Recognition: 2 theorem links
· Lean TheoremAnyBand-Diff: A Unified Remote Sensing Image Generation and Band Repair Framework with Spectral Priors
Pith reviewed 2026-05-15 01:56 UTC · model grok-4.3
The pith
AnyBand-Diff reconstructs complete spectral information in remote sensing images from arbitrary band subsets using physics-guided diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AnyBand-Diff achieves accurate spectral reconstruction and reliable imagery generation by integrating a Masked Conditional Diffusion backbone with dual stochastic masking, Physics-Guided Sampling using gradients from a differentiable physical model, and a Multi-Scale Physical Loss to enforce constraints across pixel, region, and global levels.
What carries the argument
The Physics-Guided Sampling mechanism, which leverages gradients from a differentiable physical model to steer the denoising trajectory toward physically plausible solutions.
If this is right
- Generated images maintain radiometric fidelity suitable for quantitative analysis in remote sensing applications.
- The framework supports reconstruction from any combination of input bands, increasing flexibility in data processing pipelines.
- Multi-scale loss ensures consistency at local and global levels, reducing artifacts in large-scale imagery.
- Physics integration reduces spectral distortion compared to standard diffusion approaches.
Where Pith is reading between the lines
- Similar physics-guided techniques could improve generative models in other domains requiring physical consistency, such as medical imaging or climate modeling.
- Future work might test the framework's robustness on diverse satellite sensors beyond those used in the experiments.
- Integrating additional physical priors could further enhance performance in complex atmospheric conditions.
Load-bearing premise
The differentiable physical model accurately captures real-world radiometric and spectral relationships so that its gradients steer the process to valid solutions without new artifacts.
What would settle it
A direct comparison of the spectral signatures in generated images against independent ground-truth spectrometer measurements from the same locations would show whether the outputs match physical expectations or introduce distortions.
Figures



read the original abstract
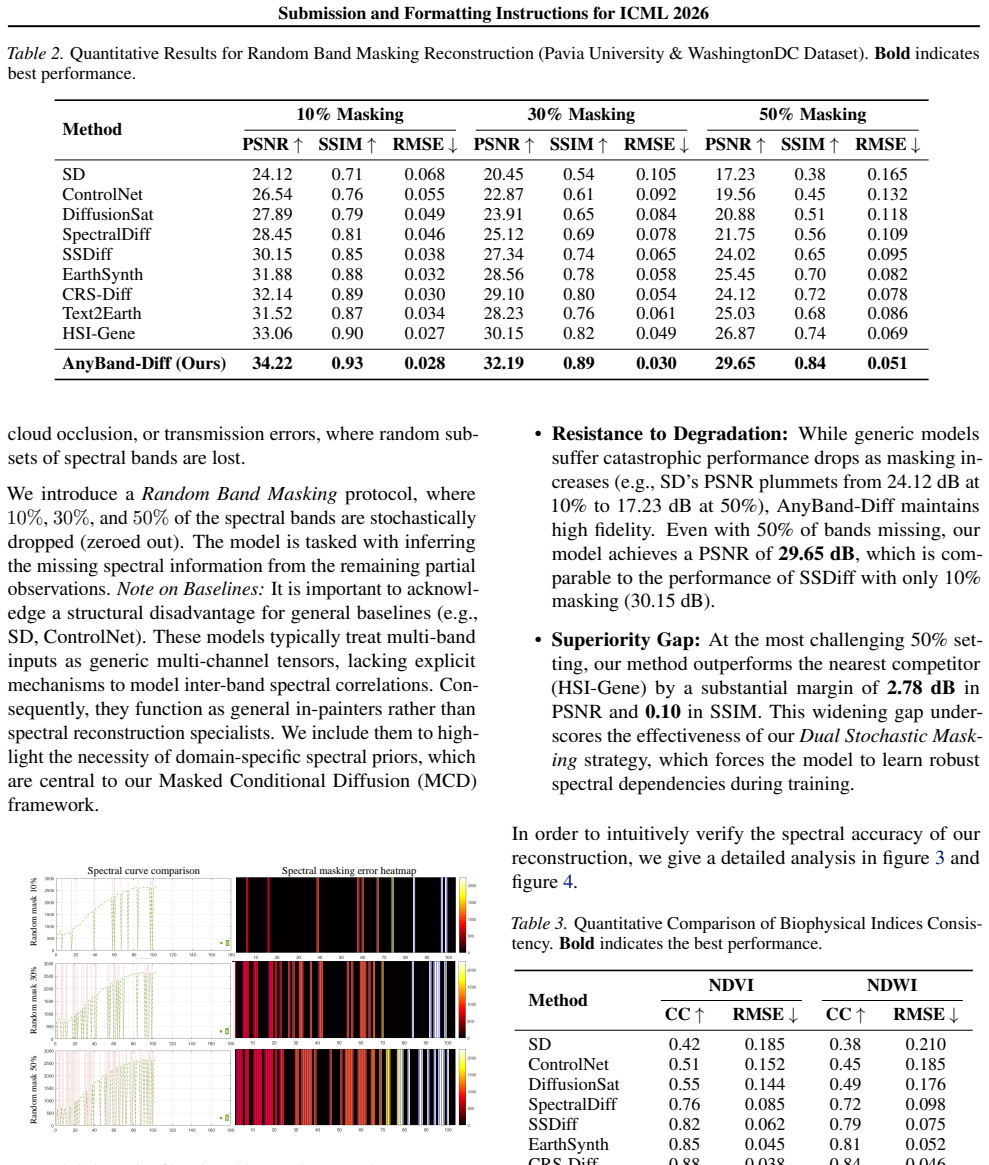
Existing diffusion models have made significant progress in generating realistic images. However, their direct adaptation to remote sensing imagery often disregards intrinsic physical laws. This oversight frequently leads to spectral distortion and radiometric inconsistency, severely limiting the scientific utility of generated data. To address this issue, this paper introduces AnyBand-Diff, a novel spectral-prior-guided diffusion framework tailored for robust spectral reconstruction. Specifically, we design a Masked Conditional Diffusion backbone integrated with a dual stochastic masking strategy, empowering the model to recover complete spectral information from arbitrary band subsets. Subsequently, to ensure radiometric fidelity, a Physics-Guided Sampling mechanism is proposed, leveraging gradients from a differentiable physical model to explicitly steer the denoising trajectory toward the manifold of physically plausible solutions. Furthermore, a Multi-Scale Physical Loss is formulated to enforce rigorous constraints across pixel, region, and global levels in a joint manner. Extensive experiments confirm the effectiveness of AnyBand-Diff in generating reliable imagery and achieving accurate spectral reconstruction, contributing to the advancement of physics-aware generative methods for Earth observation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AnyBand-Diff, a diffusion-based framework for remote sensing image generation and arbitrary-band repair. It combines a Masked Conditional Diffusion backbone with dual stochastic masking to recover full spectra from partial band inputs, a Physics-Guided Sampling step that uses gradients from a differentiable physical model to steer denoising toward radiometrically plausible outputs, and a Multi-Scale Physical Loss enforcing constraints at pixel, region, and global scales. The abstract asserts that extensive experiments confirm accurate spectral reconstruction and reliable imagery generation.
Significance. If the central claims hold after proper validation, the work could advance physics-aware generative modeling for Earth observation by reducing spectral distortion and radiometric inconsistency that currently limit the scientific utility of synthetic remote-sensing data. The explicit incorporation of differentiable physical priors and multi-scale losses represents a potentially useful direction beyond standard conditional diffusion approaches.
major comments (3)
- [Abstract] Abstract: the claim that 'extensive experiments confirm the effectiveness' is unsupported because the abstract (and, per the provided description, the manuscript) supplies no quantitative metrics, baseline comparisons, error bars, or ablation results on held-out radiometric or spectral fidelity measures.
- [Physics-Guided Sampling] Physics-Guided Sampling description: the mechanism is stated to steer the denoising trajectory via gradients from a differentiable physical model, yet the manuscript provides neither the explicit equations of this model, the sensor/atmospheric/illumination parameters it employs, nor any ablation demonstrating that the steered samples improve over unguided diffusion on radiometric metrics.
- [Multi-Scale Physical Loss] Multi-Scale Physical Loss: the formulation is described only at a high level (pixel/region/global constraints); without the precise mathematical definition or weighting scheme, it is impossible to evaluate whether the loss actually enforces physical consistency or merely adds an auxiliary regularizer.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive experiments confirm the effectiveness' is unsupported because the abstract (and, per the provided description, the manuscript) supplies no quantitative metrics, baseline comparisons, error bars, or ablation results on held-out radiometric or spectral fidelity measures.
Authors: We agree that the abstract would be improved by including concrete quantitative support. In the revised manuscript we will update the abstract to summarize key results from the experiments, specifically referencing spectral reconstruction metrics (e.g., SAM and RMSE) and baseline comparisons reported in the main text and tables. revision: yes
-
Referee: [Physics-Guided Sampling] Physics-Guided Sampling description: the mechanism is stated to steer the denoising trajectory via gradients from a differentiable physical model, yet the manuscript provides neither the explicit equations of this model, the sensor/atmospheric/illumination parameters it employs, nor any ablation demonstrating that the steered samples improve over unguided diffusion on radiometric metrics.
Authors: The current description is high-level. We will expand Section 3.2 to include the explicit equations of the differentiable physical model, the specific sensor response functions, atmospheric parameters (e.g., from the 6S model), and illumination estimation procedure. We will also add an ablation study in the experiments section that directly compares guided versus unguided sampling on held-out radiometric and spectral fidelity metrics. revision: yes
-
Referee: [Multi-Scale Physical Loss] Multi-Scale Physical Loss: the formulation is described only at a high level (pixel/region/global constraints); without the precise mathematical definition or weighting scheme, it is impossible to evaluate whether the loss actually enforces physical consistency or merely adds an auxiliary regularizer.
Authors: We will revise the manuscript to provide the full mathematical definitions of the pixel-level, region-level, and global-level terms in the Multi-Scale Physical Loss, together with the exact weighting scheme used in the joint optimization. This will clarify how the loss enforces physical consistency beyond a simple regularizer. revision: yes
Circularity Check
No circularity: new architectural components and losses are independent of fitted inputs
full rationale
The derivation introduces a Masked Conditional Diffusion backbone with dual stochastic masking, Physics-Guided Sampling via gradients from a differentiable physical model, and a Multi-Scale Physical Loss. None of these reduce by construction to parameters fitted on the same data or to self-referential definitions; the physical model is invoked as an external steering mechanism rather than derived from the diffusion outputs themselves. No self-citation chains, uniqueness theorems, or renamed empirical patterns appear as load-bearing steps in the abstract or described framework. The claims rest on the proposed components plus external experiments, making the chain self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A differentiable physical model exists that accurately captures radiometric and spectral relationships in remote sensing imagery
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Physics-Guided Sampling mechanism is proposed, leveraging gradients from a differentiable physical model to explicitly steer the denoising trajectory toward the manifold of physically plausible solutions
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Multi-Scale Physical Loss ... Pixel-Level: Spectral Correlation Constraint ... Lpixel = ||C(X̂0) - S||_F^2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
The changing risk and burden of wildfire in the united states
Burke, M., Driscoll, A., Heft-Neal, S., Xue, J., Burney, J., and Wara, M. The changing risk and burden of wildfire in the united states. Proceedings of the National Academy of Sciences, 118 0 (2): 0 e2011048118, 2021
work page 2021
-
[3]
Spectraldiff: A generative framework for hyperspectral image classification with diffusion models
Chen, N., Yue, J., Fang, L., and Xia, S. Spectraldiff: A generative framework for hyperspectral image classification with diffusion models. IEEE Transactions on Geoscience and Remote Sensing, 61: 0 1--16, 2023
work page 2023
-
[4]
Ambient diffusion: Learning clean distributions from corrupted data
Daras, G., Shah, K., Dagan, Y., Gollakota, A., Dimakis, A., and Klivans, A. Ambient diffusion: Learning clean distributions from corrupted data. Advances in Neural Information Processing Systems, 36: 0 288--313, 2023
work page 2023
-
[5]
de Ara \'u jo, B. M. P. B., von Bloh, M., Rupprecht, V., Schaefer, H., and Asseng, S. Bird’s-eye view: Remote sensing insights into the impact of mowing events on eurasian curlew habitat selection. Agriculture, Ecosystems & Environment, 378: 0 109299, 2025
work page 2025
-
[6]
L., Xu, F., Hu, Y., B \"o sch, H., Landgraf, J., and Li, Z
Dubovik, O., Schuster, G. L., Xu, F., Hu, Y., B \"o sch, H., Landgraf, J., and Li, Z. Grand challenges in satellite remote sensing, 2021
work page 2021
-
[8]
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M \"u ller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[9]
Rsvq-diffusion model for text-to-remote-sensing image generation
Gao, X., Fu, Y., Jiang, X., Wu, F., Zhang, Y., Fu, T., Li, C., and Pei, J. Rsvq-diffusion model for text-to-remote-sensing image generation. Applied Sciences, 15 0 (3): 0 1121, 2025
work page 2025
-
[10]
M., Drees, L., Toker, A., Asseng, S., and von Bloh, M
Goktepe, M., hossein Shamseddin, A., Uysal, E., Monteagudo, J. M., Drees, L., Toker, A., Asseng, S., and von Bloh, M. Ecomapper: Generative modeling for climate-aware satellite imagery. In Forty-second International Conference on Machine Learning, 2025
work page 2025
-
[11]
Frequency generation for real-world image super-resolution
Guan, W., Li, H., Xu, D., Liu, J., Gong, S., and Liu, J. Frequency generation for real-world image super-resolution. IEEE Transactions on Circuits and Systems for Video Technology, 34 0 (8): 0 7029--7040, 2024
work page 2024
- [12]
-
[13]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[14]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33: 0 6840--6851, 2020
work page 2020
-
[15]
Hodson, T. O. Root mean square error (rmse) or mean absolute error (mae): When to use them or not. Geoscientific Model Development Discussions, 2022: 0 1--10, 2022
work page 2022
-
[16]
Hore, A. and Ziou, D. Image quality metrics: Psnr vs. ssim. In 2010 20th International Conference on Pattern Recognition, pp.\ 2366--2369, 2010
work page 2010
- [17]
-
[18]
Hussain, S., Lu, L., Mubeen, M., Nasim, W., Karuppannan, S., Fahad, S., Tariq, A., Mousa, B., Mumtaz, F., and Aslam, M. Spatiotemporal variation in land use land cover in the response to local climate change using multispectral remote sensing data. Land, 11 0 (5): 0 595, 2022
work page 2022
-
[19]
Glob-diffusion: A global consistent diffusion model for large-scale image generation
Kang, Y., Shi, H., Liu, H., Xie, W., Fang, L., and Bruzzone, L. Glob-diffusion: A global consistent diffusion model for large-scale image generation. IEEE Transactions on Circuits and Systems for Video Technology, pp.\ 1--1, 2025
work page 2025
-
[20]
Diffusionsat: A generative foundation model for satellite imagery
Khanna, S., Liu, P., Zhou, L., Meng, C., Rombach, R., Burke, M., Lobell, D., and Ermon, S. Diffusionsat: A generative foundation model for satellite imagery. In Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., and Sun, Y. (eds.), International Conference on Representation Learning, volume 2024, pp.\ 5586--5604, 2024
work page 2024
-
[21]
Le, T.-T.-H., Truong, T.-T.-H., and Nguyen, C.-T. Enhancing ship detection in remote sensing: A data augmentation approach using state-of-the-art text-to-image diffusion. In 2025 International Conference on Multimedia Analysis and Pattern Recognition (MAPR), pp.\ 1--6, 2025
work page 2025
-
[22]
Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., and Lee, Y. J. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 22511--22521, 2023
work page 2023
-
[23]
Li, Z., Chen, B., Wu, S., Su, M., Chen, J. M., and Xu, B. Deep learning for urban land use category classification: A review and experimental assessment. Remote Sensing of Environment, 311: 0 114290, 2024
work page 2024
-
[24]
Liu, C., Chen, K., Zhao, R., Zou, Z., and Shi, Z. Text2earth: Unlocking text-driven remote sensing image generation with a global-scale dataset and a foundation model. IEEE Geoscience and Remote Sensing Magazine, 2025 a
work page 2025
-
[25]
Black box adversarial sample generation of remote sensing image description
Liu, G., Li, Y., Fang, S., Shang, R., and Jiao, L. Black box adversarial sample generation of remote sensing image description. In IGARSS 2025 - 2025 IEEE International Geoscience and Remote Sensing Symposium, pp.\ 6633--6636, 2025 b
work page 2025
-
[26]
Diffusion models meet remote sensing: Principles, methods, and perspectives
Liu, Y., Yue, J., Xia, S., Ghamisi, P., Xie, W., and Fang, L. Diffusion models meet remote sensing: Principles, methods, and perspectives. IEEE Transactions on Geoscience and Remote Sensing, 2024
work page 2024
-
[27]
Ctigen-cdm: Controlled text-to-image generation using cropped diffusion models
Liu, Y., Huang, J., Wen, S., He, X., Zhang, W., and Feng, Z. Ctigen-cdm: Controlled text-to-image generation using cropped diffusion models. IEEE Transactions on Circuits and Systems for Video Technology, 35 0 (12): 0 11849--11862, 2025 c
work page 2025
-
[28]
Long, Y., Xia, G.-S., Li, S., Yang, W., Yang, M. Y., Zhu, X. X., Zhang, L., and Li, D. On creating benchmark dataset for aerial image interpretation: Reviews, guidances, and million-aid. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14: 0 4205--4230, 2021
work page 2021
-
[29]
Exploring models and data for remote sensing image caption generation
Lu, X., Wang, B., Zheng, X., and Li, X. Exploring models and data for remote sensing image caption generation. IEEE Transactions on Geoscience and Remote Sensing, 56 0 (4): 0 2183--2195, 2017
work page 2017
-
[30]
Meng, Y., Li, W., Lei, S., Zou, Z., and Shi, Z. Large-factor super-resolution of remote sensing images with spectra-guided generative adversarial networks. IEEE Transactions on Geoscience and Remote Sensing, 60: 0 1--11, 2022
work page 2022
-
[31]
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., and Shan, Y. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI Conference On Artificial Intelligence, volume 38, pp.\ 4296--4304, 2024
work page 2024
-
[32]
Physics-based generative adversarial models for image restoration and beyond
Pan, J., Dong, J., Liu, Y., Zhang, J., Ren, J., Tang, J., Tai, Y.-W., and Yang, M.-H. Physics-based generative adversarial models for image restoration and beyond. IEEE transactions on pattern analysis and machine intelligence, 43 0 (7): 0 2449--2462, 2020
work page 2020
-
[33]
Earthsynth: Generating informative earth observation with diffusion models, 2025
Pan, J., Lei, S., Fu, Y., Li, J., Liu, Y., Sun, Y., He, X., Peng, L., Huang, X., and Zhao, B. Earthsynth: Generating informative earth observation with diffusion models, 2025
work page 2025
-
[34]
Hsigene: A foundation model for hyperspectral image generation
Pang, L., Cao, X., Tang, D., Xu, S., Bai, X., Zhou, F., and Meng, D. Hsigene: A foundation model for hyperspectral image generation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 48 0 (1): 0 730--746, 2026
work page 2026
-
[35]
Raissi, M., Perdikaris, P., and Karniadakis, G. E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378: 0 686--707, 2019
work page 2019
-
[36]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 10684--10695, 2022
work page 2022
-
[37]
Geosynth: Contextually-aware high-resolution satellite image synthesis
Sastry, S., Khanal, S., Dhakal, A., and Jacobs, N. Geosynth: Contextually-aware high-resolution satellite image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 460--470, 2024
work page 2024
-
[38]
Sebaq, A. and ElHelw, M. Rsdiff: Remote sensing image generation from text using diffusion model. Neural Computing and Applications, 36 0 (36): 0 23103--23111, 2024
work page 2024
-
[39]
Shirmard, H., Farahbakhsh, E., M \"u ller, R. D., and Chandra, R. A review of machine learning in processing remote sensing data for mineral exploration. Remote Sensing of Environment, 268: 0 112750, 2022
work page 2022
-
[40]
Sui, J., Wu, Q., and Pun, M.-O. Denoising diffusion probabilistic model with adversarial learning for remote sensing super-resolution. Remote Sensing, 16 0 (7): 0 1219, 2024
work page 2024
-
[41]
Tang, C., Powell, J., Koch, D., Mullins, R. D., Weddell, A. S., and Chauhan, J. Physwin: An efficient and physically-informed foundation model for multispectral earth observation. In Advances in Neural Information Processing Systems, 2020
work page 2020
-
[42]
Crs-diff: Controllable remote sensing image generation with diffusion model
Tang, D., Cao, X., Hou, X., Jiang, Z., Liu, J., and Meng, D. Crs-diff: Controllable remote sensing image generation with diffusion model. IEEE Transactions on Geoscience and Remote Sensing, 62: 0 1--14, 2024
work page 2024
-
[43]
Aerogen: Enhancing remote sensing object detection with diffusion-driven data generation
Tang, D., Cao, X., Wu, X., Li, J., Yao, J., Bai, X., Jiang, D., Li, Y., and Meng, D. Aerogen: Enhancing remote sensing object detection with diffusion-driven data generation. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp.\ 3614--3624, June 2025
work page 2025
-
[44]
Tian, J., Wu, J., Chen, H., and Ma, M. Mapgen-diff: An end-to-end remote sensing image to map generator via denoising diffusion bridge model. Remote Sensing, 16 0 (19): 0 3716, 2024
work page 2024
-
[45]
Wang, C. and Sun, W. Controllable reference-based real-world remote sensing image super-resolution with generative diffusion priors, 2025
work page 2025
-
[46]
High-resolution image synthesis and semantic manipulation with conditional gans
Wang, T.-C., Liu, M.-Y., Zhu, J.-Y., Tao, A., Kautz, J., and Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 8798--8807, 2018
work page 2018
-
[47]
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13 0 (4): 0 600--612, 2004
work page 2004
-
[48]
Willmott, C. J. and Matsuura, K. Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance. Climate research, 30 0 (1): 0 79--82, 2005
work page 2005
-
[49]
Sfhn: Spatial-frequency domain hybrid network for image super-resolution
Wu, Z., Liu, W., Li, J., Xu, C., and Huang, D. Sfhn: Spatial-frequency domain hybrid network for image super-resolution. IEEE Transactions on Circuits and Systems for Video Technology, 33 0 (11): 0 6459--6473, 2023
work page 2023
-
[50]
Data augmentation for remote sensing semantic segmentation via controllable diffusion models
Xie, M., Gong, J., Gao, Z., and Cao, M. Data augmentation for remote sensing semantic segmentation via controllable diffusion models. In IGARSS 2025 - 2025 IEEE International Geoscience and Remote Sensing Symposium, pp.\ 6132--6136, 2025
work page 2025
-
[51]
Dldc: A dual loop data cleaning method for fine-tuning remote sensing image generative models
Xing, T., Yan, H., Wang, X., Sun, K., Yu, H., Li, P., and Zhao, Q. Dldc: A dual loop data cleaning method for fine-tuning remote sensing image generative models. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 18: 0 28709--28725, 2025
work page 2025
-
[52]
Metaearth: A generative foundation model for global-scale remote sensing image generation
Yu, Z., Liu, C., Liu, L., Shi, Z., and Zou, Z. Metaearth: A generative foundation model for global-scale remote sensing image generation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 47 0 (3): 0 1764--1781, 2025 a
work page 2025
-
[53]
A guideline of u-net-based framework for precipitation estimates
Yu, Z., Wang, H., and Chen, H. A guideline of u-net-based framework for precipitation estimates. International Journal of Artificial Intelligence for Science (IJAI4S), 1 0 (1), 2025 b
work page 2025
-
[54]
Zachow, M., Kunstmann, H., Miralles, D. J., and Asseng, S. Multi-model ensembles for regional and national wheat yield forecasts in argentina. Environmental Research Letters, 19 0 (8): 0 084037, 2024
work page 2024
-
[55]
Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., and Metaxas, D. N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 5907--5915, 2017
work page 2017
-
[56]
Adding conditional control to text-to-image diffusion models
Zhang, L., Rao, A., and Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 3836--3847, 2023 a
work page 2023
-
[57]
Zhang, M., Liu, Y., Liu, Y., Zhao, Y., and Ye, Q. Cc-diff++: Spatially controllable text-to-image synthesis for remote sensing with enhanced contextual coherence. IEEE Transactions on Geoscience and Remote Sensing, 63: 0 1--16, 2025 a
work page 2025
-
[58]
A., Shechtman, E., and Wang, O
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 586--595, 2018
work page 2018
-
[60]
Cascaded autoregressive diffusion models for remote sensing scene generation
Zhang, Y., Liu, L., Chen, K., Xu, J., Shi, Z., and Zou, Z. Cascaded autoregressive diffusion models for remote sensing scene generation. IEEE Transactions on Geoscience and Remote Sensing, 63: 0 1--17, 2025 b
work page 2025
-
[61]
Zhao, S., Chen, D., Chen, Y.-C., Bao, J., Hao, S., Yuan, L., and Wong, K.-Y. K. Uni-controlnet: All-in-one control to text-to-image diffusion models. Advances in Neural Information Processing Systems, 36: 0 11127--11150, 2023
work page 2023
-
[62]
Diverse text-prompt generation for remote sensing image classification
Zhao, W., Lv, X., He, R., Zhao, F., Wang, H., and He, Y. Diverse text-prompt generation for remote sensing image classification. IEEE Transactions on Geoscience and Remote Sensing, 63: 0 1--10, 2025. doi:10.1109/TGRS.2024.3522283
-
[63]
Ssdiff: Spatial-spectral integrated diffusion model for remote sensing pansharpening
Zhong, Y., Wu, X., Cao, Z., Dou, H.-X., and Deng, L.-J. Ssdiff: Spatial-spectral integrated diffusion model for remote sensing pansharpening. Advances in Neural Information Processing Systems, 37: 0 77962--77986, 2024
work page 2024
-
[64]
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 2223--2232, 2017
work page 2017
-
[65]
Diffcr: A fast conditional diffusion framework for cloud removal from optical satellite images
Zou, X., Li, K., Xing, J., Zhang, Y., Wang, S., Jin, L., and Tao, P. Diffcr: A fast conditional diffusion framework for cloud removal from optical satellite images. IEEE Transactions on Geoscience and Remote Sensing, 62: 0 1--14, 2024
work page 2024
-
[66]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Unpaired image-to-image translation using cycle-consistent adversarial networks , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[67]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
High-resolution image synthesis and semantic manipulation with conditional gans , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[68]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
HSIGene: A Foundation Model for Hyperspectral Image Generation , year=
Pang, Li and Cao, Xiangyong and Tang, Datao and Xu, Shuang and Bai, Xueru and Zhou, Feng and Meng, Deyu , journal=. HSIGene: A Foundation Model for Hyperspectral Image Generation , year=
-
[70]
IEEE Geoscience and Remote Sensing Magazine , year=
Text2Earth: Unlocking text-driven remote sensing image generation with a global-scale dataset and a foundation model , author=. IEEE Geoscience and Remote Sensing Magazine , year=
-
[71]
CRS-Diff: Controllable Remote Sensing Image Generation With Diffusion Model , year=
Tang, Datao and Cao, Xiangyong and Hou, Xingsong and Jiang, Zhongyuan and Liu, Junmin and Meng, Deyu , journal=. CRS-Diff: Controllable Remote Sensing Image Generation With Diffusion Model , year=
-
[72]
Zhang, Mu and Liu, Yunfan and Liu, Yue and Zhao, Yuzhong and Ye, Qixiang , journal=. CC-Diff++: Spatially Controllable Text-to-Image Synthesis for Remote Sensing With Enhanced Contextual Coherence , year=
-
[73]
RSVQ-Diffusion Model for Text-to-Remote-Sensing Image Generation , author=. Applied Sciences , volume=
-
[74]
Meng, Yapeng and Li, Wenyuan and Lei, Sen and Zou, Zhengxia and Shi, Zhenwei , journal=. Large-Factor Super-Resolution of Remote Sensing Images With Spectra-Guided Generative Adversarial Networks , year=
-
[75]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=
-
[76]
Advances in Neural Information Processing Systems , year=
PhySwin: An Efficient and Physically-Informed Foundation Model for Multispectral Earth Observation , author=. Advances in Neural Information Processing Systems , year=
-
[77]
IEEE transactions on pattern analysis and machine intelligence , volume=
Physics-based generative adversarial models for image restoration and beyond , author=. IEEE transactions on pattern analysis and machine intelligence , volume=
-
[78]
Image quality metrics: PSNR vs. SSIM , author=. 2010 20th International Conference on Pattern Recognition , pages=
work page 2010
-
[79]
Geoscientific Model Development Discussions , volume=
Root mean square error (RMSE) or mean absolute error (MAE): When to use them or not , author=. Geoscientific Model Development Discussions , volume=
-
[80]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Adding conditional control to text-to-image diffusion models , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[81]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[82]
DiffusionSat: A Generative Foundation Model for Satellite Imagery , volume =
Khanna, Samar and Liu, Patrick and Zhou, Linqi and Meng, Chenlin and Rombach, Robin and Burke, Marshall and Lobell, David and Ermon, Stefano , booktitle =. DiffusionSat: A Generative Foundation Model for Satellite Imagery , volume =
-
[83]
Controllable Reference-Based Real-World Remote Sensing Image Super-Resolution with Generative Diffusion Priors , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.