Recognition: 2 theorem links
· Lean TheoremSafety-Constrained Reinforcement Learning with Post-Training Reachability Verification for Robot Navigation
Pith reviewed 2026-05-15 04:50 UTC · model grok-4.3
The pith
CVaR-constrained training produces robot navigation policies with larger obstacle margins that formal reachability verification confirms at higher rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimizing policies under CVaR constraints on cumulative costs yields reachable action sets that remain within safety margins for a larger share of evaluated states under bounded observation uncertainty, producing higher safety verification rates than policies trained with average-cost objectives.
What carries the argument
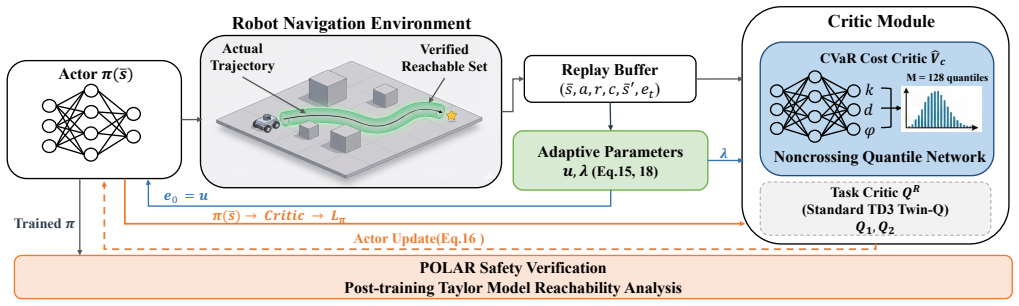
CVaR-constrained optimization on a TD3 backbone, followed by Taylor Model reachability analysis that computes the proportion of states whose reachable actions stay inside safety margins.
Load-bearing premise
Bounded observation uncertainty can be modeled accurately and Taylor Model analysis produces reachable sets tight enough to yield a meaningful safety-rate metric.
What would settle it
Finding a CVaR-trained policy whose reachable action sets violate safety margins at a lower rate than an average-cost baseline, under the same bounded uncertainty model, would falsify the central claim.
Figures


read the original abstract
Safe navigation for mobile robots demands policies that remain reliable under the high-consequence perception uncertainty of cluttered environments. Yet most existing safe reinforcement learning (RL) methods assess safety through average cumulative cost. Such metrics can mask dangerous tail-risk behaviors. To address this, we propose a framework that trains risk-sensitive policies through Conditional Value-at-Risk (CVaR) constrained optimization on an off-policy TD3 backbone and evaluates their safety margins post-training through neural network reachability verification. During training, the policy is optimized under CVaR constraints on cumulative costs, promoting sensitivity to high-cost tail outcomes rather than average behavior alone. After training, we compute action reachable sets under bounded observation uncertainty using Taylor Model analysis, yielding a safety rate metric that quantifies the proportion of evaluated states at which the policy's reachable action set remains within prescribed safety margins. A key finding is that policies trained with CVaR constraints maintain larger safety margins from obstacles across evaluated states. This makes them significantly more amenable to formal reachability verification. Experiments across ten navigation scenarios and six baselines show that our method achieves a 98.3\% success rate, the highest safety verification rate among all compared methods, while revealing that average cost rankings and reachability-based safety rankings can diverge. This indicates that reachability verification captures risks which are missed by empirical cost metrics alone. We further validate our approach on a physical Clearpath Jackal robot, demonstrating successful sim-to-real transfer.
Editorial analysis
A structured set of objections, weighed in public.
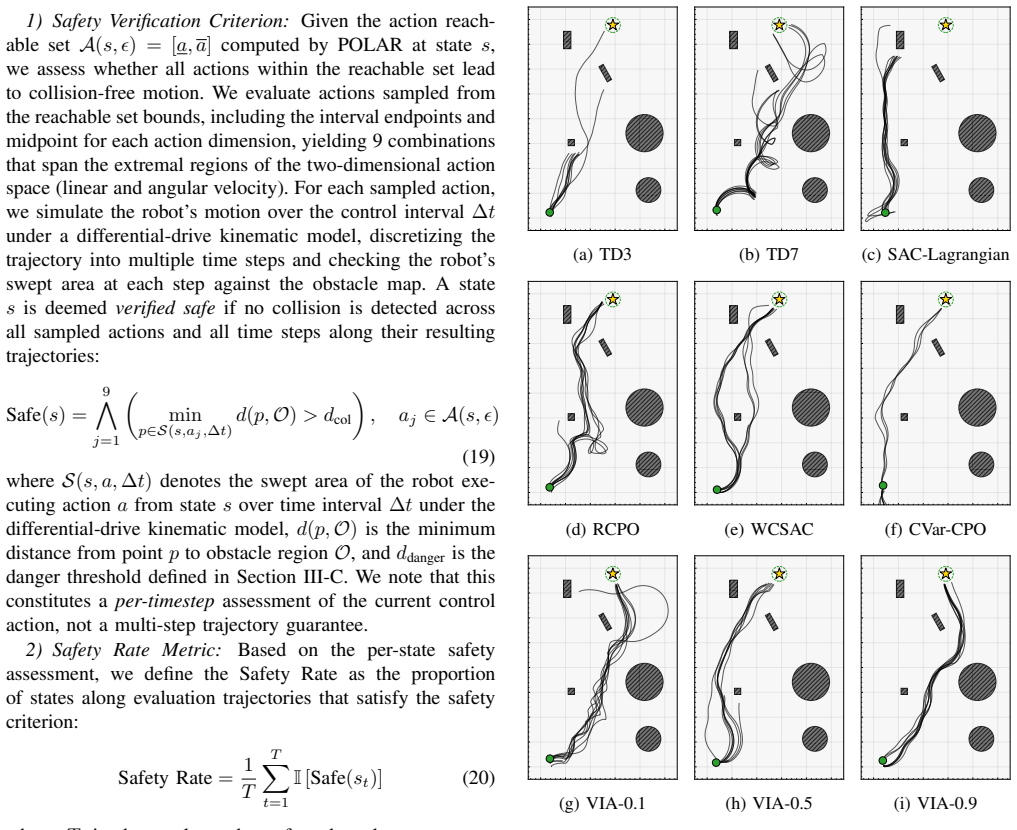
Referee Report
Summary. The paper proposes training risk-sensitive navigation policies for mobile robots via CVaR-constrained optimization on an off-policy TD3 backbone, then evaluating safety post-training by computing reachable action sets under bounded observation uncertainty using Taylor Model analysis. The central claims are that CVaR policies produce larger safety margins from obstacles (hence higher safety verification rates) than average-cost baselines, that average-cost and reachability rankings diverge, that the method achieves 98.3% success rate and the highest safety verification rate across ten scenarios and six baselines, and that the approach transfers successfully to a physical Clearpath Jackal robot.
Significance. If the tightness of the Taylor Model reachable sets can be established, the work would be significant for safe RL in robotics: it directly addresses the limitation of average-cost metrics in masking tail-risk behaviors, supplies a post-training formal verification step that is independent of the training objective, and demonstrates sim-to-real transfer. The explicit separation of CVaR training from reachability-based safety rate computation is a useful methodological contribution.
major comments (2)
- [Reachability verification and Experiments] The central claim that CVaR policies maintain meaningfully larger safety margins (and are therefore more amenable to formal verification) depends on the Taylor Model reachable sets being sufficiently tight that observed differences reflect policy behavior rather than differential looseness of the over-approximation. No quantitative tightness metrics (Hausdorff distance to sampled trajectories, comparison against interval arithmetic, or remainder bounds) are reported in the reachability or experiments sections, leaving open the possibility that CVaR-induced dynamics simply produce smaller Taylor remainders.
- [Experiments] The reported 98.3% success rate and highest safety verification rate lack accompanying details on the precise baselines, the exact bounded-observation uncertainty model used in the Taylor analysis, the number of evaluated states per scenario, and statistical uncertainty (e.g., confidence intervals or variance across runs). These omissions make it impossible to assess whether the claimed superiority over average-cost methods is robust.
minor comments (1)
- [Abstract / Results] The abstract states that average-cost and reachability rankings diverge but does not quantify the divergence (e.g., rank correlation or specific policy pairs that invert). Adding a small table or sentence in the results section would strengthen the point.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our reachability verification results and experimental details. We address each major comment below and have incorporated revisions to provide the requested quantitative metrics and clarifications.
read point-by-point responses
-
Referee: [Reachability verification and Experiments] The central claim that CVaR policies maintain meaningfully larger safety margins (and are therefore more amenable to formal verification) depends on the Taylor Model reachable sets being sufficiently tight that observed differences reflect policy behavior rather than differential looseness of the over-approximation. No quantitative tightness metrics (Hausdorff distance to sampled trajectories, comparison against interval arithmetic, or remainder bounds) are reported in the reachability or experiments sections, leaving open the possibility that CVaR-induced dynamics simply produce smaller Taylor remainders.
Authors: We agree that explicit tightness quantification is essential to rule out approximation artifacts. In the revised manuscript we add a dedicated subsection (Section IV-C) reporting two tightness metrics computed on the same state sets used for safety verification: (i) average Hausdorff distance between the Taylor Model reachable action sets and 2000 Monte-Carlo trajectory samples drawn under the identical bounded observation noise, and (ii) a direct comparison of Taylor remainder bounds versus interval-arithmetic bounds for both CVaR and baseline policies. The new results show that the Hausdorff distances are statistically indistinguishable across methods (within 3 % relative difference) and that Taylor remainders are actually slightly larger for the CVaR policies, confirming that the observed safety-margin advantage is attributable to policy behavior rather than differential looseness. revision: yes
-
Referee: [Experiments] The reported 98.3% success rate and highest safety verification rate lack accompanying details on the precise baselines, the exact bounded-observation uncertainty model used in the Taylor analysis, the number of evaluated states per scenario, and statistical uncertainty (e.g., confidence intervals or variance across runs). These omissions make it impossible to assess whether the claimed superiority over average-cost methods is robust.
Authors: We appreciate the request for reproducibility details. The revised experimental section now contains: (1) an explicit table listing all six baselines together with their exact hyperparameters and training seeds; (2) the precise bounded-observation uncertainty model (additive uniform noise with per-sensor bounds taken from the Clearpath Jackal datasheet); (3) the evaluation protocol (1000 states uniformly sampled per scenario, 10 scenarios total); and (4) statistical reporting of success rate, safety verification rate, and safety margin with 95 % confidence intervals computed over 10 independent training runs. The 98.3 % figure is now accompanied by its standard deviation (1.2 %) and the corresponding interval. These additions allow direct verification of robustness. revision: yes
Circularity Check
No significant circularity; post-training verification remains independent of training inputs
full rationale
The paper separates CVaR-constrained policy optimization during training from post-training safety-rate computation via Taylor Model reachability analysis. The safety rate quantifies the proportion of states where reachable action sets stay within margins, evaluated empirically across policies without any equation that reduces this metric to the CVaR parameters or fitted costs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the described derivation chain. The key finding (larger margins for CVaR policies) emerges from comparative evaluation rather than definitional equivalence, consistent with the reader's assessment of independent computation.
Axiom & Free-Parameter Ledger
free parameters (1)
- CVaR alpha level
axioms (1)
- domain assumption Observation uncertainty is bounded and can be propagated via Taylor Model analysis to compute action reachable sets
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose VIA... CVaR-constrained optimization on an off-policy TD3 backbone and evaluates their safety margins post-training through neural network reachability verification... using Taylor Model analysis
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A key finding is that policies trained with CVaR constraints maintain larger safety margins from obstacles across evaluated states.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Altman,Constrained Markov decision processes
E. Altman,Constrained Markov decision processes. Routledge, 2021
work page 2021
-
[2]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inInternational conference on machine learning. Pmlr, 2017, pp. 22–31
work page 2017
-
[3]
Reward Constrained Policy Optimization
C. Tessler, D. J. Mankowitz, and S. Mannor, “Reward constrained policy optimization,”arXiv preprint arXiv:1805.11074, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Learning to walk in the real world with minimal human effort,
S. Ha, P. Xu, Z. Tan, S. Levine, and J. Tan, “Learning to walk in the real world with minimal human effort,” inConference on Robot Learning, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:211205073
work page 2020
-
[5]
Benchmarking safe exploration in deep reinforcement learning,
A. Ray, J. Achiam, and D. Amodei, “Benchmarking safe exploration in deep reinforcement learning,”arXiv preprint arXiv:1910.01708, vol. 7, no. 1, p. 2, 2019
-
[6]
Optimization of conditional value- at-risk,
R. T. Rockafellar and S. Uryasev, “Optimization of conditional value- at-risk,”Journal of risk, vol. 2, pp. 21–42, 2000
work page 2000
-
[7]
Risk-sensitive and robust decision-making: a cvar optimization approach,
Y . Chow, A. Tamar, S. Mannor, and M. Pavone, “Risk-sensitive and robust decision-making: a cvar optimization approach,”Advances in neural information processing systems, vol. 28, 2015
work page 2015
-
[8]
Wcsac: Worst-case soft actor critic for safety-constrained reinforcement learn- ing,
Q. Yang, T. D. Sim ˜ao, S. H. Tindemans, and M. T. Spaan, “Wcsac: Worst-case soft actor critic for safety-constrained reinforcement learn- ing,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 10 639–10 646
work page 2021
-
[9]
Trc: Trust region conditional value at risk for safe reinforcement learning,
D. Kim and S. Oh, “Trc: Trust region conditional value at risk for safe reinforcement learning,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2621–2628, 2022
work page 2022
-
[10]
Cvar-constrained policy optimization for safe reinforcement learning,
Q. Zhang, S. Leng, X. Ma, Q. Liu, X. Wang, B. Liang, Y . Liu, and J. Yang, “Cvar-constrained policy optimization for safe reinforcement learning,”IEEE transactions on neural networks and learning systems, vol. 36, no. 1, pp. 830–841, 2024
work page 2024
-
[11]
Control barrier function based quadratic programs for safety critical systems,
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,”IEEE Transactions on Automatic Control, vol. 62, no. 8, pp. 3861–3876, 2016
work page 2016
-
[12]
Hamilton-jacobi reachability: A brief overview and recent advances,
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” in2017 IEEE 56th annual conference on decision and control (CDC). IEEE, 2017, pp. 2242–2253
work page 2017
-
[13]
Safe reinforcement learning via shielding,
M. Alshiekh, R. Bloem, R. Ehlers, B. K ¨onighofer, S. Niekum, and U. Topcu, “Safe reinforcement learning via shielding,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
work page 2018
-
[14]
Polar: A poly- nomial arithmetic framework for verifying neural-network controlled systems,
C. Huang, J. Fan, X. Chen, W. Li, and Q. Zhu, “Polar: A poly- nomial arithmetic framework for verifying neural-network controlled systems,” inInternational Symposium on Automated Technology for Verification and Analysis. Springer, 2022, pp. 414–430
work page 2022
-
[15]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
work page 2018
-
[16]
Projection-based constrained policy optimization,
T.-Y . Yang, J. Rosca, K. Narasimhan, and P. J. Ramadge, “Projection-based constrained policy optimization,”arXiv preprint arXiv:2010.03152, 2020
-
[17]
First order constrained optimiza- tion in policy space,
Y . Zhang, Q. Vuong, and K. Ross, “First order constrained optimiza- tion in policy space,”Advances in Neural Information Processing Systems, vol. 33, pp. 15 338–15 349, 2020
work page 2020
-
[18]
Risk- constrained reinforcement learning with percentile risk criteria,
Y . Chow, M. Ghavamzadeh, L. Janson, and M. Pavone, “Risk- constrained reinforcement learning with percentile risk criteria,”Jour- nal of Machine Learning Research, vol. 18, no. 167, pp. 1–51, 2018
work page 2018
-
[19]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
work page 2018
-
[20]
H. Rahimian and S. Mehrotra, “Distributionally robust optimization: A review,”arXiv preprint arXiv:1908.05659, 2019
-
[21]
G. N. Iyengar, “Robust dynamic programming,”Mathematics of Op- erations Research, vol. 30, no. 2, pp. 257–280, 2005
work page 2005
-
[22]
Safe learning in robotics: From learning-based control to safe reinforcement learning,
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, no. 1, pp. 411–444, 2022
work page 2022
-
[23]
Sherlock-a tool for verification of neural network feedback systems: demo abstract,
S. Dutta, X. Chen, S. Jha, S. Sankaranarayanan, and A. Tiwari, “Sherlock-a tool for verification of neural network feedback systems: demo abstract,” inProceedings of the 22nd ACM International Con- ference on Hybrid Systems: Computation and Control, 2019, pp. 262– 263
work page 2019
-
[24]
Verisig: verifying safety properties of hybrid systems with neural network controllers,
R. Ivanov, J. Weimer, R. Alur, G. J. Pappas, and I. Lee, “Verisig: verifying safety properties of hybrid systems with neural network controllers,” inProceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, 2019, pp. 169–178
work page 2019
-
[25]
Verisig 2.0: Verification of neural network controllers using taylor model preconditioning,
R. Ivanov, T. Carpenter, J. Weimer, R. Alur, G. Pappas, and I. Lee, “Verisig 2.0: Verification of neural network controllers using taylor model preconditioning,” inInternational Conference on Computer Aided Verification. Springer, 2021, pp. 249–262
work page 2021
-
[26]
Reachnn: Reachability analysis of neural-network controlled systems,
C. Huang, J. Fan, W. Li, X. Chen, and Q. Zhu, “Reachnn: Reachability analysis of neural-network controlled systems,”ACM Transactions on Embedded Computing Systems (TECS), vol. 18, no. 5s, pp. 1–22, 2019
work page 2019
-
[27]
Safety gymnasium: A unified safe reinforcement learning benchmark,
J. Ji, B. Zhang, J. Zhou, X. Pan, W. Huang, R. Sun, Y . Geng, Y . Zhong, J. Dai, and Y . Yang, “Safety gymnasium: A unified safe reinforcement learning benchmark,”Advances in Neural Information Processing Systems, vol. 36, pp. 18 964–18 993, 2023
work page 2023
-
[28]
Non-crossing quantile regression for distributional reinforcement learning,
F. Zhou, J. Wang, and X. Feng, “Non-crossing quantile regression for distributional reinforcement learning,”Advances in neural information processing systems, vol. 33, pp. 15 909–15 919, 2020
work page 2020
-
[29]
Distributional reinforcement learning with quantile regression,
W. Dabney, M. Rowland, M. Bellemare, and R. Munos, “Distributional reinforcement learning with quantile regression,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
work page 2018
-
[30]
Goal-driven autonomous exploration through deep reinforcement learning,
R. Cimurs, I. H. Suh, and J. H. Lee, “Goal-driven autonomous exploration through deep reinforcement learning,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 730–737, 2021
work page 2021
-
[31]
For sale: State-action representation learning for deep reinforcement learning,
S. Fujimoto, W.-D. Chang, E. Smith, S. S. Gu, D. Precup, and D. Meger, “For sale: State-action representation learning for deep reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 61 573–61 624, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.