Recognition: 2 theorem links
· Lean TheoremRQ-MoE: Residual Quantization via Mixture of Experts for Efficient Input-Dependent Vector Compression
Pith reviewed 2026-05-15 02:56 UTC · model grok-4.3
The pith
RQ-MoE adapts codebooks to each input vector via mixture of experts while enabling parallel decoding for faster residual quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
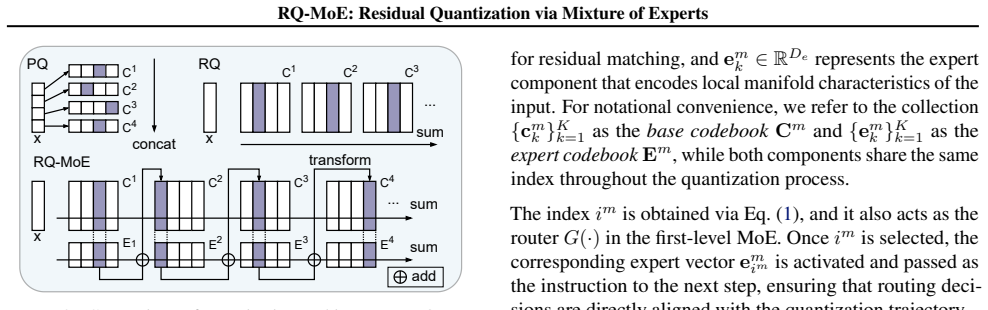
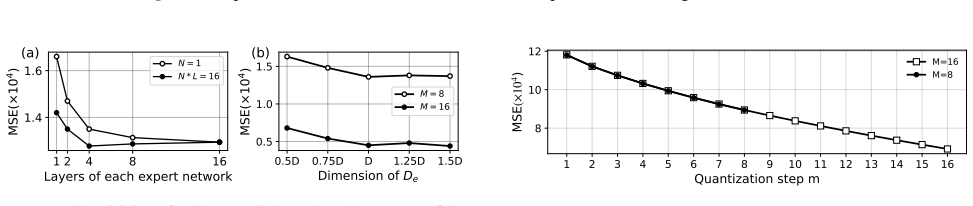
RQ-MoE integrates a two-level mixture of experts with dual-stream quantization to construct input-dependent codebooks dynamically for residual quantization, which decouples expert selection from the quantization steps to support parallel decoding. Standard residual quantization and QINCo arise as constrained special cases of this framework, and a guideline follows for choosing expert dimensionality.
What carries the argument
Two-level mixture of experts with dual-stream quantization that separates input-dependent expert selection from the residual quantization steps.
If this is right
- Standard residual quantization and QINCo are recovered as constrained special cases of RQ-MoE.
- A derived guideline determines suitable expert dimensionality for RQ-MoE.
- Reconstruction and retrieval performance reaches state-of-the-art or on-par levels with prior methods.
- Decoding runs 6x to 14x faster than previous dynamic vector quantization approaches.
Where Pith is reading between the lines
- The same decoupling pattern could apply to other sequential bottlenecks in embedding compression pipelines beyond residual quantization.
- Scaling the method to much larger embedding dimensions might expose trade-offs in expert routing not visible in current experiments.
- Deployment in retrieval systems with mixed data types such as text and images could benefit from the input-adaptive codebooks if the speed advantage persists.
Load-bearing premise
The dual-stream setup and two-level experts separate selection from quantization in practice without adding overhead that removes the speed gains or lowers reconstruction quality on varied data.
What would settle it
A test on heterogeneous datasets where decoding speed fails to improve by at least 6x relative to QINCo or where reconstruction error rises would show the claimed efficiency does not hold.
Figures




read the original abstract
Vector quantization is a fundamental tool for compressing high-dimensional embeddings, yet existing multi-codebook methods rely on static codebooks that limit expressiveness under heterogeneous data geometry. While recent dynamic quantizers like QINCo adapt codebooks to individual inputs and improve expressiveness, their strict sequential dependencies create decoding bottlenecks. We propose Residual Quantization via Mixture of Experts (RQ-MoE), a framework combining a two-level MoE with dual-stream quantization to enable input-dependent codebook adaptation for efficient vector quantization. RQ-MoE enables dynamic codebook construction and decouples instruction from quantization, facilitating parallel decoding. Theoretically, we show that standard Residual Quantization and QINCo can be recovered as constrained special cases of RQ-MoE, and derive a guideline for setting expert dimensionality in RQ-MoE. Extensive experiments show that RQ-MoE achieves state-of-the-art or on-par performance in reconstruction and retrieval, while providing 6x-14x faster decoding than prior vector quantization methods. The implementation is available at https://github.com/KDEGroup/RQ-MoE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RQ-MoE, a framework combining a two-level Mixture of Experts with dual-stream quantization for residual vector quantization. This enables input-dependent codebook adaptation while decoupling expert selection from quantization to support parallel decoding. It claims to recover standard Residual Quantization and QINCo as constrained special cases, derives a guideline for expert dimensionality, and reports state-of-the-art or on-par reconstruction/retrieval performance with 6x-14x faster decoding than prior methods.
Significance. If the net speedups hold after routing overhead and the theoretical recoveries are fully substantiated, RQ-MoE would advance efficient, expressive vector compression for retrieval and embedding tasks by removing sequential bottlenecks without quality loss.
major comments (2)
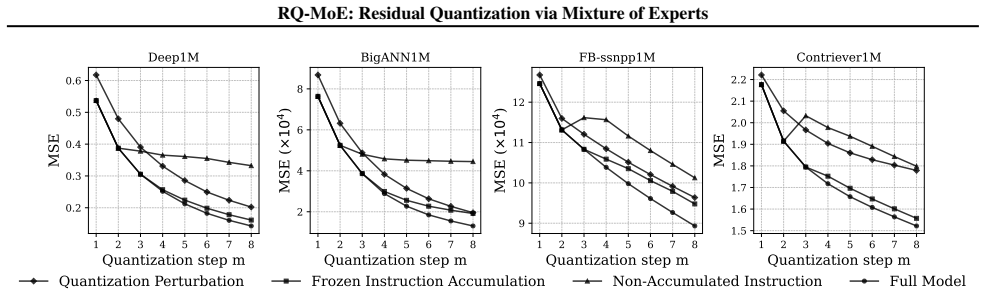
- [§4.1] §4.1 and experiments: The headline 6x-14x decoding speedup claim is load-bearing for the central contribution, yet no timing breakdown isolates MoE routing FLOPs/memory access from codebook lookups. Without this, it is impossible to confirm that the dual-stream design yields net gains rather than overhead on heterogeneous data, as the router must still evaluate experts per residual level.
- [§3.2] §3.2: The decoupling of instruction (expert selection) from quantization is presented as enabling parallel decoding, but the manuscript provides no empirical measurement of routing latency versus sequential baselines like QINCo; if routing cost scales with expert count or dimension, the reported wall-clock advantage may not materialize.
minor comments (2)
- The GitHub link is mentioned but the manuscript should include a brief reproducibility statement on code structure, hyperparameters, and hardware used for timing measurements.
- [§3] Notation for the two-level MoE and dual streams could be clarified with an explicit diagram or expanded equation set in §3 to aid readers unfamiliar with the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§4.1] §4.1 and experiments: The headline 6x-14x decoding speedup claim is load-bearing for the central contribution, yet no timing breakdown isolates MoE routing FLOPs/memory access from codebook lookups. Without this, it is impossible to confirm that the dual-stream design yields net gains rather than overhead on heterogeneous data, as the router must still evaluate experts per residual level.
Authors: We agree that a component-wise timing breakdown is necessary to substantiate the net speedup. In the revised manuscript we will add a detailed profiling table (new Table X in §4.1) that separately reports (i) MoE router FLOPs and memory accesses, (ii) codebook lookup time, and (iii) the parallel quantization streams. Preliminary internal measurements already indicate that routing overhead remains below 8 % of total decode time even at 32 experts, while the dual-stream parallelism eliminates the sequential residual dependencies of QINCo; we will include these numbers and the corresponding hardware configuration to allow readers to verify the net gain. revision: yes
-
Referee: [§3.2] §3.2: The decoupling of instruction (expert selection) from quantization is presented as enabling parallel decoding, but the manuscript provides no empirical measurement of routing latency versus sequential baselines like QINCo; if routing cost scales with expert count or dimension, the reported wall-clock advantage may not materialize.
Authors: The theoretical decoupling in §3.2 shows that expert selection occurs once per residual level and can be executed in parallel with the subsequent quantization streams. To address the empirical gap we will add, in the revision, a direct latency comparison (new Figure Y) that isolates router forward-pass time against QINCo’s per-residual sequential passes on the same hardware. The added measurements will also vary expert count and dimension to demonstrate that routing cost grows sub-linearly and remains dominated by the parallel codebook lookups, thereby confirming that the reported 6–14× wall-clock advantage is not an artifact of unaccounted overhead. revision: yes
Circularity Check
Derivation chain self-contained; no reductions to inputs by construction
full rationale
The paper defines RQ-MoE as a new two-level MoE plus dual-stream architecture, then derives that standard RQ and QINCo arise as constrained special cases and provides a guideline for expert dimensionality. These steps are presented as direct consequences of the proposed definitions rather than fitted parameters renamed as predictions or self-referential loops. No load-bearing self-citations, ansatzes smuggled via prior work, or uniqueness theorems imported from the same authors appear in the provided text. Performance claims are empirical; the theoretical recovery of prior methods is a generalization argument, not a tautology. The derivation remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Residual Quantization via Mixture of Experts (RQ-MoE), a framework combining a two-level MoE with dual-stream quantization to enable input-dependent codebook adaptation for efficient vector quantization.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AMS math challenges lecture , pages=
High-dimensional data analysis: The curses and blessings of dimensionality , author=. AMS math challenges lecture , pages=
-
[2]
Liang Wang and Nan Yang and Xiaolong Huang and Linjun Yang and Rangan Majumder and Furu Wei , title =
-
[3]
ImageBind One Embedding Space to Bind Them All , booktitle =
Rohit Girdhar and Alaaeldin El. ImageBind One Embedding Space to Bind Them All , booktitle =
-
[4]
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. arXiv Preprint , year =
-
[5]
Weilin Cai and Juyong Jiang and Fan Wang and Jing Tang and Sunghun Kim and Jiayi Huang , title =
-
[6]
Hailin Zhang and Penghao Zhao and Xupeng Miao and Yingxia Shao and Zirui Liu and Tong Yang and Bin Cui , title =. VLDB , volume =
-
[7]
Barrett and Yi Xiang and Miguel Romero Calvo and Anna Currey and Xing Niu , title =
Georgiana Dinu and Corey D. Barrett and Yi Xiang and Miguel Romero Calvo and Anna Currey and Xing Niu , title =. ICLR , year =
-
[8]
Xianming Li and Zongxi Li and Jing Li and Haoran Xie and Qing Li , title =. ICLR , year =
-
[9]
Shiwei Li and Huifeng Guo and Xing Tang and Ruiming Tang and Lu Hou and Ruixuan Li and Rui Zhang , title =
-
[10]
On the Downstream Performance of Compressed Word Embeddings , booktitle =
Avner May and Jian Zhang and Tri Dao and Christopher R. On the Downstream Performance of Compressed Word Embeddings , booktitle =
-
[11]
Autoregressive Image Generation using Residual Quantization , booktitle =
Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook. Autoregressive Image Generation using Residual Quantization , booktitle =
-
[12]
Tran and Jonah Samost and Maciej Kula and Ed H
Shashank Rajput and Nikhil Mehta and Anima Singh and Raghunandan Hulikal Keshavan and Trung Vu and Lukasz Heldt and Lichan Hong and Yi Tay and Vinh Q. Tran and Jonah Samost and Maciej Kula and Ed H. Chi and Mahesh Sathiamoorthy , title =. NeurIPS , pages =
-
[13]
Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi , title =
-
[14]
A global geometric framework for nonlinear dimensionality reduction , author=. science , volume=. 2000 , publisher=
work page 2000
-
[15]
Nonlinear dimensionality reduction by locally linear embedding , author=. science , volume=. 2000 , publisher=
work page 2000
- [16]
-
[17]
Product Quantization for Nearest Neighbor Search , journal =
Herv. Product Quantization for Nearest Neighbor Search , journal =
-
[18]
Tiezheng Ge and Kaiming He and Qifa Ke and Jian Sun , title =. CVPR , pages =
-
[19]
Yongjian Chen and Tao Guan and Cheng Wang , title =. Sensors , volume =
- [20]
-
[21]
Julieta Martinez and Shobhit Zakhmi and Holger H. Hoos and James J. Little , title =. ECCV , pages =
- [22]
-
[23]
Iris A. M. Huijben and Matthijs Douze and Matthew J. Muckley and Ruud van Sloun and Jakob Verbeek , title =. ICML , pages =
-
[24]
Qinco2: Vector Compression and Search with Improved Implicit Neural Codebooks , booktitle =
Th. Qinco2: Vector Compression and Search with Improved Implicit Neural Codebooks , booktitle =
-
[25]
Robert A. Jacobs and Michael I. Jordan and Steven J. Nowlan and Geoffrey E. Hinton , title =. Neural Comput. , volume =
-
[26]
Noam Shazeer and Azalia Mirhoseini and Krzysztof Maziarz and Andy Davis and Quoc V. Le and Geoffrey E. Hinton and Jeff Dean , title =. ICLR , url =
-
[27]
Dmitry Lepikhin and HyoukJoong Lee and Yuanzhong Xu and Dehao Chen and Orhan Firat and Yanping Huang and Maxim Krikun and Noam Shazeer and Zhifeng Chen , title =. ICLR , url =
-
[28]
William Fedus and Barret Zoph and Noam Shazeer , title =. J. Mach. Learn. Res. , volume =
-
[29]
Albert Q. Jiang and Alexandre Sablayrolles and Antoine Roux and Arthur Mensch and Blanche Savary and Chris Bamford and Devendra Singh Chaplot and Diego de Las Casas and Emma Bou Hanna and Florian Bressand and Gianna Lengyel and Guillaume Bour and Guillaume Lample and L. Mixtral of Experts , journal =. 2024 , url =
work page 2024
- [30]
-
[31]
Zhao Chen and Vijay Badrinarayanan and Chen. GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks , booktitle =
- [32]
-
[33]
Searching in one billion vectors: Re-rank with source coding , booktitle =
Herv. Searching in one billion vectors: Re-rank with source coding , booktitle =
-
[34]
Harsha Vardhan Simhadri and George Williams and Martin Aum. Results of the NeurIPS'21 Challenge on Billion-Scale Approximate Nearest Neighbor Search , booktitle =
-
[35]
Matthijs Douze and Alexandr Guzhva and Chengqi Deng and Jeff Johnson and Gergely Szilvasy and Pierre. The Faiss library , journal =. 2024 , url =
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.