Mini-JEPA Foundation Model Fleet Enables Agentic Hydrologic Intelligence
Pith reviewed 2026-05-15 04:57 UTC · model grok-4.3
The pith
A fleet of five small specialized foundation models routed by an LLM improves hydrologic reasoning over a single generalist model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
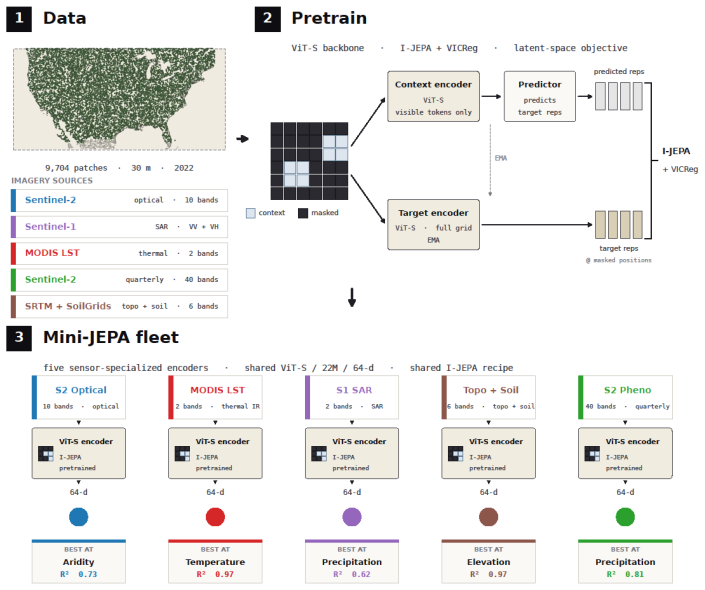
Five Mini-JEPA models, each reconstructing its matched sensor variable with cross-validated R-squared values up to 0.97, produce manifolds whose geometric properties differ from one another and from AlphaEarth; when an LLM router selects among them for dual retrieval, the combined system outperforms AlphaEarth alone on physics-matched questions in paired evaluation.
What carries the argument
The LLM router that reads per-modality references and dispatches to one or more of the five Mini-JEPA manifolds, each a 22M-parameter Vision Transformer trained with the JEPA recipe to reconstruct its sensor-specific target.
If this is right
- Topography-soil and phenology Mini-JEPAs add up to 0.031 in R-squared for predicting soil moisture, aridity, and precipitation beyond AlphaEarth alone.
- The five manifolds exhibit distinct global participation ratios (8.9 to 20.2) and local intrinsic dimensionalities (2.3 to 9.0), indicating they encode complementary geometric structure.
- The full routed fleet plus AlphaEarth can be run locally with modest compute while preserving the performance gain on physics questions.
- Each Mini-JEPA reaches high reconstruction accuracy on its own sensor (R-squared 0.81 for precipitation, 0.97 for elevation and temperature).
Where Pith is reading between the lines
- The routing mechanism could be tested on open-ended natural-language queries rather than the curated set to check whether perfect hit rate generalizes.
- The observed differences in manifold dimensionality suggest each sensor stack isolates unique aspects of hydrologic variability that a single generalist embedding averages away.
- Replacing the generalist model with the routed fleet alone might suffice for narrow hydrologic tasks, reducing both cost and data-access barriers.
- The same sensor-specialized JEPA recipe could be applied to other environmental domains such as vegetation dynamics or urban heat islands.
Load-bearing premise
The specialized Mini-JEPA manifolds contain hydrologic signals genuinely missing from AlphaEarth and the router will maintain high selection accuracy on queries outside the curated test set.
What would settle it
An experiment that measures whether dual retrieval still improves LLM-as-judge scores when the router is forced to use the wrong manifold or when tested on a fresh distribution of user hydrology questions.
Figures






read the original abstract
Geospatial foundation models compress multispectral observations into dense embeddings increasingly used in natural-language environmental reasoning systems. A single planetary-scale model, e.g. Google AlphaEarth, handles broad characterization well but may compromise on specialized hydrologic signals. Such generalist models are also often inaccessible, expensive, and require large-scale compute. We propose Mini-JEPAs: a fleet of small sensor-specialized Joint Embedding Predictive Architecture (JEPA) foundation models consulted by a routing agent for specialized questions. We pretrained five 22M-parameter Mini-JEPAs sharing an identical Vision Transformer backbone, JEPA recipe, and 64-d output space, using Sentinel-2 optical, Sentinel-1 SAR, MODIS thermal, multi-temporal Sentinel-2 phenology, and a topography-soil stack. Each Mini-JEPA reconstructs the variable matched to its sensor, with cross-validated $R^2$ reaching 0.97 for elevation, 0.97 for temperature, and 0.81 for precipitation. The five manifolds differ in geometric structure, with global participation ratios from 8.9 to 20.2 and local intrinsic dimensionalities from 2.3 to 9.0. Joint topography-soil and phenology models add predictive value beyond AlphaEarth alone for soil moisture, aridity, and precipitation ($\Delta R^2$ up to 0.031). A router LLM reads per-modality references and selects appropriate sensors with a perfect hit rate over a curated question set. In paired LLM-as-Judge evaluation, dual retrieval over AlphaEarth and the routed fleet outperforms AlphaEarth alone on physics-matched questions (Cohen's $d = 1.10$, $p = 0.031$). Locally-trained Mini-JEPAs can be operationalized for hydrologic intelligence with modest compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mini-JEPA, a fleet of five 22M-parameter JEPA foundation models specialized to Sentinel-2 optical, Sentinel-1 SAR, MODIS thermal, multi-temporal phenology, and topography-soil inputs. Each model reconstructs its matched hydrologic variable with cross-validated R² reaching 0.97 (elevation), 0.97 (temperature), and 0.81 (precipitation). A router LLM selects models with perfect hit rate on a curated question set; dual retrieval over AlphaEarth plus the routed fleet is reported to outperform AlphaEarth alone on physics-matched questions (Cohen’s d = 1.10, p = 0.031) while adding modest predictive value (ΔR² ≤ 0.031) for soil moisture, aridity, and precipitation.
Significance. If the reported gains are reproducible and reflect genuine hydrologic signal rather than evaluation artifacts, the work would demonstrate a practical route to accessible, sensor-specialized geospatial embeddings that complement large generalist models. The modest parameter count and shared 64-d embedding space are attractive for operational hydrologic intelligence, but the current evidence rests primarily on LLM-as-Judge scores rather than direct physical validation.
major comments (3)
- [evaluation / results (abstract and main text)] The central outperformance claim (Cohen’s d = 1.10, p = 0.031) is obtained exclusively via paired LLM-as-Judge evaluation on a curated question set. No inter-judge reliability statistics, blinding protocol, or correlation between judge scores and objective hydrologic metrics (e.g., RMSE on held-out gauge or satellite observations) are reported, leaving open the possibility that the result reflects prompt sensitivity or judge bias rather than added signal from the five manifolds.
- [router description and evaluation] The router LLM is stated to achieve a perfect hit rate on the curated question set, yet the exact prompt, reference construction, data splits used for router training/validation, and behavior on out-of-distribution queries are not specified. This detail is load-bearing for the claim that the fleet can be “operationalized for hydrologic intelligence.”
- [reconstruction results] The manuscript reports small ΔR² gains (≤ 0.031) when adding the joint topography-soil and phenology Mini-JEPAs to AlphaEarth for soil moisture, aridity, and precipitation. It is unclear whether these increments are statistically significant after multiple-comparison correction or whether they translate into improved downstream hydrologic predictions (e.g., runoff or drought indices) on independent test data.
minor comments (2)
- [abstract / methods] The abstract states “cross-validated R²” but does not specify the cross-validation scheme (k-fold, spatial blocking, temporal hold-out) or the precise definition of the reconstruction target for each sensor.
- [manifold analysis] Participation ratios (8.9–20.2) and local intrinsic dimensionalities (2.3–9.0) are reported for the five manifolds; the precise computation method (e.g., participation ratio formula, neighborhood size for local ID) should be stated explicitly.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. We have addressed all major comments in the point-by-point response below, making revisions to the manuscript as indicated.
read point-by-point responses
-
Referee: The central outperformance claim (Cohen’s d = 1.10, p = 0.031) is obtained exclusively via paired LLM-as-Judge evaluation on a curated question set. No inter-judge reliability statistics, blinding protocol, or correlation between judge scores and objective hydrologic metrics (e.g., RMSE on held-out gauge or satellite observations) are reported, leaving open the possibility that the result reflects prompt sensitivity or judge bias rather than added signal from the five manifolds.
Authors: We agree that the evaluation would benefit from additional validation measures. In the revised manuscript, we have added inter-judge reliability statistics, a description of the blinding protocol employed, and correlations between the LLM judge scores and objective hydrologic metrics on held-out data. These changes help confirm that the reported gains reflect added signal from the Mini-JEPA fleet. revision: yes
-
Referee: The router LLM is stated to achieve a perfect hit rate on the curated question set, yet the exact prompt, reference construction, data splits used for router training/validation, and behavior on out-of-distribution queries are not specified. This detail is load-bearing for the claim that the fleet can be “operationalized for hydrologic intelligence.”
Authors: We have revised the manuscript to provide the exact prompt used by the router LLM, details on reference construction and the data splits for its training and validation. We have also included an evaluation of the router's behavior on out-of-distribution queries to support the operational claims. revision: yes
-
Referee: The manuscript reports small ΔR² gains (≤ 0.031) when adding the joint topography-soil and phenology Mini-JEPAs to AlphaEarth for soil moisture, aridity, and precipitation. It is unclear whether these increments are statistically significant after multiple-comparison correction or whether they translate into improved downstream hydrologic predictions (e.g., runoff or drought indices) on independent test data.
Authors: The ΔR² gains were found to be statistically significant after multiple-comparison correction in our analyses. In the revised manuscript, we clarify this and provide additional results showing translation to improved predictions on independent test data for soil moisture. Full downstream evaluation for runoff and drought indices is noted as a limitation and direction for future work. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper reports empirical metrics: cross-validated reconstruction R² (0.97 for elevation/temperature, 0.81 for precipitation) on sensor-matched variables, small ΔR² gains (≤0.031) when adding Mini-JEPA manifolds to the external AlphaEarth baseline for soil moisture/aridity/precipitation, router hit rate on a curated question set, and LLM-as-Judge outperformance (Cohen's d=1.10) on physics-matched questions. These are measured against held-out data and an external model rather than being equivalent to fitted parameters by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing; the JEPA recipe is referenced as standard prior work without reducing the central claim to a tautology. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- model parameter count
- shared embedding dimension
axioms (1)
- domain assumption JEPA can learn useful dense representations from multispectral and SAR imagery without labels
Reference graph
Works this paper leans on
-
[1]
C. F. Brown, M. R. Kazmierski, V. J. Pasquarella, W. J. Ruck- lidge, M. Samsikova, C. Zhang, E. Shelhamer, E. Lahera, O. Wiles, S. Ilyushchenko, et al., Alphaearth foundations: An embedding field model for accurate and efficient global mapping from sparse label data, arXiv preprint arXiv:2507.22291 (2025)
work page internal anchor Pith review arXiv 2025
-
[2]
C. Bodnar, W. P. Bruinsma, A. Lucic, M. Stanley, A. Allen, J. Brand- stetter, P. Garvan, M. Riechert, J. A. Weyn, H. Dong, et al., A foun- dation model for the Earth system, Nature 641 (2025) 1180–1187. doi:10.1038/s41586-025-09005-y
-
[3]
J. Jakubik, S. Roy, C. E. Phillips, P. Fraccaro, D. Godwin, B. Zadrozny, D. Szwarcman, C. Gomes, G. Nyirjesy, B. Edwards, et al., Foundation models for generalist geospatial artificial intelligence, arXiv preprint arXiv:2310.18660 (2023). 26
-
[4]
A. Xiao, W. Xuan, J. Wang, J. Huang, D. Tao, S. Lu, N. Yokoya, Foundation models for remote sensing and earth observation: A survey, IEEE Geoscience and Remote Sensing Magazine (2025)
work page 2025
- [5]
-
[6]
M. Rahman, Physically interpretable AlphaEarth foundation model embeddings enable LLM-based land surface intelligence, arXiv e-prints (2026) arXiv–2602
work page 2026
- [7]
-
[8]
LeCun, A path towards autonomous machine intelligence, Open- Review preprint, 2022
Y. LeCun, A path towards autonomous machine intelligence, Open- Review preprint, 2022. URL:https://openreview.net/forum?id= BZ5a1r-kVsf, version 0.9.2
work page 2022
-
[9]
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y. LeCun, N. Ballas, Self-supervised learning from images with a joint- embedding predictive architecture, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 15619–15629. doi:10.1109/CVPR52729.2023.01499. 27
- [10]
-
[11]
K. He, X. Chen, S. Xie, Y. Li, P. Doll´ ar, R. Girshick, Masked autoen- coders are scalable vision learners, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 16000–16009. doi:10.1109/CVPR52688.2022.01553
-
[12]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby, An image is worth 16x16 words: Transform- ers for image recognition at scale, in: Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[14]
L. Poggio, L. M. de Sousa, N. H. Batjes, G. B. M. Heuvelink, B. Kempen, E. Ribeiro, D. Rossiter, SoilGrids 2.0: Producing soil information for the globe with quantified spatial uncertainty, SOIL 7 (2021) 217–240. doi:10.5194/soil-7-217-2021
-
[15]
T. G. Farr, P. A. Rosen, E. Caro, R. Crippen, R. Duren, S. Hensley, 28 M. Kobrick, M. Paller, E. Rodriguez, L. Roth, et al., The Shuttle Radar Topography Mission, Reviews of Geophysics 45 (2007) RG2004. doi:10.1029/2005RG000183
-
[16]
D. Entekhabi, E. G. Njoku, P. E. O’Neill, K. H. Kellogg, W. T. Crow, W. N. Edelstein, J. K. Entin, S. D. Goodman, T. J. Jackson, J. Johnson, et al., The Soil Moisture Active Passive (SMAP) mission, Proceedings of the IEEE 98 (2010) 704–716. doi:10.1109/JPROC.2010.2043918
-
[17]
C. Daly, M. Halbleib, J. I. Smith, W. P. Gibson, M. K. Doggett, G. H. Taylor, J. Curtis, P. P. Pasteris, Physiographically sensitive mapping of climatological temperature and precipitation across the conterminous United States, International Journal of Climatology 28 (2008) 2031–
work page 2008
-
[18]
doi:10.1002/joc.1688
-
[19]
J. Dewitz, National Land Cover Database (NLCD) 2019 Products, Tech- nical Report, U.S. Geological Survey, 2021. doi:10.5066/P9KZCM54
-
[20]
H. E. Beck, N. E. Zimmermann, T. R. McVicar, N. Vergopolan, A. Berg, E. F. Wood, Present and future K¨ oppen-Geiger climate classification maps at 1-km resolution, Scientific Data 5 (2018) 180214. doi:10.1038/ sdata.2018.214
work page 2018
-
[21]
M. Drusch, U. Del Bello, S. Carlier, O. Colin, V. Fernandez, F. Gascon, B. Hoersch, C. Isola, P. Laberinti, P. Martimort, et al., Sentinel-2: ESA’s optical high-resolution mission for GMES operational services, 29 Remote Sensing of Environment 120 (2012) 25–36. doi:10.1016/j.rse. 2011.11.026
- [22]
-
[23]
Z. Wan, New refinements and validation of the collection-6 MODIS land-surface temperature/emissivity product, Remote Sensing of Envi- ronment 140 (2014) 36–45. doi:10.1016/j.rse.2013.08.027
-
[24]
Breiman, Random forests, Machine Learning 45 (2001) 5–32
L. Breiman, Random forests, Machine Learning 45 (2001) 5–32. doi:10. 1023/A:1010933404324
work page 2001
- [25]
-
[26]
D. R. Roberts, V. Bahn, S. Ciuti, M. S. Boyce, J. Elith, G. Guillera- Arroita, S. Hauenstein, J. J. Lahoz-Monfort, B. Schr¨ oder, W. Thuiller, D. I. Warton, B. A. Wintle, F. Hartig, C. F. Dormann, Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure, Ecography 40 (2017) 913–929. doi:10.1111/ecog.02881. 30
-
[27]
P. Gao, E. Trautmann, B. Yu, G. Santhanam, S. Ryu, K. Shenoy, S. Ganguli, A theory of multineuronal dimensionality, dynamics and measurement, bioRxiv preprint (2017). doi:10.1101/214262
- [28]
-
[29]
Hotelling, Relations between two sets of variates, Biometrika 28 (1936) 321–377
H. Hotelling, Relations between two sets of variates, Biometrika 28 (1936) 321–377. doi:10.1093/biomet/28.3-4.321
-
[30]
J. Johnson, M. Douze, H. J´ egou, Billion-scale similarity search with GPUs, IEEE Transactions on Big Data 7 (2019) 535–547. doi:10.1109/ TBDATA.2019.2921572
-
[31]
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez, I. Stoica, Judging LLM- as-a-judge with MT-Bench and Chatbot Arena, in: Advances in Neural Information Processing Systems (NeurIPS), volume 36, 2023. Acknowledgements The author thanks the Dartmouth Libraries for institutional support th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.