Recognition: 2 theorem links
· Lean TheoremOn the Burden of Achieving Fairness in Conformal Prediction
Pith reviewed 2026-05-15 02:35 UTC · model grok-4.3
The pith
Pooled calibration in conformal prediction creates irreducible coverage distortion across groups set by quantile heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
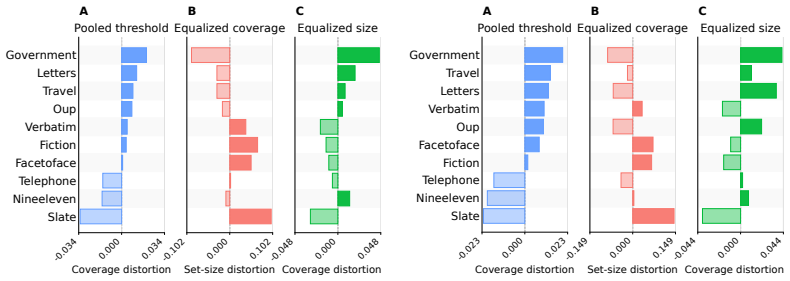
Pooled calibration incurs irreducible group-wise coverage distortion at a scale set by cross-group quantile heterogeneity. The two leading fairness definitions, equalized coverage and equalized set size, are in fundamental tension. The choice between treating groups separately or pooling them determines whether the resulting distortion appears in the coverage or the size dimension.
What carries the argument
A conservation law relating pooled and group-wise coverage probabilities derived from the population score distributions in split conformal prediction.
Load-bearing premise
The derivations rely on population-level score distributions for each group being well-defined and independent of the training process.
What would settle it
Measure group-wise coverage and average set sizes on a dataset with known score distributions under both pooled and separate calibration; if the observed coverage gaps exactly match the quantile-heterogeneity lower bound (within finite-sample error), the bound holds, while systematic deviation would falsify it.
Figures
















read the original abstract
Conformal prediction is often calibrated with a single pooled threshold, but this can hide cross-group heterogeneity in score distributions and distort group-wise coverage. We study this phenomenon through the population score distributions underlying split conformal calibration. First, we derive a conservation law and lower bound showing that pooled calibration incurs irreducible group-wise coverage distortion at a scale set by cross-group quantile heterogeneity. Second, we demonstrate that the two leading fairness definitions for conformal prediction, Equalized Coverage and Equalized Set Size, are fundamentally in tension. Third, we quantify the cost of moving between policies which treat groups separately or pool them. Experiments on synthetic and real data confirm the same bidirectional trade-off after finite-sample calibration. Our results show that, for the policy families studied here, calibration choice does not remove cross-group heterogeneity; it determines whether the resulting distortion appears in the coverage or size dimension, providing a principled lens for analyzing fairness-oriented calibration choices in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pooled calibration in split conformal prediction incurs an irreducible group-wise coverage distortion whose scale is set by cross-group quantile heterogeneity, as formalized by a derived population-level conservation law and lower bound. It further shows that Equalized Coverage and Equalized Set Size are in fundamental tension, quantifies the cost of moving between separate-group and pooled policies, and validates the bidirectional coverage/size trade-off on synthetic and real data after finite-sample calibration.
Significance. If the central derivations hold, the work supplies a principled population-level explanation for why fairness-oriented calibration choices in conformal prediction merely relocate rather than eliminate cross-group heterogeneity. This is a useful lens for practitioners and offers falsifiable predictions about the location of distortion under different policies.
major comments (2)
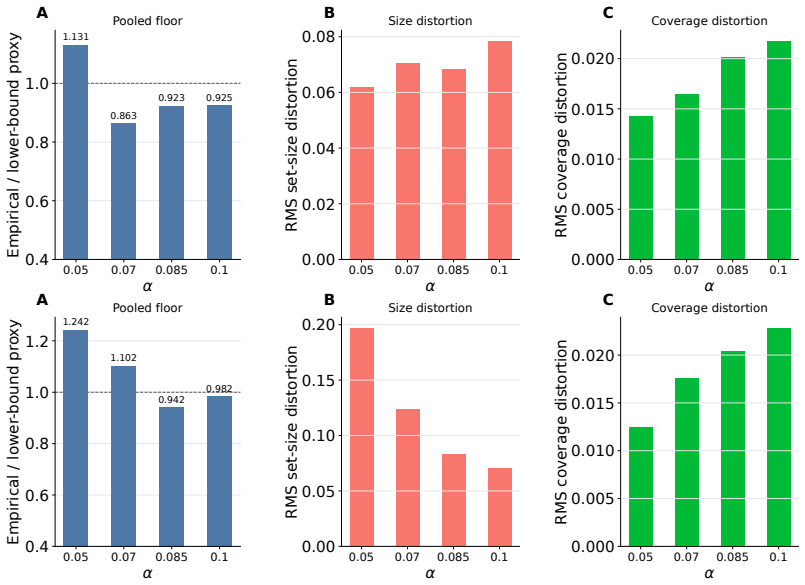
- [§3] §3 (conservation law and lower bound): The derivations start from population score distributions and produce an irreducible term controlled by quantile heterogeneity. However, the finite-sample experiments in §4 replace population quantiles with empirical ones computed on finite calibration sets per group; the manuscript does not isolate or bound the additive estimation error component separately from the claimed population term, leaving open whether observed distortions are dominated by the irreducible heterogeneity or by finite-sample artifacts.
- [§4] §4 (experiments): The synthetic and real-data results demonstrate the bidirectional trade-off, but without controls that vary calibration-set size while holding population heterogeneity fixed, or that report separate estimates of the population component, it is difficult to confirm that the population conservation law dominates the observed finite-sample distortions as asserted in the abstract.
minor comments (2)
- [Introduction] The transition from the population derivations to the finite-sample setting could be stated more explicitly in the introduction or §2 to clarify how the lower bound is expected to manifest after empirical quantile estimation.
- [§3] Notation for group-wise quantiles and coverage deviations is introduced in §3 but could be summarized in a single table for quick reference when reading the experimental results.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the distinction between the population-level derivations and the finite-sample experiments. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (conservation law and lower bound): The derivations start from population score distributions and produce an irreducible term controlled by quantile heterogeneity. However, the finite-sample experiments in §4 replace population quantiles with empirical ones computed on finite calibration sets per group; the manuscript does not isolate or bound the additive estimation error component separately from the claimed population term, leaving open whether observed distortions are dominated by the irreducible heterogeneity or by finite-sample artifacts.
Authors: The derivations in §3 are explicitly population-level and yield an exact conservation law together with a lower bound on coverage distortion that depends only on cross-group quantile heterogeneity. The §4 experiments are intended to show that the same qualitative bidirectional trade-off appears once the population quantiles are replaced by their finite-sample conformal estimates. We acknowledge that the manuscript does not supply a separate analytic bound on the quantile estimation error. In the revision we will add a short paragraph in §4 (and a corresponding remark in the appendix) that (i) recalls the known consistency of conformal quantiles, (ii) notes that the observed distortions remain aligned in sign and approximate magnitude with the population lower bound even for moderate calibration sizes, and (iii) states that a full finite-sample decomposition is left for future work. This clarifies the relationship without altering the central claims. revision: partial
-
Referee: [§4] §4 (experiments): The synthetic and real-data results demonstrate the bidirectional trade-off, but without controls that vary calibration-set size while holding population heterogeneity fixed, or that report separate estimates of the population component, it is difficult to confirm that the population conservation law dominates the observed finite-sample distortions as asserted in the abstract.
Authors: The current experiments fix calibration-set sizes that are typical in practice and already vary effective sample sizes across groups in the synthetic design. While we agree that an explicit sweep over calibration size (holding the underlying score distributions fixed) would strengthen the isolation of the population term, the existing results are consistent with the population predictions across both synthetic and real data. In the revision we will add a supplementary figure that varies calibration-set size on the synthetic data and overlays the empirical distortion against the population lower bound; this will make the convergence behavior explicit and address the concern directly. revision: yes
Circularity Check
Derivation from population score distributions is self-contained
full rationale
The paper's central derivation begins from assumed population-level score distributions per group and derives a conservation law plus lower bound on coverage distortion driven by cross-group quantile heterogeneity. This step is a direct mathematical consequence of the definitions of pooled vs. group-wise quantiles and does not reduce to fitted parameters, self-referential quantities, or prior self-citations. Subsequent claims about tension between Equalized Coverage and Equalized Set Size follow from the same population quantities. Finite-sample experiments are presented as separate empirical confirmation rather than part of the derivation. No load-bearing step matches any of the enumerated circularity patterns; the population analysis stands independently of the finite-sample calibration details.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Population score distributions exist and are distinct across groups
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 (Pooled-threshold uncertainty relation): Var(εG(q)) ≥ meff(q)² Var(qG) under local density lower bounds.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Uncer- tainty sets for image classifiers using conformal prediction
Anastasios Nikolas Angelopoulos, Stephen Bates, Michael Jordan, and Jitendra Malik. Uncer- tainty sets for image classifiers using conformal prediction. InInternational Conference on Learning Representations, 2021
work page 2021
-
[2]
Francis Bach. A Convex Loss Function for Set Prediction with Optimal Trade-offs Between Size and Conditional Coverage.arXiv:2512.19142, 2025
-
[3]
Alexandra Chouldechova. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments.Big data, 5(2):153–163, 2017. doi: 10.1089/big.2016.0047
-
[4]
Cresswell, Yi Sui, Bhargava Kumar, and Noël V ouitsis
Jesse C. Cresswell, Yi Sui, Bhargava Kumar, and Noël V ouitsis. Conformal prediction sets improve human decision making. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[5]
Cresswell, Bhargava Kumar, Yi Sui, and Mouloud Belbahri
Jesse C. Cresswell, Bhargava Kumar, Yi Sui, and Mouloud Belbahri. Conformal prediction sets can cause disparate impact. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[6]
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting
Maria De-Arteaga, Alexey Romanov, Hanna Wallach, Jennifer Chayes, Christian Borgs, Alexan- dra Chouldechova, Sahin Geyik, Krishnaram Kenthapadi, and Adam Tauman Kalai. Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting. InProceedings of the Conference on Fairness, Accountability, and Transparency, page 120–128, 2019. ISBN ...
-
[7]
Aryeh Dvoretzky, Jack Kiefer, and Jacob Wolfowitz. Asymptotic minimax character of the sam- ple distribution function and of the classical multinomial estimator.The Annals of Mathematical Statistics, pages 642–669, 1956
work page 1956
-
[8]
Rina Foygel Barber, Emmanuel J Candès, Aaditya Ramdas, and Ryan J Tibshirani. The limits of distribution-free conditional predictive inference.Information and Inference: A Journal of the IMA, 10(2):455–482, 2021
work page 2021
-
[9]
Rina Foygel Barber, Emmanuel J Candès, Aaditya Ramdas, and Ryan J Tibshirani. De finetti’s theorem and related results for infinite weighted exchangeable sequences.Bernoulli, 30(4): 3004–3028, 2024
work page 2024
-
[10]
V olume optimality in conformal prediction with structured prediction sets
Chao Gao, Liren Shan, Vaidehi Srinivas, and Aravindan Vijayaraghavan. V olume optimality in conformal prediction with structured prediction sets. InProceedings of the 42nd International Conference on Machine Learning, volume 267, pages 18495–18527, 2025
work page 2025
-
[11]
Isaac Gibbs, John J Cherian, and Emmanuel J Candès. Conformal prediction with conditional guarantees.Journal of the Royal Statistical Society Series B: Statistical Methodology, 87(4): 1100–1126, 03 2025. ISSN 1369-7412. doi: 10.1093/jrsssb/qkaf008
-
[12]
Counterfactually fair conformal prediction
Ozgur Guldogan, Neeraj Sarna, Yuanyuan Li, and Michael Berger. Counterfactually fair conformal prediction. InProceedings of The 29th International Conference on Artificial Intelligence and Statistics, 2026
work page 2026
-
[13]
FACET: Fairness in computer vision evaluation benchmark
Laura Gustafson, Chloe Rolland, Nikhila Ravi, Quentin Duval, Aaron Adcock, Cheng-Yang Fu, Melissa Hall, and Candace Ross. FACET: Fairness in computer vision evaluation benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20370– 20382, 2023
work page 2023
-
[14]
Equality of opportunity in supervised learning
Moritz Hardt, Eric Price, and Nati Srebro. Equality of opportunity in supervised learning. In Advances in Neural Information Processing Systems 29, pages 3315–3323, 2016
work page 2016
-
[15]
Inherent trade-offs in the fair determination of risk scores
Jon Kleinberg, Sendhil Mullainathan, and Manish Raghavan. Inherent trade-offs in the fair determination of risk scores. In8th Innovations in Theoretical Computer Science Conference, volume 67, pages 43:1–43:23, 2017. doi: 10.4230/LIPIcs.ITCS.2017.43
-
[16]
Claire Lazar Reich and Suhas Vijaykumar. A Possibility in Algorithmic Fairness: Can Calibra- tion and Equal Error Rates Be Reconciled? In2nd Symposium on Foundations of Responsible Computing, volume 192, pages 4:1–4:21, 2021. doi: 10.4230/LIPIcs.FORC.2021.4. 11
-
[17]
Meichen Liu, Lei Ding, Dengdeng Yu, Wulong Liu, Linglong Kong, and Bei Jiang. Conformal- ized fairness via quantile regression.Advances in Neural Information Processing Systems, 35: 11561–11572, 2022
work page 2022
- [18]
-
[19]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 8748–8763, 2021
work page 2021
-
[20]
Yaniv Romano, Rina Foygel Barber, Chiara Sabatti, and Emmanuel Candès. With malice toward none: Assessing uncertainty via equalized coverage.Harvard Data Science Review, 2(2):4, 2020
work page 2020
-
[21]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[22]
A Tutorial on Conformal Prediction.Journal of Machine Learning Research, 9(12):371–421, 2008
Glenn Shafer and Vladimir V ovk. A Tutorial on Conformal Prediction.Journal of Machine Learning Research, 9(12):371–421, 2008
work page 2008
-
[23]
Bernard W Silverman.Density estimation for statistics and data analysis. Routledge, 2018
work page 2018
-
[24]
Davut Emre Tasar. The coverage-deferral trade-off: Fairness implications of conformal predic- tion in human-in-the-loop decision systems.Preprints, 2025. doi: 10.20944/preprints202512. 2631.v1
-
[25]
Vadlamani, Anutam Srinivasan, Pranav Maneriker, Ali Payani, and Srinivasan Parthasarathy
Aditya T. Vadlamani, Anutam Srinivasan, Pranav Maneriker, Ali Payani, and Srinivasan Parthasarathy. A generic framework for conformal fairness. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[26]
Mondrian confidence machine.Technical Report, 2003
Vladimir V ovk, David Lindsay, Ilia Nouretdinov, and Alex Gammerman. Mondrian confidence machine.Technical Report, 2003
work page 2003
-
[27]
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, 2005
work page 2005
-
[28]
Fangxin Wang, Lu Cheng, Ruocheng Guo, Kay Liu, and Philip S Yu. Equal opportunity of coverage in fair regression.Advances in Neural Information Processing Systems, 36:7743–7755, 2023
work page 2023
-
[29]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122, 2018. doi: 10.18653/v1/N18-1101
-
[30]
Yanfei Zhou and Matteo Sesia. Conformal classification with equalized coverage for adaptively selected groups.Advances in Neural Information Processing Systems, 37:108760–108823, 2024. 12 Appendix Contents • Appendix A: Technical Discussion • Appendix B: Proofs of Theoretical Results • Appendix C: Additional Experimental Details • Appendix D:Bias in BiosE...
work page 2024
-
[31]
Under exact conservation,δ(q) = 0, we haveΩ o(q) Ωu(q)≥B 2 K. When q is the pooled population quantile and the mixture CDF FS is continuous at q, Theorem 1 givesδ(q) = 0, so the exact-conservation form in part 3 is the relevant pooled-calibration case. Theorem 6 refines Theorem 1 from a signed additive conservation law to a magnitude lower bound. The prod...
-
[32]
shows that in binary settings, when two groups have different base rates,πg =P(Y= 1|G=g) , predictive parity, i.e., equalPPVg =P(Y= 1| ˆY= 1, G=g) across groups, cannot generally hold simultaneously with equalized error profiles matching the false positive rates FPRg =P( ˆY= 1| Y= 0, G=g) and the true positive rates TPRg =P( ˆY= 1|Y= 1, G=g) . The incompa...
-
[33]
More precisely, for every g∈ H r \ {r},ℓ g(qg)−ℓ r(qr)≥c g >0
The group-wise thresholds {qg}g∈G, which achieve an exact group-wise coverage level 1−α , necessarily induce a nonzero cross-group disparity in expected set size. More precisely, for every g∈ H r \ {r},ℓ g(qg)−ℓ r(qr)≥c g >0. Consequently, max g,g ′∈G |ℓg(qg)−ℓ g′(qg′)| ≥max g∈Hr\{r} cg >0.(14) Therefore, exact group-wise coverage cannot simultaneously sa...
-
[34]
The restricted mean squared cross-group size disparity relative to the reference grouprsatisfies D2 r = X g∈Hr\{r} pg(ℓg(qg)−ℓ r(qr))2 ≥ X g∈Hr\{r} pgc2 g >0. (15) 17 Proof. The group-wise thresholds {qg}g∈G achieve equalized coverage at level 1−α across groups. Now fix any g∈ H r \ {r}. By definition of Hr, we have qg ≥q r. Since t7→ℓ g(t) is non-decreas...
-
[35]
Custom license, see dataset download agreement,
Under exact conservation,δ(q) = 0, we haveΩ o(q) Ωu(q)≥B 2 K. Proof. For any group with q≥q g, we have εg(q)≥m g(q−q g). Similarly, for any group with q≤q g, we haveε g(q)≤m g(q−q g). Therefore, we have Ωo(q)≥ X g wg(q−q g)+ =:A +(q) Ω u(q)≥ X g wg(qg −q) + =:A −(q).(37) At the crossing point¯qm, A+(¯qm) =A −(¯qm) = 1 2 X g wg|qg −¯qm|=B K.(38) Since A+(q...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.