Unified Pix Token And Word Token Generative Language Model
Pith reviewed 2026-05-15 05:45 UTC · model grok-4.3
The pith
A new generative language model assigns each image pixel its own token to unify visual and textual inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a generative language model can treat every pixel as an independent token with its own embedding, combine it with word tokens, apply color folding and global conditional attention approximation, and still reach usable performance after unsupervised image pretraining on a small model with limited data; they further assert that performance will continue to rise with increased scale following the scaling law.
What carries the argument
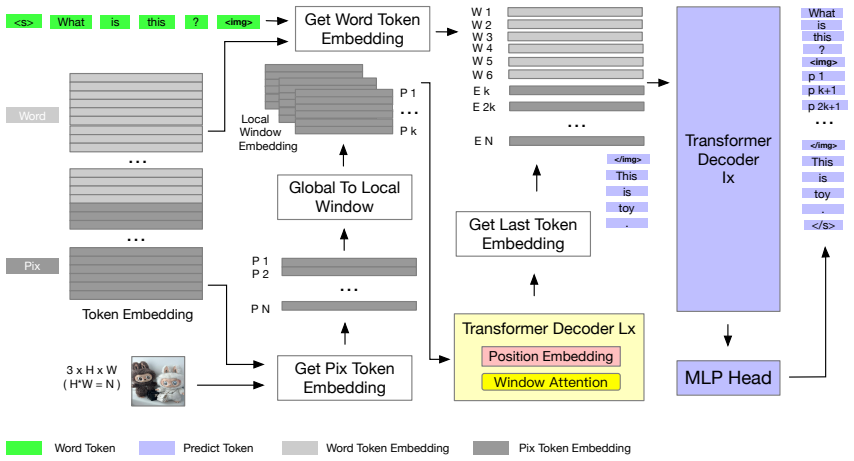
The unified pix-token and word-token architecture in which each pixel receives its own embedding and is processed together with textual tokens inside the same generative language model.
If this is right
- The model can recognize small text and numbers in images more readily than current patch-based multimodal systems.
- Usable visual understanding is achievable with a small parameter count and limited training data.
- Performance is expected to improve steadily as model size and data volume increase according to the scaling law.
- The same architecture can serve as the backbone for multimodal generative tasks that require precise visual detail.
Where Pith is reading between the lines
- Pixel-level tokenization could allow the model to generate or edit images at finer spatial resolutions than patch-based approaches.
- The method may reduce dependence on separate large vision encoders in future multimodal systems.
- Direct application to OCR-heavy or diagram-understanding benchmarks would provide a clear test of the detail advantage.
Load-bearing premise
That assigning a dedicated token embedding to every pixel, together with color folding and the attention approximation, produces better visual detail understanding than patch-based encoders.
What would settle it
A side-by-side evaluation on images containing small text or numbers that measures whether the new model recognizes those details more accurately than a standard ViT-based encoder of comparable size.
Figures





read the original abstract
Since the emergence of Vision Transformer (ViT), it has been widely used in generative language model and generative visual model. Especially in the current state-of-art open source multimodal models, ViT obtained by CLIP or SigLIP method serves as the vision encoder backbone to help them acquire visual understanding capabilities. But this method leads to limitations in visual understanding for details, such as difficulty in recognizing small text or numbers in images. To address these issues, we propose a new model to unify pix token and word token into the generative language model. The new model also features with each pix of image having its own token embedding, color folding, global conditional attention approximation and image unsupervised pretraining. We conducted image unsupervised pretraining experiments using our new model to explore its potential. The experimental results show that it has good performance even in small model and with limited training data. We believe our model also conforms to the scaling law, as long as model parameters and training data increased, its performance will continue to improve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified generative language model integrating pixel tokens and word tokens. It introduces per-pixel token embeddings for images, color folding, global conditional attention approximation, and unsupervised image pretraining. The authors claim that experiments demonstrate good performance even with small models and limited training data, and assert that the approach will continue to improve in line with scaling laws as model size and data increase.
Significance. If the per-pixel tokenization and associated mechanisms demonstrably improve fine-grained visual understanding over patch-based encoders such as ViT or CLIP, the work could address a recognized limitation in current multimodal generative models. The focus on unsupervised pretraining with small-scale resources also aligns with interest in efficient training paradigms. However, the absence of any quantitative support leaves the potential significance unevaluated.
major comments (2)
- [Experiments] Experiments section: The manuscript asserts that unsupervised pretraining 'show[s] that it has good performance even in small model and with limited training data,' yet reports no metrics, baselines, error bars, ablation studies, or task-specific results (e.g., OCR accuracy on text-in-image). This directly undermines evaluation of the central claim.
- [Model Description] Model architecture: No equations, complexity analysis, or implementation details are supplied for the per-pixel token embedding scheme, color folding, or global conditional attention approximation. Without these, it is impossible to assess whether the approach overcomes the stated ViT/CLIP limitations or is computationally viable.
minor comments (1)
- [Abstract] The abstract and main text repeatedly use the phrase 'good performance' without defining the evaluation protocol or comparison points.
Simulated Author's Rebuttal
We thank the referee for their detailed review and valuable comments on our manuscript. We address the major concerns point by point below and will revise the paper to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The manuscript asserts that unsupervised pretraining 'show[s] that it has good performance even in small model and with limited training data,' yet reports no metrics, baselines, error bars, ablation studies, or task-specific results (e.g., OCR accuracy on text-in-image). This directly undermines evaluation of the central claim.
Authors: We agree with the referee that the experiments section requires more rigorous quantitative support. The current manuscript presents preliminary results from unsupervised pretraining to illustrate the model's potential with small-scale resources, but lacks specific metrics and comparisons. In the revised version, we will include quantitative metrics (such as reconstruction loss or downstream task accuracies like OCR on text-in-image), baselines (e.g., comparisons to ViT-based models), error bars from multiple runs, and ablation studies on the proposed components. This will allow proper evaluation of the central claims. revision: yes
-
Referee: [Model Description] Model architecture: No equations, complexity analysis, or implementation details are supplied for the per-pixel token embedding scheme, color folding, or global conditional attention approximation. Without these, it is impossible to assess whether the approach overcomes the stated ViT/CLIP limitations or is computationally viable.
Authors: We acknowledge the need for more detailed technical descriptions. The manuscript introduces these concepts at a high level, but we will expand the model architecture section to include mathematical formulations (equations) for per-pixel token embeddings, the color folding technique, and the global conditional attention approximation. We will also provide a complexity analysis (e.g., time and space complexity) and implementation details such as tokenization process and attention mechanisms. This will help demonstrate how the approach addresses fine-grained visual understanding limitations of patch-based methods like ViT and CLIP, and assess its computational viability. revision: yes
Circularity Check
No circularity: architecture proposal and scaling-law belief are stated without self-referential derivations or fitted inputs renamed as predictions
full rationale
The paper proposes a new generative model unifying per-pixel token embeddings with word tokens, adding color folding and global conditional attention approximation, then reports unsupervised pretraining results on a small model with limited data. No equations, derivation chain, or first-principles results are presented that reduce to the inputs by construction. The scaling-law statement is explicitly labeled a belief rather than derived from model equations. No self-citations, uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central claim of improved detail understanding is an empirical assertion resting on the architectural choice and pretraining, not on any circular reduction of predictions to fitted parameters or self-referential definitions. This is a standard non-circular proposal of a new design.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Patch-based vision encoders inherently limit fine-detail recognition in images
invented entities (1)
-
pix token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Neural Information Processing Systems , year=
Attention is All you Need , author=. Neural Information Processing Systems , year=
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2020 , journal=
work page 2020
-
[3]
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
work page 2021
-
[4]
Sigmoid Loss for Language Image Pre-Training , author=. 2023 , eprint=
work page 2023
- [5]
- [6]
- [7]
-
[8]
Generative Pretraining from Pixels , author=. 37th International Conference on Machine Learning: ICML 2020, Online, 13-18 July 2020, Part 3 of 15 , year=
work page 2020
-
[9]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , author=. 2021 , eprint=
work page 2021
-
[10]
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers , author=. 2021 , eprint=
work page 2021
-
[11]
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation , author=. 2022 , eprint=
work page 2022
-
[12]
SeaFormer++: Squeeze-enhanced Axial Transformer for Mobile Visual Recognition , author=. 2025 , eprint=
work page 2025
-
[13]
In Advances in Neural Information Processing Systems , author=. Mit Press , year=
-
[14]
Video (language) modeling: a baseline for generative models of natural videos , author=. 2016 , eprint=
work page 2016
-
[15]
Language Models are Few-Shot Learners , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.