Recognition: no theorem link
Reinforcement Learning for Tool-Calling Agents in Fast Healthcare Interoperability Resources (FHIR)
Pith reviewed 2026-05-15 04:53 UTC · model grok-4.3
The pith
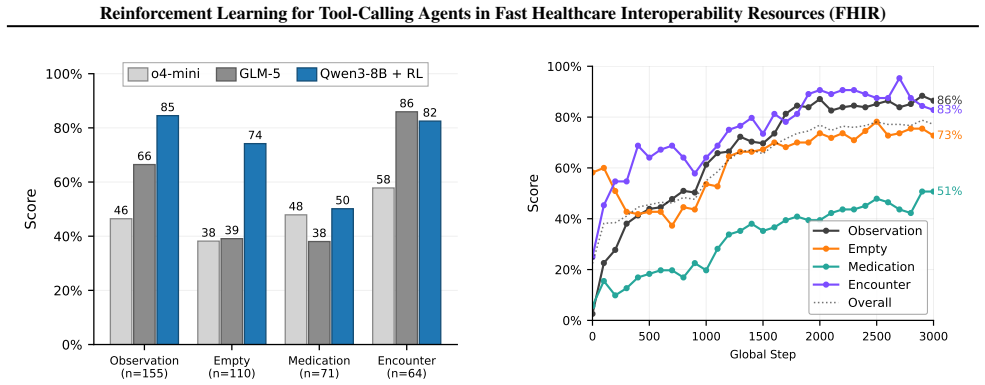
Reinforcement learning post-training raises a Qwen3-8B model to 77 percent correctness on FHIR clinical queries, surpassing larger closed models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By casting FHIR reasoning as sequential decision-making over a queryable structured graph and post-training a multi-turn CodeAct agent with reinforcement learning using execution-grounded rewards from an LLM judge, the authors achieve 77 percent answer correctness on FHIR-AgentBench with a Qwen3-8B model, compared to 50 percent for o4-mini, while maintaining data-integrity constraints.
What carries the argument
The RL post-trained multi-turn CodeAct agent equipped with a custom harness and an LLM judge that supplies execution-grounded rewards for traversals across FHIR resource graphs.
If this is right
- Smaller open-weight models can reach higher accuracy than larger closed models on structured healthcare question-answering tasks.
- Reinforcement learning enforces data-integrity constraints during agent reasoning over clinical graphs.
- An end-to-end post-training pipeline reliably improves multi-turn reasoning on queryable structured data.
- Performance gains arise from reward-driven training rather than prompt engineering alone.
Where Pith is reading between the lines
- The same reinforcement-learning harness could be applied to other graph-structured interoperability standards outside healthcare.
- Lower inference costs from using smaller models could make clinical decision-support tools more accessible in resource-limited settings.
- Varying the judge model or adding human verification steps would test how sensitive the gains are to reward quality.
- Combining this approach with retrieval or planning modules from other agent frameworks might further reduce error rates on complex aggregation queries.
Load-bearing premise
An LLM judge can supply reliable execution-grounded rewards without bias or systematic errors when scoring multi-step FHIR traversals.
What would settle it
Evaluating the trained agent on a fresh held-out portion of FHIR-AgentBench questions with independent ground-truth execution results that show correctness at or below 50 percent.
Figures






read the original abstract
Fast Healthcare Interoperability Resources (FHIR) is the dominant standard for interoperable exchange of healthcare data. In FHIR, electronic health records form a directed graph of resources. Answering clinically meaningful questions over FHIR requires agents to perform multi-step reasoning, filtering, and aggregation across multiple resource types. Prior work shows that even tool-augmented LLM agents (retrieval, code execution, multi-turn planning) often select the wrong resources or violate traversal constraints. We study this problem in the context of FHIR-AgentBench, a benchmark for realistic question answering over real-world hospital data, and frame reasoning on FHIR as a sequential decision-making problem over a queryable structured graph. We implement a multi-turn CodeAct agent and post-train it with reinforcement learning using a custom harness and tools. A LLM Judge provides execution-grounded rewards. Compared to prompt-based, closed-model baselines, RL post-training improves performance while enforcing data-integrity constraints. Empirically, our approach improves answer correctness from 50% (o4-mini) to 77% on FHIR-AgentBench using a smaller and cheaper Qwen3-8B model. We present an end-to-end post-training pipeline (environment building, harness construction, model training and custom evaluation) that reliably improves multi-turn reasoning over structured clinical graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an end-to-end pipeline for post-training a Qwen3-8B model using reinforcement learning for multi-turn tool-calling agents in FHIR data querying. Framing the problem as sequential decision-making over a structured graph, they employ a CodeAct agent and an LLM Judge to provide execution-grounded rewards, reporting an improvement in answer correctness from 50% (o4-mini baseline) to 77% on the FHIR-AgentBench benchmark.
Significance. If the results are robust, this work would be significant for demonstrating that RL can enhance smaller open models to outperform larger proprietary ones on complex, constraint-heavy reasoning tasks in healthcare interoperability. It provides a practical pipeline for building reliable agents over clinical data graphs, potentially reducing costs and improving accessibility while enforcing data integrity.
major comments (2)
- [Reward Design] The central empirical claim (50% to 77% correctness) depends on the LLM Judge supplying reliable rewards for multi-step FHIR traversals. However, the manuscript provides no calibration data, human agreement metrics, or ablation studies on the judge's prompting or consistency, making it impossible to rule out systematic biases as the source of the performance lift rather than the RL training itself.
- [Experimental Setup] The abstract reports a clear numerical gain but the full methods lack details on training curves, reward shaping specifics, baseline implementations, statistical significance testing, or error analysis, which are necessary to assess the robustness of the 27-point improvement.
minor comments (1)
- [Methods] Clarify the exact definition of the CodeAct agent and how it interfaces with the FHIR environment in the methods section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below and indicate the revisions planned for the next version.
read point-by-point responses
-
Referee: [Reward Design] The central empirical claim (50% to 77% correctness) depends on the LLM Judge supplying reliable rewards for multi-step FHIR traversals. However, the manuscript provides no calibration data, human agreement metrics, or ablation studies on the judge's prompting or consistency, making it impossible to rule out systematic biases as the source of the performance lift rather than the RL training itself.
Authors: We agree that explicit validation of the LLM Judge is required to support the central claim. In the revised manuscript we will add a dedicated subsection reporting calibration results: human-expert agreement on a random sample of 150 multi-turn trajectories (Cohen's kappa and raw agreement), plus ablations on judge prompt phrasing and temperature. These data will be placed in the main text with full details in the appendix. We note that rewards remain execution-grounded (FHIR query success and constraint violations are verified by the environment), which limits the scope for judge-induced bias, but the requested metrics will allow readers to quantify any residual judge variance. revision: yes
-
Referee: [Experimental Setup] The abstract reports a clear numerical gain but the full methods lack details on training curves, reward shaping specifics, baseline implementations, statistical significance testing, or error analysis, which are necessary to assess the robustness of the 27-point improvement.
Authors: We accept that the current Methods section is insufficiently detailed for reproducibility and robustness assessment. The revision will expand this section to include: (i) training curves for both reward and correctness metrics across epochs, (ii) the exact reward-shaping formula with component weights, (iii) verbatim prompt templates and tool configurations used for the o4-mini baseline, (iv) statistical significance results (bootstrap 95% CI and McNemar test on paired outcomes), and (v) a categorized error analysis of the remaining 23% failures. These additions will be integrated into the main paper and will directly address concerns about the reported 27-point gain. revision: yes
Circularity Check
No significant circularity; empirical result rests on external benchmark
full rationale
The paper frames FHIR reasoning as a sequential decision problem and reports an empirical performance lift (50% to 77% on FHIR-AgentBench) obtained by RL post-training of Qwen3-8B with rewards supplied by an LLM judge. No equations, derivations, or parameter-fitting steps are described that would reduce the reported correctness metric to the inputs by construction. The central claim depends on an external benchmark and the unvalidated assumption that the LLM judge supplies reliable execution-grounded rewards; this is an empirical assumption rather than a self-referential definition or a prediction forced by fitted parameters. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way. The derivation chain is therefore self-contained as a standard RL experiment on a public benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM Judge supplies execution-grounded rewards that correlate with true answer correctness
Reference graph
Works this paper leans on
-
[1]
Journal of the American Medical Informatics Association , author =
Electronic health record adoption in. Journal of the American Medical Informatics Association , author =. 2017 , pages =. doi:10.1093/jamia/ocx080 , abstract =
-
[2]
Challenges in and. Gut and Liver , author =. 2024 , pmid =. doi:10.5009/gnl230272 , abstract =
-
[3]
AMA journal of ethics , author =
Language,. AMA journal of ethics , author =. 2017 , pmid =. doi:10.1001/journalofethics.2017.19.3.stas1-1703 , abstract =
work page doi:10.1001/journalofethics.2017.19.3.stas1-1703 2017
-
[4]
WIREs Computational Statistics , author =
Challenges and opportunities beyond structured data in analysis of electronic health records , volume =. WIREs Computational Statistics , author =. 2021 , note =. doi:10.1002/wics.1549 , abstract =
-
[5]
The application of large language models in medicine:. iScience , author =. 2024 , pmid =. doi:10.1016/j.isci.2024.109713 , abstract =
-
[6]
NEJM AI , author =. 2024 , pmid =. doi:10.1056/aics2300301 , abstract =
-
[7]
Conference on Empirical Methods in Natural Language Processing , author =
Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing , author =. 2024 , pmid =. doi:10.18653/v1/2024.emnlp-main.1245 , abstract =
-
[8]
DeepSeek-AI and Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bocha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948
-
[9]
BMC Medical Research Methodology , author =
External validation of a. BMC Medical Research Methodology , author =. 2013 , keywords =. doi:10.1186/1471-2288-13-33 , abstract =
-
[10]
and Lemeshow, Stanley and May, Susanne , month = feb, year =
Hosmer, David W. and Lemeshow, Stanley and May, Susanne , month = feb, year =. Applied
-
[11]
BMC Medical Research Methodology , author =
Survival prediction models: an introduction to discrete-time modeling , volume =. BMC Medical Research Methodology , author =. 2022 , keywords =. doi:10.1186/s12874-022-01679-6 , abstract =
-
[12]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2005
-
[13]
Müller, Robert , month = jul, year =. Semantic. doi:10.48550/arXiv.2507.10820 , abstract =
-
[14]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Feng, Jiazhan and Huang, Shijue and Qu, Xingwei and Zhang, Ge and Qin, Yujia and Zhong, Baoquan and Jiang, Chengquan and Chi, Jinxin and Zhong, Wanjun , month = apr, year =. doi:10.48550/arXiv.2504.11536 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.11536
-
[15]
Singh, Joykirat and Magazine, Raghav and Pandya, Yash and Nambi, Akshay , month = apr, year =. Agentic. doi:10.48550/arXiv.2505.01441 , abstract =
-
[16]
Nemotron-research-tool-n1: Exploring tool-using language models with reinforced reasoning
Zhang, Shaokun and Dong, Yi and Zhang, Jieyu and Kautz, Jan and Catanzaro, Bryan and Tao, Andrew and Wu, Qingyun and Yu, Zhiding and Liu, Guilin , month = may, year =. Nemotron-. doi:10.48550/arXiv.2505.00024 , abstract =
-
[17]
ToolRL: Reward is All Tool Learning Needs
Qian, Cheng and Acikgoz, Emre Can and He, Qi and Wang, Hongru and Chen, Xiusi and Hakkani-Tür, Dilek and Tur, Gokhan and Ji, Heng , month = apr, year =. doi:10.48550/arXiv.2504.13958 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13958
- [18]
-
[19]
Understanding R1-Zero-Like Training: A Critical Perspective
Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , month = mar, year =. Understanding. doi:10.48550/arXiv.2503.20783 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.20783
-
[20]
BMC Medical Research Methodology , author =. 2018 , keywords =. doi:10.1186/s12874-018-0482-1 , abstract =
-
[21]
Evaluating the yield of medical tests , volume =. JAMA , author =. 1982 , pmid =
work page 1982
-
[22]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun and Liu, Xin and Lin, Haibin and Lin, Zhiqi and Ma, Bole and Sheng, Guangming and Tong, Yuxuan and Zhang, Chi and Zhang, Mofan and Zhang, Wang and Zhu, Hang and Zhu, Jinhua and Chen, Jiaze and Chen,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476
-
[23]
GitHub repository , howpublished =
Brad Hilton and Kyle Corbitt and David Corbitt and Saumya Gandhi and Angky William and Bohdan Kovalenskyi and Andie Jones , title =. GitHub repository , howpublished =. 2025 , publisher =
work page 2025
- [24]
- [25]
-
[26]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs , author=. 2025 , eprint=
work page 2025
-
[27]
Nemotron-Research-Tool-N1: Exploring Tool-Using Language Models with Reinforced Reasoning , author=. 2025 , eprint=
work page 2025
-
[28]
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[29]
APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay , author=. 2025 , eprint=
work page 2025
- [30]
- [31]
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[33]
MedAlpaca -- An Open-Source Collection of Medical Conversational AI Models and Training Data , author=. 2025 , eprint=
work page 2025
-
[34]
SkyRL-SQL: Matching GPT-4o and o4-mini on Text2SQL with Multi-Turn RL , author=. 2025 , note=
work page 2025
-
[35]
2025 , month = jun, howpublished =
Evolving SkyRL into a Highly-Modular RL Framework , author =. 2025 , month = jun, howpublished =
work page 2025
-
[36]
Executable Code Actions Elicit Better LLM Agents , author=. 2024 , eprint=
work page 2024
-
[37]
International Conference on Learning Representations (ICLR) , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[38]
PAL: Program-aided Language Models
PAL: Program-aided Language Models , author=. arXiv preprint arXiv:2211.10435 , year=
work page internal anchor Pith review arXiv
-
[39]
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author=. arXiv preprint arXiv:2211.12588 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
The Art of Scaling Reinforcement Learning Compute for LLMs , author=. 2025 , eprint=
work page 2025
-
[41]
TRL GRPO Trainer Documentation , author=
- [42]
-
[43]
arXiv preprint arXiv:2506.10446 , year=
Efficient Reasoning via Powered Length Penalty , author=. arXiv preprint arXiv:2506.10446 , year=
-
[44]
DLER: Doing Length pEnalty Right - Incentivizing More Intelligence per Token via Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[45]
2019 , month = oct, day =
work page 2019
-
[46]
The Heat is On: US Caught FHIR in 2019 , howpublished =
work page 2019
-
[47]
FHIR-AgentBench: Benchmarking LLM Agents for Realistic Interoperable EHR Question Answering , author=. 2025 , eprint=
work page 2025
-
[48]
Large Language Models for Automating Clinical Data Standardization: HL7 FHIR Use Case , author=. 2025 , eprint=
work page 2025
-
[49]
Journal of Medical Internet Research , author =
Using a. Journal of Medical Internet Research , author =. 2025 , pmid =. doi:10.2196/73540 , abstract =
- [50]
-
[51]
Question Answering on Patient Medical Records with Private Fine-Tuned LLMs , author=. 2025 , eprint=
work page 2025
-
[52]
MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents , author=. 2025 , eprint=
work page 2025
- [53]
- [54]
-
[55]
Patil, Shishir G. and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle =. The. 2025 , url =
work page 2025
-
[56]
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models , author =. 2024 , eprint =
work page 2024
-
[57]
Butterfly Effects in Toolchains: Categorizing and Analyzing Failures in Parameter Filling for LLMs , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2025
-
[58]
Lost in Execution: On the Multilingual Robustness of Tool Calling in Large Language Models , author =. 2026 , eprint =
work page 2026
-
[59]
Tool-Augmented Policy Optimization: Synergizing Reasoning and Adaptive Tool Use with Reinforcement Learning , author =. 2025 , eprint =
work page 2025
-
[60]
Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors , author =. 2026 , eprint =
work page 2026
-
[61]
ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration , author =. 2025 , eprint =
work page 2025
-
[62]
ToolGate: Contract-Grounded and Verified Tool Execution for LLMs , author =. 2026 , eprint =
work page 2026
-
[63]
From Failure to Mastery: Generating Hard Samples for Tool-use Agents , author =. 2026 , eprint =
work page 2026
-
[64]
Trajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents , author =. 2026 , eprint =
work page 2026
-
[65]
Emerging from Ground: Addressing Intent Deviation in Tool-Using Agents via Deriving Real Calls into Virtual Trajectories , author =. 2026 , eprint =
work page 2026
-
[66]
AMIA Annual Symposium Proceedings , author =
Reducing. AMIA Annual Symposium Proceedings , author =. 2023 , pmid =
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.