Recognition: no theorem link
An Encoded Corrective Double Deep Q-Networks for Multi-Agent Control Systems
Pith reviewed 2026-05-15 01:53 UTC · model grok-4.3
The pith
A message-passing mechanism refines noisy and delayed global states to incrementally correct Q-networks in multi-agent control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
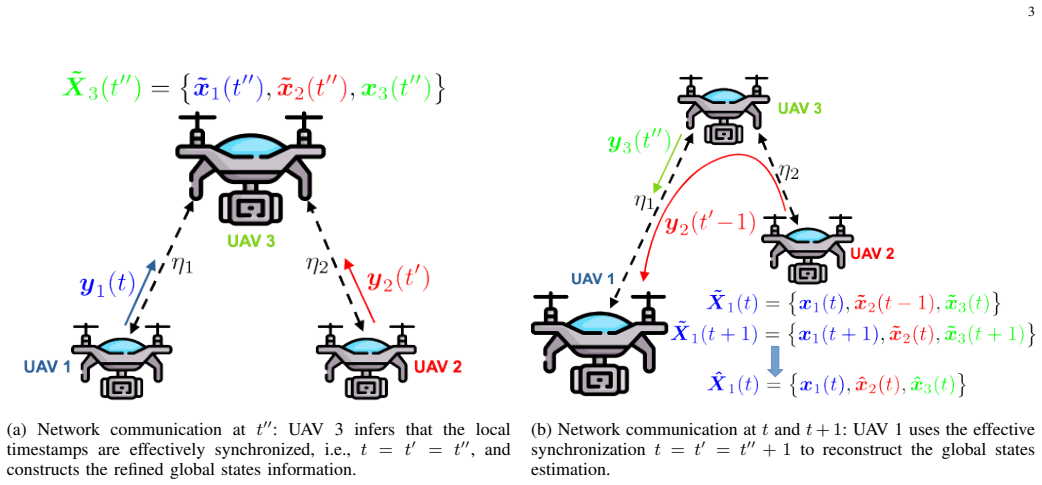
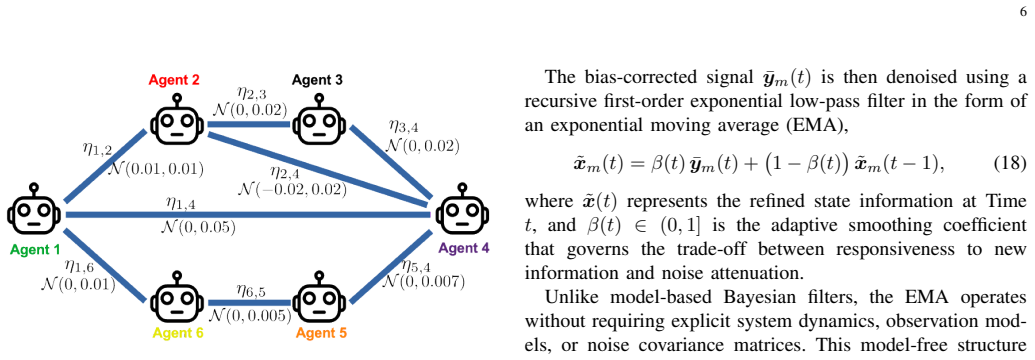
By modeling communication imperfections and employing a message-passing mechanism that tracks timing and information flow, the framework can refine and time-shift global state information from noisy and delayed sources, which is then used to incrementally correct the Q-networks in the double actor-critic setup.
What carries the argument
The novel message-passing mechanism within the encoded corrective double actor-critic framework, which refines global state information based on network timing and flow to correct Q-networks.
Load-bearing premise
That global states, though noisy and delayed, can be progressively reconstructed and refined over time based on the network configuration and the proposed message-passing mechanism.
What would settle it
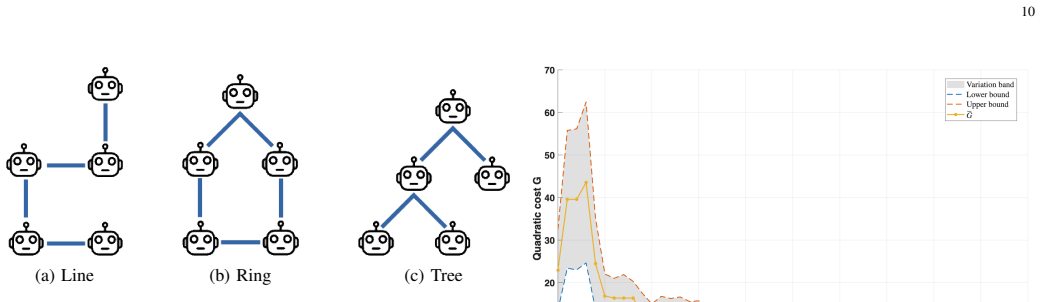
An experiment showing that the reconstructed states do not lead to lower collective costs compared to baselines that ignore delays and noise.
Figures






read the original abstract
This paper studies the synthesis of control policies for heterogeneous and interconnected multi-agent systems that collaborate through data exchange over a communication network to minimize a collective cost. We propose a distributed encoded corrective double actor-critic framework that integrates a novel message-passing mechanism. Existing methods assume noise-free and delay-free access to the global or partial states and overlook the fact that the global states, though noisy and delayed, can be progressively reconstructed and refined over time. In contrast, this work explicitly models communication sampling asynchrony, delay, and link noise based on the network configuration. The proposed message-passing mechanism characterizes timing and information flow to refine and time shift global state information, which is then used to incrementally correct the Q-networks. The double Q-network design mitigates overestimation bias, while the shared encoder coupling the actor-critic networks captures inter-agent dependencies. We evaluate our approach in multiple test cases, demonstrate its effectiveness over various baselines, and provide a numerical regret analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper proposes a distributed encoded corrective double actor-critic framework for synthesizing control policies in heterogeneous multi-agent systems collaborating over communication networks. It introduces a novel message-passing mechanism that explicitly models sampling asynchrony, delay, and link noise based on network configuration to refine and time-shift global state information, which is then used to incrementally correct the Q-networks. The double Q-network design mitigates overestimation bias, while a shared encoder captures inter-agent dependencies. The approach is evaluated on multiple test cases against baselines, with a numerical regret analysis provided.
Significance. If the message-passing mechanism delivers stable progressive reconstruction of global states under realistic communication imperfections, the framework would represent a useful extension of actor-critic methods to distributed multi-agent control with imperfect information exchange. The explicit incorporation of timing and noise modeling addresses a practical gap in existing RL approaches that assume noise-free or delay-free access. The numerical regret analysis, if fully derived, could provide a concrete basis for comparing performance in heterogeneous settings such as robotic swarms or networked control systems.
major comments (2)
- [Abstract] Abstract: The central claim that the message-passing mechanism enables progressive reconstruction and refinement of noisy, delayed global states to correct the Q-networks lacks any referenced convergence bound, error recursion, or stability guarantee. This is load-bearing because, without topology-specific conditions, persistent information loss in low-connectivity graphs could prevent error reduction and render the corrective step ineffective.
- [Evaluation] Evaluation section: The abstract asserts effectiveness over baselines via multiple test cases and a numerical regret analysis, yet no specific quantitative results, regret bounds, baseline definitions, or experimental configurations are detailed. This prevents assessment of whether the reported improvements are statistically meaningful or generalizable beyond the chosen scenarios.
minor comments (1)
- Clarify the precise definition of the shared encoder and how it couples the actor and critic networks; the current description leaves the dependency-capture mechanism somewhat opaque.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating where revisions will be made to improve clarity and address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the message-passing mechanism enables progressive reconstruction and refinement of noisy, delayed global states to correct the Q-networks lacks any referenced convergence bound, error recursion, or stability guarantee. This is load-bearing because, without topology-specific conditions, persistent information loss in low-connectivity graphs could prevent error reduction and render the corrective step ineffective.
Authors: We agree that the manuscript does not provide formal convergence bounds, error recursions, or stability guarantees for the message-passing mechanism. The work is primarily empirical, relying on numerical validation and a regret analysis to demonstrate progressive refinement under modeled communication imperfections. In revision, we will update the abstract to note that reconstruction effectiveness is shown numerically for the considered network configurations and add a short discussion in the introduction on the role of graph connectivity in limiting information loss, without claiming unproven theoretical guarantees. revision: partial
-
Referee: [Evaluation] Evaluation section: The abstract asserts effectiveness over baselines via multiple test cases and a numerical regret analysis, yet no specific quantitative results, regret bounds, baseline definitions, or experimental configurations are detailed. This prevents assessment of whether the reported improvements are statistically meaningful or generalizable beyond the chosen scenarios.
Authors: The full manuscript's Evaluation section contains the specific quantitative results, regret values from the numerical analysis, baseline definitions (including standard multi-agent RL methods), and experimental configurations such as agent heterogeneity, network topologies, delay models, and noise levels. To make the abstract self-contained and address this point, we will incorporate key quantitative highlights and a brief outline of the regret analysis approach into the revised abstract. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained
full rationale
The paper introduces a novel message-passing mechanism within an encoded corrective double actor-critic framework to handle noisy, delayed, and asynchronous global states in heterogeneous multi-agent systems. It explicitly models communication effects based on network configuration and uses this to refine state information for Q-network correction, building on but not reducing to standard double Q-learning. No load-bearing derivation step equates a claimed prediction or result to its inputs by construction, self-definition, or self-citation chain. The central claims rest on the proposed architecture and its empirical evaluation against baselines plus numerical regret analysis, which are independent of any fitted parameters renamed as predictions or uniqueness theorems imported from the authors' prior work. This is the expected honest non-finding for a method-proposal paper with external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Communication sampling asynchrony, delay, and link noise can be modeled based on the network configuration.
- domain assumption Global states can be progressively reconstructed and refined over time despite noise and delays.
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey of multiagent reinforcement learning,
L. Busoniu, R. Babuska, and B. De Schutter, “A comprehensive survey of multiagent reinforcement learning,”IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 2, pp. 156–172, 2008
work page 2008
-
[2]
H. Pei, “Group consensus of multi-agent systems with hybrid charac- teristics and directed topological networks,”ISA Transactions, vol. 138, pp. 311–317, 2023
work page 2023
-
[3]
Distributed Q-learning for dynamically decoupled systems,
S. Alemzadeh and M. Mesbahi, “Distributed Q-learning for dynamically decoupled systems,” inAmerican Control Conference (ACC), pp. 772– 777, IEEE, 2019
work page 2019
-
[4]
Distributed Q-Learning with state tracking for multi-agent networked control,
H. Wang, S. Lin, H. Jafarkhani, and J. Zhang, “Distributed Q-Learning with state tracking for multi-agent networked control,” inProceedings of the 20th International Conference on Autonomous Agents and MultiA- gent Systems, AAMAS ’21, (Richland, SC), p. 1692–1694, International Foundation for Autonomous Agents and Multiagent Systems, 2021
work page 2021
-
[5]
Distributed control design for spa- tially interconnected systems,
R. D’Andrea and G. E. Dullerud, “Distributed control design for spa- tially interconnected systems,”IEEE Transactions on Automatic Control, vol. 48, no. 9, pp. 1478–1495, 2003
work page 2003
-
[6]
Distributed control for identical dynam- ically coupled systems: A decomposition approach,
P. Massioni and M. Verhaegen, “Distributed control for identical dynam- ically coupled systems: A decomposition approach,”IEEE Transactions on Automatic Control, vol. 54, no. 1, pp. 124–135, 2009
work page 2009
-
[7]
Distributed control of linear parameter-varying decomposable systems,
C. Hoffmann, A. Eichler, and H. Werner, “Distributed control of linear parameter-varying decomposable systems,” inAmerican Control Conference, pp. 2380–2385, IEEE, 2013
work page 2013
-
[8]
Stability and optimality of distributed model predictive control,
A. N. Venkat, J. B. Rawlings, and S. J. Wright, “Stability and optimality of distributed model predictive control,” inProceedings of the IEEE Conference on Decision and Control, pp. 6680–6685, IEEE, 2005
work page 2005
-
[9]
Distributed receding horizon control of dynamically coupled nonlinear systems,
W. B. Dunbar, “Distributed receding horizon control of dynamically coupled nonlinear systems,”IEEE Transactions on Automatic Control, vol. 52, no. 7, pp. 1249–1263, 2007
work page 2007
-
[10]
Fully distributed adaptive consensus control of multi-agent systems with LQR performance index,
Z. Li and Z. Ding, “Fully distributed adaptive consensus control of multi-agent systems with LQR performance index,” in2015 54th IEEE Conference on Decision and Control (CDC), pp. 386–391, IEEE, 2015
work page 2015
-
[11]
Regret analysis of distributed online LQR control for unknown LTI systems,
T.-J. Chang and S. Shahrampour, “Regret analysis of distributed online LQR control for unknown LTI systems,”IEEE Transactions on Auto- matic Control, vol. 69, no. 1, pp. 667–673, 2023
work page 2023
-
[12]
Distributed LQR design for identical dy- namically decoupled systems,
F. Borrelli and T. Keviczky, “Distributed LQR design for identical dy- namically decoupled systems,”IEEE Transactions on Automatic Control, vol. 53, no. 8, pp. 1901–1912, 2008
work page 1901
-
[13]
E. E. Vlahakis, L. D. Dritsas, and G. D. Halikias, “Distributed LQR design for identical dynamically coupled systems: Application to load frequency control of multi-area power grid,” in2019 IEEE 58th Con- ference on Decision and Control (CDC), pp. 4471–4476, IEEE, 2019
work page 2019
-
[14]
Distributed optimal control of multiple systems,
W. Dong, “Distributed optimal control of multiple systems,”Interna- tional Journal of Control, vol. 83, no. 10, pp. 2067–2079, 2010
work page 2067
-
[15]
C. J. Watkins and P. Dayan, “Q-learning,”Machine learning, vol. 8, pp. 279–292, 1992
work page 1992
-
[16]
V . Narayanan and S. Jagannathan, “Distributed adaptive optimal regu- lation of uncertain large-scale interconnected systems using hybrid Q- learning approach,”IET Control Theory & Applications, vol. 10, no. 12, pp. 1448–1457, 2016
work page 2016
-
[17]
Sparse wide-area control of power systems using data-driven reinforcement learning,
A. F. Dizche, A. Chakrabortty, and A. Duel-Hallen, “Sparse wide-area control of power systems using data-driven reinforcement learning,” in 2019 American Control Conference (ACC), pp. 2867–2872, IEEE, 2019
work page 2019
-
[18]
Fully decentralized multi-agent reinforcement learning with networked agents,
K. Zhang, Z. Yang, H. Liu, T. Zhang, and T. Basar, “Fully decentralized multi-agent reinforcement learning with networked agents,” inInterna- tional Conference on Machine Learning, pp. 5872–5881, PMLR, 2018
work page 2018
-
[19]
Distributed off-policy actor-critic reinforcement learning with policy consensus,
Y . Zhang and M. M. Zavlanos, “Distributed off-policy actor-critic reinforcement learning with policy consensus,” inIEEE Conference on Decision and Control, pp. 4674–4679, IEEE, 2019
work page 2019
-
[20]
Efficient and scalable reinforcement learning for large-scale network control,
C. Ma, A. Li, Y . Du, H. Dong, and Y . Yang, “Efficient and scalable reinforcement learning for large-scale network control,”Nature Machine Intelligence, vol. 6, no. 9, pp. 1006–1020, 2024
work page 2024
-
[21]
Policy evaluation in decentralized POMDPS with belief sharing,
M. Kayaalp, F. Ghadieh, and A. H. Sayed, “Policy evaluation in decentralized POMDPS with belief sharing,”IEEE Open Journal of Control Systems, vol. 2, pp. 125–145, 2023
work page 2023
-
[22]
Information state embedding in partially observable cooperative multi-agent reinforcement learning,
W. Mao, K. Zhang, E. Miehling, and T. Bas ¸ar, “Information state embedding in partially observable cooperative multi-agent reinforcement learning,” in2020 59th IEEE Conference on Decision and Control (CDC), pp. 6124–6131, 2020
work page 2020
-
[23]
Neural recursive belief states in multi-agent reinforcement learning,
P. Moreno, E. Hughes, K. R. McKee, B. A. Pires, and T. Weber, “Neural recursive belief states in multi-agent reinforcement learning,”
- [24]
-
[25]
Adaptive optimal control for a class of nonlinear systems: The online policy iteration approach,
S. He, H. Fang, M. Zhang, F. Liu, and Z. Ding, “Adaptive optimal control for a class of nonlinear systems: The online policy iteration approach,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 2, pp. 549–558, 2019
work page 2019
-
[26]
Distributed average consensus with dithered quantization,
T. C. Aysal, M. J. Coates, and M. G. Rabbat, “Distributed average consensus with dithered quantization,”IEEE Transactions on Signal Processing, vol. 56, no. 10, pp. 4905–4918, 2008
work page 2008
-
[27]
S. Kar and J. M. Moura, “Distributed consensus algorithms in sensor networks with imperfect communication: Link failures and channel noise,”IEEE Transactions on Signal Processing, vol. 57, no. 1, pp. 355– 369, 2008
work page 2008
-
[28]
Network-based consensus av- eraging with general noisy channels,
R. Rajagopal and M. J. Wainwright, “Network-based consensus av- eraging with general noisy channels,”IEEE Transactions on Signal Processing, vol. 59, no. 1, pp. 373–385, 2010
work page 2010
-
[29]
Consensus- based distributed connectivity control in multi-agent systems,
K. Griparic, M. Polic, M. Krizmancic, and S. Bogdan, “Consensus- based distributed connectivity control in multi-agent systems,”IEEE Transactions on Network Science and Engineering, vol. 9, no. 3, pp. 1264–1281, 2022
work page 2022
-
[30]
Quantized and asynchronous federated learning,
T. Ortega and H. Jafarkhani, “Quantized and asynchronous federated learning,”IEEE Transactions on Communications, vol. 73, no. 4, pp. 2361–2374, 2024
work page 2024
-
[31]
Decentralized optimization in networks with arbitrary delays,
T. Ortega and H. Jafarkhani, “Decentralized optimization in networks with arbitrary delays,” inICC 2024-IEEE International Conference on Communications, pp. 794–799, IEEE, 2024
work page 2024
-
[32]
Distributed and quantized online multi-kernel learning,
Y . Shen, S. Karimi-Bidhendi, and H. Jafarkhani, “Distributed and quantized online multi-kernel learning,”IEEE Transactions on Signal Processing, vol. 69, pp. 5496–5511, 2021
work page 2021
-
[33]
Multi-UA V energy- efficient wildfire coverage optimization,
C. Diaz-Vilor, M. Barzegaran, and H. Jafarkhani, “Multi-UA V energy- efficient wildfire coverage optimization,”IEEE Transactions on Wireless Communications, 2025
work page 2025
-
[34]
M. Barzegaran and H. Jafarkhani, “Dynamic deployment of hetero- geneous wireless sensor drone networks with limited communication range,”IEEE Transactions on V ehicular Technology, 2025
work page 2025
-
[35]
T.-Y . Tung, S. Kobus, J. P. Roig, and D. G ¨und¨uz, “Effective communi- cations: A joint learning and communication framework for multi-agent reinforcement learning over noisy channels,”IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2590–2603, 2021
work page 2021
-
[36]
Y . Yang, Q. Liu, H. Tan, Z. Shen, and D. Wu, “Collision-free and connectivity-preserving formation control of nonlinear multi-agent sys- tems with external disturbances,”IEEE Transactions on V ehicular Tech- nology, vol. 72, no. 8, pp. 9956–9968, 2023
work page 2023
-
[37]
Cell-free UA V networks: Asymptotic analysis and deployment optimization,
C. Diaz-Vilor, A. Lozano, and H. Jafarkhani, “Cell-free UA V networks: Asymptotic analysis and deployment optimization,”IEEE Transactions on Wireless Communications, vol. 22, no. 5, pp. 3055–3070, 2023
work page 2023
-
[38]
Cell-free UA V networks with wireless fronthaul: Analysis and optimization,
C. Diaz-Vilor, A. Lozano, and H. Jafarkhani, “Cell-free UA V networks with wireless fronthaul: Analysis and optimization,”IEEE Transactions on Wireless Communications, vol. 23, no. 3, pp. 2054–2069, 2024. 15
work page 2054
-
[39]
Issues in using function approximation for reinforcement learning,
S. Thrun and A. Schwartz, “Issues in using function approximation for reinforcement learning,” inProceedings of the 4th Connectionist Models Summer School, Lawrence Erlbaum Associates, 1993
work page 1993
-
[40]
Shamma,Cooperative control of distributed multi-agent systems
J. Shamma,Cooperative control of distributed multi-agent systems. John Wiley & Sons, 2008
work page 2008
-
[41]
Decentralized control of connec- tivity for multi-agent systems,
M. C. De Gennaro and A. Jadbabaie, “Decentralized control of connec- tivity for multi-agent systems,” inProceedings of the IEEE Conference on Decision and Control, pp. 3628–3633, IEEE, 2006
work page 2006
-
[42]
A survey on model-based distributed control and filtering for industrial cyber-physical systems,
D. Ding, Q.-L. Han, Z. Wang, and X. Ge, “A survey on model-based distributed control and filtering for industrial cyber-physical systems,” IEEE Transactions on Industrial Informatics, vol. 15, no. 5, pp. 2483– 2499, 2019
work page 2019
-
[43]
K. Ogata and Y . Yang,Modern control engineering, vol. 4. Prentice Hall India, 2002
work page 2002
-
[44]
Evaluation of measure- ment data — guide to the expression of uncertainty in measurement (GUM),
International Organization for Standardization, “Evaluation of measure- ment data — guide to the expression of uncertainty in measurement (GUM),” tech. rep., ISO/IEC Guide 98-3, 2008
work page 2008
-
[45]
Worst-case additive noise in wireless networks,
I. Shomorony and A. S. Avestimehr, “Worst-case additive noise in wireless networks,”IEEE Transactions on Information Theory, vol. 59, no. 6, pp. 3833–3847, 2013
work page 2013
-
[46]
O. A. Gbadamosi and D. R. Aremu, “Design of a modified Dijkstra’s algorithm for finding alternate routes for shortest-path problems with huge costs,” in2020 International Conference in Mathematics, Com- puter Engineering and Computer Science (ICMCECS), pp. 1–6, IEEE, 2020
work page 2020
-
[47]
An introduction to the Kalman filter,
G. Bishop, G. Welch,et al., “An introduction to the Kalman filter,”Proc of SIGGRAPH, Course, vol. 8, no. 27599-23175, p. 41, 2001
work page 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.