Recognition: 2 theorem links
· Lean TheoremCoRDS: Coreset-based Representative and Diverse Selection for Streaming Video Understanding
Pith reviewed 2026-05-15 02:24 UTC · model grok-4.3
The pith
Treating KV-cache compression as coreset selection improves streaming video understanding under fixed memory budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By viewing KV-cache compression as a bicriteria coreset selection task in a joint key-value representation, the method balances coverage of retrieval structure and output-relevant information while using an orthogonality criterion, connected to log-determinant subset selection, to favor diverse directions and thereby retain a more representative subset than local pruning heuristics.
What carries the argument
The bicriteria objective that selects a coreset by balancing coverage in joint key-value space with an orthogonality-driven diversity term.
If this is right
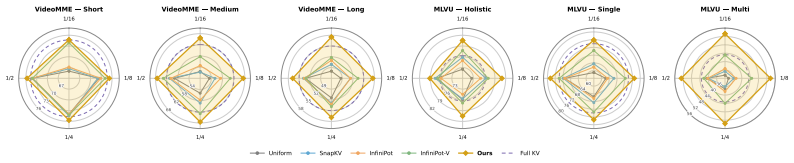
- Accuracy rises on long-video and streaming benchmarks compared with recency, redundancy, or saliency baselines at fixed cache size.
- The retained subset preserves both retrieval geometry and output-relevant signals better than independent token scoring.
- Orthogonality favors new directions, reducing redundancy within the compressed cache.
- The same selection principle applies across multiple open-source vision-language models without task-specific retraining.
Where Pith is reading between the lines
- The same coverage-plus-diversity logic could be tested on long-context language models to compress their KV caches.
- Adaptive cache budgets that grow or shrink based on detected scene complexity might further improve the method.
- Links to log-determinant selection suggest possible connections to other matrix-based summarization tasks in machine learning.
Load-bearing premise
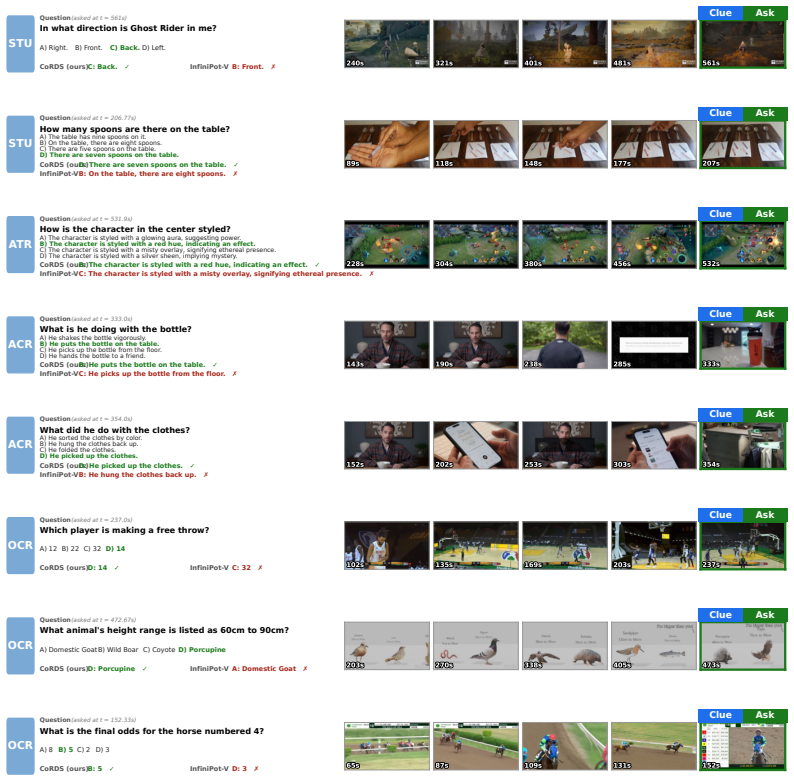
A small geometrically covering subset of tokens will retain the information needed for arbitrary future reasoning queries over the entire video history.
What would settle it
A controlled test on a long video where a query depends on visual content from a cluster of tokens that the coreset discards, producing a measurable drop in answer accuracy relative to the full cache.
Figures






read the original abstract
Streaming video understanding with large vision-language models (VLMs) requires a compact memory that can support future reasoning over an ever-growing visual history. A common solution is to compress the key-value (KV) cache, but existing streaming methods typically rely on local token-wise heuristics, such as recency, temporal redundancy, or saliency, which do not explicitly optimize whether the retained cache is representative of the accumulated history. We propose to view KV-cache compression as a coreset selection problem: rather than scoring tokens independently for retention, we select a small subset that covers the geometry of the accumulated visual cache. Our method operates in a joint KV representation and introduces a bicriteria objective that balances coverage in key and value spaces, preserving both retrieval structure and output-relevant information. To encourage a more diverse retained subset, we further introduce an orthogonality-driven diversity criterion that favors candidates contributing new directions beyond the current selection, and connect this criterion to log-determinant subset selection. Across four open-source VLMs and five long-video and streaming-video benchmarks, our method improves over heuristic streaming compression baselines under a fixed cache budget. These results highlight that representative coreset selection offers a more effective principle, than token-wise pruning, for memory-constrained streaming video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoRDS, a method that frames KV-cache compression for streaming video understanding as a coreset selection problem. It introduces a bicriteria objective balancing coverage in joint key-value spaces with an orthogonality-driven diversity term connected to log-determinant subset selection, and reports empirical improvements over heuristic baselines across four open-source VLMs and five long-video/streaming benchmarks under fixed cache budgets.
Significance. If the central empirical claim holds after addressing the noted gaps, the work would demonstrate that geometry-aware coreset selection can outperform local token-wise heuristics for memory-constrained VLM inference on long videos, offering a principled alternative to recency or saliency pruning with potential impact on efficient streaming video reasoning systems.
major comments (3)
- [§3.2] §3.2 (bicriteria objective): the balance weight between key and value coverage and the diversity regularization strength are free parameters, yet no ablation or sensitivity analysis is reported on their effect on performance; this is load-bearing because the abstract and experiments attribute gains to the joint objective without showing robustness to these choices.
- [§4] §4 (experiments): results claim consistent improvements over baselines but provide no quantitative variance, standard deviations across runs, or statistical significance tests, undermining the ability to assess whether gains are reliable or could be explained by benchmark-specific tuning.
- [§3.3] §3.3 (diversity criterion and log-det connection): no approximation guarantee, regret bound, or worst-case analysis is supplied showing that the selected coreset retains tokens necessary for arbitrary future queries; the evaluation is confined to the five benchmark distributions, leaving open the risk that low-coverage but query-critical tokens are systematically dropped when the stream diverges from observed statistics.
minor comments (1)
- [§3] Notation for the joint KV representation and the orthogonality term could be clarified with an explicit equation reference in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (bicriteria objective): the balance weight between key and value coverage and the diversity regularization strength are free parameters, yet no ablation or sensitivity analysis is reported on their effect on performance; this is load-bearing because the abstract and experiments attribute gains to the joint objective without showing robustness to these choices.
Authors: We agree that sensitivity analysis is necessary to support the claims. In the revised manuscript we will add an ablation study varying the balance weight between key and value coverage and the diversity regularization strength across a range of values, reporting performance on the main benchmarks to demonstrate robustness of the reported gains. revision: yes
-
Referee: [§4] §4 (experiments): results claim consistent improvements over baselines but provide no quantitative variance, standard deviations across runs, or statistical significance tests, undermining the ability to assess whether gains are reliable or could be explained by benchmark-specific tuning.
Authors: We acknowledge the absence of variance reporting. Although the core selection procedure is deterministic, we will repeat experiments under varied stream orderings and report standard deviations together with statistical significance tests (e.g., paired Wilcoxon tests) in the updated tables to quantify reliability. revision: yes
-
Referee: [§3.3] §3.3 (diversity criterion and log-det connection): no approximation guarantee, regret bound, or worst-case analysis is supplied showing that the selected coreset retains tokens necessary for arbitrary future queries; the evaluation is confined to the five benchmark distributions, leaving open the risk that low-coverage but query-critical tokens are systematically dropped when the stream diverges from observed statistics.
Authors: We note that worst-case guarantees for arbitrary future queries are difficult to obtain without strong distributional assumptions on the query stream. Our diversity term is connected to log-determinant subset selection, which inherits known submodular approximation properties in the static setting. In the revision we will expand §3.3 with an explicit discussion of these limitations, the empirical scope of the evaluation, and potential risks for out-of-distribution streams. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines a new bicriteria coreset objective for KV-cache compression (coverage in joint key-value space plus orthogonality linked to log-det diversity) and reports empirical gains on five benchmarks across four VLMs. No step reduces a claimed prediction or result to a fitted parameter defined on the same data, nor does any load-bearing premise collapse to a self-citation, ansatz smuggled via prior work, or renaming of a known result. The central claim remains an empirical observation under fixed cache budgets rather than a self-referential derivation.
Axiom & Free-Parameter Ledger
free parameters (2)
- bicriteria balance weight
- diversity regularization strength
axioms (1)
- domain assumption A small subset selected by coverage and diversity criteria will retain sufficient information for downstream reasoning over the full history.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bicriteria distance d_α(i,S)=min_j [α||k_i-k_j||²+(1-α)||v_i-v_j||²] ... orthogonal novelty score Orth(i|St)=η||r_i||²+(1-η)||rV_i||² ... log det((U_K_S)^⊤U_K_S+εI)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
greedy orthogonalization achieves (1-e^{-1}) log-det approximation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Long context transfer from language to vision.Transactions on Machine Learning Research, 2025
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.Transactions on Machine Learning Research, 2025
work page 2025
-
[4]
Infinipot-v: Memory-constrained kv cache compression for streaming video understanding
Minsoo Kim, Kyuhong Shim, Jungwook Choi, and Simyung Chang. Infinipot-v: Memory-constrained kv cache compression for streaming video understanding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[5]
Streaming long video understanding with large language models
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Jiaqi Wang, and Dahua Lin. Streaming long video understanding with large language models. InAdvances in Neural Information Processing Systems, 2024.https://arxiv.org/abs/2405.16009
-
[6]
Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra. LongVU: Spatiotemporal adaptive compression for long video-language understanding. InForty-secon...
work page 2025
-
[7]
Streamingbench: Assessing the gap for mllms to achieve streaming video understanding
Junming Lin, Zheng Fang, Chi Chen, Haoxuan Cheng, Zihao Wan, Fuwen Luo, Ziyue Wang, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video understanding. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12147–12151. IEEE, 2026
work page 2026
-
[8]
Flash-vstream: Efficient real-time understanding for long video streams
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, and Xiaojie Jin. Flash-vstream: Efficient real-time understanding for long video streams. InProceedings of the IEEE/CVF international conference on computer vision, pages 21059–21069, 2025
work page 2025
-
[9]
Training-free adaptive frame selection for video-language understanding, 2026
Bhavika Suresh Devnani, Jitesh Jain, Humphrey Shi, and Judy Hoffman. Training-free adaptive frame selection for video-language understanding, 2026
work page 2026
-
[10]
Adaptive keyframe sampling for long video understanding
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive keyframe sampling for long video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29118–29128, 2025
work page 2025
-
[11]
Storm: Token-efficient long video understanding for multimodal llms
Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, Zhiqi Li, De-An Huang, Guilin Liu, Zhiding Yu, Kurt Keutzer, et al. Storm: Token-efficient long video understanding for multimodal llms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5830–5841, 2025
work page 2025
-
[12]
Streaming video question-answering with in-context video kv-cache retrieval
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, Hao Jiang, et al. Streaming video question-answering with in-context video kv-cache retrieval. InICLR, 2025
work page 2025
-
[13]
Yanlai Yang, Zhuokai Zhao, Satya Narayan Shukla, Aashu Singh, Shlok Kumar Mishra, Lizhu Zhang, and Mengye Ren. Streammem: Query-agnostic kv cache memory for streaming video understanding.arXiv preprint arXiv:2508.15717, 2025. 10
-
[14]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
work page 2025
-
[15]
LLaV A-NeXT: A strong zero-shot video understanding model
Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. LLaV A-NeXT: A strong zero-shot video understanding model. https://llava-vl. github.io/blog/2024-04-30-llava-next-video/, April 2024
work page 2024
-
[16]
EgoSchema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. EgoSchema: A diagnostic benchmark for very long-form video language understanding. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
work page 2023
-
[17]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Rongrong Ji, and Xing Sun. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025
work page 2025
-
[20]
Needle in a video haystack: A scalable synthetic evaluator for video mllms
Zijia Zhao, Haoyu Lu, Yuqi Huo, Yifan Du, Tongtian Yue, Longteng Guo, Bingning Wang, Weipeng Chen, and Jing Liu. Needle in a video haystack: A scalable synthetic evaluator for video mllms. InInternational Conference on Learning Representations, 2025
work page 2025
-
[21]
InternVideo2.5: Empowering video MLLMs with long and rich context modeling.arXiv:2501.12386, 2025
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, Min Dou, Kai Chen, Wenhai Wang, Yu Qiao, Yali Wang, and Limin Wang. InternVideo2.5: Empowering video MLLMs with long and rich context modeling.arXiv:2501.12386, 2025
-
[22]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. VideoLLaMA 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual representation by alignment before projection.arXiv:2311.10122, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Natan Bagrov, Eugene Khvedchenia, Borys Tymchenko, Shay Aharon, Lior Kadoch, Tomer Keren, Ofri Masad, Yonatan Geifman, Ran Zilberstein, Tuomas Rintamaki, et al. Efficient video sampling: Pruning temporally redundant tokens for faster vlm inference.arXiv preprint arXiv:2510.14624, 2025
-
[25]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
work page 2025
-
[26]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your ViT but faster. InICLR, 2023
work page 2023
-
[27]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
work page 2025
-
[28]
StreamingVLM: Real-time understanding for infinite video streams
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Kelly Peng, Yao Lu, and Song Han. StreamingVLM: Real-time understanding for infinite video streams. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[29]
k-means++: The advantages of careful seeding
David Arthur and Sergei Vassilvitskii. k-means++: The advantages of careful seeding. InProceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1027–1035, 2007
work page 2007
-
[30]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18992–19001, 2025. 11
work page 2025
-
[31]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-OneVision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
George L. Nemhauser, Laurence A. Wolsey, and Marshall L. Fisher. An analysis of approximations for maximizing submodular set functions.Mathematical Programming, 14(1):265–294, 1978
work page 1978
-
[33]
What shape was the meat I put on the pan?
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024. A Theory and Proofs This appendix provides the formal statements and proofs underlying two ingredients of our method: (i) the bicriteria coverage objective that we minimise as a tractable surrogate...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.