Recognition: no theorem link
Learning with Semantic Priors: Stabilizing Point-Supervised Infrared Small Target Detection via Hierarchical Knowledge Distillation
Pith reviewed 2026-05-15 01:53 UTC · model grok-4.3
The pith
A frozen vision foundation model supplies semantic priors to stabilize point-supervised infrared small target detection through hierarchical distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
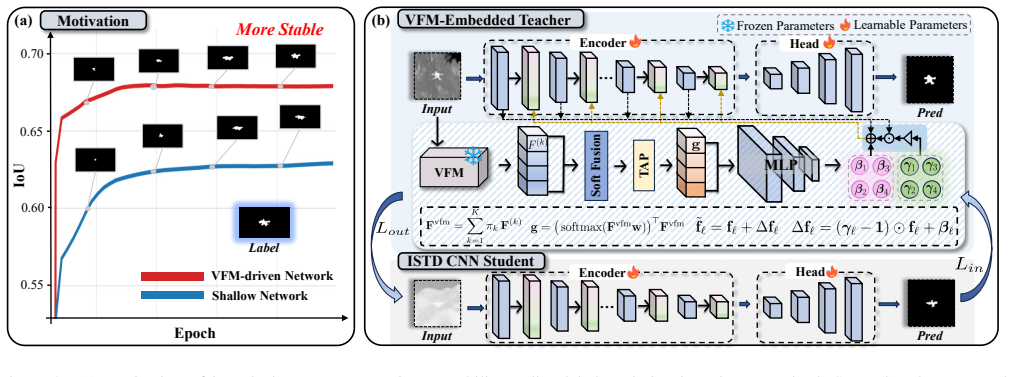
Point-supervised infrared small target detection can be cast as a bilevel optimization in which a frozen VFM-embedded teacher adapts on reweighted samples in the inner loop and supplies validation-guided knowledge to a lightweight student in the outer loop; Semantic-Conditioned Affine Modulation then injects the resulting semantic priors at multiple feature layers, and dynamic collaborative learning with cluster-level reweighting mitigates pseudo-label noise, yielding consistent improvements in detection accuracy and training stability across diverse ISTD backbones.
What carries the argument
Hierarchical VFM-driven knowledge distillation that uses bilevel optimization and Semantic-Conditioned Affine Modulation (SCAM) to transfer semantic priors from a frozen Vision Foundation Model into lightweight CNN features.
If this is right
- The same bilevel setup and SCAM modulation can be attached to any existing ISTD backbone to reduce pseudo-label noise.
- Cluster-level reweighting makes the student robust to imperfect pseudo-masks generated from point labels.
- Validation-guided outer-loop transfer limits training-set bias that otherwise destabilizes lightweight detectors.
- Semantic injection at multiple layers improves localization of weak targets under heavy background clutter.
Where Pith is reading between the lines
- If future vision foundation models capture more infrared-relevant structure, the same frozen-teacher recipe would raise the performance ceiling without retraining the teacher.
- The bilevel formulation suggests a general recipe for stabilizing weak supervision in other sensor modalities where dense labels are costly.
- SCAM-style modulation may allow semantic transfer even when the source and target domains differ in spectral characteristics.
Load-bearing premise
A frozen general-purpose vision foundation model can supply semantic priors that transfer reliably to infrared small targets via SCAM modulation and bilevel optimization without domain-specific adaptation or overfitting.
What would settle it
Run the framework on a new infrared dataset containing clutter patterns absent from the VFM pretraining distribution and measure whether detection metrics improve or training instability increases compared with the baseline point-supervised method.
Figures



read the original abstract
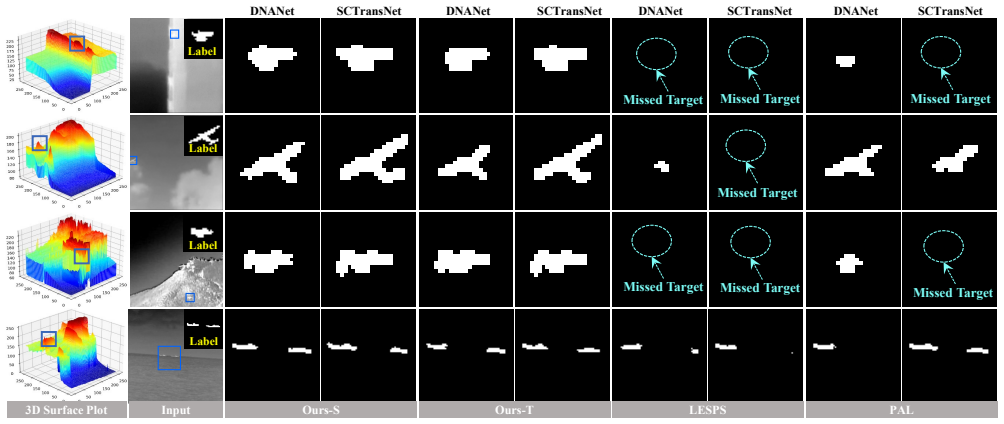
Single-frame Infrared Small Target Detection (ISTD) aims to localize weak targets under heavy background clutter, yet dense pixel-wise annotations are expensive. Point supervision with online label evolution reduces annotation cost; however, lightweight CNN detectors often lack sufficient semantics, leading to noisy pseudo-masks and unstable optimization. To address this, we propose a hierarchical VFM-driven knowledge distillation framework that uses a frozen Vision Foundation Model (VFM) during training. We formulate point-supervised learning as a bilevel optimization process: the inner loop adapts a VFM-embedded teacher on reweighted training samples, while the outer loop transfers validation-guided knowledge to a lightweight student to mitigate pseudo-label noise and training-set bias. We further introduce Semantic-Conditioned Affine Modulation (SCAM) to inject VFM semantics into CNN features at multiple layers. In addition, a dynamic collaborative learning strategy with cluster-level sample reweighting enhances robustness to imperfect pseudo-masks. Experiments on diverse challenging cases across multiple ISTD backbones demonstrate consistent improvements in detection accuracy and training stability. Our code is available at https://github.com/yuanhang-yao/semantic-prior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
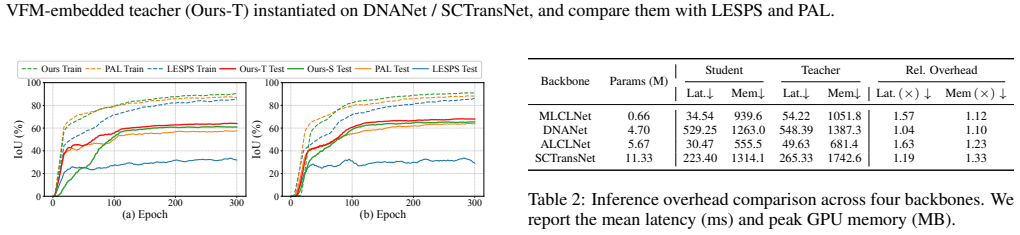
Summary. The manuscript proposes a hierarchical VFM-driven knowledge distillation framework for point-supervised single-frame infrared small target detection (ISTD). It formulates the problem as bilevel optimization in which an inner loop adapts a frozen Vision Foundation Model (VFM) teacher on cluster-reweighted samples while an outer loop distills validation-guided knowledge to a lightweight CNN student. Semantic-Conditioned Affine Modulation (SCAM) is introduced to inject VFM semantics into CNN features at multiple layers, and a dynamic collaborative reweighting strategy is added to mitigate noisy pseudo-masks. Experiments are claimed to show consistent gains in detection accuracy and training stability across multiple ISTD backbones.
Significance. If the empirical claims hold, the work would be moderately significant for annotation-efficient ISTD, as point supervision plus external semantic priors could lower labeling cost while improving stability. The bilevel formulation and SCAM modulation constitute a concrete technical contribution. However, the central premise—that a frozen RGB-trained VFM supplies reliable, transferable priors to thermal IR small-target imagery without domain adaptation—remains unproven in the provided description and would need rigorous ablation to establish load-bearing value.
major comments (3)
- [Abstract] Abstract: the claim of 'consistent improvements in detection accuracy and training stability' across backbones is stated without any numerical metrics, baseline comparisons, standard deviations, or ablation tables. This absence prevents assessment of effect size and robustness, which is load-bearing for the central claim of stabilization via VFM priors.
- [Method] Method (SCAM and bilevel sections): the assertion that a frozen general-purpose VFM reliably supplies semantic priors transferable to IR small targets via SCAM modulation lacks supporting evidence that VFM embeddings are not largely irrelevant or noisy in the thermal regime. Without an ablation replacing the VFM with a random or domain-adapted encoder (or showing performance collapse when SCAM is removed), it remains possible that the bilevel reweighting alone drives the gains, rendering the VFM component non-load-bearing.
- [Experiments] Experiments: the manuscript asserts gains 'across multiple ISTD backbones' and 'diverse challenging cases' but supplies no quantitative tables, no error bars, and no statistical significance tests. This omission directly undermines the reproducibility and generality claims that are central to the contribution.
minor comments (2)
- [Abstract] The code link is provided, which supports reproducibility; however, the repository should include the exact training scripts, hyper-parameters, and the VFM checkpoint used.
- [Method] Notation for SCAM (Semantic-Conditioned Affine Modulation) should be defined with explicit equations showing how VFM features modulate CNN activations at each layer.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in the presentation of quantitative evidence. We agree that the current manuscript description lacks sufficient numerical results, ablations, and statistical support to fully substantiate the claims. In the revised version, we will add the requested tables, metrics with standard deviations, ablation studies (including VFM replacement and SCAM removal), and significance tests while preserving the core bilevel formulation and SCAM design.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent improvements in detection accuracy and training stability' across backbones is stated without any numerical metrics, baseline comparisons, standard deviations, or ablation tables. This absence prevents assessment of effect size and robustness, which is load-bearing for the central claim of stabilization via VFM priors.
Authors: We acknowledge the abstract's lack of specific numbers. In revision we will expand the abstract to report key quantitative results (e.g., mAP gains of X% on average across backbones, stability measured by variance reduction with standard deviations over 5 runs) and reference the new ablation tables that will appear in the experiments section. revision: yes
-
Referee: [Method] Method (SCAM and bilevel sections): the assertion that a frozen general-purpose VFM reliably supplies semantic priors transferable to IR small targets via SCAM modulation lacks supporting evidence that VFM embeddings are not largely irrelevant or noisy in the thermal regime. Without an ablation replacing the VFM with a random or domain-adapted encoder (or showing performance collapse when SCAM is removed), it remains possible that the bilevel reweighting alone drives the gains, rendering the VFM component non-load-bearing.
Authors: We agree an explicit ablation is required. We will add experiments that (1) replace the frozen VFM with a randomly initialized encoder of identical architecture and (2) disable SCAM while keeping the bilevel reweighting intact. Results will show clear performance drops, confirming that the semantic priors transferred via SCAM are load-bearing rather than incidental to the reweighting strategy. revision: yes
-
Referee: [Experiments] Experiments: the manuscript asserts gains 'across multiple ISTD backbones' and 'diverse challenging cases' but supplies no quantitative tables, no error bars, and no statistical significance tests. This omission directly undermines the reproducibility and generality claims that are central to the contribution.
Authors: We will insert comprehensive result tables reporting mAP, F1, and stability metrics for each backbone (with mean ± std over multiple random seeds), plus error bars on all plots. We will also include paired t-test p-values comparing our method against baselines on each dataset to establish statistical significance of the reported gains. revision: yes
Circularity Check
No significant circularity; framework uses external frozen VFM
full rationale
The paper formulates point-supervised ISTD as bilevel optimization with an inner loop adapting a VFM-embedded teacher on reweighted samples and an outer loop for student distillation, plus SCAM modulation to inject semantics from a frozen external Vision Foundation Model. No equations, self-definitions, or fitted parameters are presented as predictions by construction. The central claims depend on an independent pre-trained VFM and public code rather than reducing to the method's own inputs or self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen general-purpose Vision Foundation Models supply transferable semantic priors for infrared small target scenes
invented entities (1)
-
Semantic-Conditioned Affine Modulation (SCAM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[Bai and Zhou, 2010] Xiangzhi Bai and Fugen Zhou. Anal- ysis of new top-hat transformation and the application for infrared dim small target detection.Pattern Recognition, 43(6):2145–2156,
work page 2010
-
[2]
[Chenet al., 2014 ] CL Philip Chen, Hong Li, Yantao Wei, Tian Xia, and Yuan Yan Tang. A local contrast method for small infrared target detection.IEEE Transactions on Geoscience and Remote Sensing, 52(1):574–581,
work page 2014
-
[3]
Asymmetric contextual modulation for infrared small target detection
[Daiet al., 2021 ] Yimian Dai, Yiquan Wu, Fei Zhou, and Kobus Barnard. Asymmetric contextual modulation for infrared small target detection. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, pages 950–959,
work page 2021
-
[4]
[Kirillovet al., 2023 ] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment Anything. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026,
work page 2023
-
[5]
[Liet al., 2023 ] Boyang Li, Chao Xiao, Longguang Wang, Yingqian Wang, Zaiping Lin, Miao Li, Wei An, and Yulan Guo. Dense nested attention network for infrared small target detection.IEEE Transactions on Image Processing, 32:1745–1758,
work page 2023
-
[6]
[Liuet al., 2023a ] Zhu Liu, Zihang Chen, Jinyuan Liu, Long Ma, Xin Fan, and Risheng Liu. Enhancing infrared small target detection robustness with bi-level adversarial frame- work.arXiv preprint arXiv:2309.01099,
-
[7]
DEAL: Data-efficient adversarial learning for high-quality infrared imaging
[Liuet al., 2025 ] Zhu Liu, Zijun Wang, Jinyuan Liu, Fanqi Meng, Long Ma, and Risheng Liu. DEAL: Data-efficient adversarial learning for high-quality infrared imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28198–28207,
work page 2025
-
[8]
[Liuet al., 2026 ] Risheng Liu, Zhu Liu, Weihao Mao, Wei Yao, and Jin Zhang. Bilevel optimization for adversar- ial learning problems: Sharpness, generation, and be- yond.Advances in Neural Information Processing Sys- tems, 38:29102–29130,
work page 2026
-
[9]
DINOv2: Learning Robust Visual Features without Supervision
[Oquabet al., 2023 ] Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning ro- bust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Learning transferable visual models from nat- ural language supervision
[Radfordet al., 2021 ] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InInternational Conference on Machine Learning, pages 8748–8763. PMLR,
work page 2021
-
[11]
[Raoet al., 2021 ] Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. DynamicViT: Efficient vision transformers with dynamic token sparsifi- cation.Advances in Neural Information Processing Sys- tems, 34:13937–13949,
work page 2021
-
[12]
[Sim´eoniet al., 2025 ] Oriane Sim ´eoni, Huy V V o, Maxim- ilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa, et al. DINOv3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
[Wanget al., 2023 ] Weimin Wang, Ting Yang, Yu Du, and Yu Liu. Snow removal for LiDAR point clouds with spatio-temporal conditional random fields.IEEE Robotics and Automation Letters, 8(10):6739–6746,
work page 2023
-
[14]
MergeNet: Explicit mesh reconstruc- tion from sparse point clouds via edge prediction
[Wanget al., 2024 ] Weimin Wang, Yingxu Deng, Zezeng Li, Yu Liu, and Na Lei. MergeNet: Explicit mesh reconstruc- tion from sparse point clouds via edge prediction. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE,
work page 2024
-
[15]
[Wanget al., 2025 ] Weimin Wang, Xin Tan, Liang Li, Yu Liu, and Qiong Chang. 3D-NLM: V oxel-based non- local means for 3D point cloud noise detection and smoothing.Computers & Graphics, page 104348,
work page 2025
-
[16]
[Wanget al., 2026 ] Weimin Wang, Ruifeng Nie, Yingchi Liu, Long Ma, Chengpei Xu, Qi Jia, Yu Liu, and Na Lei. SWG-Fusion: Soft weather-guided multimodal fusion with VLM-assistance for BEV object detection under harsh weather.Pattern Recognition, page 113398,
work page 2026
-
[17]
[Yinget al., 2023 ] Xinyi Ying, Li Liu, Yingqian Wang, Ruo- jing Li, Nuo Chen, Zaiping Lin, Weidong Sheng, and Shilin Zhou. Mapping degeneration meets label evolu- tion: Learning infrared small target detection with sin- gle point supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15528–15538,
work page 2023
-
[18]
[Yuet al., 2025 ] Chuang Yu, Jinmiao Zhao, Yunpeng Liu, Sicheng Zhao, Yimian Dai, and Xiangyu Yue. From easy to hard: Progressive active learning framework for infrared small target detection with single point supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2588–2598,
work page 2025
-
[19]
[Yuanet al., 2024 ] Shuai Yuan, Hanlin Qin, Xiang Yan, Naveed Akhtar, and Ajmal Mian. SCTransNet: Spatial- channel cross transformer network for infrared small target detection.IEEE Transactions on Geoscience and Remote Sensing, 62:1–15,
work page 2024
-
[20]
ISNet: Shape matters for infrared small target detection
[Zhanget al., 2022 ] Mingjin Zhang, Rui Zhang, Yuxiang Yang, Haichen Bai, Jing Zhang, and Jie Guo. ISNet: Shape matters for infrared small target detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 877–886,
work page 2022
-
[21]
IRSAM: Ad- vancing Segment Anything Model for infrared small target detection
[Zhanget al., 2024 ] Mingjin Zhang, Yuchun Wang, Jie Guo, Yunsong Li, Xinbo Gao, and Jing Zhang. IRSAM: Ad- vancing Segment Anything Model for infrared small target detection. InProceedings of the European Conference on Computer Vision, pages 233–249. Springer,
work page 2024
-
[22]
SAIST: Seg- ment any infrared small target model guided by con- trastive language-image pretraining
[Zhanget al., 2025 ] Mingjin Zhang, Xiaolong Li, Fei Gao, Jie Guo, Xinbo Gao, and Jing Zhang. SAIST: Seg- ment any infrared small target model guided by con- trastive language-image pretraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9549–9558,
work page 2025
-
[23]
[Zhaoet al., 2023 ] Jinmiao Zhao, Chuang Yu, Zelin Shi, Yunpeng Liu, and Yingdi Zhang. Gradient-guided learn- ing network for infrared small target detection.IEEE Geo- science and Remote Sensing Letters, 20:1–5,
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.