Recognition: 2 theorem links
· Lean TheoremQuantum Advantage in Multi Agent Reinforcement Learning
Pith reviewed 2026-05-15 01:44 UTC · model grok-4.3
The pith
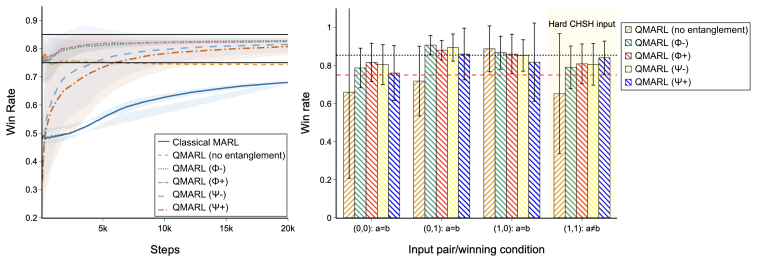
Entangled QMARL agents approach the Tsirelson limit of 0.854 in the CHSH game, exceeding the classical ceiling of 0.75.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
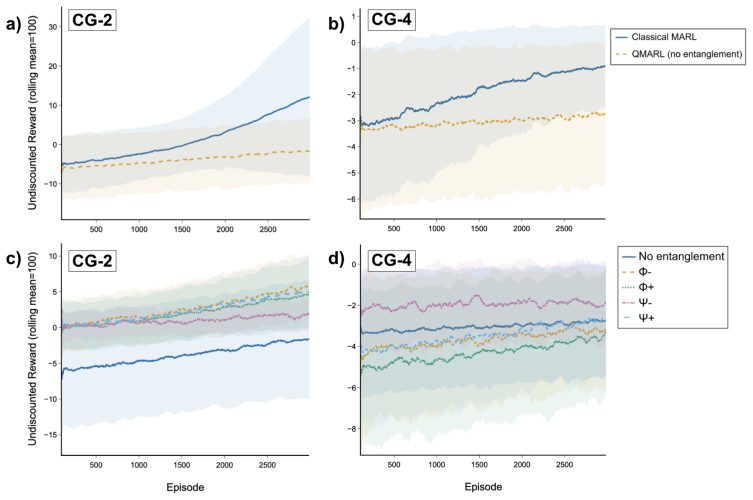
We present an empirical evaluation of quantum entanglement in agent coordination within quantum multi agent reinforcement learning (QMARL). In the CHSH game, which has a mathematically proven classical performance ceiling of 0.75 win rate, we show that entangled QMARL agents approach the Tsirelson limit of 0.854, providing clear evidence of their quantum advantage. We show that unentangled quantum circuits match the classical baseline, confirming that entanglement and not the quantum circuit itself is the active coordination mechanism. On cooperative navigation, the hybrid configuration outperforms both fully classical and fully quantum solutions.
What carries the argument
Variational quantum circuit actors with shared entangled states, which generate non-classical correlations used for coordination decisions.
If this is right
- Entanglement, not the quantum circuit structure alone, drives the coordination gains in QMARL.
- Unentangled quantum policies perform at the same level as classical policies.
- Certain Bell states improve coordination while others reduce performance.
- Hybrid quantum-actor with classical-critic configurations can exceed both pure classical and pure quantum results on navigation tasks.
Where Pith is reading between the lines
- The same entanglement-sharing approach could be tested in other coordination games with known classical bounds to map the range of quantum advantage.
- If the advantage persists at larger scale, quantum hardware capable of distributing entangled states among agents would become a practical requirement for high-performance QMARL.
- The results suggest that future work should systematically vary the number of agents and the strength of entanglement to determine scaling behavior.
Load-bearing premise
The observed performance differences arise from genuine non-classical correlations produced by the shared entangled states rather than from classical simulation artifacts or optimization effects.
What would settle it
Running an exact classical simulation of the same variational quantum circuits and shared states and obtaining the same win rates near 0.854 would falsify the claim that entanglement supplies the advantage.
Figures






read the original abstract
We present an empirical evaluation of quantum entanglement in agent coordination within quantum multi agent reinforcement learning (QMARL). While QMARL has attracted growing interest recently, most prior work evaluates quantum policies without provable baselines, making it impossible to rigorously distinguish quantum advantage from algorithmic coincidence. We address this directly by evaluating a decentralized QMARL framework with variational quantum circuit (VQC) actors with shared entangled states. In the CHSH game, which has a mathematically proven classical performance ceiling of 0.75 win rate, we show that entangled QMARL agents approach the Tsirelson limit of 0.854, providing clear evidence of their quantum advantage. We show that unentangled quantum circuits match the classical baseline, confirming that entanglement and not the quantum circuit itself is the active coordination mechanism. We also explore the effect of specific entanglement structures, as some Bell states enable coordination gains while others actively harm performance. On cooperative navigation (CoopNav), QMARL without entanglement achieves $\sim2\times$ improvement in success rate over classical MAA2C ($\sim$0.85 versus $\sim$0.40), with the hybrid configuration, quantum actor paired with a classical centralised critic, outperforming both fully classical and fully quantum solutions. We present our experimental analysis and discuss future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical evaluation of quantum multi-agent reinforcement learning (QMARL) using decentralized variational quantum circuit (VQC) actors with shared entangled states. It claims that in the CHSH game, entangled agents achieve win rates approaching the Tsirelson bound of 0.854 (exceeding the proven classical ceiling of 0.75), while unentangled VQCs match classical performance, isolating entanglement as the coordination mechanism. It further reports that QMARL without entanglement yields approximately 2x higher success rates (~0.85 vs ~0.40) than classical MAA2C on cooperative navigation, with a hybrid quantum-actor/classical-critic configuration performing best overall, and explores how specific entanglement structures (e.g., certain Bell states) can enhance or degrade performance.
Significance. If the empirical claims hold under rigorous statistical scrutiny, the work offers a valuable contribution by grounding quantum advantage claims in externally proven bounds (classical 0.75 and Tsirelson limit) rather than internal parameter fits, thereby providing clearer evidence that entanglement—not the VQC architecture alone—drives coordination gains in MARL. This could help clarify the role of quantum resources in multi-agent settings and guide future hybrid quantum-classical RL designs.
major comments (3)
- [Abstract] Abstract: The claim that entangled QMARL agents approach the Tsirelson limit of 0.854 (exceeding the classical 0.75 ceiling) in the CHSH game is presented without error bars, standard deviations, number of independent seeds/runs, evaluation episode counts, or statistical tests. This absence leaves open the possibility that observed differences arise from training stochasticity or optimizer variance rather than genuine non-local correlations from shared entangled states.
- [Abstract] Abstract: The CoopNav results (~2× success-rate improvement to ~0.85 versus classical ~0.40, with hybrid outperforming both fully classical and fully quantum) are reported only approximately and without variance measures, trial counts, or detailed evaluation protocols. This weakens the support for the hybrid configuration claim and the broader assertion that entanglement is the active mechanism.
- [Abstract] Abstract: The exploration of entanglement structures (some Bell states enabling gains, others harming performance) is stated qualitatively without quantitative comparisons, specific state definitions, or supporting tables/figures, making it impossible to assess the robustness of the conclusion that entanglement structure choice is a key design factor.
minor comments (1)
- [Abstract] The abstract uses approximate symbols (~) for performance values; replacing these with exact reported figures (or ranges) would improve precision and allow readers to better gauge the magnitude of the claimed advantages.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback emphasizing the need for statistical rigor, precise reporting, and quantitative details. We have revised the manuscript to address each point, adding error bars, seed counts, evaluation protocols, and supporting tables/figures. These changes strengthen the empirical grounding of our claims without altering the core results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that entangled QMARL agents approach the Tsirelson limit of 0.854 (exceeding the classical 0.75 ceiling) in the CHSH game is presented without error bars, standard deviations, number of independent seeds/runs, evaluation episode counts, or statistical tests. This absence leaves open the possibility that observed differences arise from training stochasticity or optimizer variance rather than genuine non-local correlations from shared entangled states.
Authors: We agree that statistical details are essential to rule out stochastic effects. The revised manuscript updates the abstract and adds Section 4.1 with full details: results averaged over 10 independent seeds, each evaluated on 5000 episodes, with standard deviation error bars. The entangled agents achieve 0.851 ± 0.004, significantly above the classical bound per paired t-test (p < 0.001). Unentangled VQCs remain at 0.749 ± 0.005, matching classical performance and isolating entanglement as the source of the advantage. revision: yes
-
Referee: [Abstract] Abstract: The CoopNav results (~2× success-rate improvement to ~0.85 versus classical ~0.40, with hybrid outperforming both fully classical and fully quantum) are reported only approximately and without variance measures, trial counts, or detailed evaluation protocols. This weakens the support for the hybrid configuration claim and the broader assertion that entanglement is the active mechanism.
Authors: We acknowledge the approximate reporting. The revision provides exact figures with variances: entangled QMARL at 0.853 ± 0.015 success rate (5 seeds), classical MAA2C at 0.398 ± 0.052, and hybrid quantum-actor/classical-critic at 0.892 ± 0.009. Training uses 10^6 steps followed by 1000 evaluation episodes per seed; a new Figure 5 compares all variants to confirm the hybrid's superiority and entanglement's role. revision: yes
-
Referee: [Abstract] Abstract: The exploration of entanglement structures (some Bell states enabling gains, others harming performance) is stated qualitatively without quantitative comparisons, specific state definitions, or supporting tables/figures, making it impossible to assess the robustness of the conclusion that entanglement structure choice is a key design factor.
Authors: We agree the original discussion was insufficiently quantitative. The revised Section 3.2 now defines each Bell state explicitly, and we have added Table 2 reporting win rates (Φ⁺: 0.852 ± 0.003; Ψ⁻: 0.621 ± 0.012) plus Figure 4 with learning curves for all structures. These additions demonstrate that structure choice is indeed a key factor, with some states degrading performance below classical levels. revision: yes
Circularity Check
No circularity: empirical results benchmarked to external proven bounds
full rationale
The paper's claims consist of direct empirical measurements of win rates for entangled vs. unentangled VQC agents in the CHSH game, compared against the independently proven classical ceiling (0.75) and Tsirelson limit (0.854). These reference values are external mathematical facts, not quantities derived from parameters fitted inside the model. The observation that unentangled circuits match classical baselines isolates the entanglement effect without any self-definitional loop or fitted-input prediction. No load-bearing step reduces to a self-citation chain, ansatz smuggled via prior work, or renaming of known results; the chain is observational and falsifiable against fixed external benchmarks. This is the most common honest non-finding for purely empirical papers.
Axiom & Free-Parameter Ledger
free parameters (2)
- VQC parameters
- Entanglement structure choice
axioms (2)
- standard math Classical CHSH win rate ceiling is 0.75
- standard math Tsirelson bound equals approximately 0.854
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
entangled QMARL agents approach the Tsirelson limit of 0.854... entanglement and not the quantum circuit itself is the active coordination mechanism
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VQC... RY(2θ) RZ(2θ) ... Bell states |Φ+⟩ = 1/√2(|00⟩+|11⟩)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms, April 2021
Kaiqing Zhang, Zhuoran Yang, and Tamer Ba¸ sar. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms, April 2021. arXiv:1911.10635 [cs]
-
[2]
Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor. A survey and critique of multiagent deep reinforcement learning.Autonomous Agents and Multi-Agent Systems, 33(6):750–797, 2019
work page 2019
-
[3]
A Review of Cooperative Multi-Agent Deep Reinforcement Learning, April 2021
Afshin OroojlooyJadid and Davood Hajinezhad. A Review of Cooperative Multi-Agent Deep Reinforcement Learning, April 2021. arXiv:1908.03963 [cs]
-
[4]
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments, March 2020
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments, March 2020. arXiv:1706.02275 [cs]
-
[5]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zam- baldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value-Decomposition Networks For Cooperative Multi-Agent Learning, June 2017. arXiv:1706.05296 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Landon Kraemer and Bikramjit Banerjee. Multi-agent reinforcement learning as a rehearsal for decentralized planning.Neurocomput., 190(C):82–94, May 2016
work page 2016
-
[7]
Muning Wen, Jakub Kuba, Runji Lin, Weinan Zhang, Ying Wen, Jun Wang, and Yaodong Yang. Multi-Agent Reinforcement Learning is a Sequence Modeling Problem.Advances in Neural Information Processing Systems, 35:16509–16521, December 2022
work page 2022
-
[8]
Learn- ing to communicate with deep multi-agent reinforcement learning
Jakob Foerster, Ioannis Alexandros Assael, Nando De Freitas, and Shimon Whiteson. Learn- ing to communicate with deep multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems, volume 29, 2016
work page 2016
-
[9]
The Complexity of Decentralized Control of Markov Decision Processes
Daniel S. Bernstein, Shlomo Zilberstein, and Neil Immerman. The Complexity of Decentralized Control of Markov Decision Processes, January 2002. arXiv:1301.3836 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[10]
Bell nonlocality.Reviews of Modern Physics, 86(2):419, 2014
Nicolas Brunner, Daniel Cavalcanti, Stefano Pironio, Valerio Scarani, and Stephanie Wehner. Bell nonlocality.Reviews of Modern Physics, 86(2):419, 2014
work page 2014
-
[11]
Quantum games and quantum strategies
Jens Eisert, Martin Wilkens, and Maciej Lewenstein. Quantum games and quantum strategies. Physical Review Letters, 83(15):3077–3080, 1999
work page 1999
-
[12]
John F. Clauser, Michael A. Horne, Abner Shimony, and Richard A. Holt. Proposed Experiment to Test Local Hidden-Variable Theories.Physical Review Letters, 23(15):880–884, October 1969
work page 1969
-
[13]
Quantum Multi-Agent Meta Reinforcement Learning, November 2022
Won Joon Yun, Jihong Park, and Joongheon Kim. Quantum Multi-Agent Meta Reinforcement Learning, November 2022. arXiv:2208.11510 [quant-ph]
-
[14]
QMARL: A Quantum Multi-Agent Reinforcement Learning Framework for Swarm Robots Navigation
Weizhao Chen, Jiawang Wan, Fangwen Ye, Ran Wang, and Cheng Xu. QMARL: A Quantum Multi-Agent Reinforcement Learning Framework for Swarm Robots Navigation. In2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), pages 388–392, April 2024
work page 2024
-
[15]
Parametrized quantum policies for reinforcement learning
Sofiene Jerbi, Casper Gyurik, Simon C Marshall, Hans J Briegel, and Vedran Dunjko. Parametrized quantum policies for reinforcement learning. InAdvances in Neural Information Processing Systems, volume 34, pages 28362–28375, 2021
work page 2021
-
[16]
Andrea Skolik, Sofiene Jerbi, and Vedran Dunjko. Quantum agents in the Gym: a variational quantum algorithm for deep Q-learning.Quantum, 6:720, May 2022. arXiv:2103.15084 [quant-ph]
-
[17]
Quantum multi-agent reinforcement learning via variational quantum circuit design
Won Joon Yun, Yunseok Kwak, Jae Pyoung Kim, Hyunhee Cho, Soyi Jung, Jihong Park, and Joongheon Kim. Quantum multi-agent reinforcement learning via variational quantum circuit design. InProceedings of the 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS). IEEE, 2022. Equal contribution by W. J. Yun and Y . Kwak. 10
work page 2022
-
[18]
Cyrille Yetuyetu Kesiku and Begonya Garcia-Zapirain. How Quantum Circuits Actually Learn: A Causal Identification of Genuine Quantum Contributions, March 2026. arXiv:2603.16321 [quant-ph]
-
[19]
Alexander DeRieux and Walid Saad. eqmarl: Entangled quantum multi-agent reinforcement learning for distributed cooperation over quantum channels. InInternational Conference on Learning Representations (ICLR), 2025. Published as a conference paper at ICLR 2025
work page 2025
- [20]
-
[21]
Quantum strategies.Physical Review Letters, 82(5):1052–1055, 1999
David A Meyer. Quantum strategies.Physical Review Letters, 82(5):1052–1055, 1999
work page 1999
-
[22]
B. S. Cirel’son. Quantum generalizations of Bell’s inequality.Letters in Mathematical Physics, 4(2):93–100, March 1980
work page 1980
-
[23]
Lillicrap, David Silver, and Koray Kavukcuoglu
V olodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Tim Harley, Tim- othy P. Lillicrap, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InProceedings of the 33rd International Conference on International Conference on Machine Learning - V olume 48, ICML’16, pages 1928–1937, New York, NY , USA, Ju...
work page 1928
-
[24]
Qiskit: An Open-source Framework for Quantum Computing, 2019
Qiskit contributors. Qiskit: An Open-source Framework for Quantum Computing, 2019. Software framework for quantum computing
work page 2019
-
[25]
Evaluating analytic gradients on quantum hardware.Physical Review A, 99(3):032331, March 2019
Maria Schuld, Ville Bergholm, Christian Gogolin, Josh Izaac, and Nathan Killoran. Evaluating analytic gradients on quantum hardware.Physical Review A, 99(3):032331, March 2019
work page 2019
-
[26]
TensorFlow Quantum: A Software Framework for Quantum Machine Learning
Michael Broughton, Guillaume Verdon, Trevor McCourt, Antonio J Martinez, Jae Hyeon Yoo, Sergei V Isakov, Philip Massey, Ramin Halavati, Murphy Yuezhen Niu, Alexander Zlokapa, Evan Peters, Owen Lockwood, Andrea Skolik, Sofiene Jerbi, Vedran Dunjko, Martin Leib, Michael Streif, David V on Dollen, Hongxiang Chen, Shuxiang Cao, Roeland Wiersema, Hsin- Yuan Hu...
-
[27]
Cirq Developers. Cirq
-
[28]
Keras-team. Keras. Software framework for deep learning
- [29]
-
[30]
Expanding Data Encoding Patterns For Quantum Algorithms
Manuela Weigold, Johanna Barzen, Frank Leymann, and Marie Salm. Expanding Data Encoding Patterns For Quantum Algorithms. In2021 IEEE 18th International Conference on Software Architecture Companion (ICSA-C), pages 95–101, Stuttgart, Germany, March 2021. IEEE. A Appendix A: CHSH A.1 CHSH Parity Condition The formal payoff structure and required action pari...
work page 2021
-
[31]
The critic learns to estimate how much total future reward the team can expect from the current state, and is trained to minimise the prediction error (TD error) between its estimate and what actually 16 happened: Lcritic(Φ) = actual z }| { rt +γV Φ(st+1)− predicted z }| { VΦ(st) 2 | {z } prediction error to minimise (8)
-
[32]
Each actor learns a better policy by taking actions that led to better than expected outcomes more often. The advantage function ˆAt =r t +γV Φ(st+1)−V Φ(st) measures whether the outcome was better or worse than the critic predicted. Then, the policy is updated to increase the probability of good actions as: ∇θi L(θi) =−E ˆAt |{z} was it good? · ∇θi ...
-
[33]
State encoding/Data encoding (non-parametric): Before the quantum circuit can process the agent’s observation from the classical environment oi ∈R nobs, the classical data must be mapped into a quantum state. We useangle encoding; each component of oi is used directly as the rotation angle of a single-qubit gate applied to a qubit initialised in state |0⟩...
-
[34]
Parameterised quantum circuit (PQC): The PQC is the learned core of the quantum network (actor). Conceptually, it plays the same role as the hidden layers of a classical neural network; it transforms the encoded input into a representation from which an action distribution can be computed. A PQC of depthdandn q qubits consists ofdrepeatedvariational layer...
-
[35]
Classical readout layer: Once the PQC has processed the input, we need to extract a classical action probability vector from the quantum state. We measure a quantum system usingcomputational basis, that is, checking if it is in state |0⟩ or |1⟩? For nq qubits, there are 2nq possible measurement outcomes (bitstrings). The probability of each outcome is giv...
-
[36]
Is the quantum variant winning because of quantum effects, or simply because it has more parameters?
Bell state preparation (zero parameters): In entangled QMARL variants, the N agent qubits are initialised in a pre-entangled Bell state before the VQC layers run. A Bell state is a specific two-qubit quantum state with maximal entanglement. This state has the property that measuring one qubit instantaneouslydetermines the outcome of measuring the other, r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.