Recognition: 2 theorem links
· Lean TheoremHow Twist Class Redundancy Drives the Prediction of Traces of Frobenius of Elliptic Curves
Pith reviewed 2026-05-15 02:39 UTC · model grok-4.3
The pith
Redundancy within quadratic twist classes of elliptic curves suffices for highly accurate machine learning predictions of their Frobenius traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The underlying datasets for predicting traces of Frobenius contain significant redundancy within quadratic twist classes, and this redundancy alone is sufficient to produce highly accurate predictions. The authors introduce a benchmark dataset consisting exclusively of unique twist class representatives.
What carries the argument
Redundancy inside quadratic twist classes, which supplies repeated examples that models can exploit to achieve high accuracy without learning new arithmetic relations.
If this is right
- Models trained on standard datasets can reach high accuracy without capturing genuine arithmetic features of elliptic curves.
- Future machine-learning work on elliptic-curve invariants must be tested on the unique-twist benchmark to confirm it learns properties beyond twist relations.
- Accuracy on the new benchmark is expected to fall, directly quantifying how much prior performance relied on redundancy.
- Any claimed advance in predicting arithmetic invariants must now be re-evaluated on deduplicated data.
Where Pith is reading between the lines
- Analogous redundancy may exist in other number-theoretic datasets built from families closed under twists or isogenies.
- Dataset audits for class-level repetitions should become standard before reporting predictive success in algebraic geometry or number theory.
- The unique-twist benchmark could be extended to additional invariants or to curves over number fields to test whether the redundancy effect generalizes.
Load-bearing premise
The drop in model performance on the unique-twist dataset is caused by removal of redundancy rather than by shifts in data distribution or limits on model capacity.
What would settle it
Train an identical model on the unique-twist-class benchmark and check whether prediction accuracy for traces of Frobenius stays as high as on the original dataset; a large drop supports the claim while little or no drop falsifies it.
Figures


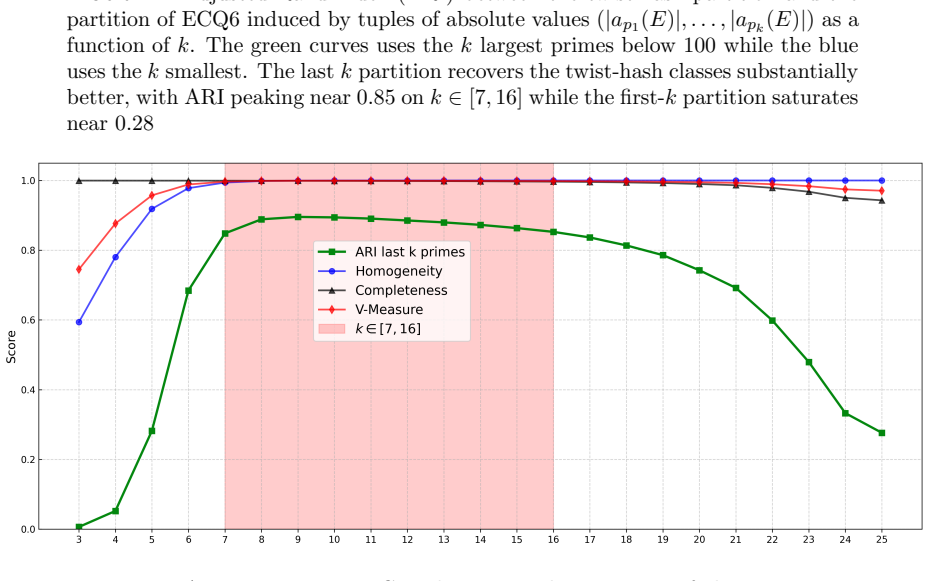
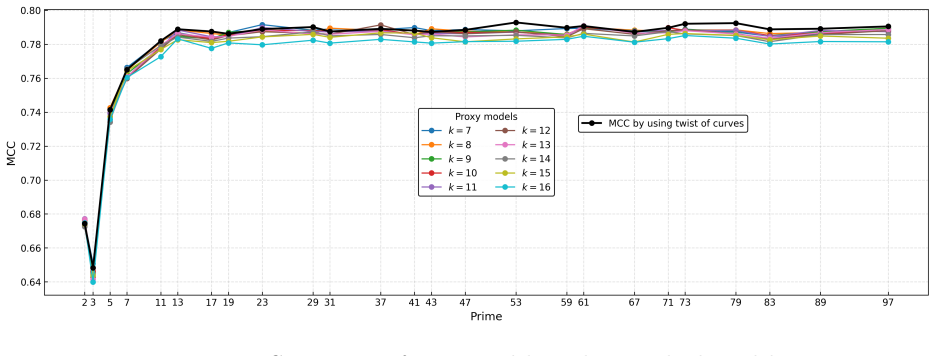

read the original abstract
Recent interest in applying machine learning methods to predict invariants of mathematical objects has yielded models with surprisingly strong performance, including those predicting traces of Frobenius for elliptic curves. We demonstrate that the underlying datasets contain significant redundancy within quadratic twist classes, which alone is sufficient to produce highly accurate predictions. To ensure future models capture new arithmetic properties rather than potentially exploiting these dataset artifacts, we introduce a benchmark dataset consisting exclusively of unique twist class representatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that machine learning models for predicting traces of Frobenius on elliptic curves achieve high accuracy primarily by exploiting redundancy within quadratic twist classes in existing public datasets. The authors demonstrate this effect empirically and introduce a new benchmark dataset consisting exclusively of unique twist-class representatives to encourage models that learn genuine arithmetic properties rather than dataset artifacts.
Significance. If the central claim holds after addressing the noted concerns, the work would be significant for the intersection of machine learning and number theory. It identifies a concrete dataset artifact (twist-class repetition) that can produce misleadingly strong performance and supplies an externally defined benchmark to mitigate it. This strengthens the foundation for reproducible and falsifiable ML experiments on elliptic curve invariants, particularly by highlighting the need for distribution-controlled ablations in future studies.
major comments (2)
- [§4 and §5] §4 (Benchmark Dataset Construction) and §5 (Experimental Results): The performance drop on the unique-twist-class dataset is presented as evidence that redundancy drives accuracy, but the construction necessarily alters the joint distribution of conductors, discriminants, and ranks. No control experiment is reported that holds this distribution fixed while removing only intra-class duplicates, leaving open the possibility that the gap arises from distributional shift alone.
- [§5.1] §5.1 (Quantitative Comparisons): The claim that twist-class redundancy is 'sufficient to produce highly accurate predictions' requires explicit quantification of how much of the original accuracy is recovered when duplicates are reintroduced while preserving the new benchmark's distribution; the current ablation does not isolate this effect.
minor comments (2)
- [Abstract] The abstract should include the specific accuracy metrics (e.g., R² or MAE values) on both the original and unique-twist datasets to make the redundancy effect immediately quantifiable.
- [§3] Notation for twist-class equivalence and the selection of representatives should be defined more formally, perhaps with a short equation or pseudocode in §3.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments, which help clarify how to better isolate the role of twist-class redundancy from potential distributional effects. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Benchmark Dataset Construction) and §5 (Experimental Results): The performance drop on the unique-twist-class dataset is presented as evidence that redundancy drives accuracy, but the construction necessarily alters the joint distribution of conductors, discriminants, and ranks. No control experiment is reported that holds this distribution fixed while removing only intra-class duplicates, leaving open the possibility that the gap arises from distributional shift alone.
Authors: We acknowledge that the unique-twist-class benchmark construction necessarily changes the joint distribution of conductors, discriminants, and ranks. Our primary aim was to supply an externally defined benchmark free of intra-class repetition. To isolate redundancy from distributional shift, we will add a control experiment in the revised manuscript: subsample the original dataset to match the conductor, discriminant, and rank distribution of the unique-twist benchmark while retaining duplicates, then compare model performance against the unique-twist results. revision: partial
-
Referee: [§5.1] §5.1 (Quantitative Comparisons): The claim that twist-class redundancy is 'sufficient to produce highly accurate predictions' requires explicit quantification of how much of the original accuracy is recovered when duplicates are reintroduced while preserving the new benchmark's distribution; the current ablation does not isolate this effect.
Authors: We agree that a direct quantification of accuracy recovery when reintroducing duplicates under the fixed benchmark distribution would strengthen the claim. In the revised manuscript we will add this controlled experiment: start from the unique-twist benchmark, reintroduce duplicates to restore the original redundancy levels while preserving the benchmark distribution, and report the resulting performance to measure the isolated contribution of redundancy. revision: yes
Circularity Check
No significant circularity; empirical dataset observation is self-contained
full rationale
The paper's core demonstration—that quadratic twist class redundancy in public elliptic curve datasets suffices for high-accuracy trace-of-Frobenius predictions—is an empirical comparison between the original dataset and a new benchmark of unique twist-class representatives. This comparison relies on the externally defined arithmetic equivalence relation of quadratic twists rather than any fitted parameter, self-referential definition, or load-bearing self-citation. No derivation step reduces by construction to its own inputs; the performance drop is presented as an observation, not a mathematical identity. The construction of the unique-representative benchmark is independent of the model's training procedure.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We demonstrate that the underlying datasets contain significant redundancy within quadratic twist classes, which alone is sufficient to produce highly accurate predictions.
-
IndisputableMonolith.Foundation.AlexanderDualityalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a benchmark dataset consisting exclusively of unique twist class representatives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Amir, Y.-H. He, K.-H. Lee, T. Oliver, and E. Sultanow. Machine learning class numbers of real quadratic fields.https://arxiv.org/pdf/2209.09283, 2022. arXiv:math.NT:2209.09283
-
[2]
Angelica Babei. Frobenius traces for a set of (quadratic) twist classes of elliptic curves of conductor up to 10 7, May 2026
work page 2026
-
[3]
Banwait, AJ Fing, Xiaoyu Huang, and Deependra Singh
Angelica Babei, Barinder S. Banwait, AJ Fing, Xiaoyu Huang, and Deependra Singh. Machine learning ap- proaches to the shafarevich-tate group of elliptic curves.Advances in Theoretical and Mathematical Physics, 29(8):pp. 2353–2379, 2025
work page 2025
-
[4]
Angelica Babei, Fran¸ cois Charton, Edgar Costa, Xiaoyu Huang, Kyu-Hwan Lee, David Lowry-Duda, Ashvni Narayanan, and Alexey Pozdnyakov. Learning euler factors of elliptic curves.Advances in Theoretical and Math- ematical Physics, 29(8):2327–2351, 2025
work page 2025
-
[5]
Booker, Min Lee, and David Lowry-Duda
Jonathan Bober, Andrew R. Booker, Min Lee, and David Lowry-Duda. Murmurations of modular forms in the weight aspect.http://arxiv.org/abs/2310.07746v1, 2023. arXiv:math.NT:2310.07746v1
-
[6]
Booker, Min Lee, David Lowry-Duda, Andrei Seymour-Howell, and Nina Zubrilina
Andrew R. Booker, Min Lee, David Lowry-Duda, Andrei Seymour-Howell, and Nina Zubrilina. Murmurations of Maass forms.http://arxiv.org/abs/2409.00765v1, 2024. arXiv:math.NT:2409.00765v1
-
[7]
Booker, Jeroen Sijsling, Andrew V
Andrew R. Booker, Jeroen Sijsling, Andrew V. Sutherland, John Voight, and Dan Yasaki. A database of genus-2 curves over the rational numbers.LMS Journal of Computation and Mathematics, 19(A):235–254, 2016
work page 2016
-
[8]
Wieb Bosma, John Cannon, and Catherine Playoust. The Magma algebra system. I. The user language.J. Symbolic Comput., 24(3-4):235–265, 1997. Computational algebra and number theory (London, 1993)
work page 1997
-
[9]
Murmurations of Mestre-Nagao sums.http://arxiv
Zvonimir Bujanovi´ c, Matija Kazalicki, and Lukas Novak. Murmurations of Mestre-Nagao sums.http://arxiv. org/abs/2403.17626v1, 2024. arXiv:math.NT:2403.17626v1. 12
-
[10]
Frobenious traces for a set of isogeny classes of elliptic curves of conductor up to 10 6, June 2025
Edgar Costa. Frobenious traces for a set of isogeny classes of elliptic curves of conductor up to 10 6, June 2025
work page 2025
-
[11]
Murmurations and explicit formulas.http://arxiv.org/abs/2306.10425v2, 2023
Alex Cowan. Murmurations and explicit formulas.http://arxiv.org/abs/2306.10425v2, 2023. arXiv:math.NT:2306.10425v2
-
[12]
Murmurations and ratios conjectures.http://arxiv.org/abs/2408.12723v1, 2024
Alex Cowan. Murmurations and ratios conjectures.http://arxiv.org/abs/2408.12723v1, 2024. arXiv:math.NT:2408.12723v1
-
[13]
Jan Gorodkin. Comparing two k-category assignments by a k-category correlation coefficient.Computational biology and chemistry, 28(5-6):367–374, 2004
work page 2004
-
[14]
Murmurations of elliptic curves.Exper- imental Mathematics, pages 1–13, 2024
Yang-Hui He, Kyu-Hwan Lee, Thomas Oliver, and Alexey Pozdnyakov. Murmurations of elliptic curves.Exper- imental Mathematics, pages 1–13, 2024
work page 2024
-
[15]
Comparing partitions.Journal of Classification, 2(1):193–218, 1985
Lawrence Hubert and Phipps Arabie. Comparing partitions.Journal of Classification, 2(1):193–218, 1985
work page 1985
-
[16]
Ranks of elliptic curves and deep neural networks.Res
Matija Kazalicki and Domagoj Vlah. Ranks of elliptic curves and deep neural networks.Res. Number Theory, 9(3):Paper No. 53, 21, 2023
work page 2023
-
[17]
K.-H. Lee and S. Lee. Machines learn number fields, but how? the case of galois groups.https://arxiv.org/ pdf/2508.06670, 2025. arXiv:math.NT:2508.06670
-
[18]
Murmurations of Dirichlet characters.International Mathematics Research Notices, 2025(1), 2025
Kyu-Hwan Lee, Thomas Oliver, and Alexey Pozdnyakov. Murmurations of Dirichlet characters.International Mathematics Research Notices, 2025(1), 2025
work page 2025
-
[19]
The L-functions and modular forms database.https://www.lmfdb.org, 2024
The LMFDB Collaboration. The L-functions and modular forms database.https://www.lmfdb.org, 2024. [On- line; accessed 29 December 2024]
work page 2024
-
[20]
Kimball Martin. Distribution of local signs of modular forms and murmurations of Fourier coefficients.http: //arxiv.org/abs/2409.02338v1, 2024. arXiv:math.NT:2409.02338v1
-
[21]
Comparison of the predicted and observed secondary structure of t4 phage lysozyme
Brian W Matthews. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochimica et Biophysica Acta (BBA)-Protein Structure, 405(2):442–451, 1975
work page 1975
-
[22]
V-measure: A conditional entropy-based external cluster evaluation measure
Andrew Rosenberg and Julia Hirschberg. V-measure: A conditional entropy-based external cluster evaluation measure. InProceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 410–420, 2007
work page 2007
-
[23]
Will Sawin and Andrew V. Sutherland. Murmurations for elliptic curves ordered by height.arXiv preprint, 2025
work page 2025
-
[24]
Silverman.The arithmetic of elliptic curves, volume 106 ofGraduate Texts in Mathematics
Joseph H. Silverman.The arithmetic of elliptic curves, volume 106 ofGraduate Texts in Mathematics. Springer, Dordrecht, second edition, 2009
work page 2009
-
[25]
Andrew V. Sutherland. Magma repository.https://github.com/AndrewVSutherland/Magma, 2023
work page 2023
-
[26]
A set of isogeny classes of elliptic curves of conductor up to 10 8, September 2024
Andrew Victor Sutherland. A set of isogeny classes of elliptic curves of conductor up to 10 8, September 2024
work page 2024
-
[27]
Murmurations.http://arxiv.org/abs/2310.07681v1, 2023
Nina Zubrilina. Murmurations.http://arxiv.org/abs/2310.07681v1, 2023. arXiv:math.NT:2310.07681v1. 13 Appendix Table 4.2.Comparison of Twist Hash and Proxy (k= 8) Models Prime# of GoodConductors Twist Hash Model Proxy Model (k= 8)ProbabilisticallyPredicted∗ OverallCorrect∗ DeterministicMCC OverallMCCProbabilisticallyPredicted∗ OverallCorrect∗ Deterministic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.