Recognition: unknown
PVRF: All-in-one Adverse Weather Removal via Prior-modulated and Velocity-constrained Rectified Flow
Pith reviewed 2026-05-15 05:41 UTC · model grok-4.3
The pith
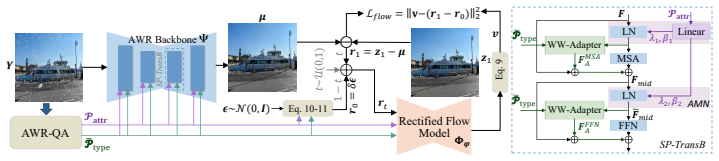
PVRF uses zero-shot weather perceptions from frozen vision-language models to guide a velocity-constrained rectified flow that refines restoration anchors for multiple adverse degradations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that zero-shot soft weather perceptions generated by frozen VLMs, when used to modulate restoration networks through AMN and WWA, create a reliable anchor that a terminal-consistent residual rectified flow with perception-adaptive perturbation and terminal-consistent velocity parameterization can refine to deliver higher fidelity and perceptual quality than existing baselines while generalizing across single and combined degradations.
What carries the argument
Terminal-consistent residual rectified flow with perception-adaptive source perturbation and terminal-consistent velocity parameterization, which stabilizes refinement near the data terminal by adapting the flow trajectory to the perception-derived anchor.
If this is right
- The framework handles both single-type and combined weather degradations in one model without task-specific retraining.
- Cross-dataset generalization improves because the perception conditioning adapts the flow without requiring paired data for every degradation combination.
- Perceptual quality rises relative to distortion-only baselines because the rectified-flow refinement avoids excessive smoothing near the terminal distribution.
- The anchor estimate produced by AMN and WWA serves as a stable starting point that reduces variance in the learned velocity field.
Where Pith is reading between the lines
- The same perception-to-anchor-to-flow pattern could be tested on other composite restoration problems such as joint denoising and deblurring by swapping the AWR-QA module for appropriate attribute estimators.
- Velocity-constrained parameterization might reduce mode collapse or oversmoothing when applied to other generative refinement tasks that currently rely on standard diffusion or flow schedules.
- If VLM perceptions prove reliable, the approach opens a route to interpretable restoration where the model can report the weather attributes it detected and the changes it applied.
- Extending the terminal-consistent velocity to video frames could enforce temporal coherence without additional optical-flow supervision.
Load-bearing premise
The zero-shot soft weather perceptions from frozen VLMs are accurate and informative enough to condition the restoration networks effectively.
What would settle it
A controlled experiment in which the AWR-QA module is replaced by random or mismatched weather labels while keeping the rest of the architecture fixed, then measuring whether fidelity and perceptual scores drop substantially compared with the original PVRF outputs.
Figures








read the original abstract
Adverse weather removal (AWR) in real-world images remains challenging due to heterogeneous and unseen degradations, while distortion-driven training often yields overly smooth results. We propose PVRF, a unified framework that integrates zero-shot soft weather perceptions with velocity-constrained rectified-flow refinement. PVRF introduces an AWR-specific question answering module (AWR-QA) that uses frozen vision--language models (VLMs) to estimate soft probabilities of weather types and low-level attribute scores. These perceptions condition restoration networks via attribute-modulated normalization (AMN) and weather-weighted adapters (WWA), producing an anchor estimate for refinement. We then learn a terminal-consistent residual rectified flow with perception-adaptive source perturbation and a terminal-consistent velocity parameterization to stabilize learning near the terminal regime. Extensive experiments show that PVRF improves both fidelity and perceptual quality over state-of-the-art baselines, with strong cross-dataset generalization on single and combined degradations. Code will be released at https://github.com/dongw22/PVRF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PVRF, a unified all-in-one framework for adverse weather removal that combines zero-shot soft weather perceptions (weather-type probabilities and low-level attribute scores) generated by an AWR-QA module using frozen VLMs, which condition restoration networks via attribute-modulated normalization (AMN) and weather-weighted adapters (WWA) to produce an anchor estimate, followed by a terminal-consistent residual rectified flow trained with perception-adaptive source perturbation and a specialized velocity parameterization. The central claim is that this yields improved fidelity and perceptual quality over state-of-the-art baselines together with strong cross-dataset generalization on both single and combined degradations.
Significance. If the central claims hold, the work would be moderately significant for image restoration under real-world adverse conditions, as it attempts a single model for heterogeneous degradations by fusing perceptual priors from VLMs with constrained generative flow refinement. The emphasis on terminal-consistent flow and code release are positive elements that could aid reproducibility and follow-up work.
major comments (2)
- [§3.1] §3.1 (AWR-QA module description): No quantitative validation is reported for the accuracy or informativeness of the zero-shot soft weather perceptions and attribute scores produced by the frozen VLMs (e.g., no classification accuracy, agreement with human annotations, or correlation metrics on weather categories). This is load-bearing for the headline claim, because the improvements are attributed to conditioning via AMN and WWA; without such evidence or an ablation isolating perception quality, it is possible that observed gains derive entirely from the rectified-flow stage.
- [§4] §4 (experimental tables): The cross-dataset generalization results lack reported standard deviations across multiple runs or statistical significance tests, making it difficult to determine whether the reported improvements in fidelity and perceptual metrics are robust or could be explained by training variance alone.
minor comments (2)
- [Abstract] The abstract and §3.2 introduce 'terminal-consistent velocity parameterization' without a brief inline definition or reference to the exact equation, which reduces immediate clarity for readers unfamiliar with rectified-flow variants.
- [§4] Figure captions in §4 could more explicitly state the degradation types and dataset splits used for each qualitative example to aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we provide point-by-point responses to the major comments and describe the revisions incorporated into the updated manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (AWR-QA module description): No quantitative validation is reported for the accuracy or informativeness of the zero-shot soft weather perceptions and attribute scores produced by the frozen VLMs (e.g., no classification accuracy, agreement with human annotations, or correlation metrics on weather categories). This is load-bearing for the headline claim, because the improvements are attributed to conditioning via AMN and WWA; without such evidence or an ablation isolating perception quality, it is possible that observed gains derive entirely from the rectified-flow stage.
Authors: We agree that quantitative validation of the zero-shot perceptions would strengthen the claims. In the revised manuscript we have added a new subsection reporting agreement rates between the AWR-QA outputs and human annotations on both weather-type probabilities and low-level attribute scores, together with an ablation that isolates the contribution of the perception conditioning (AMN + WWA) from the rectified-flow stage alone. These results confirm that the perceptions are informative and account for a measurable portion of the performance gains. revision: yes
-
Referee: [§4] §4 (experimental tables): The cross-dataset generalization results lack reported standard deviations across multiple runs or statistical significance tests, making it difficult to determine whether the reported improvements in fidelity and perceptual metrics are robust or could be explained by training variance alone.
Authors: We acknowledge this limitation. In the revised version we have rerun all cross-dataset experiments with multiple random seeds and now report mean ± standard deviation for every metric. We have also added paired t-test p-values to establish statistical significance of the improvements over the baselines. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes an empirical image restoration framework that conditions networks on zero-shot outputs from external frozen VLMs and trains a rectified flow model with standard velocity parameterization. No equations, derivations, or self-referential normalizations appear in the provided text that reduce performance claims to quantities defined by the method's own fitted parameters or prior outputs. The central claims rest on cross-dataset empirical results rather than any tautological reduction of the form 'prediction equals input by construction.'
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frozen vision-language models can produce reliable soft probabilities for weather types and low-level attribute scores without task-specific fine-tuning
- domain assumption A terminal-consistent velocity parameterization stabilizes rectified-flow learning near the clean-image regime
invented entities (2)
-
AWR-QA module
no independent evidence
-
Attribute-modulated normalization (AMN) and weather-weighted adapters (WWA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[2]
Unirestore: Unified perceptual and task-oriented image restoration model using diffusion prior
I-Hsiang Chen, Wei-Ting Chen, Yu-Wei Liu, Yuan-Chun Chiang, Sy-Yen Kuo, and Ming-Hsuan Yang. Unirestore: Unified perceptual and task-oriented image restoration model using diffusion prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[3]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InEuropean Conference on Computer Vision, 2022
work page 2022
-
[4]
Wei-Ting Chen, Hao-Yu Fang, Cheng-Lin Hsieh, Cheng-Che Tsai, I Chen, Jian-Jiun Ding, Sy-Yen Kuo, et al. All snow removed: Single image desnowing algorithm using hierarchical dual-tree complex wavelet representation and contradict channel loss. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
work page 2021
-
[5]
Bio-inspired image restoration
Yuning Cui, Wenqi Ren, and Alois Knoll. Bio-inspired image restoration. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[6]
Adair: Adaptive all-in-one image restoration via frequency mining and modulation
Yuning Cui, Syed Waqas Zamir, Salman Khan, Alois Knoll, Mubarak Shah, and Fahad Shahbaz Khan. Adair: Adaptive all-in-one image restoration via frequency mining and modulation. In International Conference on Learning Representations, 2025
work page 2025
-
[7]
A theory of the distortion-perception tradeoff in wasserstein space
Dror Freirich, Tomer Michaeli, and Ron Meir. A theory of the distortion-perception tradeoff in wasserstein space. InAdvances in Neural Information Processing Systems, 2021
work page 2021
-
[8]
Onerestore: A universal restoration framework for composite degradation
Yu Guo, Yuan Gao, Yuxu Lu, Huilin Zhu, Ryan Wen Liu, and Shengfeng He. Onerestore: A universal restoration framework for composite degradation. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[9]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems, 2017
work page 2017
-
[10]
Universal image restoration pre-training via degradation classification
JiaKui Hu, Lujia Jin, Zhengjian Yao, and Yanye Lu. Universal image restoration pre-training via degradation classification. InInternational Conference on Learning Representations, 2025
work page 2025
-
[11]
Multi-scale progressive fusion network for single image deraining
Kui Jiang, Zhongyuan Wang, Peng Yi, Chen Chen, Baojin Huang, Yimin Luo, Jiayi Ma, and Junjun Jiang. Multi-scale progressive fusion network for single image deraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
work page 2020
-
[12]
Autodir: Automatic all-in-one image restoration with latent diffusion
Yitong Jiang, Zhaoyang Zhang, Tianfan Xue, and Jinwei Gu. Autodir: Automatic all-in-one image restoration with latent diffusion. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[13]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
work page 2021
-
[14]
Chulwoo Lee, Chul Lee, and Chang-Su Kim. Contrast enhancement based on layered difference representation of 2d histograms.IEEE Transactions on Image Processing, 2013
work page 2013
-
[15]
Aod-net: All-in-one dehazing network
Boyi Li, Xiulian Peng, Zhangyang Wang, Jizheng Xu, and Dan Feng. Aod-net: All-in-one dehazing network. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2017
work page 2017
-
[16]
Benchmarking single-image dehazing and beyond.IEEE Transactions on Image Processing, 2018
Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. Benchmarking single-image dehazing and beyond.IEEE Transactions on Image Processing, 2018
work page 2018
-
[17]
Heavy rain image restoration: Integrating physics model and conditional adversarial learning
Ruoteng Li, Loong-Fah Cheong, and Robby T Tan. Heavy rain image restoration: Integrating physics model and conditional adversarial learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019. 11
work page 2019
-
[18]
Wei Li, Qiming Zhang, Jing Zhang, Zhen Huang, Xinmei Tian, and Dacheng Tao. Toward real- world single image deraining: A new benchmark and beyond.arXiv preprint arXiv:2206.05514, 2022
-
[19]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
work page 2021
-
[20]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
work page 2023
-
[21]
Desnownet: Context-aware deep network for snow removal.IEEE Transactions on Image Processing, 2018
Yun-Fu Liu, Da-Wei Jaw, Shih-Chia Huang, and Jenq-Neng Hwang. Desnownet: Context-aware deep network for snow removal.IEEE Transactions on Image Processing, 2018
work page 2018
-
[22]
Controlling vision-language models for universal image restoration
Ziwei Luo, Fredrik K Gustafsson, Zheng Zhao, Jens Sjölund, and Thomas B Schön. Controlling vision-language models for universal image restoration. InInternational Conference on Learning Representations, 2024
work page 2024
-
[23]
Kede Ma, Kai Zeng, and Zhou Wang. Perceptual quality assessment for multi-exposure image fusion.IEEE Transactions on Image Processing, 2015
work page 2015
-
[24]
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Making a “completely blind” image quality analyzer.IEEE Signal Processing Letters, 2012
work page 2012
-
[25]
Deep multi-scale convolutional neural network for dynamic scene deblurring
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[26]
Posterior-mean rectified flow: Towards minimum mse photo-realistic image restoration
Guy Ohayon, Tomer Michaeli, and Michael Elad. Posterior-mean rectified flow: Towards minimum mse photo-realistic image restoration. InInternational Conference on Learning Representations, 2025
work page 2025
-
[27]
Ozan Özdenizci and Robert Legenstein. Restoring vision in adverse weather conditions with patch-based denoising diffusion models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[28]
Promptir: Prompting for all-in-one blind image restoration
Vaishnav Potlapalli, Syed Waqas Zamir, Salman Khan, and Fahad Shahbaz Khan. Promptir: Prompting for all-in-one blind image restoration. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[29]
Ziyi Shen, Wenguan Wang, Xiankai Lu, Jianbing Shen, Haibin Ling, Tingfa Xu, and Ling Shao. Human-aware motion deblurring. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
work page 2019
-
[30]
Restoring images in adverse weather conditions via histogram transformer
Shangquan Sun, Wenqi Ren, Xinwei Gao, Rui Wang, and Xiaochun Cao. Restoring images in adverse weather conditions via histogram transformer. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[31]
Transweather: Transformer- based restoration of images degraded by adverse weather conditions
Jeya Maria Jose Valanarasu, Rajeev Yasarla, and Vishal M Patel. Transweather: Transformer- based restoration of images degraded by adverse weather conditions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[32]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI Conference on Artificial Intelligence, 2023
work page 2023
-
[33]
Shuhang Wang, Jin Zheng, Hai-Miao Hu, and Bo Li. Naturalness preserved enhancement algorithm for non-uniform illumination images.IEEE Transactions on Image Processing, 2013
work page 2013
-
[34]
Tao Wang, Kaihao Zhang, Ziqian Shao, Wenhan Luo, Bjorn Stenger, Tong Lu, Tae-Kyun Kim, Wei Liu, and Hongdong Li. Gridformer: Residual dense transformer with grid structure for image restoration in adverse weather conditions.International Journal of Computer Vision, 2024. 12
work page 2024
-
[35]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 2004
work page 2004
-
[36]
Deep retinex decomposition for low-light enhancement
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. InBritish Machine Vision Conference, 2018
work page 2018
-
[37]
Gradient as conditions: Rethinking hog for all-in-one image restoration
Jiawei Wu, Zhifei Yang, Zhe Wang, and Zhi Jin. Gradient as conditions: Rethinking hog for all-in-one image restoration. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
work page 2026
-
[38]
Yimin Xu, Nanxi Gao, Yunshan Zhong, Fei Chao, and Rongrong Ji. Unified-width adaptive dynamic network for all-in-one image restoration.arXiv preprint arXiv:2401.13221, 2024
-
[39]
Language-driven all-in-one adverse weather removal
Hao Yang, Liyuan Pan, Yan Yang, and Wei Liang. Language-driven all-in-one adverse weather removal. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2024
work page 2024
-
[40]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[41]
Deep joint rain detection and removal from a single image
Wenhan Yang, Robby T Tan, Jiashi Feng, Jiaying Liu, Zongming Guo, and Shuicheng Yan. Deep joint rain detection and removal from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[42]
Deep Retinex Decomposition for Low-Light Enhancement
Wenhan Yang, Wenjing Wang, Haofeng Huang, Shiqi Wang, and Jiaying Liu. Sparse gradient regularized deep retinex network for robust low-light image enhancement.arXiv preprint arXiv:1808.04560, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Adverse weather removal with codebook priors
Tian Ye, Sixiang Chen, Jinbin Bai, Jun Shi, Chenghao Xue, Jingxia Jiang, Junjie Yin, Erkang Chen, and Yun Liu. Adverse weather removal with codebook priors. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[44]
Vision-language gradient descent-driven all-in-one deep unfolding networks
Haijin Zeng, Xiaoming Wang, Yongyong Chen, Jingyong Su, and Jie Liu. Vision-language gradient descent-driven all-in-one deep unfolding networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[45]
The unreason- able effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[46]
Glare: Low light image enhancement via generative latent feature based codebook retrieval
Han Zhou, Wei Dong, Xiaohong Liu, Shuaicheng Liu, Xiongkuo Min, Guangtao Zhai, and Jun Chen. Glare: Low light image enhancement via generative latent feature based codebook retrieval. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[47]
Low-light image enhancement via generative perceptual priors
Han Zhou, Wei Dong, Xiaohong Liu, Yulun Zhang, Guangtao Zhai, and Jun Chen. Low-light image enhancement via generative perceptual priors. InProceedings of the AAAI Conference on Artificial Intelligence, 2025
work page 2025
-
[48]
Lednet: Joint low-light enhancement and deblurring in the dark
Shangchen Zhou, Chongyi Li, and Chen Change Loy. Lednet: Joint low-light enhancement and deblurring in the dark. InEuropean Conference on Computer Vision, 2022
work page 2022
-
[49]
Yurui Zhu, Tianyu Wang, Xueyang Fu, Xuanyu Yang, Xin Guo, Jifeng Dai, Yu Qiao, and Xiaowei Hu. Learning weather-general and weather-specific features for image restoration under multiple adverse weather conditions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 13
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.