Recognition: unknown
KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
Pith reviewed 2026-05-15 02:35 UTC · model grok-4.3
The pith
KVPO aligns streaming autoregressive video generators by routing semantic variations through the KV cache and modeling policies via velocity energy in ODE space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KVPO introduces a causal-semantic exploration paradigm that relocates the source of variation from stochastic noise to the historical KV cache, constructing semantically diverse generation branches that remain strictly on the data manifold, and a velocity-field surrogate policy based on Trajectory Velocity Energy that yields a reward-weighted contrastive objective fully consistent with the native ODE formulation.
What carries the argument
Causal-semantic exploration by stochastic routing of historical KV cache entries, paired with a Trajectory Velocity Energy (TVE) velocity-field surrogate policy that quantifies branch likelihood in flow-matching velocity space.
If this is right
- Improved visual quality in the aligned video outputs
- Higher motion quality across generated sequences
- Stronger text-video alignment on both short and long horizons
- Consistent performance gains on multiple distilled autoregressive video generators
Where Pith is reading between the lines
- The KV-routing idea could transfer to aligning autoregressive models in text or audio domains where semantic coherence over long sequences matters.
- Velocity-field surrogates may serve as a general template for ODE-native reinforcement learning in other flow-matching generative systems.
- Combining KVPO with varied reward signals beyond human preferences could be tested directly on existing video generators.
Load-bearing premise
Stochastically routing historical KV entries produces semantically diverse generation branches that remain strictly on the data manifold without introducing artifacts or deviating from the model's learned distribution.
What would settle it
Generating multiple branches via KV routing and finding that they introduce visible artifacts or fall outside the original model's output distribution would falsify the exploration paradigm.
Figures














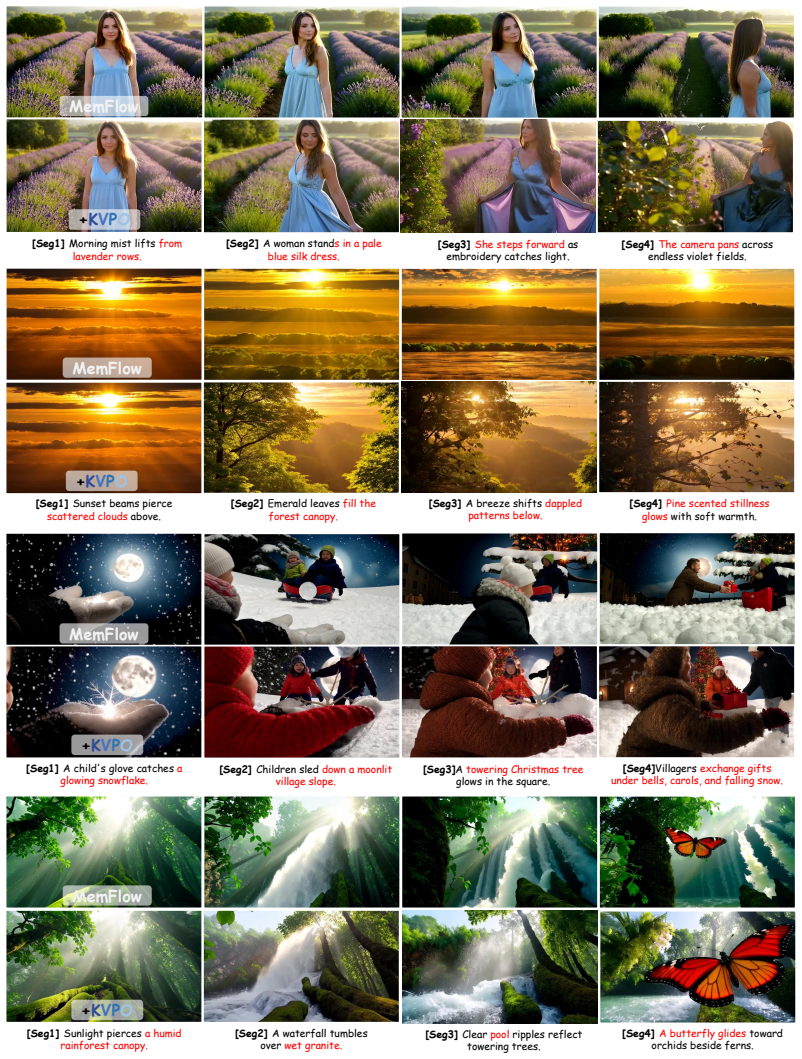




read the original abstract
Aligning streaming autoregressive (AR) video generators with human preferences is challenging. Existing reinforcement learning methods predominantly rely on noise-based exploration and SDE-based surrogate policies that are mismatched to the deterministic ODE dynamics of distilled AR models, and tend to perturb low-level appearance rather than the high-level semantic storyline progression critical for long-horizon coherence. To address these limitations, we present KVPO, an ODE-native online Group Relative Policy Optimization (GRPO) framework for aligning streaming video generators. For diversity exploration, KVPO introduces a causal-semantic exploration paradigm that relocates the source of variation from stochastic noise to the historical KV cache. By stochastically routing historical KV entries, it constructs semantically diverse generation branches that remain strictly on the data manifold. For policy modeling, KVPO introduces a velocity-field surrogate policy based on Trajectory Velocity Energy (TVE), which quantifies branch likelihood in flow-matching velocity space and yields a reward-weighted contrastive objective fully consistent with the native ODE formulation. Experiments on multiple distilled AR video generators demonstrate consistent gains in visual quality, motion quality, and text-video alignment across both single-prompt short-video and multi-prompt long-video settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. KVPO is an ODE-native online Group Relative Policy Optimization (GRPO) framework for aligning streaming autoregressive video generators with human preferences. It replaces noise-based SDE exploration with causal-semantic exploration via stochastic routing of historical KV cache entries to generate semantically diverse branches that remain on the data manifold, and introduces a Trajectory Velocity Energy (TVE) velocity-field surrogate policy that produces a reward-weighted contrastive objective consistent with native ODE/flow-matching dynamics. The abstract claims consistent gains in visual quality, motion quality, and text-video alignment on distilled AR video generators for both short single-prompt and long multi-prompt settings.
Significance. If the on-manifold invariance under KV routing and the independent grounding of TVE hold, the method could provide a semantically focused alternative to noise-based exploration, improving long-horizon coherence in video alignment without low-level perturbations. The ODE-native formulation directly addresses the mismatch between existing RL methods and distilled deterministic models, which is a relevant direction for autoregressive video generation.
major comments (3)
- [Abstract] Abstract: the claim of 'consistent gains in visual quality, motion quality, and text-video alignment' is stated without any quantitative results, baselines, error bars, or experimental details, so the magnitude and reliability of the reported improvements cannot be assessed.
- [Exploration paradigm (implied §3)] The central claim that stochastically routing historical KV entries constructs branches that remain strictly on the data manifold and preserve velocity-field consistency lacks any derivation or check; without this, the TVE surrogate and reward-weighted contrastive objective rest on an unverified invariance, and the claimed advantage over noise-based SDE exploration is not established.
- [Policy modeling (implied §4)] TVE definition and usage: Trajectory Velocity Energy is presented as quantifying branch likelihood in flow-matching velocity space to yield a consistent objective, but without the full equations it is unclear whether TVE has independent grounding or reduces to a fitted quantity, creating potential circularity in the policy modeling.
minor comments (1)
- The manuscript would benefit from including the explicit mathematical definition of TVE and the KV routing procedure in the main text rather than relying on high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent gains in visual quality, motion quality, and text-video alignment' is stated without any quantitative results, baselines, error bars, or experimental details, so the magnitude and reliability of the reported improvements cannot be assessed.
Authors: We agree that the abstract would be strengthened by including specific quantitative support. In the revised manuscript we will add concise numerical results (e.g., relative improvements in the primary metrics together with references to the corresponding tables) while preserving brevity. The full experimental results, including all baselines, error bars, and statistical details, are already reported in Section 5. revision: yes
-
Referee: [Exploration paradigm (implied §3)] The central claim that stochastically routing historical KV entries constructs branches that remain strictly on the data manifold and preserve velocity-field consistency lacks any derivation or check; without this, the TVE surrogate and reward-weighted contrastive objective rest on an unverified invariance, and the claimed advantage over noise-based SDE exploration is not established.
Authors: We acknowledge that a formal derivation of the on-manifold invariance under KV routing is not explicitly provided. Section 3 presents the conceptual argument based on the causal structure of the KV cache, but we agree a rigorous check is needed. In the revision we will insert a new subsection containing a mathematical derivation showing that stochastic KV routing preserves both manifold membership and velocity-field consistency, together with a direct comparison to noise-based SDE perturbations. revision: yes
-
Referee: [Policy modeling (implied §4)] TVE definition and usage: Trajectory Velocity Energy is presented as quantifying branch likelihood in flow-matching velocity space to yield a consistent objective, but without the full equations it is unclear whether TVE has independent grounding or reduces to a fitted quantity, creating potential circularity in the policy modeling.
Authors: The definition and derivation of TVE appear in Section 4, where it is obtained directly from the flow-matching velocity field along each trajectory and is therefore independent of the reward model. To remove any ambiguity we will expand the equations in the revision, include an explicit statement of its grounding in the ODE dynamics, and add a short paragraph clarifying that the contrastive objective follows from this definition without circularity. revision: yes
Circularity Check
No significant circularity detected; claims presented as novel constructions without reduction to inputs by definition
full rationale
The provided abstract and description introduce KVPO's causal-semantic exploration (via stochastic KV routing) and TVE surrogate policy as new mechanisms that achieve on-manifold branches and ODE-consistent objectives. No equations, self-definitions, fitted parameters renamed as predictions, or self-citation chains are exhibited that would make any central result equivalent to its inputs by construction. The on-manifold guarantee and consistency are asserted as consequences of the proposed paradigm rather than tautologically defined into the inputs. The derivation chain therefore remains self-contained against external benchmarks, with no load-bearing steps reducing to prior fitted quantities or author-specific ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Stochastically routing historical KV entries constructs semantically diverse branches that remain strictly on the data manifold
- domain assumption The velocity-field surrogate policy based on TVE is fully consistent with the native ODE formulation
invented entities (1)
-
Trajectory Velocity Energy (TVE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.16955 (2025)
He, D., Feng, G., Ge, X., Niu, Y ., Zhang, Y ., Ma, B., Song, G., Liu, Y ., Li, H.: Neighbor grpo: Contrastive ode policy optimization aligns flow models. arXiv preprint arXiv:2511.16955 (2025)
-
[2]
arXiv preprint arXiv:2603.17461 (2026)
He, D., Feng, G., Ge, X., Zhang, Y ., Ma, B., Song, G., Liu, Y ., Li, H.: Ar-copo: Align autore- gressive video generation with contrastive policy optimization. arXiv preprint arXiv:2603.17461 (2026)
-
[3]
arXiv preprint arXiv:2603.21299 (2026)
Hu, B., Qi, Z., Huang, G., Xu, Z., Zhang, R., Ye, C., Zhou, J., Li, X., Wang, J.: Identity- consistent video generation under large facial-angle variations. arXiv preprint arXiv:2603.21299 (2026)
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, J.E., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Chen, W.: Lora: Low- rank adaptation of large language models. ArXivabs/2106.09685(2021), https://api. semanticscholar.org/CorpusID:235458009
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Ji, Y ., Zhong, Z., Zhang, J., Yang, Q., Jin, X., Qin, Y ., Luo, W., Mao, S., Liu, W., Li, H.: Forcing-kv: Hybrid kv cache compression for efficient autoregressive video diffusion models (2026),https://arxiv.org/abs/2605.09681
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Lipman, Y ., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023), https://openreview.net/forum?id=PqvMRDCJT9t
work page 2023
-
[9]
arXiv preprint arXiv:2602.11146 (2026)
Liu, G., Yang, B., Zhi, Y ., Zhong, Z., Ke, L., Deng, D., Gao, H., Huang, Y ., Zhang, K., Fu, H., et al.: Beyond vlm-based rewards: Diffusion-native latent reward modeling. arXiv preprint arXiv:2602.11146 (2026)
-
[10]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y ., Liu, J., Wang, X., Wan, P., Zhang, D., Ouyang, W.: Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Improving Video Generation with Human Feedback
Liu, J., Liu, G., Liang, J., Yuan, Z., Liu, X., Zheng, M., Wu, X., Wang, Q., Xia, M., Wang, X., et al.: Improving video generation with human feedback. arXiv preprint arXiv:2501.13918 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Lu, Y ., Zeng, Y ., Li, H., Ouyang, H., Wang, Q., Cheng, K.L., Zhu, J., Cao, H., Zhang, Z., Zhu, X., et al.: Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation. arXiv preprint arXiv:2512.04678 (2025)
-
[13]
arXiv preprint arXiv:2509.24200 (2025)
Luo, J., Lin, J., Zhang, Z., Wu, B., Fang, M., Chen, L., Tang, H.: Univid: The open-source unified video model. arXiv preprint arXiv:2509.24200 (2025)
- [14]
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
work page 2023
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Yang, R., Xu, J., Li, M., Zhang, Y .W., Li, Y .K., Gao, Y ., Ma, D., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
In: International Confer- ence on Machine Learning (2023) 10
Song, Y ., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: International Confer- ence on Machine Learning (2023) 10
work page 2023
-
[18]
In: International Conference on Learning Representations (2021)
Song, Y ., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations (2021)
work page 2021
-
[19]
Wang, W., Yang, Y .: Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion models. In: Thirty-eighth Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=pYNl76onJL
work page 2024
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, Z., Yu, Z., Zhou, Z., Zhou, J., Jin, X., Hong, F.T., Ji, X., Zhu, J., Cai, C., Tang, S., et al.: Hunyuanportrait: Implicit condition control for enhanced portrait animation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15909–15919 (2025)
work page 2025
-
[21]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y ., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al.: Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
LongLive: Real-time Interactive Long Video Generation
Yang, S., Huang, W., Chu, R., Xiao, Y ., Zhao, Y ., Wang, X., Li, M., Xie, E., Chen, Y ., Lu, Y ., Chen, S.H.Y .: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
work page internal anchor Pith review arXiv 2025
-
[24]
In: Conference on Computer Vision and Pattern Recognition (2024)
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Conference on Computer Vision and Pattern Recognition (2024)
work page 2024
-
[25]
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: CVPR (2024)
work page 2024
-
[26]
Yin, T., Zhang, Q., Zhang, R., Freeman, W.T., Durand, F., Shechtman, E., Huang, X.: From slow bidirectional to fast autoregressive video diffusion models. In: CVPR (2025)
work page 2025
-
[27]
RoboStereo: Dual-Tower 4D Embodied World Models for Unified Policy Optimization
Zhang, R., Chen, G., Xu, Z., Liu, Z., Zhong, Z., Zhang, M., Zhou, J., Li, X.: Ro- bostereo: Dual-tower 4d embodied world models for unified policy optimization. arXiv preprint arXiv:2603.12639 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
arXiv preprint arXiv:2512.06628 (2025)
Zhang, R., Zhang, M., Zhou, J., Guo, Z., Liu, X., Xu, Z., Zhong, Z., Yan, P., Luo, H., Li, X.: Mind-v: Hierarchical video generation for long-horizon robotic manipulation with rl-based physical alignment. arXiv preprint arXiv:2512.06628 (2025)
-
[29]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, R., Zhou, J., Xu, Z., Liu, Z., Huang, J., Zhang, M., Sun, Y ., Li, X.: Zo3t: Zero-shot 3d-aware trajectory-guided image-to-video generation via test-time training. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 12708–12716 (2026)
work page 2026
-
[30]
Zhang, S., Xue, Z., Fu, S., Huang, J., Kong, X., Ma, Y ., Huang, H., Duan, N., Rao, A.: Astrolabe: Steering forward-process reinforcement learning for distilled autoregressive video models. arXiv preprint arXiv:2603.17051 (2026)
-
[31]
Advances in Neural Information Processing Systems36, 49842–49869 (2023)
Zhao, W., Bai, L., Rao, Y ., Zhou, J., Lu, J.: Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. Advances in Neural Information Processing Systems36, 49842–49869 (2023)
work page 2023
-
[32]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y ., Zhang, F., Zhang, Y ., He, J., Zheng, W.S., Qiao, Y ., Liu, Z.: VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Manifold-aware exploration for reinforcement learning in video generation, 2026
Zheng, M., Kong, W., Wu, Y ., Jiang, D., Ma, Y ., He, X., Lin, B., Gong, K., Zhong, Z., Bo, L., et al.: Manifold-aware exploration for reinforcement learning in video generation. arXiv preprint arXiv:2603.21872 (2026) 11 Appendix A KVPO Training Pipeline We summarize the full training procedure ofKVPO. At a high level, each iteration consists of three tig...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.