Recognition: 2 theorem links
· Lean TheoremDiagnosing and Correcting Concept Omission in Multimodal Diffusion Transformers
Pith reviewed 2026-05-15 02:42 UTC · model grok-4.3
The pith
Text embeddings in multimodal diffusion transformers encode a detectable omission signal that can be amplified to include missing concepts in generated images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
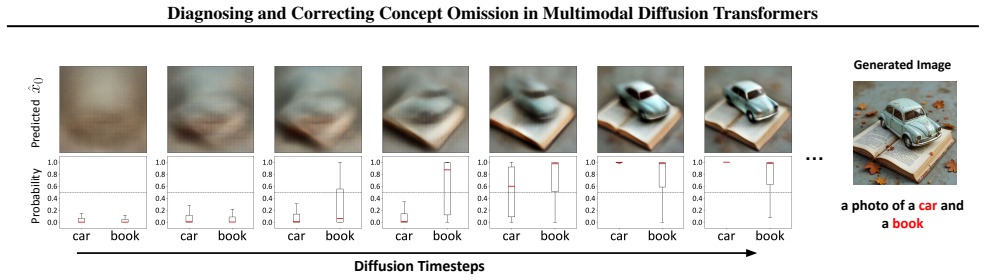
By performing linear probing on text tokens, text embeddings can distinguish a characteristic omission signal representing the absence of target concepts. Leveraging this insight, Omission Signal Intervention amplifies the omission signal to actively catalyze the generation of missing concepts. Comprehensive experiments on FLUX.1-Dev and SD3.5-Medium demonstrate that OSI significantly alleviates concept omission even in extreme scenarios.
What carries the argument
Omission Signal Intervention (OSI), which amplifies the omission signal identified by linear probing on text tokens to promote inclusion of missing concepts during diffusion.
If this is right
- OSI reduces concept omission rates on both FLUX.1-Dev and SD3.5-Medium without any retraining.
- The intervention works by directly modifying text embeddings at inference time.
- The method succeeds even when prompts specify many concepts or unusual combinations.
- Linear probing on tokens provides a diagnostic tool that predicts omission before generation.
Where Pith is reading between the lines
- The same linear-probing approach could diagnose other generation failures such as attribute misbinding or spatial errors.
- Concept presence appears to occupy a roughly linear direction in the text embedding space of these models.
- OSI might combine with existing prompt-optimization techniques to further raise overall prompt adherence.
- If similar omission signals appear in video or audio diffusion models, the intervention could transfer with minimal changes.
Load-bearing premise
The omission signal detected by linear probing is causal for concept omission, and amplifying it will reliably add the missing concepts without introducing artifacts or lowering image quality.
What would settle it
Running OSI on a set of prompts that previously showed omissions and finding no reduction in omission rate or a drop in image quality metrics would falsify the claim that amplifying the signal catalyzes correct generation.
Figures






read the original abstract
Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-to-image generation, yet they frequently suffer from concept omission, where specified objects or attributes fail to emerge in the generated image. By performing linear probing on text tokens, we demonstrate that text embeddings can distinguish a characteristic `omission signal' representing the absence of target concepts. Leveraging this insight, we propose Omission Signal Intervention (OSI), which amplifies the omission signal to actively catalyze the generation of missing concepts. Comprehensive experiments on FLUX.1-Dev and SD3.5-Medium demonstrate that OSI significantly alleviates concept omission even in extreme scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that linear probing on text tokens in Multimodal Diffusion Transformers (MM-DiTs) can identify a characteristic 'omission signal' in embeddings that distinguishes the absence of target concepts. It introduces Omission Signal Intervention (OSI) to amplify this signal during generation, thereby correcting concept omissions. The work asserts that comprehensive experiments on FLUX.1-Dev and SD3.5-Medium demonstrate that OSI significantly alleviates omission even in extreme scenarios.
Significance. If the probed direction proves causal and OSI reliably inserts missing concepts without introducing artifacts or degrading fidelity, the diagnostic probing technique and intervention would constitute a practical advance for improving the reliability of text-to-image DiT models. The linear-probing diagnostic itself provides an interpretable lens on embedding geometry that could generalize beyond the specific correction method.
major comments (2)
- [Abstract] Abstract: the assertion of 'comprehensive experiments' on FLUX.1-Dev and SD3.5-Medium is unsupported by any reported metrics, baselines, controls, quantitative results, or statistical tests, so the central claim that OSI alleviates concept omission cannot be evaluated from the supplied information.
- [Method] Method (linear probing and OSI definition): the manuscript shows only that a linear classifier can separate omission cases in frozen text embeddings, but supplies no controlled interventions, ablations, or causal tests (e.g., orthogonal directions or counterfactual prompts) to establish that scaling the probed direction inside cross-attention is the operative mechanism rather than a downstream correlate of prompt statistics.
minor comments (1)
- [Method] The precise mathematical definition of the omission signal vector and the exact scaling operation performed by OSI should be stated with equations to permit reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped clarify the presentation of our results. We address each major comment below and have revised the manuscript to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'comprehensive experiments' on FLUX.1-Dev and SD3.5-Medium is unsupported by any reported metrics, baselines, controls, quantitative results, or statistical tests, so the central claim that OSI alleviates concept omission cannot be evaluated from the supplied information.
Authors: We agree that the abstract should report concrete metrics to support its claims. Although the full manuscript contains quantitative results, baselines, controls, and statistical tests in Sections 4 and 5, the abstract did not include specific numbers. We have revised the abstract to include key quantitative findings, such as omission rate reductions on both FLUX.1-Dev and SD3.5-Medium with comparisons to baselines. revision: yes
-
Referee: [Method] Method (linear probing and OSI definition): the manuscript shows only that a linear classifier can separate omission cases in frozen text embeddings, but supplies no controlled interventions, ablations, or causal tests (e.g., orthogonal directions or counterfactual prompts) to establish that scaling the probed direction inside cross-attention is the operative mechanism rather than a downstream correlate of prompt statistics.
Authors: We acknowledge the need for stronger causal evidence. The original submission included ablations on intervention strength, but to directly address causality we have added new controlled experiments in the revised manuscript: interventions along orthogonal directions (which yield no improvement) and tests with counterfactual prompts that explicitly vary concept presence. These results, now detailed in Section 3.3, indicate the effect is specific to the probed omission direction rather than a general correlate of prompt statistics. revision: yes
Circularity Check
No significant circularity; empirical probing and intervention chain is self-contained
full rationale
The paper identifies an omission signal via linear probing on text tokens and proposes OSI to amplify it for concept insertion. This is an empirical discovery-plus-intervention pipeline with no equations or derivations that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central steps (probing to find a distinguishing direction, then scaling it) are externally testable via generation experiments on FLUX.1-Dev and SD3.5-Medium rather than tautological. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided text. The approach remains open to causal questions but does not exhibit circularity per the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probing on text tokens isolates a characteristic omission signal that is actionable for generation
invented entities (1)
-
Omission Signal Intervention (OSI)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we first compute the direction vector δ(l,h) defined by Mass Mean Shift ... δ(l,h)=E[k(t,l,h)|y=0]−E[k(t,l,h)|y=1]
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we employ linear probing ... training a classifier to detect concept omission in the embedding space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2411.14257 , year=
Do i know this entity? knowledge awareness and hallucinations in language models , author=. arXiv preprint arXiv:2411.14257 , year=
- [3]
-
[4]
arXiv preprint arXiv:2509.18096 , year=
Seg4diff: Unveiling open-vocabulary segmentation in text-to-image diffusion transformers , author=. arXiv preprint arXiv:2509.18096 , year=
-
[5]
ACM transactions on Graphics (TOG) , volume=
Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models , author=. ACM transactions on Graphics (TOG) , volume=. 2023 , publisher=
work page 2023
-
[6]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
- [8]
-
[9]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[10]
The Eleventh International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[11]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[12]
Black Forest Labs , title =
-
[13]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Geneval: An object-focused framework for evaluating text-to-image alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards understanding cross and self-attention in stable diffusion for text-guided image editing , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
MMDetection: Open MMLab Detection Toolbox and Benchmark
MMDetection: Open mmlab detection toolbox and benchmark , author=. arXiv preprint arXiv:1906.07155 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[19]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Exploring multimodal diffusion transformers for enhanced prompt-based image editing , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[21]
arXiv preprint arXiv:2507.01496 , year=
ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation , author=. arXiv preprint arXiv:2507.01496 , year=
-
[22]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Enhancing text-to-image diffusion transformer via split-text conditioning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[23]
stabilityai , title =
-
[24]
meta-llama , title =
-
[25]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Kim, Kwanyoung and Sim, Byeongsu , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
work page 2025
-
[26]
discus0434 , title =
-
[27]
European Conference on Computer Vision , pages=
Self-rectifying diffusion sampling with perturbed-attention guidance , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Improving sample quality of diffusion models using self-attention guidance , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
Advances in Neural Information Processing Systems , volume=
Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
A-star: Test-time attention segregation and retention for text-to-image synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Conform: Contrast is all you need for high-fidelity text-to-image diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
European Conference on Computer Vision , pages=
Object-conditioned energy-based attention map alignment in text-to-image diffusion models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[33]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Glide: Towards photorealistic image generation and editing with text-guided diffusion models , author=. arXiv preprint arXiv:2112.10741 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Advances in neural information processing systems , volume=
Photorealistic text-to-image diffusion models with deep language understanding , author=. Advances in neural information processing systems , volume=
-
[35]
International conference on machine learning , pages=
Zero-shot text-to-image generation , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[36]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
work page 2015
-
[37]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[38]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[39]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gligen: Open-set grounded text-to-image generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[40]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
work page 2014
-
[42]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Musiq: Multi-scale image quality transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maniqa: Multi-dimension attention network for no-reference image quality assessment , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[44]
Advances in Neural Information Processing Systems , volume=
A cat is a cat (not a dog!): Unraveling information mix-ups in text-to-image encoders through causal analysis and embedding optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[46]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked-attention mask transformer for universal image segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[47]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Advances in Neural Information Processing Systems , volume=
Comat: Aligning text-to-image diffusion model with image-to-text concept matching , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Yang, Tianyun and Li, Ziniu and Cao, Juan and Xu, Chang , booktitle =. Understanding and Mitigating Hallucination in Large Vision-Language Models via Modular Attribution and Intervention , url =
-
[51]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[52]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Perception prioritized training of diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[54]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Style-friendly snr sampler for style-driven generation , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[55]
arXiv preprint arXiv:2602.21402 , year=
FlowFixer: Towards Detail-Preserving Subject-Driven Generation , author=. arXiv preprint arXiv:2602.21402 , year=
-
[56]
Toward interactive regional understanding in vision-large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[57]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Guiding What Not to Generate: Automated Negative Prompting for Text-Image Alignment , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.