Recognition: no theorem link
Towards Fine-Grained and Verifiable Concept Bottleneck Models
Pith reviewed 2026-05-15 02:11 UTC · model grok-4.3
The pith
A verifiable CBM framework grounds concepts in localized image patches, achieving comparable accuracy to standard CBMs on medical benchmarks while enabling direct inspection of concept correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
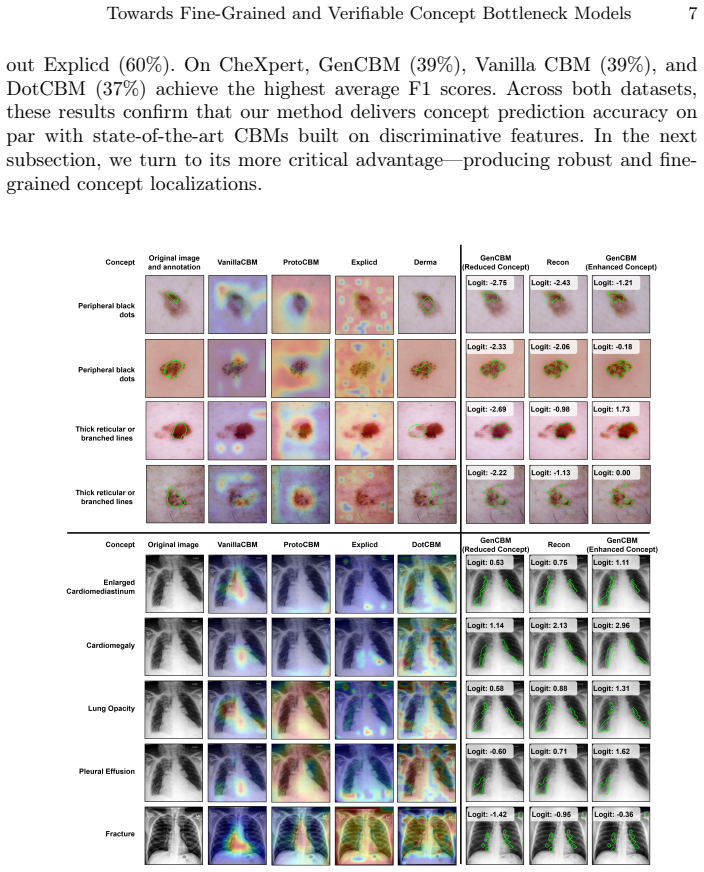
Experiments on medical imaging benchmarks show that our learned concept space is information-complete and achieves predictive performance comparable to standard CBMs, while substantially improving transparency. Unlike post-hoc attribution methods, our framework validates both the presence and correctness of concept representations.
Load-bearing premise
That localizing each concept to visual evidence regions will reliably prevent the model from learning spurious correlations and that human inspection of these regions will correctly verify intended concepts without additional validation data or metrics.
Figures



read the original abstract
Concept Bottleneck Models (CBMs) offer interpretable alternatives to black-box predictors by introducing human-relatable concepts before the final output. However, existing CBMs struggle to verify whether predicted concepts correspond to the correct visual evidence, limiting their reliability. We propose a fine-grained CBM framework that grounds each concept in localized visual evidence, enabling direct inspection of where and how concepts are encoded. This design allows users to interpret predictions and verify that the model learns intended concepts rather than spurious correlations. Experiments on medical imaging benchmarks show that our learned concept space is information-complete and achieves predictive performance comparable to standard CBMs, while substantially improving transparency. Unlike post-hoc attribution methods, our framework validates both the presence and correctness of concept representations, bridging interpretability with verifiability. Our approach enhances the trustworthiness of CBMs and establishes a principled mechanism for human-model interaction at the concept level, paving the way toward more reliable and clinically actionable concept-based learning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a fine-grained Concept Bottleneck Model (CBM) framework that grounds each concept in localized visual evidence regions. This design is intended to enable direct human inspection of concept encodings, verify correctness rather than spurious correlations, and improve transparency over standard CBMs and post-hoc attribution methods. Experiments on medical imaging benchmarks are claimed to show that the learned concept space is information-complete, achieves predictive performance comparable to standard CBMs, and substantially improves transparency.
Significance. If the localization mechanism and experimental claims hold, the work would strengthen the verifiability of CBMs in high-stakes domains such as medical imaging by providing a direct way to inspect and validate concept representations, thereby increasing trustworthiness and supporting human-model interaction at the concept level.
major comments (2)
- [Abstract] Abstract: the claim that experiments demonstrate an 'information-complete' concept space with comparable predictive performance rests on unspecified methods, baselines, error bars, and quantification of information-completeness; these details are load-bearing for the central claim of improved verifiability and must be supplied with concrete metrics and controls.
- [Proposed framework] Proposed framework: no explicit regularization term, loss component, or architectural constraint is described that penalizes concept activations outside the localized visual evidence mask or forces the downstream predictor to ignore non-localized features. Without such a mechanism, localization maps can be produced as a side effect while the model still relies on global image statistics, undermining the guarantee that localization prevents spurious correlations.
minor comments (1)
- [Abstract] Abstract: the phrase 'validates both the presence and correctness of concept representations' is used without a precise operational definition or reference to the validation procedure.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments demonstrate an 'information-complete' concept space with comparable predictive performance rests on unspecified methods, baselines, error bars, and quantification of information-completeness; these details are load-bearing for the central claim of improved verifiability and must be supplied with concrete metrics and controls.
Authors: We agree that the abstract should provide more concrete details to support the central claims. In the revised manuscript we will expand the abstract to specify the metrics used to quantify information-completeness (concept prediction accuracy on held-out patches together with downstream task performance retention), the baselines employed (standard CBMs and end-to-end black-box models), and the use of error bars obtained from multiple random seeds. These elements are already reported in Section 4; the revision will simply make them explicit in the abstract. revision: yes
-
Referee: [Proposed framework] Proposed framework: no explicit regularization term, loss component, or architectural constraint is described that penalizes concept activations outside the localized visual evidence mask or forces the downstream predictor to ignore non-localized features. Without such a mechanism, localization maps can be produced as a side effect while the model still relies on global image statistics, undermining the guarantee that localization prevents spurious correlations.
Authors: We appreciate this observation. While the framework supplies localized patches as the sole input for each concept predictor, the original submission did not include an explicit penalty that strictly discourages activations outside those patches. To close this gap we will introduce a regularization term in the loss that penalizes concept activations outside the provided localization masks. This addition will enforce that the learned concept representations are grounded exclusively in the designated visual evidence and will be described in the revised Section 3. revision: yes
Circularity Check
No load-bearing circularity; localization framework adds independent verification mechanism
full rationale
The paper proposes a fine-grained CBM with explicit localization of concepts to visual regions, enabling human inspection for presence and correctness. No equations or training objectives are shown to reduce by construction to fitted parameters or prior self-citations; the claim of information-completeness and comparable performance rests on experimental benchmarks rather than tautological re-derivation. Self-citations, if present, are not load-bearing for the core transparency argument, which introduces a new grounding step not equivalent to standard CBM inputs. This yields a minor score reflecting normal academic self-reference without forcing the central result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature Machine Intelligence3(12), 1061–1070 (2021)
Barnett, A.J., Schwartz, F.R., Tao, C., Chen, C., Ren, Y., Lo, J.Y., Rudin, C.: A case-based interpretable deep learning model for classification of mass lesions in digital mammography. Nature Machine Intelligence3(12), 1061–1070 (2021)
work page 2021
-
[2]
Nature Communications15(1), 524 (2024)
Chanda, T., Hauser, K., Hobelsberger, S., Bucher, T.C., Garcia, C.N., Wies, C., Kittler, H., Tschandl, P., Navarrete-Dechent, C., Podlipnik, S., et al.: Dermatologist-like explainable ai enhances trust and confidence in diagnosing melanoma. Nature Communications15(1), 524 (2024)
work page 2024
-
[3]
In: 2018 IEEE winter conference on applications of computer vision (WACV)
Chattopadhay, A., Sarkar, A., Howlader, P., Balasubramanian, V.N.: Grad- cam++: Generalized gradient-based visual explanations for deep convolutional networks. In: 2018 IEEE winter conference on applications of computer vision (WACV). pp. 839–847. IEEE (2018)
work page 2018
-
[4]
Codella, N., Rotemberg, V., Tschandl, P., Celebi, M.E., Dusza, S., Gutman, D., Helba,B.,Kalloo,A.,Liopyris,K.,Marchetti,M.,etal.:Skinlesionanalysistoward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv preprint arXiv:1902.03368 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Advances in neural information processing systems35, 21400–21413 (2022)
Espinosa Zarlenga, M., Barbiero, P., Ciravegna, G., Marra, G., Giannini, F., Dili- genti, M., Shams, Z., Precioso, F., Melacci, S., Weller, A., et al.: Concept em- bedding models: Beyond the accuracy-explainability trade-off. Advances in neural information processing systems35, 21400–21413 (2022)
work page 2022
-
[6]
In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention
Gao, Y., Gu, D., Zhou, M., Metaxas, D.: Aligning human knowledge with visual concepts towards explainable medical image classification. In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention. pp. 46–56. Springer (2024)
work page 2024
-
[7]
Advances in Neural Information Processing Systems35, 23386–23397 (2022)
Havasi, M., Parbhoo, S., Doshi-Velez, F.: Addressing leakage in concept bottle- neck models. Advances in Neural Information Processing Systems35, 23386–23397 (2022)
work page 2022
-
[8]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
work page 2016
-
[9]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Huang, Q., Song, J., Hu, J., Zhang, H., Wang, Y., Song, M.: On the concept trust- worthiness in concept bottleneck models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 21161–21168 (2024)
work page 2024
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huy, T.D., Tran, S.K., Nguyen, P., Tran, N.H., Sam, T.B., van den Hengel, A., Liao, Z., Verjans, J.W., To, M.S., Phan, V.M.H.: Interactive medical image analysis with concept-based similarity reasoning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 30797–30806 (2025)
work page 2025
-
[11]
In: Proceedings of the AAAI conference on artificial intelligence
Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 590–597 (2019)
work page 2019
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8110–8119 (2020)
work page 2020
-
[13]
In: International conference on machine learning
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al.: Inter- pretabilitybeyondfeatureattribution:Quantitativetestingwithconceptactivation vectors (tcav). In: International conference on machine learning. pp. 2668–2677. PMLR (2018) 10 Y. Fang, H. Xu et al
work page 2018
-
[14]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
In: International conference on machine learning
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International conference on machine learning. pp. 5338–5348. PMLR (2020)
work page 2020
-
[16]
In: International Conference on Learning Representations (2023)
Oikarinen, T., Das, S., Nguyen, L.M., Weng, T.W.: Label-free concept bottleneck models. In: International Conference on Learning Representations (2023)
work page 2023
-
[17]
In: International Conference on Learning Representations (2023)
Oikarinen, T., Weng, T.W.: Clip-dissect: Automatic description of neuron rep- resentations in deep vision networks. In: International Conference on Learning Representations (2023)
work page 2023
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Preechakul, K., Chatthee, N., Wizadwongsa, S., Suwajanakorn, S.: Diffusion au- toencoders: Toward a meaningful and decodable representation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10619– 10629 (2022)
work page 2022
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Richardson, E., Alaluf, Y., Patashnik, O., Nitzan, Y., Azar, Y., Shapiro, S., Cohen- Or, D.: Encoding in style: a stylegan encoder for image-to-image translation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 2287–2296 (2021)
work page 2021
-
[20]
In: Proceedings of the IEEE international conference on computer vision
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision. pp. 618–626 (2017)
work page 2017
-
[21]
Advances in Neural Information Processing Systems36, 26966– 26990 (2023)
Sheth, I., Ebrahimi Kahou, S.: Auxiliary losses for learning generalizable concept- based models. Advances in Neural Information Processing Systems36, 26966– 26990 (2023)
work page 2023
-
[22]
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv e-prints pp. arXiv–1409 (2014)
work page 2014
-
[23]
In: European Conference on Computer Vision
Tan, A., Zhou, F., Chen, H.: Explain via any concept: Concept bottleneck model with open vocabulary concepts. In: European Conference on Computer Vision. pp. 123–138. Springer (2024)
work page 2024
-
[24]
Scientific data5(1), 180161 (2018)
Tschandl, P., Rosendahl, C., Kittler, H.: The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data5(1), 180161 (2018)
work page 2018
-
[25]
arXiv preprint arXiv:2506.12568 (2025)
Wang, C., Zhang, K., Liu, Y., He, Z., Tao, X., Zhou, S.K.: Mvp-cbm: Multi-layer visualpreference-enhancedconceptbottleneckmodelforexplainablemedicalimage classification. arXiv preprint arXiv:2506.12568 (2025)
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xie, Y., Zeng, Z., Zhang, H., Ding, Y., Wang, Y., Wang, Z., Chen, B., Liu, H.: Discovering fine-grained visual-concept relations by disentangled optimal trans- port concept bottleneck models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 30199–30209 (2025)
work page 2025
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xu, Y., Shen, Y., Zhu, J., Yang, C., Zhou, B.: Generative hierarchical features from synthesizing images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4432–4442 (2021)
work page 2021
-
[28]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Zhang, R., Du, X., Yan, J., Zhang, S.: The decoupling concept bottleneck model. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.