Recognition: 2 theorem links
· Lean TheoremTILT: Target-induced loss tilting under covariate shift
Pith reviewed 2026-05-15 02:25 UTC · model grok-4.3
The pith
The target-side penalty on an auxiliary predictor component induces implicit relative importance weighting that stays bounded even with disjoint supports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
At the population level, the target-side penalty on b implicitly induces relative importance weighting in terms of an estimand b*_f that is self-localized to the current error and remains uniformly bounded for any source-target pair, even those with disjoint supports. A general finite-sample oracle inequality holds and yields an end-to-end guarantee for sparse ReLU networks.
What carries the argument
Decomposition of the source predictor as f + b with a penalty applied to b on target inputs.
If this is right
- The fit f serves as an effective target predictor improving over source-only training.
- Performance gains hold over exact importance weighting and density-ratio baselines.
- The approach gives guarantees for training sparse ReLU networks under covariate shift.
- Finite-sample oracle inequality on the excess risk is established.
Where Pith is reading between the lines
- The method could apply to other base learners beyond neural networks.
- Self-localization of the weighting might allow better handling of varying shift severity.
- Extensions to semi-supervised settings where some target labels are available could be explored.
Load-bearing premise
The analysis assumes that penalizing the auxiliary component b on target data produces a useful implicit weighting for the main predictor f without needing support overlap or explicit density estimation.
What would settle it
Observing that the induced weighting becomes unbounded or that target performance does not improve in settings with disjoint supports would challenge the central claim.
Figures



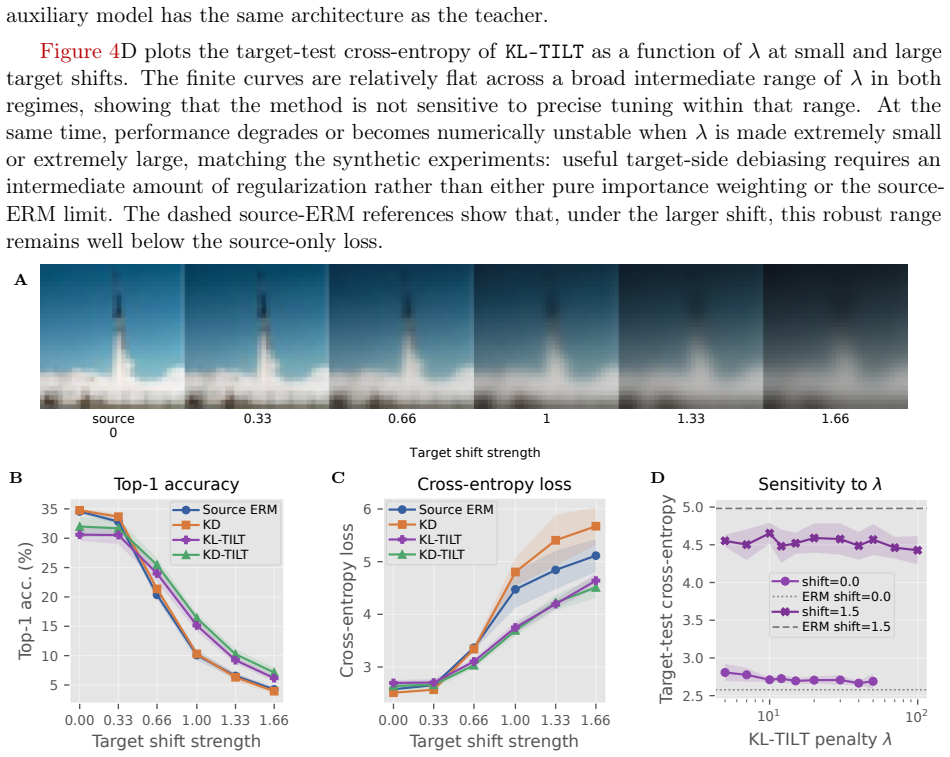






read the original abstract
We introduce and analyze Target-Induced Loss Tilting (TILT) for unsupervised domain adaptation under covariate shift. It is based on a novel objective function that decomposes the source predictor as $f+b$, fits $f+b$ on labeled source data while simultaneously penalizing the auxiliary component $b$ on unlabeled target inputs. The resulting fit $f$ is deployed as the final target predictor. At the population level, we show that this target-side penalty implicitly induces relative importance weighting at the population level, but in terms of an estimand $b^*_f$ that is self-localized to the current error, and remains uniformly bounded for any source-target pair (even those with disjoint supports). We prove a general finite-sample oracle inequality on the excess risk, and use it to give an end-to-end guarantee for training with sparse ReLU networks. Experiments on controlled regression problems and shifted CIFAR-100 distillation show that TILT improves target-domain performance over source-only training, exact importance weighting, and relative density-ratio baselines, with a stable dependence on the regularization parameter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Target-Induced Loss Tilting (TILT) for unsupervised domain adaptation under covariate shift. The method decomposes the predictor as f + b, fits f + b to labeled source data while applying a penalty to the auxiliary b on unlabeled target inputs, and deploys the resulting f as the target predictor. At the population level, the target penalty is shown to induce relative importance weighting via a self-localized estimand b*_f that is claimed to remain uniformly bounded for arbitrary source-target pairs (including disjoint supports). A general finite-sample oracle inequality is proved and specialized to yield end-to-end excess-risk guarantees for sparse ReLU networks. Experiments on synthetic regression and shifted CIFAR-100 distillation demonstrate improved target performance relative to source-only training, exact importance weighting, and density-ratio baselines, with stable behavior in the regularization parameter.
Significance. If the uniform boundedness of b*_f and the oracle inequality hold, TILT supplies a theoretically grounded alternative to explicit density-ratio estimation that does not require overlapping supports. The end-to-end sparse-ReLU guarantee would be a concrete advance for neural-network domain adaptation, and the empirical gains over standard baselines indicate practical utility when the regularization parameter is chosen reasonably.
major comments (1)
- Abstract and population-level analysis (the claim that b*_f is uniformly bounded for any source-target pair, including disjoint supports): the finite-sample oracle inequality and the subsequent sparse-ReLU guarantee rely on constants controlled by this bound. When supports are disjoint the population objective decouples; for any function class rich enough to approximate the residual (including the sparse ReLU networks used in the end-to-end result), b*_f can drive the source term to zero by setting b ≈ y - f on the source support while b ≈ 0 on the target support. Consequently |b*_f| scales with the size of the residual of f and is not uniformly bounded independently of f. This appears to threaten the claimed bound and the validity of the oracle inequality constants. Please supply the precise derivation establishing uniform boundedness or state any additional assumptions that prevent the
minor comments (2)
- Notation: the distinction between the population b*_f and its finite-sample estimator is not always explicit in the experimental section; adding a short clarifying sentence would improve readability.
- Experiments: the CIFAR-100 distillation protocol would benefit from an explicit statement of the number of random seeds and whether the reported improvements are statistically significant under a paired test.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on the population-level analysis. We address the concern regarding the uniform boundedness of b*_f below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [—] Abstract and population-level analysis (the claim that b*_f is uniformly bounded for any source-target pair, including disjoint supports): the finite-sample oracle inequality and the subsequent sparse-ReLU guarantee rely on constants controlled by this bound. When supports are disjoint the population objective decouples; for any function class rich enough to approximate the residual (including the sparse ReLU networks used in the end-to-end result), b*_f can drive the source term to zero by setting b ≈ y - f on the source support while b ≈ 0 on the target support. Consequently |b*_f| scales with the size of the residual of f and is not uniformly bounded independently of f. This appears to threaten the claimed bound and the validity of the oracle inequality constants. Please supply the precise derivation establishing uniform boundedness or state any additional assumptions that prevent
Authors: We thank the referee for this insightful observation. Upon closer examination, the decoupling does occur for disjoint supports when the function class is rich enough to fit the residual on the source support independently. The self-localized nature of b*_f means it approximates the residual only where needed, but the magnitude is indeed tied to the current error of f. The original claim of uniform boundedness independent of f was overstated. We will revise the manuscript to remove the claim of uniform boundedness for arbitrary f and instead derive a bound that depends on the excess risk of f or assume bounded residuals (e.g., via bounded labels and Lipschitz losses). This will adjust the constants in the oracle inequality to be explicit in terms of the approximation quality. The end-to-end guarantee for sparse ReLU networks will be updated to reflect this dependence, which is common in oracle inequalities. We believe this clarifies the analysis without invalidating the core contribution. Revision will be made in the population analysis section and the abstract. revision: yes
Circularity Check
Self-referential b*_f makes induced weighting definitional by construction
specific steps
-
self definitional
[Abstract]
"At the population level, we show that this target-side penalty implicitly induces relative importance weighting at the population level, but in terms of an estimand b^*_f that is self-localized to the current error, and remains uniformly bounded for any source-target pair (even those with disjoint supports)."
The claimed induction occurs 'in terms of' b*_f, where b*_f is the optimal b for the fixed f in the objective that decomposes the predictor as f + b and penalizes b on target data. The weighting effect is therefore equivalent to the definition of b* as the argmin over b, rendering the population result self-definitional rather than a non-tautological first-principles derivation.
full rationale
The paper's population-level claim identifies the target penalty as inducing relative importance weighting via the estimand b*_f. However, b*_f is defined directly as the auxiliary minimizer for fixed f in the decomposed objective, so the induction reduces to the objective's own construction rather than an independent derivation. The subsequent oracle inequality and sparse ReLU guarantees build on this with additional analysis and do not collapse entirely, yielding moderate circularity. No fitted-input predictions, self-citation chains, or uniqueness theorems are load-bearing.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization parameter lambda
axioms (1)
- domain assumption Covariate shift: the conditional distribution of labels given inputs is the same in source and target, only the marginal input distribution changes.
invented entities (1)
-
auxiliary component b
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
inf_b 1/λ A(f,b) = E²_λ(f) with b*_f(x) := -v_λ(x)(f(x)-f*(x)), v_λ(x) := p(x)/(p(x)+λq(x))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 oracle inequality on E²_λ(bf) via metric entropy of F+B and B
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. Tyrrell Rockafellar and Ren. Prox-regular functions in variational analysis , journal =
-
[2]
Introduction to Nonparametric Estimation , author =. 2009 , publisher =
work page 2009
- [3]
-
[4]
Foundations and Trends in Optimization , volume =
Proximal Algorithms , author =. Foundations and Trends in Optimization , volume =. 2014 , publisher =
work page 2014
-
[5]
Proceedings of the 29th Annual Conference on Learning Theory , series =
Benefits of Depth in Neural Networks , author =. Proceedings of the 29th Annual Conference on Learning Theory , series =. 2016 , editor =
work page 2016
- [6]
- [7]
-
[8]
Convex Analysis and Monotone Operator Theory in Hilbert Spaces , author=. 2017 , publisher=
work page 2017
- [9]
- [10]
-
[11]
G. Raskutti and M. J. Wainwright and B. Yu , TITLE =. Journal of Machine Learning Research , VOLUME =. 2014 , TOPIC =
work page 2014
-
[12]
A. W. van der Vaart and J. Wellner. Weak Convergence and Empirical Processes. 1996
work page 1996
- [13]
-
[14]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations , author=. ICLR , year=
-
[15]
The Annals of Statistics , volume=
Additive Logistic Regression: A Statistical View of Boosting , author=. The Annals of Statistics , volume=
-
[16]
The Annals of Statistics , volume=
Boosting with Early Stopping: Convergence and Consistency , author=. The Annals of Statistics , volume=
-
[17]
Journal of the American Statistical Association , volume=
Boosting with the L2 Loss: Regression and Classification , author=. Journal of the American Statistical Association , volume=
-
[18]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[19]
Born Again Trees , author=
-
[20]
Proceedings of Machine Learning Research , volume=
Born-Again Tree Ensembles , author=. Proceedings of Machine Learning Research , volume=
-
[21]
Proceedings of Machine Learning Research , volume=
Born-Again Neural Networks , author=. Proceedings of Machine Learning Research , volume=
-
[22]
Distilling a Neural Network Into a Soft Decision Tree
Distilling a Neural Network Into a Soft Decision Tree , author=. arXiv preprint arXiv:1711.09784 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Model Compression , author=. Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year=
-
[25]
Advances in Neural Information Processing Systems 27 (NeurIPS) , year=
Do Deep Nets Really Need to be Deep? , author=. Advances in Neural Information Processing Systems 27 (NeurIPS) , year=
-
[26]
Advances in Neural Information Processing Systems (NeurIPS) , year=
When Does Label Smoothing Help? , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[27]
Self-Training with Noisy Student Improves ImageNet Classification , author=. CVPR , year=
-
[28]
Certainty Driven Consistency Loss on Multi-Teacher Networks for Semi-Supervised Learning , author=. Pattern Recognition , volume=. 2021 , publisher=
work page 2021
-
[29]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 1703.01780 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in Neural Information Processing Systems (NeurIPS) , year=
The Convergence Rate of Neural Networks for Learned Functions of Different Frequencies , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
- [31]
- [32]
-
[33]
IEEE Transactions on Information Theory , volume=
Probability of error of some adaptive pattern-recognition machines , author=. IEEE Transactions on Information Theory , volume=
- [34]
-
[35]
Journal of Machine Learning Research (JMLR) , volume=
A PAC-style model for learning from labeled and unlabeled data , author=. Journal of Machine Learning Research (JMLR) , volume=
-
[36]
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence , volume =
Sohn, Kihyuk and Berthelot, David and Carlini, Nicholas and Zhang, Zizhao and Zhang, Han and Raffel, Colin A and Cubuk, Ekin Dogus and Kurakin, Alexey and Li, Chun-Liang , booktitle =. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence , volume =
-
[37]
International Conference on Machine Learning (ICML) , pages=
Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation , author=. International Conference on Machine Learning (ICML) , pages=
-
[38]
International Conference on Learning Representations (ICLR) , year=
Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data , author=. International Conference on Learning Representations (ICLR) , year=
-
[39]
Proceedings of the 37th International Conference on Machine Learning (ICML) , pages =
Understanding Self-Training for Gradual Domain Adaptation , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , pages =. 2020 , volume =
work page 2020
-
[40]
A theory of learning from different domains , author=. Machine Learning , volume=
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Correcting sample selection bias by unlabeled data , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[42]
Journal of Machine Learning Research , volume=
Covariate shift adaptation by importance weighted cross validation , author=. Journal of Machine Learning Research , volume=
-
[43]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Learning with Mismatching Distributions , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[44]
The Annals of Statistics , volume=
Arcing classifier (with discussion and a rejoinder by the author) , author=. The Annals of Statistics , volume=
-
[45]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[46]
Active learning of convex loss functions with margins , author=. Neurocomputing , volume=
-
[47]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Frequency principle: Fourier analysis sheds light on deep neural networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[48]
Communications in Computational Physics , volume=
Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks , author=. Communications in Computational Physics , volume=. 2020 , publisher=
work page 2020
-
[49]
The Annals of Statistics , volume=
Consistent nonparametric regression , author=. The Annals of Statistics , volume=
-
[50]
Foundations of Computational Mathematics , volume=
Optimal rates for the regularized least squares algorithm , author=. Foundations of Computational Mathematics , volume=
-
[51]
Unsupervised Word Sense Disambiguation Rivaling Supervised Methods , author=. Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[52]
International Conference on Machine Learning (ICML) , pages=
On the Spectral Bias of Neural Networks , author=. International Conference on Machine Learning (ICML) , pages=. 2019 , organization=
work page 2019
-
[53]
Advances in Neural Information Processing Systems (NIPS) , volume=
Boosting Algorithms as Gradient Descent , author=. Advances in Neural Information Processing Systems (NIPS) , volume=
-
[54]
Conference on Learning Theory (COLT) , pages=
Marginal Singularity, and the Benefits of Covariance Shift , author=. Conference on Learning Theory (COLT) , pages=. 2018 , organization=
work page 2018
-
[55]
International Conference on Machine Learning (ICML) , pages=
A new similarity measure for covariate shift with applications to nonparametric regression , author=. International Conference on Machine Learning (ICML) , pages=
-
[56]
Journal of Statistical Planning and Inference , volume=
Improving Predictive Inference Under Covariate Shift by Weighting the Log-Likelihood Function , author=. Journal of Statistical Planning and Inference , volume=. 2000 , publisher=
work page 2000
- [57]
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[59]
Journal of Machine Learning Research (JMLR) , volume=
Domain-Adversarial Training of Neural Networks , author=. Journal of Machine Learning Research (JMLR) , volume=
-
[60]
International Conference on Learning Representations (ICLR) , year=
Unsupervised Representation Learning by Predicting Image Rotations , author=. International Conference on Learning Representations (ICLR) , year=
-
[61]
International Conference on Machine Learning (ICML) , pages=
A Simple Framework for Contrastive Learning of Visual Representations , author=. International Conference on Machine Learning (ICML) , pages=. 2020 , organization=
work page 2020
-
[62]
Frustratingly easy domain adaptation , author=. Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics (ACL) , pages=
-
[63]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Anchor regression: Heterogeneous data meet causality , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2021 , publisher=
work page 2021
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Domain separation networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[65]
International Conference on Machine Learning , pages=
Stability and hypothesis transfer learning , author=. International Conference on Machine Learning , pages=. 2013 , organization=
work page 2013
-
[66]
Advances in Neural Information Processing Systems , volume=
Unsupervised domain adaptation with residual transfer networks , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Regularized multi-task learning , author=. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[69]
A Dirty Model for Multi-task Learning , volume =
Jalali, Ali and Sanghavi, Sujay and Ruan, Chao and Ravikumar, Pradeep , booktitle =. A Dirty Model for Multi-task Learning , volume =
-
[70]
Journal of Machine Learning Research (JMLR) , volume=
Boosting as a Regularized Path to a Maximum Margin Classifier , author=. Journal of Machine Learning Research (JMLR) , volume=
-
[71]
Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation , author=. 2012 , publisher=
work page 2012
-
[72]
Dataset Shift in Machine Learning , pages=
Covariate shift by kernel mean matching , author=. Dataset Shift in Machine Learning , pages=. 2008 , publisher=
work page 2008
-
[73]
Annals of the Institute of Statistical Mathematics , volume=
Direct importance estimation with model selection and its application to covariate shift adaptation , author=. Annals of the Institute of Statistical Mathematics , volume=. 2008 , publisher=
work page 2008
-
[74]
Journal of Machine Learning Research , volume=
A least-squares approach to direct importance estimation , author=. Journal of Machine Learning Research , volume=
-
[75]
Advances in Neural Information Processing Systems , volume=
Relative density ratio estimation for robust distribution comparison , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
Nonparametric regression using deep neural networks with
Schmidt-Hieber, Johannes , journal=. Nonparametric regression using deep neural networks with. 2020 , publisher=
work page 2020
-
[77]
High-Dimensional Statistics: A Non-Asymptotic Viewpoint , author=. 2019 , publisher=
work page 2019
-
[78]
2020 International Joint Conference on Neural Networks (IJCNN) , pages=
Pseudo-labeling and confirmation bias in deep semi-supervised learning , author=. 2020 International Joint Conference on Neural Networks (IJCNN) , pages=. 2020 , organization=
work page 2020
- [79]
-
[80]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[81]
Proceedings of the 41st International Conference on Machine Learning , pages=
Transformers Implement Functional Gradient Descent to Learn Non-Linear Functions In Context , author=. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , volume=
work page 2024
-
[82]
BERT: Pre- training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.