Recognition: 2 theorem links
· Lean TheoremWirelessSenseLLM: Zero-Shot Human Activity Understanding by Bridging Wireless Signals and Human Language
Pith reviewed 2026-05-15 02:18 UTC · model grok-4.3
The pith
WirelessSenseLLM uses an adapter to map unsegmented Wi-Fi CSI signals into language space for zero-shot motion descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
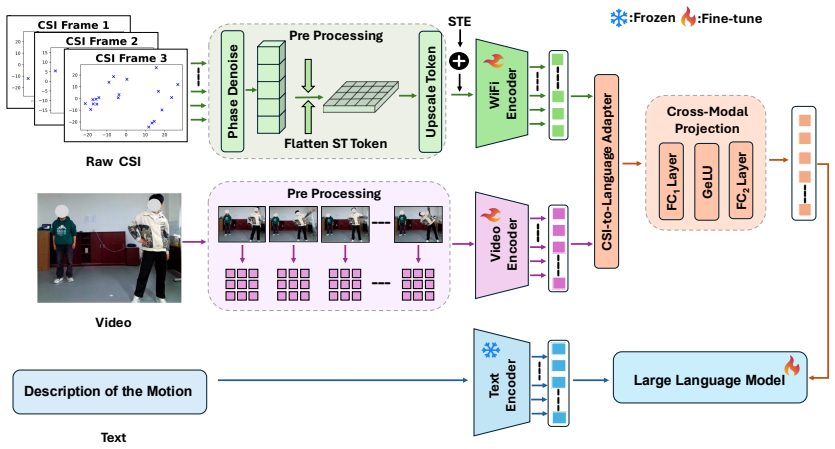
We present WirelessSenseLLM, a language-driven framework that leverages large language models to enable zero-shot human motion understanding from unsegmented Wi-Fi Channel State Information (CSI). To bridge the modality gap between time-series CSI and discrete language representations, we introduce a CSI-to-Language Adapter and a cross-modal projection mechanism that maps CSI features into a language-aligned semantic space. This design enables the generation of fine-grained natural language descriptions of sequential and overlapping human motions, supporting downstream reasoning without segmented training data.
What carries the argument
CSI-to-Language Adapter with cross-modal projection that aligns time-series CSI features to language embeddings for zero-shot generation.
Load-bearing premise
The CSI-to-Language Adapter can reliably map unsegmented CSI time-series features into a language-aligned semantic space even when actions overlap.
What would settle it
If the generated language descriptions systematically fail to match the actual sequence and timing of motions in a held-out set of unsegmented CSI recordings, the zero-shot claim would not hold.
Figures






read the original abstract
There is growing interest in enabling wireless sensing systems to interpret human motion from unsegmented wireless signals; however, existing CSI-based applications rely heavily on accurate signal segmentation and predefined action labels, limiting their applicability in zero-shot scenarios. We present WirelessSenseLLM, a language-driven framework that leverages large language models (LLMs) to enable zero-shot human motion understanding from unsegmented Wi-Fi Channel State Information (CSI). To bridge the modality gap between time-series CSI and discrete language representations, we introduce a CSI-to-Language Adapter and a cross-modal projection mechanism that maps CSI features into a language-aligned semantic space. This design enables the generation of fine-grained natural language descriptions of sequential and overlapping human motions, supporting downstream reasoning without segmented training data. We address two core technical challenges: modality mismatch between CSI features and language embeddings, and overlapping actions in unsegmented CSI streams. Extensive experiments demonstrate strong performance in zero-shot action understanding (92% accuracy and 91% F1-score), language-based reasoning quality (30% factual and 15% reasoning improvements), and multi-person motion explanation with an average 12.33% improvement over prior methods. These results highlight WirelessSenseLLM's effectiveness for robust and interpretable human motion understanding from CSI signals.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CSI-to-Language Adapter ... two-layer MLP with GeLU activation to map CSI embeddings into language-aligned semantic space Z_l ... Contrastive learning ... L = L_c2t + L_t2c
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
cross-modal projection mechanism that maps CSI features into a language-aligned semantic space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Human activity recognition using csi information with nexmon,
J. Sch ¨afer, B. R. Barrsiwal, M. Kokhkharova, H. Adil, and J. Liebehenschel, “Human activity recognition using csi information with nexmon,”Applied Sciences, vol. 11, no. 19, p. 8860, 2021
work page 2021
-
[2]
R-dehm: Csi-based robust duration estimation of human motion with wifi,
J. Zhao, L. Liu, Z. Wei, C. Zhang, W. Wang, and Y . Fan, “R-dehm: Csi-based robust duration estimation of human motion with wifi,”Sensors, vol. 19, no. 6, p. 1421, 2019
work page 2019
-
[3]
Towards position-independent sensing for gesture recognition with wi-fi,
R. Gao, M. Zhang, J. Zhang, Y . Li, E. Yi, D. Wu, L. Wang, and D. Zhang, “Towards position-independent sensing for gesture recognition with wi-fi,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiq- uitous Technologies, vol. 5, no. 2, pp. 1–28, 2021
work page 2021
-
[4]
Sensing technology for human activity recognition: A comprehensive survey,
B. Fu, N. Damer, F. Kirchbuchner, and A. Kuijper, “Sensing technology for human activity recognition: A comprehensive survey,”Ieee Access, vol. 8, pp. 83 791– 83 820, 2020
work page 2020
-
[5]
Wireless sensing for human activity: A survey,
J. Liu, H. Liu, Y . Chen, Y . Wang, and C. Wang, “Wireless sensing for human activity: A survey,”IEEE Communica- tions Surveys & Tutorials, vol. 22, no. 3, pp. 1629–1645, 2019
work page 2019
-
[6]
M. J. Bocus, W. Li, S. Vishwakarma, R. Kou, C. Tang, K. Woodbridge, I. Craddock, R. McConville, R. Santos- Rodriguez, K. Chettyet al., “Operanet, a multimodal ac- tivity recognition dataset acquired from radio frequency and vision-based sensors,”Scientific data, vol. 9, no. 1, p. 474, 2022
work page 2022
-
[7]
Wi-chat: Large language model powered wi-fi sensing,
H. Zhang, Y . Ren, H. Yuan, J. Zhang, and Y . Shen, “Wi-chat: Large language model powered wi-fi sensing,” arXiv preprint arXiv:2502.12421, 2025
-
[8]
Survey on extreme learning machines for outlier detection,
R. Kiani, W. Jin, and V . S. Sheng, “Survey on extreme learning machines for outlier detection,”Machine Learn- ing, vol. 113, no. 8, pp. 5495–5531, 2024
work page 2024
-
[9]
Motionllm: Understanding human behaviors from human motions and videos,
L.-H. Chen, S. Lu, A. Zeng, H. Zhang, B. Wang, R. Zhang, and L. Zhang, “Motionllm: Understanding human behaviors from human motions and videos,”arXiv preprint arXiv:2405.20340, 2024
-
[10]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural informa- tion processing systems, vol. 30, 2017
work page 2017
-
[11]
Deep learning and its applications to wifi human sensing: A benchmark and a tutorial,
J. Yang, X. Chen, D. Wang, H. Zou, C. X. Lu, S. Sun, and L. Xie, “Deep learning and its applications to wifi human sensing: A benchmark and a tutorial,”arXiv preprint arXiv:2207.07859, 2022
-
[12]
Precise power delay profiling with commodity wifi,
Y . Xie, Z. Li, and M. Li, “Precise power delay profiling with commodity wifi,” inProceedings of the 21st An- nual international conference on Mobile Computing and Networking, 2015, pp. 53–64
work page 2015
-
[13]
Device-free wireless sensing for human detection: The deep learning perspective,
R. Zhang, X. Jing, S. Wu, C. Jiang, J. Mu, and F. R. Yu, “Device-free wireless sensing for human detection: The deep learning perspective,”IEEE Internet of Things Journal, vol. 8, no. 4, pp. 2517–2539, 2020
work page 2020
-
[14]
Wifi-based human sensing with deep learning: Recent advances, challenges, and opportunities,
I. Ahmad, A. Ullah, and W. Choi, “Wifi-based human sensing with deep learning: Recent advances, challenges, and opportunities,”IEEE Open Journal of the Commu- nications Society, vol. 5, pp. 3595–3623, 2024
work page 2024
-
[15]
M. S. Islam, M. K. A. Jannat, M. N. Hossain, W.- S. Kim, S.-W. Lee, and S.-H. Yang, “Stc-nlstmnet: An improved human activity recognition method using convolutional neural network with nlstm from wifi csi,” Sensors, vol. 23, no. 1, p. 356, 2022
work page 2022
-
[16]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual represen- tation by alignment before projection,”arXiv preprint arXiv:2311.10122, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Z. Lai, J. Yang, S. Xia, L. Lin, L. Sun, R. Wang, J. Liu, Q. Wu, and L. Pei, “Radarllm: Empowering large language models to understand human motion from millimeter-wave point cloud sequence,”arXiv preprint arXiv:2504.09862, 2025
-
[18]
Skeleton-based human pose recognition using channel state information: A survey,
Z. Wang, M. Ma, X. Feng, X. Li, F. Liu, Y . Guo, and D. Chen, “Skeleton-based human pose recognition using channel state information: A survey,”Sensors, vol. 22, no. 22, p. 8738, 2022
work page 2022
-
[19]
F. Abuhoureyah, K. S. Sim, and Y . C. Wong, “Multi-user human activity recognition through adaptive location- independent wifi signal characteristics,”IEEE Access, vol. 12, pp. 112 008–112 024, 2024
work page 2024
-
[20]
M. I. Kobir, P. Machado, A. Lotfi, D. Haider, and I. K. Ihianle, “Enhancing multi-user activity recognition in an indoor environment with augmented wi-fi channel state information and transformer architectures,”Sensors, vol. 25, no. 13, p. 3955, 2025
work page 2025
-
[21]
Person-in-wifi 3d: End-to-end multi-person 3d pose estimation with wi-fi,
K. Yan, F. Wang, B. Qian, H. Ding, J. Han, and X. Wei, “Person-in-wifi 3d: End-to-end multi-person 3d pose estimation with wi-fi,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 969–978
work page 2024
-
[22]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.”ICLR, vol. 1, no. 2, p. 3, 2022
work page 2022
-
[23]
CSI-Bench: A Large-Scale In-the-Wild Dataset for Multi-task WiFi Sensing,
G. Zhu, Y . Hu, W. Gao, W.-H. Wang, B. Wang, and K. Liu, “Csi-bench: A large-scale in-the-wild dataset for multi-task wifi sensing,”arXiv preprint arXiv:2505.21866, 2025
-
[24]
Wimans: A benchmark dataset for wifi-based multi-user activity sensing,
S. Huang, K. Li, D. You, Y . Chen, A. Lin, S. Liu, X. Li, and J. A. McCann, “Wimans: A benchmark dataset for wifi-based multi-user activity sensing,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 72–91
work page 2024
-
[25]
A survey on behavior recognition using wifi chan- nel state information,
S. Yousefi, H. Narui, S. Dayal, S. Ermon, and S. Valaee, “A survey on behavior recognition using wifi chan- nel state information,”IEEE Communications Magazine, vol. 55, no. 10, pp. 98–104, 2017
work page 2017
-
[26]
Widar 3.0: Wifi-based activity recognition dataset,
Z. Yang, Y . Zhang, G. Zhang, Y . Zheng, and G. Chi, “Widar 3.0: Wifi-based activity recognition dataset,” IEEE Dataport, vol. 10, 2020
work page 2020
-
[27]
Sensefi: A library and benchmark on deep-learning-empowered wifi human sensing,
J. Yang, X. Chen, H. Zou, C. X. Lu, D. Wang, S. Sun, and L. Xie, “Sensefi: A library and benchmark on deep-learning-empowered wifi human sensing,”Patterns, vol. 4, no. 3, 2023
work page 2023
-
[28]
LLaVA-OneVision: Easy Visual Task Transfer
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liuet al., “Llava- onevision: Easy visual task transfer,”arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
work page 2022
-
[30]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText summarization branches out, 2004, pp. 74–81
work page 2004
-
[31]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Associ- ation for Computational Linguistics, 2002, pp. 311–318
work page 2002
-
[32]
Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,” inProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72
work page 2005
-
[33]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,”arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.