Recognition: 2 theorem links
· Lean TheoremGrounded Continuation: A Linear-Time Runtime Verifier for LLM Conversations
Pith reviewed 2026-05-15 04:43 UTC · model grok-4.3
The pith
A runtime verifier builds a dependency graph from eight formal update operations to keep LLM continuations grounded on active premises.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
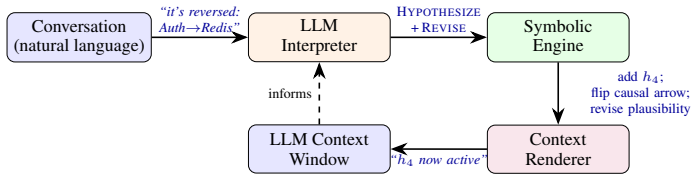
The verifier maintains an explicit dependency graph by having an LLM classify each turn into one of eight update operations, then uses a symbolic engine to perform support checks and retraction propagation as graph walks, delivering linear per-turn cost, a conflict-free guarantee, 89.7 percent accuracy on LongMemEval-KU, and 100 percent accuracy on the 15-item stale-premise subset.
What carries the argument
The dependency graph updated by eight formal operations (from dynamic epistemic logic, abductive reasoning, awareness logic, and argumentation) whose classification by the LLM enables sound graph-walk checks for continuation support and precise retraction propagation.
If this is right
- The structural soundness of the graph check is guaranteed by construction regardless of the LLM used for classification.
- Retraction propagation runs in microseconds while full history replay grows linearly with conversation length.
- The verifier produces correct abstentions on cases where pure LLM or retrieval baselines confabulate unsupported answers.
- The same graph mechanism extends to multi-agent scenarios and the 50-item grounding test set.
Where Pith is reading between the lines
- The soundness-faithfulness split lets developers improve only the classifier while keeping the verification engine unchanged.
- The eight-operation set could be expanded with additional logics to cover more kinds of premise change.
- Deployed agents could invoke the verifier after every turn to block context-manipulation attacks before they succeed.
- The linear-cost property makes the approach practical for conversations that grow to thousands of turns.
Load-bearing premise
The LLM can classify each conversation turn into one of the eight update operations with enough faithfulness that the resulting dependency graph accurately reflects which premises remain active.
What would settle it
A conversation sequence containing a clear premise retraction followed by a continuation that still depends on the retracted premise, where the verifier fails to flag the unsupported continuation.
Figures



read the original abstract
In long conversations, an LLM can produce a next utterance that sounds plausible but rests on premises the conversation has already abandoned. Context-manipulation attacks against deployed agents now actively exploit this gap. We close it with a runtime verifier that maintains an explicit dependency graph: an LLM classifies each turn into one of 8 update operations drawn from four formalisms (dynamic epistemic logic, abductive reasoning, awareness logic, argumentation), and a symbolic engine records which claims depend on which evidence. Checking whether a continuation is supported reduces to a graph walk; retraction propagates through the same graph to flag exactly the conclusions that lose support, with linear per-turn cost and a formal conflict-free guarantee. On LongMemEval-KU oracle (n=78), the verifier reaches 89.7% accuracy vs. 88.5% for the LLM-only baseline (+1.3pp) and 87.2% for a transcript-RAG baseline matched on retrieval budget (+2.6pp); wins among disagreements are correct abstentions where the baseline confabulates. On LoCoMo's 60 official QA items the verifier is competitive with retrieval-augmented baselines. Beyond external benchmarks, we construct two multi-agent scenarios and a 50-item grounding test: on the 15-item stale-premise subset, the verifier reaches 100% accuracy vs. 93.3% (+6.7pp). These instantiate a soundness-faithfulness decomposition: the structural check is sound by construction, and per-deployment LLM extraction faithfulness is the empirical question we measure across four LLM families. The retraction check plateaus at microseconds while history-replay grows linearly with conversation length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a runtime verifier for LLM conversations that maintains an explicit dependency graph. An LLM classifies each turn into one of 8 update operations drawn from dynamic epistemic logic, abductive reasoning, awareness logic, and argumentation; a symbolic engine then performs graph walks to check support for continuations and propagate retractions. The approach claims linear per-turn cost, a formal conflict-free guarantee, and improved accuracy over baselines: 89.7% on LongMemEval-KU (n=78) vs. 88.5% LLM-only and 87.2% transcript-RAG, plus 100% on a 15-item stale-premise subset.
Significance. If the LLM classification step proves reliable, the work offers a practical decomposition of soundness (symbolic graph walk by construction) and faithfulness (empirically measured), addressing context-manipulation risks with efficiency gains over history replay. The formal guarantees and linear-time retraction are notable strengths when the graph is accurate.
major comments (2)
- [Evaluation (LongMemEval-KU and grounding test results)] The central empirical results (89.7% on LongMemEval-KU oracle and 100% on the 15-item stale-premise subset) are reported only as end-to-end accuracy. No per-operation precision, recall, or confusion matrix is provided for the LLM's mapping of turns to the 8 update operations. This is load-bearing: systematic misclassification of subtle cases (e.g., abductive inference as epistemic update) would silently corrupt the dependency graph, so the formal conflict-free guarantee no longer certifies groundedness even though the symbolic engine remains correct by construction.
- [Method and §5 (faithfulness measurement)] The soundness-faithfulness decomposition is stated explicitly, yet the manuscript provides no isolated error analysis or adversarial test cases for the classification step itself. Without this, it is impossible to quantify how often the graph encodes incorrect support relations, which directly affects the claim that the verifier reaches high accuracy with formal guarantees.
minor comments (2)
- [§3] A table listing the exact 8 operations with one-sentence definitions and an example turn would improve clarity of the classification prompt.
- [Symbolic engine description] The retraction propagation is described as linear-time; a brief complexity argument or pseudocode reference would strengthen the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the current evaluation would be strengthened by explicit per-operation metrics and isolated analysis of the classification step to better substantiate the soundness-faithfulness decomposition. We respond to each major comment below and will incorporate the requested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation (LongMemEval-KU and grounding test results)] The central empirical results (89.7% on LongMemEval-KU oracle and 100% on the 15-item stale-premise subset) are reported only as end-to-end accuracy. No per-operation precision, recall, or confusion matrix is provided for the LLM's mapping of turns to the 8 update operations. This is load-bearing: systematic misclassification of subtle cases (e.g., abductive inference as epistemic update) would silently corrupt the dependency graph, so the formal conflict-free guarantee no longer certifies groundedness even though the symbolic engine remains correct by construction.
Authors: We agree that end-to-end accuracy alone does not fully rule out systematic classification errors that could corrupt the dependency graph. The 100% result on the stale-premise subset provides indirect support for reliable classification on retraction-critical cases, but this is insufficient. In the revised manuscript we will add a full per-operation precision/recall breakdown together with a confusion matrix for the eight update operations, computed on both LongMemEval-KU and the grounding test set. This will allow direct assessment of classification faithfulness and the frequency of support-relation errors. revision: yes
-
Referee: [Method and §5 (faithfulness measurement)] The soundness-faithfulness decomposition is stated explicitly, yet the manuscript provides no isolated error analysis or adversarial test cases for the classification step itself. Without this, it is impossible to quantify how often the graph encodes incorrect support relations, which directly affects the claim that the verifier reaches high accuracy with formal guarantees.
Authors: We acknowledge that the manuscript lacks an isolated error analysis of the classification step and does not present adversarial test cases targeting subtle distinctions (e.g., abductive versus epistemic updates). To address this directly, the revision will include a dedicated error-analysis subsection in §5 with quantitative results on classification mistakes, their propagation to the graph, and performance on a set of adversarial examples we will construct to probe boundary cases between the eight operations. This will quantify the rate at which incorrect support relations are encoded. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's method decomposes into an LLM prompt for mapping turns to 8 operations (drawn from external formalisms) and an independent symbolic dependency graph whose soundness and conflict-free guarantee hold by construction regardless of classification accuracy. All reported results are end-to-end empirical accuracies on external benchmarks (LongMemEval-KU, LoCoMo, custom grounding tests) with no equations, predictions, or central claims that reduce to fitted parameters, self-defined quantities, or load-bearing self-citations. The faithfulness of the LLM step is explicitly framed as a measured empirical question rather than an internal assumption that closes the loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four formalisms supply eight update operations that together cover the dependency relations needed for conversation grounding.
invented entities (1)
-
Conversation dependency graph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat (8-tick period implicit in orbit structure) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
an LLM classifies each turn into one of 8 update operations drawn from four formalisms (dynamic epistemic logic, abductive reasoning, awareness logic, argumentation)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 2.1 (Conflict-free selective retraction)... S' is conflict-free in AF'
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year =
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , title =. International Conference on Learning Representations (ICLR) , year =
-
[2]
Wang, Peiran and Liu, Yang and Lu, Yunfei and Cai, Yifeng and Chen, Hongbo and Yang, Qingyou and Zhang, Jie and Hong, Jue and Wu, Ye , journal =
-
[3]
Logic and the Foundations of Game and Decision Theory (
Alexandru Baltag and Sonja Smets , title =. Logic and the Foundations of Game and Decision Theory (
-
[4]
Moss and Slawomir Solecki , title =
Alexandru Baltag and Lawrence S. Moss and Slawomir Solecki , title =. Proceedings of the 7th Conference on Theoretical Aspects of Rationality and Knowledge (
-
[5]
Halpern and Yoram Moses and Moshe Y
Ronald Fagin and Joseph Y. Halpern and Yoram Moses and Moshe Y. Vardi , title =
-
[6]
Ronald Fagin and Joseph Y. Halpern , title =. Artificial Intelligence , volume =
-
[7]
Hans van Ditmarsch and Wiebe van der Hoek and Bart Kooi , title =
-
[8]
Fernando R. Vel. An Epistemic and Dynamic Approach to Abductive Reasoning: Abductive Problem and Abductive Solution , journal =
-
[9]
Journal of Applied Non-Classical Logics , volume =
Johan van Benthem , title =. Journal of Applied Non-Classical Logics , volume =
-
[10]
Krister Segerberg on Logic of Action , editor =
Alexandru Baltag and Virginie Fiutek and Sonja Smets , title =. Krister Segerberg on Logic of Action , editor =. 2014 , pages =
work page 2014
-
[11]
On the Complexity of Dynamic Epistemic Logic , booktitle =
Guillaume Aucher and Fran. On the Complexity of Dynamic Epistemic Logic , booktitle =
-
[12]
Dunne and Michael Wooldridge , title =
Paul E. Dunne and Michael Wooldridge , title =. Argumentation in Artificial Intelligence , editor =
- [13]
-
[14]
Artificial Intelligence , volume =
Phan Minh Dung , title =. Artificial Intelligence , volume =
-
[15]
Sylvie Doutre and Andreas Herzig and Laurent Perrussel , title =. Proceedings of the Fourteenth International Conference on Principles of Knowledge Representation and Reasoning (
-
[16]
Douglas Walton and Chris Reed and Fabrizio Macagno , title =
-
[17]
Werner Kunz and Horst W. J. Rittel , title =
-
[18]
Jeff Conklin , title =
-
[19]
International Journal on Software Tools for Technology Transfer , volume =
Alessio Lomuscio and Hongyang Qu and Franco Raimondi , title =. International Journal on Software Tools for Technology Transfer , volume =. 2017 , note =
work page 2017
-
[20]
Ron van der Meyden and Kaile Su , title =. Proceedings of the 17th. 2004 , note =
work page 2004
-
[21]
Model Checking and Artificial Intelligence (MoChArt 2010) , series =
Xiaowei Huang and Cheng Luo and Ron van der Meyden , title =. Model Checking and Artificial Intelligence (MoChArt 2010) , series =. 2011 , note =
work page 2010
-
[22]
arXiv preprint arXiv:2311.17406 , year =
Siwei Chen and Anxing Xiao and David Hsu , title =. arXiv preprint arXiv:2311.17406 , year =
-
[23]
Advances in Neural Information Processing Systems (
Hao Tang and Darren Yan Key and Kevin Ellis , title =. Advances in Neural Information Processing Systems (. 2024 , note =
work page 2024
-
[24]
arXiv preprint arXiv:2504.15785 , year =
Siyu Zhou and Tianyi Zhou and Yijun Yang and Guodong Long and Deheng Ye and Jing Jiang and Chengqi Zhang , title =. arXiv preprint arXiv:2504.15785 , year =
-
[25]
Joon Sung Park and Joseph C. O'Brien and Carrie J. Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , title =. Proceedings of the 36th Annual
-
[26]
A Survey on the Memory Mechanism of Large Language Model based Agents
Zeyu Zhang and others , title =. arXiv preprint arXiv:2404.13501 , year =
work page internal anchor Pith review arXiv
-
[27]
arXiv preprint arXiv:2510.13363 , year =
Xiang Lei and Qin Li and Min Zhang , title =. arXiv preprint arXiv:2510.13363 , year =
-
[28]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen and Pavlo Paliychuk and Travis Beauvais and Jack Ryan and Daniel Chalef , title =. arXiv preprint arXiv:2501.13956 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the 29th Conference on Computational Natural Language Learning (
Timothy Obiso and Kenneth Lai and Abhijnan Nath and Nikhil Krishnaswamy and James Pustejovsky , title =. Proceedings of the 29th Conference on Computational Natural Language Learning (
-
[30]
Elfia Bezou-Vrakatseli and Oana Cocarascu and Sanjay Modgil , title =. 2024 , eprint =
work page 2024
-
[31]
Jeonghye Kim and Sojeong Rhee and Minbeom Kim and Dohyung Kim and Sangmook Lee and Youngchul Sung and Kyomin Jung , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2025 , publisher =. 2505.15182 , archivePrefix =
-
[32]
Effective Context Engineering for. 2025 , month = sep, note =
work page 2025
-
[33]
International Conference on Learning Representations (
Qizheng Zhang and Changran Hu and Shubhangi Upasani and Boyuan Ma and Fenglu Hong and Vamsidhar Kamanuru and Jay Rainton and Chen Wu and Mengmeng Ji and Hanchen Li and Urmish Thakker and James Zou and Kunle Olukotun , title =. International Conference on Learning Representations (. 2026 , eprint =
work page 2026
-
[34]
Evaluating very long-term conversational memory of llm agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[35]
ICML 2025 Workshop on Assessing World Models , year=
ReviseQA: A Benchmark for Belief Revision in Multi-Turn Logical Reasoning , author=. ICML 2025 Workshop on Assessing World Models , year=
work page 2025
-
[36]
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , booktitle=
-
[37]
Enabling Large Language Models to Generate Text with Citations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2023
-
[38]
arXiv preprint arXiv:2212.08037 , year=
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models , author=. arXiv preprint arXiv:2212.08037 , year=
-
[39]
Shaikh, Omar and Mozannar, Hussein and Bansal, Gagan and Fourney, Adam and Horvitz, Eric , booktitle=. Navigating Rifts in Human-
-
[40]
Katsis, Yannis and Rosenthal, Sara and Fadnis, Kshitij and Gunasekara, Chulaka and Lee, Young-Suk and Popa, Lucian and Shah, Vraj and Zhu, Huaiyu and Contractor, Danish and Danilevsky, Marina , journal=
-
[41]
WildChat : 1M ChatGPT Interaction Logs in the Wild
Wildchat: 1m chatgpt interaction logs in the wild , author=. arXiv preprint arXiv:2405.01470 , year=
-
[42]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Multiwoz-a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
work page 2018
-
[43]
Proceedings of the Association for Information Science and Technology , volume=
Bing chat: The future of search engines? , author=. Proceedings of the Association for Information Science and Technology , volume=. 2023 , publisher=
work page 2023
-
[44]
Ashwin and Mittal, Prateek and Viswanath, Pramod , journal=
Patlan, Atharv Singh and Sheng, Peiyao and Hebbar, S. Ashwin and Mittal, Prateek and Viswanath, Pramod , journal=. Real
-
[45]
A Practical Memory Injection Attack against
Dong, Shen and Xu, Shaochen and He, Pengfei and Li, Yige and Tang, Jiliang and Liu, Tianming and Liu, Hui and Xiang, Zhen , journal=. A Practical Memory Injection Attack against
-
[46]
Beyond the Black Box: Demystifying Multi-Turn
Zhang, Yiran and Lin, Mingyang and Dras, Mark and Naseem, Usman , booktitle=. Beyond the Black Box: Demystifying Multi-Turn. 2026 , note=
work page 2026
-
[47]
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , booktitle =. 2025 , doi =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.