Recognition: no theorem link
Rethinking Layer Relevance in Large Language Models Beyond Cosine Similarity
Pith reviewed 2026-05-15 05:01 UTC · model grok-4.3
The pith
Cosine similarity can be arbitrarily low for a layer that is still essential to an LLM's performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
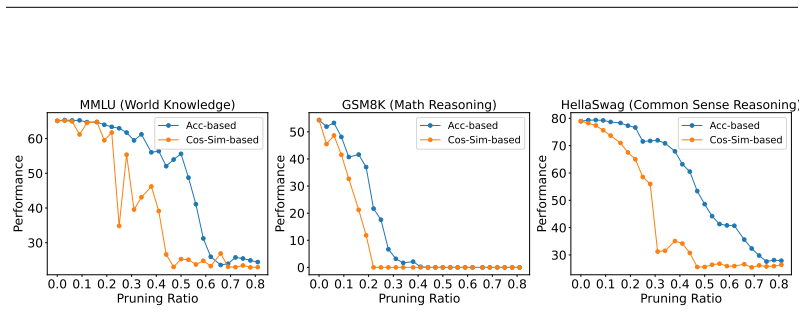
Our theoretical analysis shows that a layer can exhibit an arbitrarily low cosine similarity score while still being crucial to the model's performance. Empirical evidence from a range of LLMs confirms that the correlation between cosine similarity and actual performance degradation is often weak or moderate, leading to misleading interpretations of a transformer's internal mechanisms. We propose a more robust metric for assessing layer relevance: the actual drop in model accuracy resulting from the removal of a layer.
What carries the argument
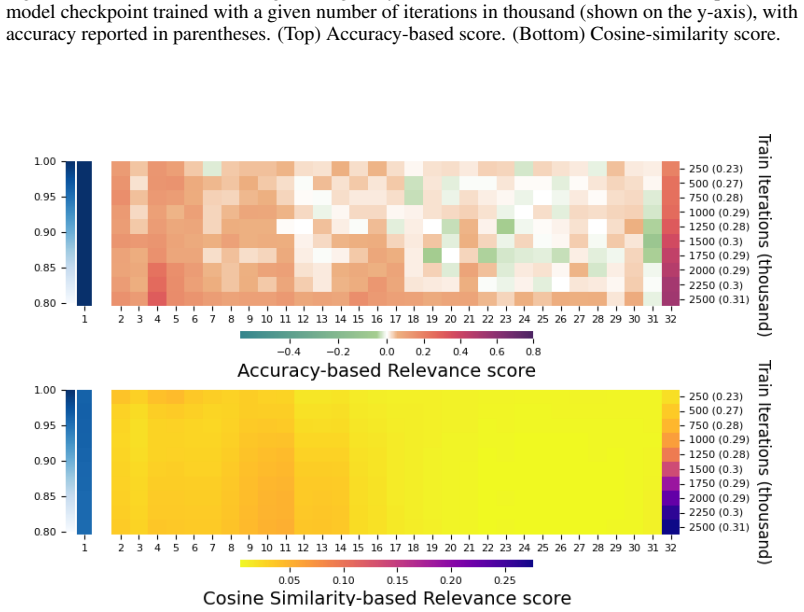
The accuracy drop metric obtained by removing one layer from the intact model and measuring the resulting change in task performance.
If this is right
- Pruning decisions based on cosine similarity alone can retain unimportant layers or discard essential ones.
- Mechanistic interpretability studies that rely on similarity measures may miss layers that drive actual capability.
- Lightweight model construction improves when layers are ranked by measured performance impact rather than similarity.
- Intervention methods such as targeted removal become preferred over passive similarity checks for assessing component importance.
Where Pith is reading between the lines
- The accuracy-drop test could be applied to smaller units such as individual attention heads or MLP blocks.
- For models too large for repeated full evaluations, cheap surrogate tests that approximate the drop would be valuable next steps.
- Existing pruning literature that used cosine similarity may need re-examination with the performance-based ranking.
Load-bearing premise
That removing a single layer and measuring accuracy drop on held-out tasks gives a faithful picture of that layer's contribution inside the intact model without major compensatory effects from remaining layers.
What would settle it
Finding a consistent strong correlation (Pearson's r above 0.7) between cosine similarity scores and accuracy drops across diverse LLMs and tasks would challenge the claim that cosine similarity is a poor proxy.
Figures
















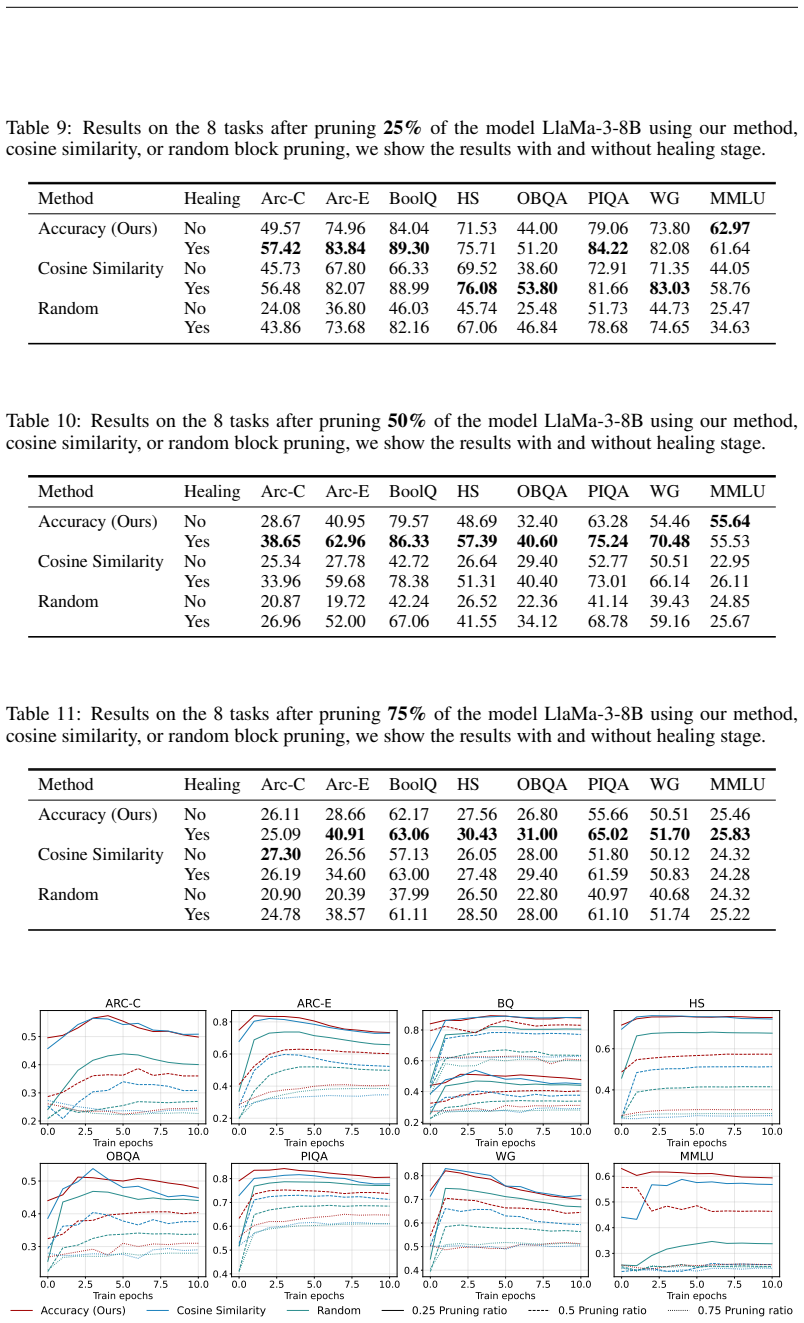
read the original abstract
Large language models (LLMs) have revolutionized natural language processing. Understanding their internal mechanisms is crucial for developing more interpretable and optimized architectures. Mechanistic interpretability has led to the development of various methods for assessing layer relevance, with cosine similarity being a widely used tool in the field. On this work, we demonstrate that cosine similarity is a poor proxy for the actual performance degradation caused by layer removal. Our theoretical analysis shows that a layer can exhibit an arbitrarily low cosine similarity score while still being crucial to the model's performance. On the other hand, empirical evidence from a range of LLMs confirms that the correlation between cosine similarity and actual performance degradation is often weak or moderate, leading to misleading interpretations of a transformer's internal mechanisms. We propose a more robust metric for assessing layer relevance: the actual drop in model accuracy resulting from the removal of a layer. Even though it is a computationally costly metric, this approach offers a more accurate picture of layer importance, allowing for more informed pruning strategies and lightweight models. Our findings have significant implications for the development of interpretable LLMs and highlight the need to move beyond cosine similarity in assessing layer relevance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that cosine similarity is a poor proxy for layer relevance in LLMs. It presents a theoretical construction showing that a layer can have arbitrarily low cosine similarity yet remain crucial to performance, and reports empirical evidence of only weak or moderate correlation between cosine similarity and the accuracy drop caused by removing that layer. The authors propose the accuracy drop upon single-layer removal as a more faithful (though expensive) metric for assessing importance and guiding pruning.
Significance. If the central claim holds, the work would usefully caution against over-reliance on cosine similarity in mechanistic interpretability and motivate more direct ablation-based diagnostics for layer importance. The theoretical counter-example is a clear strength, and the suggestion of a performance-based metric has practical value for model compression. However, the significance is limited by the unexamined assumption that single-layer ablation faithfully isolates a layer’s contribution without compensatory effects from the remaining network.
major comments (2)
- [Empirical evidence] The central empirical claim—that cosine similarity correlates only weakly with actual layer importance—rests on treating post-removal accuracy drop as the unbiased ground-truth metric. The manuscript does not discuss or control for the possibility that remaining layers can compensate for the removed layer, which is a known concern in overparameterized transformers; this assumption is load-bearing for the reported weak correlation.
- [Theoretical analysis] The theoretical analysis constructs a case of low cosine similarity yet high importance, but the argument only demonstrates that cosine similarity can be misleading if the ablation metric is accepted as faithful. No quantitative bound or example is given showing how large the discrepancy can be under realistic transformer dynamics.
minor comments (2)
- [Abstract] The abstract and introduction should explicitly state the models, datasets, and number of layers tested in the empirical section to allow readers to assess the scope of the weak-correlation claim.
- [Methods] Notation for the proposed accuracy-drop metric should be introduced formally (e.g., as ΔAcc_l) and distinguished from cosine similarity in all equations and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key assumptions underlying our claims. We address each major point below and outline targeted revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Empirical evidence] The central empirical claim—that cosine similarity correlates only weakly with actual layer importance—rests on treating post-removal accuracy drop as the unbiased ground-truth metric. The manuscript does not discuss or control for the possibility that remaining layers can compensate for the removed layer, which is a known concern in overparameterized transformers; this assumption is load-bearing for the reported weak correlation.
Authors: We agree that compensatory effects among remaining layers constitute a genuine limitation when interpreting accuracy drop as an isolated measure of layer importance. The original manuscript did not explicitly address this issue. In the revision we will add a new paragraph in the Discussion section that acknowledges this possibility, references prior work on ablation compensation in overparameterized networks, and clarifies that the accuracy-drop metric is advanced as a more direct performance-based alternative to cosine similarity rather than an absolute ground truth. We will also note that future multi-layer ablation studies could further isolate contributions. revision: partial
-
Referee: [Theoretical analysis] The theoretical analysis constructs a case of low cosine similarity yet high importance, but the argument only demonstrates that cosine similarity can be misleading if the ablation metric is accepted as faithful. No quantitative bound or example is given showing how large the discrepancy can be under realistic transformer dynamics.
Authors: The theoretical construction is deliberately general, showing that cosine similarity can be made arbitrarily low while a layer remains essential to the output, without depending on specific transformer dynamics. We accept that this does not supply quantitative bounds or realistic-dynamics examples. The revised manuscript will include a short numerical illustration using synthetic linear layers to demonstrate the scale of possible discrepancy, and will explicitly state that the argument establishes the possibility of failure rather than providing bounds for all practical cases. revision: partial
Circularity Check
No significant circularity; ablation metric is independently defined
full rationale
The paper defines its proposed layer-relevance metric directly as the observed accuracy drop after single-layer removal, an empirical quantity measured on held-out tasks and not constructed from cosine similarity, fitted parameters, or prior self-citations. The theoretical claim constructs an explicit counter-example showing arbitrarily low cosine similarity can coexist with high importance, without any definitional loop. Empirical correlations are then computed between cosine similarity and this external ablation drop; no step renames a known result, imports a uniqueness theorem from the authors' prior work, or smuggles an ansatz via citation. The derivation chain is therefore self-contained against the chosen ground-truth metric.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer layers can be removed individually without retraining while still allowing meaningful accuracy measurement.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , booktitle=NIPS17, year=
Attention is all you need , author=. Advances in neural information processing systems , booktitle=NIPS17, year=
-
[2]
All bark and no bite: Rogue dimensions in transformer language models obscure representational quality , author=
-
[3]
A Survey on Transformers in Reinforcement Learning , author=. 2023 , journal=
work page 2023
-
[4]
Breakthroughs in statistics: Methodology and distribution , pages=
Individual comparisons by ranking methods , author=. Breakthroughs in statistics: Methodology and distribution , pages=. 1992 , publisher=
work page 1992
-
[5]
Journal of the american statistical association , volume=
The use of ranks to avoid the assumption of normality implicit in the analysis of variance , author=. Journal of the american statistical association , volume=. 1937 , publisher=
work page 1937
-
[6]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
On transforming reinforcement learning with transformers: The development trajectory , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[7]
Chen, Lili and Lu, Kevin and Rajeswaran, Aravind and Lee, Kimin and Grover, Aditya and Laskin, Michael and Abbeel, Pieter and Srinivas, Aravind and Mordatch, Igor , title =. 2021 , address =
work page 2021
-
[8]
ACM computing surveys (CSUR) , volume=
Transformers in vision: A survey , author=. ACM computing surveys (CSUR) , volume=. 2022 , publisher=
work page 2022
-
[9]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[10]
Emerging Properties in Self-Supervised Vision Transformers , author=
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Multimodal learning with transformers: A survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[12]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[13]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[14]
BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer , author=. Proceedings of the 28th ACM international conference on information and knowledge management , pages=
-
[15]
2018 IEEE international conference on data mining (ICDM) , pages=
Self-attentive sequential recommendation , author=. 2018 IEEE international conference on data mining (ICDM) , pages=. 2018 , organization=
work page 2018
-
[16]
Proceedings of the 14th ACM Conference on Recommender Systems , pages=
Interpretable contextual team-aware item recommendation: application in multiplayer online battle arena games , author=. Proceedings of the 14th ACM Conference on Recommender Systems , pages=
-
[17]
Transformer layers as painters , author=
-
[18]
Transformer feed-forward layers are key-value memories , author=. 2021 , organization=
work page 2021
-
[19]
ACM Journal on Emerging Technologies in Computing Systems (JETC) , volume=
Structured pruning of deep convolutional neural networks , author=. ACM Journal on Emerging Technologies in Computing Systems (JETC) , volume=. 2017 , publisher=
work page 2017
-
[20]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space , author=. 2022 , organization=
work page 2022
-
[21]
What does BERT learn about the structure of language? , author=
-
[22]
What does BERT look at? an analysis of BERT’s attention , author=. 2019 , organization=
work page 2019
-
[23]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 Conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages=
work page 2019
-
[24]
Locating and Editing Factual Associations in GPT , author=
-
[25]
Dissecting recall of factual associations in auto-regressive language models , author=. 2023 , organization=
work page 2023
-
[26]
Language models represent space and time , author=
-
[27]
arXiv preprint arXiv:2401.12181 , year=
Universal neurons in gpt2 language models , author=. arXiv preprint arXiv:2401.12181 , year=
-
[28]
arXiv preprint arXiv:2405.14860 , year=
Not all language model features are linear , author=. arXiv preprint arXiv:2405.14860 , year=
-
[29]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
A mechanistic analysis of a transformer trained on a symbolic multi-step reasoning task , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
work page 2024
-
[30]
arXiv preprint arXiv:2310.15154 , year=
Linear representations of sentiment in large language models , author=. arXiv preprint arXiv:2310.15154 , year=
-
[31]
Looking Beyond the Top-1: Transformers Determine Top Tokens in Order , author=. 2025 , url=
work page 2025
-
[32]
Pruning Filters for Efficient ConvNets
Pruning filters for efficient convnets , author=. arXiv preprint arXiv:1608.08710 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Shortgpt: Layers in large language models are more redundant than you expect , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[34]
The Unreasonable Ineffectiveness of the Deeper Layers , author=
-
[35]
arXiv preprint arXiv:2406.15786 , year=
What matters in transformers? not all attention is needed , author=. arXiv preprint arXiv:2406.15786 , year=
- [36]
-
[37]
LLM-pruner: on the structural pruning of large language models , author=
-
[38]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Blockpruner: Fine-grained pruning for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[39]
Proceedings of the NeurIPS 2024 Workshop on Machine Learning and Compression , year=
FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models , author=. Proceedings of the NeurIPS 2024 Workshop on Machine Learning and Compression , year=
work page 2024
-
[40]
Investigating layer importance in large language models , author=
-
[41]
Large Language Models (LLM) in Industry: A Survey of Applications, Challenges, and Trends , author=. Proceedings of the IEEE 21st International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET) , pages=. 2024 , organization=
work page 2024
-
[42]
AI application in journalism: ChatGPT and the uses and risks of an emergent technology , author=. Profesional de la Informaci
-
[43]
Kunal Handa and Drew Bent and Alex Tamkin and Miles McCain and Esin Durmus and Michael Stern and Mike Schiraldi and Saffron Huang and Stuart Ritchie and Steven Syverud and Kamya Jagadish and Margaret Vo and Matt Bell and Deep Ganguli , title =. 2025 , url =
work page 2025
-
[44]
OLMo: Accelerating the science of language models , author=
-
[45]
arXiv preprint arXiv:2411.15558 , year=
Reassessing Layer Pruning in LLMs: New Insights and Methods , author=. arXiv preprint arXiv:2411.15558 , year=
-
[46]
Sleb: Streamlining llms through redundancy verification and elimination of transformer blocks , author=
-
[47]
Information Processing & Management , volume=
Less is more: Towards green code large language models via unified structural pruning , author=. Information Processing & Management , volume=. 2026 , publisher=
work page 2026
-
[48]
arXiv preprint arXiv:2505.18235 , year=
The Origins of Representation Manifolds in Large Language Models , author=. arXiv preprint arXiv:2505.18235 , year=
-
[49]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Laco: Large language model pruning via layer collapse , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[50]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[51]
Computer Speech & Language , volume=
On the effect of dropping layers of pre-trained transformer models , author=. Computer Speech & Language , volume=. 2023 , publisher=
work page 2023
-
[52]
SliceGPT: Compress Large Language Models by Deleting Rows and Columns , author=
-
[53]
How do transformers learn topic structure: Towards a mechanistic understanding , author=. 2023 , organization=
work page 2023
-
[54]
Javier Ferrando and Gabriele Sarti and Arianna Bisazza and Marta R. Costa. A Primer on the Inner Workings of Transformer-based Language Models , journal =. 2024 , url =. doi:10.48550/ARXIV.2405.00208 , eprinttype =. 2405.00208 , timestamp =
-
[55]
arXiv preprint arXiv:2410.14649 , year=
Evopress: Towards optimal dynamic model compression via evolutionary search , author=. arXiv preprint arXiv:2410.14649 , year=
-
[56]
Proceedings of the ICML 2024 Workshop on Theoretical Foundations of Foundation Models , year=
A deeper look at depth pruning of LLMs , author=. Proceedings of the ICML 2024 Workshop on Theoretical Foundations of Foundation Models , year=
work page 2024
-
[57]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[58]
arXiv preprint arXiv:2309.05653 , year=
Mammoth: Building math generalist models through hybrid instruction tuning , author=. arXiv preprint arXiv:2309.05653 , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Lima: Less is more for alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
A Simple and Effective Pruning Approach for Large Language Models , author=
-
[61]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[62]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[66]
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. Proceedings of the 2019 Conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages=
work page 2019
-
[67]
Piqa: Reasoning about physical commonsense in natural language , author=
-
[68]
Hellaswag: Can a machine really finish your sentence? , author=
-
[69]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
work page 2021
-
[70]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Measuring Massive Multitask Language Understanding , author=
-
[72]
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=
-
[73]
CodeAlpaca: Instruction tuning for code generation , author =. 2023 , url =
work page 2023
-
[74]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[75]
QLoRA: Efficient Finetuning of Quantized LLMs , author=
-
[76]
LoRA: Low-Rank Adaptation of Large Language Models , author=
-
[77]
Sourab Mangrulkar and Sylvain Gugger and Lysandre Debut and Younes Belkada and Sayak Paul and Benjamin Bossan and Marian Tietz , howpublished =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.