and Guo, C. Lightgts: A lightweight general time series forecasting model. In International Conference on Machine Learning, pp.\ 64109--64126. PMLR, 2025
work page 2025
-
[65]
Hearfire: Indoor fire detection via inaudible acoustic sensing
Wang, Z., Wang, Y., Tian, M., and Shen, J. Hearfire: Indoor fire detection via inaudible acoustic sensing. Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies, 6 0 (4): 0 1--25, 2023 b
work page 2023
-
[66]
Deepsense: A unified deep learning framework for time-series mobile sensing data processing
Yao, S., Hu, S., Zhao, Y., Zhang, A., and Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In International Conference on World Wide Web (WWW), 2017
work page 2017
-
[67]
Yao, S., Piao, A., Jiang, W., Zhao, Y., Shao, H., Liu, S., Liu, D., Li, J., Wang, T., Hu, S., et al. Stfnets: Learning sensing signals from the time-frequency perspective with short-time fourier neural networks. In The World Wide Web Conference, pp.\ 2192--2202, 2019
work page 2019
-
[68]
Frequency-domain mlps are more effective learners in time series forecasting
Yi, K., Zhang, Q., Fan, W., Wang, S., Wang, P., He, H., An, N., Lian, D., Cao, L., and Niu, Z. Frequency-domain mlps are more effective learners in time series forecasting. Advances in Neural Information Processing Systems, 36: 0 76656--76679, 2023
work page 2023
-
[69]
Yu, H. and Sano, A. Semi-supervised learning for wearable-based momentary stress detection in the wild. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7 0 (2): 0 1--23, 2023
work page 2023
-
[70]
M., Chee, M., Shenoy, P., and Balan, R
Zakaria, C., Yilmaz, G., Mammen, P. M., Chee, M., Shenoy, P., and Balan, R. Sleepmore: Inferring sleep duration at scale via multi-device wifi sensing. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 6 0 (4): 0 1--32, 2023
work page 2023
-
[71]
Self-supervised contrastive pre-training for time series via time-frequency consistency
Zhang, X., Zhao, Z., Tsiligkaridis, T., and Zitnik, M. Self-supervised contrastive pre-training for time series via time-frequency consistency. In Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[72]
Zhang, Y., Ayush, K., Qiao, S., Heydari, A. A., Narayanswamy, G., Xu, M. A., Metwally, A., Xu, J., Garrison, J., Xu, X., Althoff, T., Liu, Y., Kohli, P., Zhan, J., Malhotra, M., Patel, S., Mascolo, C., Liu, X., McDuff, D., and Yang, Y. Sensor LM : Learning the language of wearable sensors. In The Thirty-ninth Annual Conference on Neural Information Proces...
work page 2025
-
[73]
Segall: A unified active learning framework for wireless sensing data segmentation
Zheng, N., Liu, R., Fan, X., Zhang, C., Zhang, L., and Yin, Z. Segall: A unified active learning framework for wireless sensing data segmentation. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 9 0 (3): 0 1--27, 2025
work page 2025
-
[74]
Zhong, S., Song, S., Zhuo, W., Li, G., Liu, Y., and Chan, S.-H. G. A multi-scale decomposition mlp-mixer for time series analysis. Proceedings of the VLDB Endowment, 17 0 (7): 0 1723--1736, 2024
work page 2024
-
[75]
One fits all: Power general time series analysis by pretrained lm
Zhou, T., Niu, P., Sun, L., Jin, R., et al. One fits all: Power general time series analysis by pretrained lm. Advances in neural information processing systems, 36: 0 43322--43355, 2023
work page 2023
-
[76]
Scalemixer: A multi-scale mlp-mixer model for long-term time series forecasting
Zou, X., You, C., Zhao, R., Yang, H., and Cheng, X. Scalemixer: A multi-scale mlp-mixer model for long-term time series forecasting. In International Conference on Neural Information Processing, pp.\ 44--58. Springer, 2024
work page 2024
-
[77]
12th \ USENIX \ Symposium on Operating Systems Design and Implementation ( \ OSDI \ 16) , pages =
Tensorflow: A system for large-scale machine learning , author =. 12th \ USENIX \ Symposium on Operating Systems Design and Implementation ( \ OSDI \ 16) , pages =
-
[78]
Toward an internet of battlefield things: A resilience perspective , author =. Computer , publisher =
-
[79]
ACM Transactions on Internet Technology (TOIT) , publisher =
Five challenges in cloud-enabled intelligence and control , author =. ACM Transactions on Internet Technology (TOIT) , publisher =
-
[80]
2017 International Conference on Engineering and Technology (ICET) , volume =
Understanding of a convolutional neural network , author =. 2017 International Conference on Engineering and Technology (ICET) , volume =
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.