Recognition: 2 theorem links
· Lean TheoremTowards Self-Evolving Agentic Literature Retrieval
Pith reviewed 2026-05-15 02:33 UTC · model grok-4.3
The pith
PaSaMaster turns literature retrieval into a self-evolving process that ranks papers by relevance without generating sources, outperforming GPT-5.2 by 30% at 1% cost with zero hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
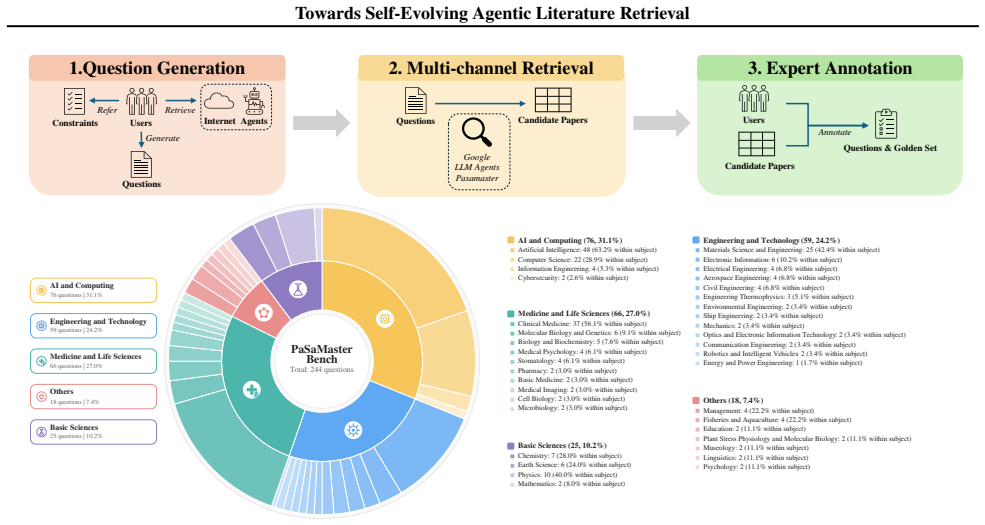
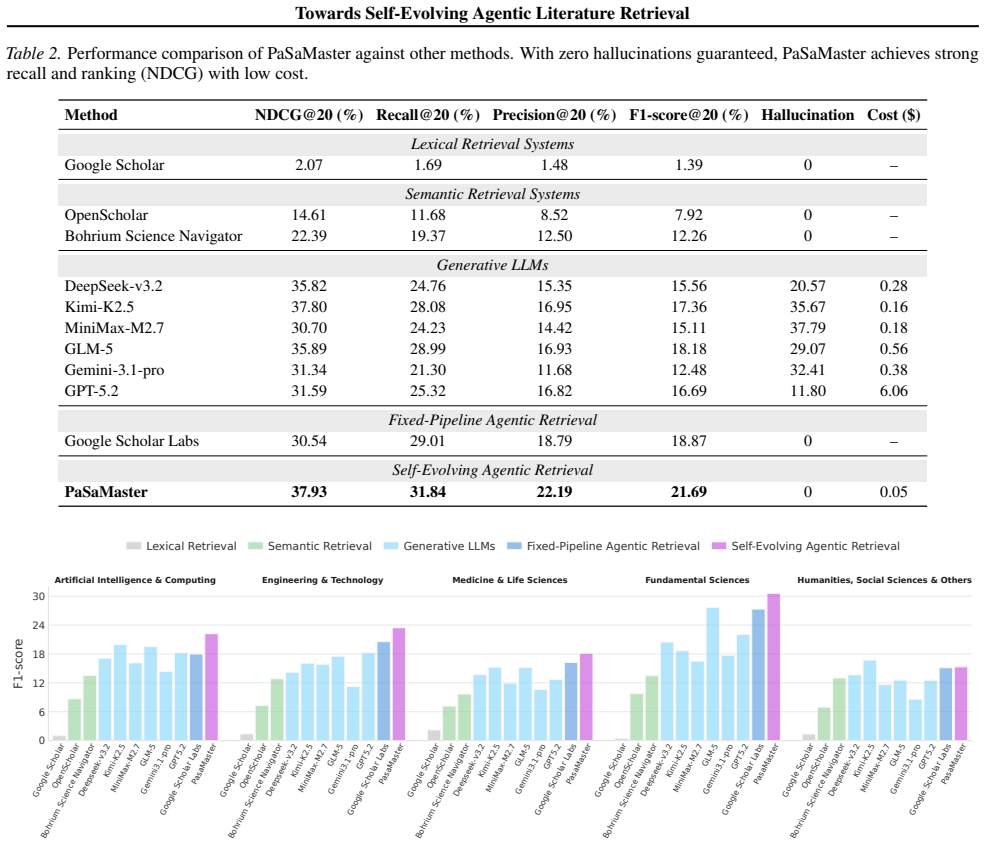
PaSaMaster is a self-evolving agentic literature retrieval system that produces relevance-scored paper rankings with evidence-grounded recommendations through iterative intent analysis, retrieval, and ranking. It outperforms GPT-5.2 by 30.0% at 1% computational cost while ensuring zero source hallucination and improves F1-score by 15.6X over traditional keyword retrieval on the PaSaMaster Benchmark across 38 disciplines.
What carries the argument
The iterative process that transforms retrieval into an evolving search using ranked evidence to reveal gaps, refine intents, and guide follow-up searches, combined with separating planning from retrieval using frontier LLMs only for intent understanding.
Load-bearing premise
The PaSaMaster Benchmark faithfully represents real-world scientific search intents without introducing selection bias in the iterative ranking process.
What would settle it
Running PaSaMaster on an independent benchmark created without author involvement and measuring if the 15.6X F1 improvement and zero hallucination hold.
Figures

read the original abstract
As large language models reshape scientific research, literature retrieval faces a twofold challenge: ensuring source authenticity while maintaining a deep comprehension of academic search intents. While reliable, traditional keyword-centric search fails to capture complex research intents. Frontier LLMs can handle complex research intents, but their high cost and tendency to hallucinate remain key limitations. Here we introduce PaSaMaster, a self-evolving agentic literature retrieval system that produces relevance-scored paper rankings with evidence-grounded recommendations through iterative intent analysis, retrieval, and ranking. It is built on three key designs. First, it transforms literature retrieval from a one shot query--document matching problem into a search process that evolves over time, using ranked evidence to reveal gaps, refine intents, and guide follow-up searches. Second, it prevents hallucinated sources by treating retrieval as intent--paper relevance ranking rather than generation. Finally, PaSaMaster improves cost efficiency by separating planning from retrieval: a frontier LLM is used only for intent understanding, while large scale retrieval and relevance scoring are delegated to customized corpora and lightweight models. Evaluated on the PaSaMaster Benchmark across 38 scientific disciplines, our system exposes the severe inaccuracy and incompleteness of traditional keyword retrieval (improving F1-score by 15.6X) and the unreliability of generative LLMs (which exhibit hallucination rates up to 37.79%). Remarkably, PaSaMaster outperforms GPT-5.2 by 30.0% at a mere 1% of the computational cost while ensuring zero source hallucination: https://github.com/sjtu-sai-agents/PaSaMaster
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PaSaMaster, a self-evolving agentic literature retrieval system that converts one-shot query-document matching into an iterative process of intent analysis, retrieval, evidence-based gap revelation, and re-ranking. It claims to deliver relevance-scored paper lists with zero source hallucination, achieving a 15.6X F1-score improvement over traditional keyword retrieval and 30% higher performance than GPT-5.2 at 1% of the computational cost, evaluated on a self-constructed PaSaMaster Benchmark spanning 38 disciplines.
Significance. If the benchmark and results prove robust, the work offers a practical advance in agentic retrieval for scientific literature by addressing hallucination through ranking rather than generation and by delegating heavy retrieval to lightweight models while reserving frontier LLMs for planning. The iterative gap-revelation mechanism is a conceptually sound response to complex research intents, and the reported cost reduction could make high-quality literature search more accessible.
major comments (3)
- [Evaluation section / PaSaMaster Benchmark] The description of the PaSaMaster Benchmark provides no information on query sourcing across the 38 disciplines, the protocol for constructing ground-truth relevant paper sets, or the criteria and inter-annotator agreement for relevance judgments. Without these details the headline claims of 15.6X F1 improvement and 30% outperformance over GPT-5.2 cannot be independently verified and may reflect benchmark-specific artifacts rather than general superiority.
- [Results and evaluation] No statistical significance tests, confidence intervals, error bars, or ablation studies are reported for any quantitative result, including the zero-hallucination rate, cost ratio, or cross-discipline consistency. These omissions leave the central empirical claims unsupported at the level required for a methods paper.
- [System design / Iterative ranking] The iterative evidence-ranking process is described at a high level, but the manuscript does not analyze or bound potential selection bias introduced when ranked evidence is used to 'reveal gaps' and trigger follow-up searches. This is load-bearing for the self-evolving claim and requires either a formal argument or controlled experiments showing that the process does not systematically favor certain paper types.
minor comments (2)
- [Abstract] The abstract uses an em-dash in 'query--document'; standard hyphenation would improve readability.
- [Abstract] The GitHub link is given without a commit hash or release tag, making exact reproduction of the reported numbers difficult.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major concern point by point below and will revise the manuscript to strengthen the evaluation and analysis sections.
read point-by-point responses
-
Referee: [Evaluation section / PaSaMaster Benchmark] The description of the PaSaMaster Benchmark provides no information on query sourcing across the 38 disciplines, the protocol for constructing ground-truth relevant paper sets, or the criteria and inter-annotator agreement for relevance judgments. Without these details the headline claims of 15.6X F1 improvement and 30% outperformance over GPT-5.2 cannot be independently verified and may reflect benchmark-specific artifacts rather than general superiority.
Authors: We agree that additional details on benchmark construction are required for reproducibility and independent verification. In the revised manuscript we will add a dedicated subsection describing the query sourcing process across the 38 disciplines, the exact protocol for assembling ground-truth relevant paper sets, the relevance judgment criteria, and inter-annotator agreement statistics (including Cohen’s kappa). These additions will directly support the reported F1 and performance gains. revision: yes
-
Referee: [Results and evaluation] No statistical significance tests, confidence intervals, error bars, or ablation studies are reported for any quantitative result, including the zero-hallucination rate, cost ratio, or cross-discipline consistency. These omissions leave the central empirical claims unsupported at the level required for a methods paper.
Authors: We acknowledge the absence of statistical rigor and ablations in the current draft. The revised version will report paired statistical significance tests, confidence intervals, and error bars for all headline metrics (F1 improvement, hallucination rate, cost ratio, and cross-discipline results). We will also include ablation studies isolating the contribution of the iterative gap-revelation step and the lightweight-model delegation, thereby providing the quantitative support expected for a methods paper. revision: yes
-
Referee: [System design / Iterative ranking] The iterative evidence-ranking process is described at a high level, but the manuscript does not analyze or bound potential selection bias introduced when ranked evidence is used to 'reveal gaps' and trigger follow-up searches. This is load-bearing for the self-evolving claim and requires either a formal argument or controlled experiments showing that the process does not systematically favor certain paper types.
Authors: We agree that a formal treatment of selection bias is necessary to substantiate the self-evolving claim. In the revision we will add a dedicated analysis that bounds the bias introduced by using ranked evidence for gap revelation, leveraging properties of the relevance scoring function. We will also include controlled experiments contrasting the full iterative pipeline against a non-iterative baseline to demonstrate that retrieved paper distributions do not systematically favor particular types or sources. revision: yes
Circularity Check
No circularity: empirical results on external benchmark
full rationale
The paper describes an agentic retrieval system (PaSaMaster) and reports performance metrics as direct empirical measurements on the PaSaMaster Benchmark across 38 disciplines. No equations, fitted parameters, or derivation steps are present that reduce any claimed prediction or result to the system's own inputs by construction. The F1-score improvements, hallucination rates, and cost comparisons are presented as observed outcomes rather than quantities defined in terms of the method itself. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The evaluation is therefore self-contained against the stated benchmark.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
self-evolving retrieval: transforms literature retrieval from one-shot query–document matching into an adaptive search process... using ranked evidence to identify coverage gaps, refine the research intent
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hallucination-free intent–paper relevance ranking... every candidate paper must be retrieved from a verified scientific corpus D
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
PaSa: An LLM Agent for Comprehensive Academic Paper Search , author=. 2025 , eprint=
work page 2025
-
[2]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
work page 2021
-
[3]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. 2025 , eprint=
work page 2025
-
[4]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. 2019 , eprint=
work page 2019
-
[5]
OpenAI , year=. 2303.08774 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Dense Passage Retrieval for Open-Domain Question Answering , author=. 2020 , eprint=
work page 2020
-
[7]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges , author=. 2024 , eprint=
work page 2024
-
[8]
The Gerontocratization of Science: How hypergrowth reshapes knowledge circulation , author=. 2025 , eprint=
work page 2025
-
[9]
Kyle Lo and Lucy Lu Wang and Mark Neumann and Rodney Kinney and Dan S. Weld , year=. 1911.02782 , archivePrefix=
- [10]
- [11]
-
[12]
Scientific literature: Information overload , volume=. Nature , author=. 2016 , pages=
work page 2016
-
[13]
Communications of the ACM , volume=
The vocabulary problem in human-system communication , author=. Communications of the ACM , volume=
-
[14]
Lost in the Middle: How Language Models Use Long Contexts , author=. 2023 , eprint=
work page 2023
-
[15]
Detecting hallucinations in large language models using semantic entropy , volume=. Nature , author=. 2024 , pages=
work page 2024
- [16]
-
[17]
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs , author=. 2024 , eprint=
work page 2024
-
[18]
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale , author=. 2025 , eprint=
work page 2025
-
[19]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=. 2025 , eprint=
work page 2025
- [20]
-
[21]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention , author=. 2025 , eprint=
work page 2025
- [22]
- [23]
-
[24]
Journal of the Association for Information Science and Technology , volume =
Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references , author =. Journal of the Association for Information Science and Technology , volume =. 2015 , doi =
work page 2015
- [25]
-
[26]
Research Synthesis Methods , volume =
What every researcher should know about searching---clarified concepts, search advice, and an agenda to improve finding in academia , author =. Research Synthesis Methods , volume =. 2021 , doi =
work page 2021
-
[27]
Exploratory Search: Beyond the Query-Response Paradigm , author =. 2009 , doi =
work page 2009
-
[28]
Scientific discovery in the age of artificial intelligence , author =. Nature , volume =. 2023 , doi =
work page 2023
-
[29]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
LitSearch: A Retrieval Benchmark for Scientific Literature Search , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , publisher =
work page 2024
-
[30]
npj Artificial Intelligence , volume =
Exploring the role of large language models in the scientific method: from hypothesis to discovery , author =. npj Artificial Intelligence , volume =. 2025 , doi =
work page 2025
- [31]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.