Recognition: 2 theorem links
· Lean TheoremIdeology Prediction of German Political Texts
Pith reviewed 2026-05-15 02:45 UTC · model grok-4.3
The pith
Transformer models map German political texts to a continuous left-to-right ideology score with poll-level accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Transformer models can recognize political framing in German news at the level of public opinion polls by projecting texts onto a continuous left-to-right spectrum represented by a normalized scalar d between -1 and 1.
What carries the argument
Transformer encoders fine-tuned as regressors on political orientation labels drawn from German parliamentary speeches, Wahl-O-Mat statements, newspaper articles, and member tweets.
If this is right
- Analysts can examine specific ideological segments such as conservatives while excluding other groups without needing multiclass labels for every segment.
- Both model architecture and the presence of domain-specific training data affect performance at least as much as raw model size.
- Models trained on parliamentary and decision-tool data generalize to newspaper articles and social-media posts from the same parliament.
- Continuous scores enable finer measurement of political bias than discrete left-center-right categories.
Where Pith is reading between the lines
- The scalar output could be applied to track gradual changes in rhetorical tone across successive election cycles.
- Similar regression setups might transfer to other languages once comparable source-labeled corpora become available.
- Automated continuous scoring opens the possibility of real-time monitoring of framing shifts in large social-media streams.
Load-bearing premise
Labels based on newspaper identities and politician affiliations accurately reflect the ideology expressed inside each individual text.
What would settle it
A new set of German political texts individually rated by human annotators on the same left-to-right scale where the model's predicted scalars show large systematic deviation from the human ratings.
Figures





read the original abstract
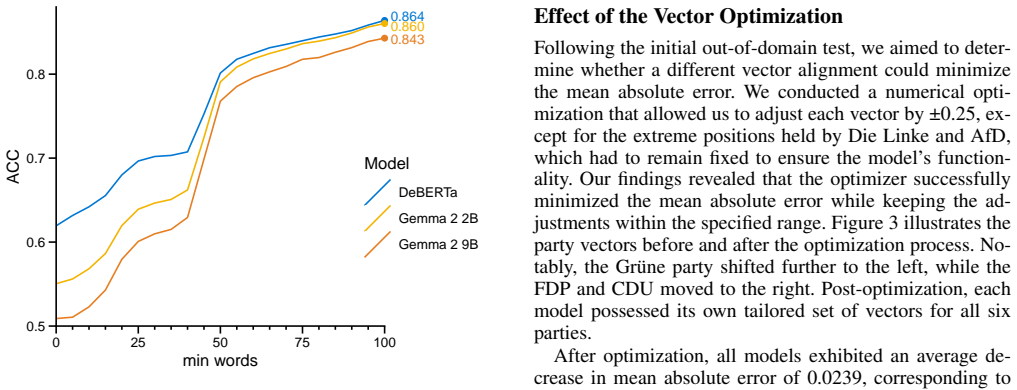
Elections represent a crucial milestone in a nation's ongoing development. To better understand the political rhetoric from various movements, ranging from left to right, we propose a transformer-based model capable of projecting the political orientation of a text on a continuous left-to-right spectrum, represented by a normalized scalar d between -1 and 1. This approach enables analysts to focus on specific segments of the political landscape, such as conservatives, while excluding liberal and far-right movements. Such a task can only be achieved with multiclass classifiers, provided that the desired orientation is incorporated within one of their predefined classes. To determine the most suitable foundation model among 13 candidate transformers for this task, we constructed four distinct corpora. One corpus comprised annotated plenary notes from the German Bundestag, while another was based on an official online decision-making tool, Wahl-O-Mat. The third corpus consisted of articles from 33 newspapers, each identified by its political orientation, and the fourth included 535,200 tweets from 597 members of the 20th and 21st German Bundestag. To mitigate overfitting, we used two distinct corpora for training and two for testing, respectively. For in-domain performance, DeBERTa-large achieved the highest F1 score F1=0.844 as well as for the X (Twitter) out-of-domain test ACC=0.864. Regarding the newspaper out-of-domain test, Gemma2-2B excelled (MAE = 0.172). This study demonstrates that transformer models can recognize political framing in German news at the level of public opinion polls. Our findings suggest that both the model architecture and the availability of domain-specific training data can be as influential as model size for estimating political bias. We discuss methodological limitations and outline directions for improving the robustness of bias measurement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains and evaluates transformer models (including DeBERTa-large and Gemma2-2B) to regress German political texts onto a continuous left-right ideology scalar in [-1,1]. Training corpora are Bundestag plenary notes and Wahl-O-Mat responses; test corpora are 33 newspapers labeled by orientation and 535k tweets from Bundestag members. Cross-corpus splits yield in-domain F1=0.844, out-of-domain tweet accuracy 0.864, and newspaper MAE=0.172. The central claim is that such models detect political framing at the accuracy level of public-opinion polls.
Significance. If the newspaper and tweet labels are reliable proxies for underlying ideology, the work supplies a reproducible, cross-domain benchmark showing that moderate-sized transformers can recover framing signals in German political language at a level useful for media monitoring. The explicit cross-corpus protocol and comparison across 13 architectures are methodological strengths that reduce overfitting risk and allow architecture-size trade-offs to be assessed.
major comments (3)
- [Abstract, §3] Abstract and §3 (data construction): the 33 newspaper orientations and 597 politician tweet labels are used as ground truth for both training and out-of-domain evaluation, yet no source, inter-annotator agreement, or external validation (e.g., Chapel Hill Expert Survey, media-bias databases) is provided. Without this, the reported MAE=0.172 and ACC=0.864 cannot be interpreted as evidence of framing detection rather than label memorization.
- [Abstract] Abstract: the assertion that performance reaches 'the level of public opinion polls' is not supported by any quantitative comparison (poll margin of error, expert annotation variance, or prior media-bias studies). The MAE=0.172 figure is presented without such a benchmark, leaving the central claim ungrounded.
- [§4] §4 (evaluation protocol): while cross-corpus splits are used, the paper does not report label noise estimates or sensitivity analyses (e.g., performance after random label flips or after restricting to high-confidence politicians). This is load-bearing because the out-of-domain results rest entirely on the assumption that the held-out labels are unbiased.
minor comments (2)
- [Table 1, §3.2] Table 1 and §3.2: the exact mapping from newspaper names to scalar values in [-1,1] is not tabulated; readers cannot reproduce the target variable without this information.
- [§5.3] §5.3: the discussion of 'domain-specific training data' versus model size would benefit from an explicit ablation that isolates the contribution of each factor rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major point below and commit to revisions that strengthen the grounding of our claims and evaluation protocol.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (data construction): the 33 newspaper orientations and 597 politician tweet labels are used as ground truth for both training and out-of-domain evaluation, yet no source, inter-annotator agreement, or external validation (e.g., Chapel Hill Expert Survey, media-bias databases) is provided. Without this, the reported MAE=0.172 and ACC=0.864 cannot be interpreted as evidence of framing detection rather than label memorization.
Authors: The newspaper orientations derive from established public media-bias classifications (e.g., reports by the Institut für Medien- und Kommunikationspolitik and comparable German media-monitoring projects). Politician tweet labels are assigned strictly according to official Bundestag party membership records, which constitute verifiable public data rather than subjective annotations; inter-annotator agreement therefore does not apply. We agree that explicit sourcing and external validation references are required to support the ground-truth assumption. We will revise §3 to include a dedicated subsection on label provenance with citations to media-bias databases and the Chapel Hill Expert Survey for party-position anchoring. The cross-corpus protocol is intended to demonstrate generalization across independently sourced domains rather than within-corpus memorization; this distinction will be clarified in the revised text. revision: yes
-
Referee: [Abstract] Abstract: the assertion that performance reaches 'the level of public opinion polls' is not supported by any quantitative comparison (poll margin of error, expert annotation variance, or prior media-bias studies). The MAE=0.172 figure is presented without such a benchmark, leaving the central claim ungrounded.
Authors: We accept that the abstract phrasing lacks a direct quantitative benchmark. The reported MAE of 0.172 on the normalized [-1,1] scale is intended to be interpreted against typical ideological scaling errors in survey research, yet no explicit comparison was supplied. In the revision we will either qualify or remove the statement and insert supporting references to studies on poll margin-of-error and media-bias annotation reliability, thereby grounding the claim in the literature. revision: yes
-
Referee: [§4] §4 (evaluation protocol): while cross-corpus splits are used, the paper does not report label noise estimates or sensitivity analyses (e.g., performance after random label flips or after restricting to high-confidence politicians). This is load-bearing because the out-of-domain results rest entirely on the assumption that the held-out labels are unbiased.
Authors: We agree that explicit robustness checks would reinforce the evaluation. Although the cross-corpus splits were chosen to limit overfitting, the manuscript does not include label-noise sensitivity analyses. We will add these experiments to the revised §4, reporting performance under simulated random label flips at multiple noise rates and on high-confidence politician subsets where party signals are unambiguous. These additions will directly address the concern about label bias. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper trains transformer models on labeled corpora (newspapers identified by political orientation, tweets from Bundestag members) and evaluates performance on separate held-out test sets using standard metrics (F1, accuracy, MAE). No equation or claim reduces by construction to a fitted parameter, self-citation chain, or renamed input; the central result is an empirical benchmark on provided labels rather than a derivation that is definitionally equivalent to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- scalar normalization bounds
axioms (1)
- domain assumption Newspaper and tweet labels accurately reflect text ideology
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The output of a trained multilabel classifier... is then multiplied by the corresponding vectors... the angle of the newly formed vector represents the classification result.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we trained and tested 13 transformer classifiers... DeBERTa-large achieved the highest F1 score F1=0.844
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Baly, R.; Karadzhov, G.; Saleh, A.; Glass, J.; and Nakov, P
Online: Association for Computational Linguistics. Baly, R.; Karadzhov, G.; Saleh, A.; Glass, J.; and Nakov, P
-
[2]
Multi-Task Ordinal Regression for Jointly Predict- ing the Trustworthiness and the Leading Political Ideology of News Media. In Burstein, J.; Doran, C.; and Solorio, T., eds.,Proceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Linguis- tics: Human Language Technologies, volume 1, 2109–2116. Minneapolis, ...
-
[3]
Clark, K.; Luong, M.-T.; Le, Q
Barcelona, Spain: International Committee on Com- putational Linguistics. Clark, K.; Luong, M.-T.; Le, Q. V .; and Manning, C. D
-
[4]
ELECTRA: Pre-training Text Encoders as Discrim- inators Rather Than Generators. arXiv:2003.10555. Cohen, R.; and Ruths, D. 2013. Classifying Political Ori- entation on Twitter: It’s Not Easy! InProceedings of the International AAAI Conference on Weblogs and Social Me- dia (ICWSM), volume 7, 91–99. Cambridge, Mass. Conneau, A.; Khandelwal, K.; Goyal, N.; C...
-
[5]
Gemma 2: Improving Open Language Models at a Practical Size
Beyond Binary Labels: Political Ideology Prediction of Twitter Users. In Barzilay, R.; and Kan, M.-Y ., eds.,Pro- ceedings of the 55th Annual Meeting of the Association for Computational Linguistics, volume 1, 729–740. Vancouver, Canada: Association for Computational Linguistics. Proudhon, P.-J. 1840.Qu’est-ce que la propri ´et´e?, ou, Recherches sur le p...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. arXiv:2506.05176. Zhuang, L.; Wayne, L.; Ya, S.; and Jun, Z. 2021. A Ro- bustly Optimized BERT Pre-training Approach with Post- training. In Li, S.; Sun, M.; Liu, Y .; Wu, H.; Liu, K.; Che, W.; He, S.; and Rao, G., eds.,Proceedings of the 20th Chinese National Conference on...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Huhhot, China: Chinese Information Processing Soci- ety of China. Paper Checklist
-
[8]
For most authors... (a) Would answering this research question advance sci- ence without violating social contracts, such as violat- ing privacy norms, perpetuating unfair profiling, exac- erbating the socio-economic divide, or implying dis- respect to societies or cultures? Yes, see the Ethical Statement (b) Do your main claims in the abstract and introd...
-
[9]
Additionally, if your study involves hypotheses testing... (a) Did you clearly state the assumptions underlying all theoretical results? NA (b) Have you provided justifications for all theoretical re- sults? NA (c) Did you discuss competing hypotheses or theories that might challenge or complement your theoretical re- sults? NA (d) Have you considered alt...
-
[10]
Additionally, if you are including theoretical proofs... (a) Did you state the full set of assumptions of all theoret- ical results? NA (b) Did you include complete proofs of all theoretical re- sults? NA
-
[11]
Additionally, if you ran machine learning experiments... (a) Did you include the code, data, and instructions needed to reproduce the main experimental results (ei- ther in the supplemental material or as a URL)? Yes (b) Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? Yes, see the linked GitHub reposito...
-
[12]
Additionally, if you are using existing assets (e.g., code, data, models) or curating/releasing new assets,without compromising anonymity... (a) If your work uses existing assets, did you cite the cre- ators? Yes, see the References and the Methods, Sub- sectionDataset (b) Did you mention the license of the assets? Yes (c) Did you include any new assets i...
work page 2020
-
[13]
Additionally, if you used crowdsourcing or conducted research with human subjects,without compromising anonymity... (a) Did you include the full text of instructions given to participants and screenshots? NA (b) Did you describe any potential participant risks, with mentions of Institutional Review Board (IRB) ap- provals? NA (c) Did you include the estim...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.