Recognition: no theorem link
Precise Verification of Transformers through ReLU-Catalyzed Abstraction Refinement
Pith reviewed 2026-05-15 02:31 UTC · model grok-4.3
The pith
ReLU encoding of dot-product ranges enables tighter convex bounds for precise transformer verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing a precise but non-linear bound for dot products with ReLUs, the method allows convex relaxation techniques from the ReLU literature to produce tighter output bounds for transformers, yielding two new verification frameworks that extend classic rule-based and optimization-based approaches.
What carries the argument
ReLU-catalyzed abstraction that encodes precise non-linear bounds on dot-product ranges in self-attention so that existing ReLU convex relaxations can be applied.
If this is right
- The approach extends both rule-based and optimization-based verification methods to transformers.
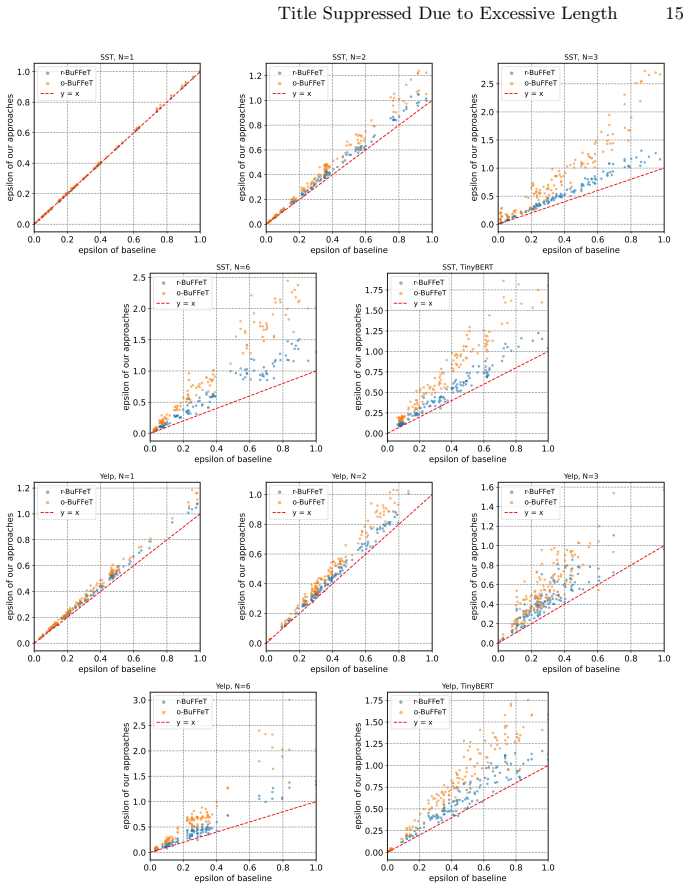
- It achieves significant precision gains on most robustness verification tasks derived from two sentiment datasets.
- Efficiency remains acceptable relative to prior over-approximation baselines.
- The method applies across different transformer architectures that contain self-attention layers.
Where Pith is reading between the lines
- Similar ReLU encodings could be explored for other non-linear operations that currently resist tight convex bounding in neural networks.
- Verification pipelines for attention-based models might adopt this encoding as a default abstraction step to lower manual parameter tuning.
- The technique suggests a general pattern of converting hard dot-product constraints into ReLU form to reuse existing relaxation solvers.
Load-bearing premise
The ReLU encoding of dot-product ranges must stay tractable for convex relaxation and produce bounds tight enough to reduce false alarms on the evaluated model sizes.
What would settle it
Executing the new method on the same sentiment-analysis models and robustness properties as the baseline and observing no reduction in false alarms or a runtime increase exceeding acceptable limits.
Figures





read the original abstract
Formal verification of transformers has become increasingly important due to their widespread deployment in safety-critical applications. Compared to classic neural networks, the inferences of transformers involve highly complex computations, such as dot products in self-attention layers, rendering their verification extremely difficult. Existing approaches explored over-approximation methods by constructing convex constraints to bound the output ranges of transformers, which can achieve high efficiency. However, they may sacrifice verification precision, and consequently introduce significant approximation error that leads to frequent occurrences of false alarms. In this paper, we propose a transformer verification approach that can achieve improved precision. At the core of our approach is a novel usage of ReLU, by which we represent a precise but non-linear bound for dot products such that we can further exploit the rich body of literature for convex relaxation of ReLU to derive precise bounds. We extend two classic approaches to the context of transformers, a rule-based one and an optimization-based one, resulting in two new frameworks for efficient and precise verification. We evaluate our approaches on different model architectures and robustness properties derived from two datasets about sentiment analysis, and compare with the state-of-the-art baseline approach. Compared to the baseline, our approach can achieve significant precision improvement for most of the verification tasks with acceptable compromise of efficiency, which demonstrates the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transformers can be verified more precisely by encoding dot-product ranges in self-attention as a precise but non-linear ReLU expression, which then permits the direct application of existing convex ReLU relaxations (rule-based or optimization-based) to obtain tighter bounds than prior direct convex over-approximations of the bilinear term. The resulting frameworks are evaluated on sentiment-analysis models and properties from two datasets, reporting significant precision gains relative to a state-of-the-art baseline at acceptable efficiency cost.
Significance. If the ReLU encoding is shown to be exact and the resulting relaxations remain tractable, the work would usefully connect transformer verification to the mature literature on ReLU convex relaxations, offering a concrete route to lower false-alarm rates on attention-based models without requiring entirely new bounding techniques.
major comments (2)
- [Abstract and §3] Abstract and §3 (core encoding): the claim that the ReLU representation yields a 'precise but non-linear bound' for dot products is load-bearing for the entire precision improvement argument, yet the manuscript provides no derivation, auxiliary-variable count, or proof that the encoding preserves exact ranges before relaxation; if auxiliary ReLUs scale with sequence length or head dimension, error accumulation could erase the claimed tightness.
- [Evaluation] Evaluation section: the reported 'significant precision improvement' on the two datasets is presented without ablation isolating the ReLU encoding, without error bars, and without explicit reporting of model sizes, sequence lengths, or property complexities; this leaves open whether the gains hold beyond the small sentiment-analysis instances described.
minor comments (1)
- [Abstract] The abstract should explicitly name the two datasets and the baseline method being compared.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and constructive feedback. Below, we address each major comment in detail and outline the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (core encoding): the claim that the ReLU representation yields a 'precise but non-linear bound' for dot products is load-bearing for the entire precision improvement argument, yet the manuscript provides no derivation, auxiliary-variable count, or proof that the encoding preserves exact ranges before relaxation; if auxiliary ReLUs scale with sequence length or head dimension, error accumulation could erase the claimed tightness.
Authors: We appreciate the referee pointing out the need for more rigorous justification of the core encoding. The ReLU representation is exact in the sense that it reformulates the dot-product constraint without introducing approximation error prior to relaxation. In the revised manuscript, we will include a complete derivation in Section 3, showing how the dot product u·v is expressed using ReLU activations on auxiliary variables representing the element-wise products and their sums. We will also provide the count of auxiliary variables, which is linear in the product of sequence length and head dimension, and a proof that the encoding is range-preserving. Furthermore, we will add analysis demonstrating that error accumulation is controlled because the convex relaxations are tight for the ReLU forms used. These additions will clarify that the precision gains stem directly from leveraging mature ReLU relaxation techniques. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported 'significant precision improvement' on the two datasets is presented without ablation isolating the ReLU encoding, without error bars, and without explicit reporting of model sizes, sequence lengths, or property complexities; this leaves open whether the gains hold beyond the small sentiment-analysis instances described.
Authors: We acknowledge the limitations in the current presentation of the evaluation results. To address this, we will revise the evaluation section to include an ablation study that compares the full approach against a baseline without the ReLU-catalyzed encoding, thereby isolating its contribution. We will also report error bars or confidence intervals for the precision metrics based on multiple verification runs. Explicit details on model sizes (e.g., 2-6 layers, 768 hidden dim), sequence lengths (128-512), and property complexities (e.g., input perturbation bounds and output specifications) will be added to Table 1 and the text. While the experiments are on sentiment analysis tasks, we will include a discussion on scalability and note that the method is general. These revisions will be made to strengthen the empirical claims. revision: yes
Circularity Check
No significant circularity; derivation relies on external ReLU relaxation literature
full rationale
The paper introduces a novel ReLU encoding to represent precise non-linear bounds on dot products within transformer self-attention, then applies established convex relaxation techniques (rule-based and optimization-based) drawn from prior external literature on ReLU. No derivation step reduces by construction to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. The central claim is a new encoding choice that leverages independent, pre-existing ReLU relaxation results rather than deriving those relaxations from quantities internal to the paper. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Convex relaxations of ReLU are sound and can be applied directly to the derived non-linear bounds.
Reference graph
Works this paper leans on
-
[1]
In: Riloff, E., Chiang, D., Hocken- maier, J., Tsujii, J
Alzantot, M., Sharma, Y., Elgohary, A., Ho, B.J., Srivastava, M., Chang, K.W.: Generating natural language adversarial examples. In: Riloff, E., Chiang, D., Hocken- maier, J., Tsujii, J. (eds.) Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 2890–2896. Association for Computational Lin- guistics, Brussels, Belgi...
-
[2]
In: Sedoc, J., Rogers, A., Rumshisky, A., Tafreshi, S
Bhargava, P., Drozd, A., Rogers, A.: Generalization in NLI: Ways (not) to go beyond simple heuristics. In: Sedoc, J., Rogers, A., Rumshisky, A., Tafreshi, S. (eds.) Proceedings of the Second Workshop on Insights from Negative Results in NLP. pp. 125–135. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic (Nov 2021). https...
-
[3]
Bonaert, G., Dimitrov, D.I., Baader, M., Vechev, M.: Fast and precise certification of transformers. In: Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation. p. 466–481. PLDI 2021, Association for Computing Machinery, New York, NY, USA (2021). https://doi. org/10.1145/3453483.3454056
-
[4]
Boudardara, F., Boussif, A., Meyer, P.J., Ghazel, M.: A review of abstraction methods toward verifying neural networks. ACM Trans. Embed. Comput. Syst. 23(4) (Jun 2024). https://doi.org/10.1145/3617508
-
[5]
Brix, C., Bak, S., Johnson, T.T., Wu, H.: The fifth international verification of neural networks competition (vnn-comp 2024): Summary and results. arXiv preprint arXiv:2412.19985 (2024). https://doi.org/https://doi.org/10.48550/arXiv. 2412.19985
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[6]
Brix, C., Müller, M.N., Bak, S., Johnson, T.T., Liu, C.: First three years of the international verification of neural networks competition (vnn-comp). Int. J. Softw. Tools Technol. Transf.25(3), 329–339 (May 2023). https://doi.org/10.1007/ s10009-023-00703-4
work page 2023
-
[7]
Bunel, R., Turkaslan, I., Torr, P.H.S., Kumar, M.P., Lu, J., Kohli, P.: Branch and bound for piecewise linear neural network verification. J. Mach. Learn. Res.21(1) (Jan 2020), https://jmlr.org/papers/volume21/19-468/19-468.pdf
work page 2020
-
[8]
Casadio, M., Arnaboldi, L., Daggitt, M., Isac, O., Dinkar, T., Kienitz, D., Rieser, V., Komendantskaya, E.: Antonio: Towards a systematic method of generating nlp benchmarks for verification. In: Narodytska, N., Amir, G., Katz, G., Isac, O. (eds.) Proceedings of the 6th Workshop on Formal Methods for ML-Enabled Autonomous Systems. Kalpa Publications in Co...
-
[9]
and Isac, Omri and Katz, Guy and Rieser, Verena and Lemon, Oliver , year =
Casadio, M., Dinkar, T., Komendantskaya, E., Arnaboldi, L., Daggitt, M.L., Isac, O., Katz, G., Rieser, V., Lemon, O.: Nlp verification: towards a general methodology for certifying robustness. European Journal of Applied Mathematics37(1), 180–237 (2026). https://doi.org/10.1017/S0956792525000099
-
[10]
(eds.) Find- ings of the Association for Computational Linguistics: ACL 2023
Chiang, C.H., Lee, H.y.: Are synonym substitution attacks really synonym sub- stitution attacks? In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Find- ings of the Association for Computational Linguistics: ACL 2023. pp. 1853–
work page 2023
-
[11]
https://doi.org/10.18653/v1/2023.findings-acl.117
Association for Computational Linguistics, Toronto, Canada (Jul 2023). https://doi.org/10.18653/v1/2023.findings-acl.117
-
[12]
doi:10.18653/v1/N19-1423 , pages =
Devlin,J.,Chang,M.W.,Lee,K.,Toutanova,K.:BERT:Pre-trainingofdeepbidirec- tional transformers for language understanding. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 4171–4...
-
[13]
In: 2018 IEEE Symposium on Security and Privacy (SP)
Gehr, T., Mirman, M., Drachsler-Cohen, D., Tsankov, P., Chaudhuri, S., Vechev, M.: Ai2: Safety and robustness certification of neural networks with abstract interpretation. In: 2018 IEEE Symposium on Security and Privacy (SP). pp. 3–18 (2018). https://doi.org/10.1109/SP.2018.00058 22 H. Liu et al
-
[14]
TinyBERT: Distilling BERT for natural language understanding
Jiao, X., Yin, Y., Shang, L., Jiang, X., Chen, X., Li, L., Wang, F., Liu, Q.: TinyBERT: Distilling BERT for natural language understanding. In: Cohn, T., He, Y., Liu, Y. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2020. pp. 4163–4174. Association for Computational Linguistics, Online (Nov 2020). https://doi.org/10.18653/v1/2020...
-
[15]
and Julian, Kyle and Kochenderfer, Mykel J
Katz, G., Barrett, C., Dill, D.L., Julian, K., Kochenderfer, M.J.: Reluplex: An efficient smt solver for verifying deep neural networks. In: Majumdar, R., Kunčak, V. (eds.) Computer Aided Verification. pp. 97–117. Springer International Publishing, Cham (2017). https://doi.org/10.1007/978-3-319-63387-9_5
-
[16]
In: 2021 IEEE/AIAA 40th Digital Avionics Systems Conference (DASC)
Katz, S.M., Corso, A.L., Strong, C.A., Kochenderfer, M.J.: Verification of image- based neural network controllers using generative models. In: 2021 IEEE/AIAA 40th Digital Avionics Systems Conference (DASC). pp. 1–10 (2021). https://doi. org/10.1109/DASC52595.2021.9594360
-
[17]
and Koller, Lukas and Manino, Edoardo and Nguyen, ThanhVu H
Kaulen, K., Ladner, T., Bak, S., Brix, C., Duong, H., Flinkow, T., Johnson, T.T., Koller, L., Manino, E., Nguyen, T.H., et al.: The 6th international verification of neural networks competition (vnn-comp 2025): Summary and results. arXiv preprint arXiv:2512.19007 (2025). https://doi.org/10.48550/arXiv.2512.19007
-
[18]
Journal of Machine Learning Research 25(12), 1–53 (2024), http://jmlr.org/papers/v25/23-0119.html
König, M., Bosman, A.W., Hoos, H.H., van Rijn, J.N.: Critically assessing the state of the art in neural network verification. Journal of Machine Learning Research 25(12), 1–53 (2024), http://jmlr.org/papers/v25/23-0119.html
work page 2024
-
[19]
Liao, B.H.C., Cheng, C.H., Esen, H., Knoll, A.: Are transformers more robust? towards exact robustness verification for transformers. In: Computer Safety, Relia- bility, and Security: 42nd International Conference, SAFECOMP 2023, Toulouse, France, September 20–22, 2023, Proceedings. p. 89–103. Springer-Verlag, Berlin, Heidelberg (2023). https://doi.org/10...
-
[20]
Liu, C., Arnon, T., Lazarus, C., Strong, C., Barrett, C., Kochenderfer, M.J.: Algorithms for verifying deep neural networks. Found. Trends Optim.4(3–4), 244–404 (Feb 2021). https://doi.org/10.1561/2400000035
-
[21]
Liu, H., Zhang, Z., Zhao, J.: Precise verification of transformers through relu- catalyzed abstraction refinement (Apr 2026). https://doi.org/10.5281/zenodo. 19841667
-
[22]
Towards Crafting Text Adversarial Samples
Samanta, S., Mehta, S.: Towards crafting text adversarial samples (2017). https: //doi.org/10.48550/arXiv.1707.02812
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.02812 2017
-
[23]
Shi, Z., Jin, Q., Kolter, Z., Jana, S., Hsieh, C.J., Zhang, H.: Neural network verification with branch-and-bound for general nonlinearities. In: Tools and Al- gorithms for the Construction and Analysis of Systems: 31st International Con- ference, TACAS 2025, Held as Part of the International Joint Conferences on Theory and Practice of Software, ETAPS 202...
-
[24]
Shi, Z., Zhang, H., Chang, K.W., Huang, M., Hsieh, C.J.: Robustness verification for transformers. In: International Conference on Learning Representations (2020), https://openreview.net/forum?id=BJxwPJHFwS
work page 2020
-
[25]
Singh, G., Gehr, T., Püschel, M., Vechev, M.: An abstract domain for certifying neural networks. Proc. ACM Program. Lang.3(POPL) (Jan 2019). https://doi. org/10.1145/3290354
-
[26]
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C.D., Ng, A., Potts, C.: Recursive deep models for semantic compositionality over a sentiment treebank. In: Yarowsky,D.,Baldwin,T.,Korhonen,A.,Livescu,K.,Bethard,S.(eds.)Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. pp. Title Suppressed Due to Excessive Lengt...
work page 2013
-
[27]
Tjeng, V., Xiao, K.Y., Tedrake, R.: Evaluating robustness of neural networks with mixed integer programming. In: 7th International Conference on Learning Repre- sentations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net (2019), https://openreview.net/forum?id=HyGIdiRqtm
work page 2019
-
[28]
In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Asso- ciates, Inc. (2017), https://proceedings.neuri...
work page 2017
-
[29]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Wegmann, A., Nguyen, D., Jurgens, D.: Tokenization is sensitive to language variation. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Findings of the Association for Computational Linguistics: ACL 2025. pp. 10958–10983. Association for Computational Linguistics, Vienna, Austria (Jul 2025). https: //doi.org/10.18653/v1/2025.findings-acl.572
-
[30]
In: Ruiz, F., Dy, J., van de Meent, J.W
Wei, D., Wu, H., Wu, M., Chen, P.Y., Barrett, C., Farchi, E.: Convex bounds on the softmax function with applications to robustness verification. In: Ruiz, F., Dy, J., van de Meent, J.W. (eds.) Proceedings of The 26th International Conference on Artificial Intelligence and Statistics. Proceedings of Machine Learning Research, vol. 206, pp. 6853–6878. PMLR...
work page 2023
-
[31]
Weng, L., Zhang, H., Chen, H., Song, Z., Hsieh, C.J., Daniel, L., Boning, D., Dhillon, I.: Towards fast computation of certified robustness for ReLU networks. In: Dy, J., Krause, A. (eds.) Proceedings of the 35th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 80, pp. 5276–5285. PMLR (10–15 Jul 2018), https://p...
work page 2018
- [32]
-
[33]
Xu, K., Zhang, H., Wang, S., Wang, Y., Jana, S., Lin, X., Hsieh, C.J.: Fast and complete: Enabling complete neural network verification with rapid and massively parallel incomplete verifiers. In: International Conference on Learning Representa- tions (2021), https://openreview.net/forum?id=nVZtXBI6LNn
work page 2021
-
[34]
In: Pro- ceedings of the 32nd International Conference on Neural Information Pro- cessing Systems
Zhang, H., Weng, T.W., Chen, P.Y., Hsieh, C.J., Daniel, L.: Efficient neu- ral network robustness certification with general activation functions. In: Pro- ceedings of the 32nd International Conference on Neural Information Pro- cessing Systems. p. 4944–4953. NIPS’18, Curran Associates Inc., Red Hook, NY, USA (2018), https://proceedings.neurips.cc/paper_f...
work page 2018
-
[35]
Zhang, X., Zhao, J., LeCun, Y.: Character-level convolutional networks for text classification. In: Proceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1. p. 649–657. NIPS’15, MIT Press, Cambridge, MA, USA (2015), https://proceedings.neurips.cc/paper_files/paper/ 2015/file/250cf8b51c773f3f8dc8b4be867a9a02-Paper.pdf
work page 2015
-
[36]
Zhang, Y., Shen, L., Guo, S., Ji, S.: Galileo: general linear relaxation framework for tightening robustness certification of transformers. In: Proceedings of the Thirty- Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on 24 H. Liu et al. Education...
-
[37]
In: Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering
Zhang, Z., Wu, Y., Liu, S., Liu, J., Zhang, M.: Provably tightest linear approximation for robustness verification of sigmoid-like neural networks. In: Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. ASE ’22, Association for Computing Machinery, New York, NY, USA (2023). https://doi.org/10.1145/3551349.3556907
-
[38]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Zhu, Z., Liu, F., Chrysos, G., Cevher, V.: Robustness in deep learning: The good (width), the bad (depth), and the ugly (initialization). In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022), https://openreview.net/forum?id=m8vzptcFKsT Title Suppressed Due to Excessive Length 25 A A Detailed Intr...
work page 2022
-
[39]
addressed the verification of dot-product operation such as z = xy by introducing planar relaxations of the form z = αx + βy + γ to bound the nonlinearity. In particular, [23] define the lower and upper bounds as follows: αU = uy, β U = lx, γ U = −lxuy, αL = ly, β L = lx, γ L = −lxly, whenx∈ [lx, ux] andy∈[l y, uy]. For the dot-product operationQK T, wher...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.