Recognition: 2 theorem links
· Lean TheoremSemantic Feature Segmentation for Interpretable Predictive Maintenance in Complex Systems
Pith reviewed 2026-05-15 02:25 UTC · model grok-4.3
The pith
Semantic feature segmentation isolates a canonical group of monitoring signals that carries the dominant information for anticipating faults.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
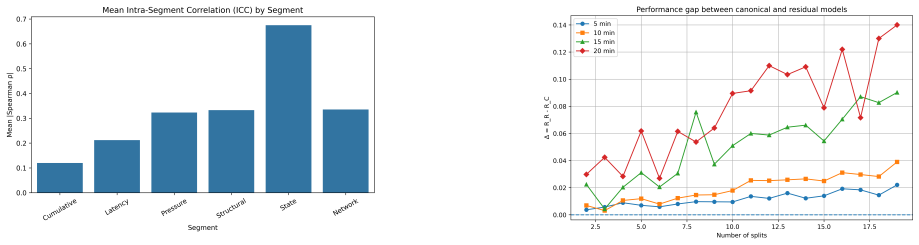
The semantic feature segmentation decomposes the monitored feature space into a canonical component that retains the dominant predictive information and a residual component containing structurally peripheral signals. Defined through domain-informed criteria that set up variables into functional groups, the decomposition yields a canonical space with consistently lower expected predictive risk than the residual space in time-aware cross-validation. The canonical segments also display stronger intra-segment coherence than inter-segment dependence, a structure that remains stable after redundancy reduction, and the space achieves predictive performance comparable to the full feature space and,
What carries the argument
Semantic feature segmentation framework that uses domain-informed criteria to partition monitoring variables into functional groups and separate them into canonical and residual components.
If this is right
- The canonical space exhibits significantly stronger intra-segment coherence than inter-segment dependence.
- This structural organization remains stable after redundancy reduction.
- Canonical space delivers predictive performance comparable to the full feature space and to PCA while preserving semantic meaning of the original variables.
- Semantic segmentation supplies an interpretable and information-preserving decomposition of monitoring signals for predictive maintenance.
Where Pith is reading between the lines
- The same grouping logic could be tested on streaming sensor data from manufacturing lines to check whether canonical components reduce the frequency of false-positive maintenance alerts.
- If the canonical-residual split generalizes, it might allow maintenance teams to monitor only a smaller subset of sensors without retraining the full model each time a new variable is added.
- Extending the approach to systems with known causal graphs could reveal whether the functional groups align with actual physical dependencies.
Load-bearing premise
The domain-informed criteria used to define functional groups and separate canonical from residual components accurately isolate the dominant predictive information without bias from the grouping choices.
What would settle it
A concrete counter-example would be a new complex system where time-aware cross-validation shows the residual space achieving lower predictive risk than the canonical space on the same fault-anticipation task.
Figures




read the original abstract
Predictive maintenance in complex systems is often complicated by the heterogeneity and redundancy of monitored variables,which can obscure fault-relevant information and reduce model interpretability. This work proposes a semantic feature segmentation framework that decomposes the monitored feature space into a canonical component,expected to retain the dominant predictive information, and a residual component containing structurally peripheral signals. The segmentation is defined through domain informed criteria and sets up monitoring variables into functional groups reflecting operational mechanisms such as throughput,latency,pressure,network activity,and structural state. To evaluate the effectiveness of this decomposition, we adopt a predictive perspective in which expected predictive risk is used as an operational proxy for task-relevant information. Experimental results obtained through time-aware cross-validation show that the canonical space consistently achieves lower predictive risk than the residual space across multiple temporal configurations, indicating that the semantic segmentation concentrates the most relevant information for fault anticipation. In addition, the canonical segments exhibit significantly stronger intra-segment coherence than inter-segment dependence, and this structural organization remains stable after redundancy reduction. When compared with the full feature space and with a Principal Component Analysis (PCA) representation, the canonical space carries out comparable predictive performance and furthermore preserves the semantic meaning of the original variables. These findings suggest that semantic feature segmentation provides an interpretable and information-preserving decomposition of monitoring signals, enabling competitive predictive performance without sacrificing the operational interpretability required in predictive maintenance applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a semantic feature segmentation framework that decomposes monitored variables in complex systems into a canonical component (retaining dominant predictive information for fault anticipation) and a residual component (containing peripheral signals), using domain-informed functional groups such as throughput, latency, pressure, network activity, and structural state. It evaluates this via expected predictive risk as a proxy under time-aware cross-validation, claiming the canonical space shows lower risk, stronger intra-segment coherence, comparable performance to the full feature space and PCA, and preserved semantic interpretability.
Significance. If the central claims hold with verifiable quantitative support, the work could offer a practical, domain-grounded alternative to black-box dimensionality reduction for predictive maintenance, improving interpretability while maintaining competitive fault-anticipation performance in heterogeneous monitoring data.
major comments (2)
- Abstract: the claim that the canonical space consistently achieves lower predictive risk than the residual space across temporal configurations is presented without any quantitative values, error bars, exact segmentation rules, or statistical tests, leaving the support for the central claim difficult to verify.
- Abstract and method description: segmentation criteria are described as domain-informed rather than optimized directly on the predictive-risk metric, with the proxy applied after the split; this setup risks the reported risk gap being expected by construction if the functional-group definitions were inspected or adjusted after observing which variables drive performance differences.
minor comments (1)
- Abstract: the phrasing 'significantly stronger intra-segment coherence' would benefit from a precise definition of the coherence metric and the statistical test used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate where revisions will be incorporated to improve verifiability and transparency.
read point-by-point responses
-
Referee: Abstract: the claim that the canonical space consistently achieves lower predictive risk than the residual space across temporal configurations is presented without any quantitative values, error bars, exact segmentation rules, or statistical tests, leaving the support for the central claim difficult to verify.
Authors: We agree that the abstract, due to its brevity, omits specific numerical values, error bars, and test details. The full manuscript reports these in the Experimental Results section (including mean risk values across temporal folds, standard deviations, and p-values from paired statistical tests). In revision we will update the abstract to include representative quantitative support (e.g., average risk reduction and significance) while retaining a pointer to the detailed tables and segmentation rules in Section 3. revision: yes
-
Referee: Abstract and method description: segmentation criteria are described as domain-informed rather than optimized directly on the predictive-risk metric, with the proxy applied after the split; this setup risks the reported risk gap being expected by construction if the functional-group definitions were inspected or adjusted after observing which variables drive performance differences.
Authors: The functional groups (throughput, latency, pressure, network activity, structural state) were fixed a priori using only domain knowledge of operational mechanisms, before any predictive-risk computation or variable inspection. No post-hoc adjustment occurred. We will add explicit wording in the revised Methods section stating the pre-experimental timeline of the segmentation to eliminate any ambiguity about circularity; the risk proxy is deliberately applied after the split to validate the domain-informed decomposition. revision: yes
Circularity Check
No circularity: domain-informed split evaluated empirically
full rationale
The segmentation into canonical and residual spaces is defined via domain-informed functional groups (throughput, latency, pressure, etc.) prior to any risk evaluation. The central result compares predictive risk on these fixed spaces using time-aware cross-validation; this is an independent empirical test rather than a quantity forced by the grouping definition or by fitting. No equations, self-citations, or ansatzes reduce the reported risk gap to the input criteria by construction. The derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain-informed criteria can define functional groups that retain the dominant predictive information for fault anticipation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
semantic feature segmentation framework that decomposes the monitored feature space into a canonical component... defined through domain-informed criteria... functional groups reflecting operational mechanisms such as throughput, latency, pressure...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
expected predictive risk... RC < RR... canonical space consistently achieves lower predictive risk than the residual space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Reliability Engineering & System Safety , author =
Modelling long- and short-term multi-dimensional patterns in predictive maintenance with accumulative attention , volume =. Reliability Engineering & System Safety , author =. 2023 , pages =. doi:10.1016/j.ress.2023.109306 , language =
-
[2]
Applied Stochastic Models in Business and Industry , author =
Explainable. Applied Stochastic Models in Business and Industry , author =. 2026 , pages =. doi:10.1002/asmb.70084 , language =
-
[3]
FeatureX: An explainable feature selection for deep learning , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.eswa.2025.127675 , author =
-
[4]
Improved. Sensors , author =. 2024 , pages =. doi:10.3390/s25010137 , language =
-
[5]
A deep learning framework for feature selection and dimensional analysis: Variational explainable neural networks , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.knosys.2025.113940 , author =
-
[6]
Strategies for overcoming data scarcity, imbalance, and feature selection challenges in machine learning models for predictive maintenance , volume =. Scientific Reports , author =. 2024 , pages =. doi:10.1038/s41598-024-59958-9 , language =
-
[7]
Multimedia Tools and Applications , author =
Few-shot semantic segmentation in complex industrial components , volume =. Multimedia Tools and Applications , author =. 2024 , pages =. doi:10.1007/s11042-024-19018-w , language =
-
[8]
The American Journal of Psychology , author =
The. The American Journal of Psychology , author =. 1904 , pages =. doi:10.2307/1412159 , number =
-
[9]
The Annals of Mathematical Statistics , author =
On a. The Annals of Mathematical Statistics , author =. 1947 , pages =. doi:10.1214/aoms/1177730491 , language =
-
[10]
Biometrics Bulletin , author =
Individual. Biometrics Bulletin , author =. 1945 , pages =. doi:10.2307/3001968 , number =
-
[11]
Neural Processing Letters , author =
A. Neural Processing Letters , author =. 2024 , pages =. doi:10.1007/s11063-024-11440-3 , language =
-
[12]
Feature selection by replicate reproducibility and non-redundancy , volume =. Bioinformatics , author =. 2024 , pages =. doi:10.1093/bioinformatics/btae548 , language =
-
[13]
Mastriani Emilio and Costa, Alessandro and Incardona, Federico and Munari, Kevin and Spinello, Sebastiano , title =
-
[14]
A. Procedia CIRP , author =. 2017 , pages =. doi:10.1016/j.procir.2016.09.015 , language =
-
[15]
IEEE Transactions on Power Electronics , author =
A. IEEE Transactions on Power Electronics , author =. 2017 , pages =. doi:10.1109/TPEL.2016.2608842 , number =
-
[16]
Mechanical Systems and Signal Processing , author =
Deep learning and its applications to machine health monitoring , volume =. Mechanical Systems and Signal Processing , author =. 2019 , pages =. doi:10.1016/j.ymssp.2018.05.050 , language =
-
[17]
Computers & Industrial Engineering , author =
A systematic literature review of machine learning methods applied to predictive maintenance , volume =. Computers & Industrial Engineering , author =. 2019 , pages =. doi:10.1016/j.cie.2019.106024 , language =
-
[18]
Discover Applied Sciences , author =
A review of explainable. Discover Applied Sciences , author =. 2025 , pages =. doi:10.1007/s42452-025-07908-z , language =
-
[19]
Data , VOLUME =
Hassan, Ietezaz Ul and Panduru, Krishna and Walsh, Joseph , TITLE =. Data , VOLUME =. 2024 , NUMBER =
2024
-
[20]
2002 , publisher=
Principal Component Analysis , author=. 2002 , publisher=
2002
-
[21]
Journal of Machine Learning Research , volume=
An introduction to variable and feature selection , author=. Journal of Machine Learning Research , volume=
-
[22]
A rigorous and versatile statistical test for correlations between stationary time series , volume =. PLOS Biology , author =. 2024 , pages =. doi:10.1371/journal.pbio.3002758 , language =
-
[23]
Shlens, Jonathon , month = apr, year =. A. doi:10.48550/arXiv.1404.1100 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1404.1100
-
[24]
ACM Computing Surveys , author =
Feature. ACM Computing Surveys , author =. 2018 , pages =. doi:10.1145/3136625 , language =
-
[25]
The European Physical Journal B , author =
Hierarchical structure in financial markets , volume =. The European Physical Journal B , author =. 1999 , pages =. doi:10.1007/s100510050929 , language =
-
[26]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[27]
Chen, Tianqi and Guestrin, Carlos , month = aug, year =. Proceedings of the 22nd. doi:10.1145/2939672.2939785 , language =
-
[28]
Random. Machine Learning , author =. 2001 , pages =. doi:10.1023/A:1010933404324 , language =
-
[29]
2015, , 579, A101
Aladro, R., Martín, S., Riquelme, D., et al. 2015, , 579, A101
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.