Recognition: 2 theorem links
· Lean TheoremLoMETab: Beyond Rank-1 Ensembles for Tabular Deep Learning
Pith reviewed 2026-05-15 02:49 UTC · model grok-4.3
The pith
LoMETab generalizes rank-1 multiplicative ensembles to rank-r adapters for tabular models, strictly enlarging the hypothesis class and exposing tunable diversity controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoMETab defines member weights as W_k = W ⊙ (1 + A_k B_k^T) with low-rank factors of rank r, lifting the rank-1 case to a family that strictly enlarges the hypothesis class for r >= 2 and lets (r, sigma_init) tune pairwise KL divergence over orders of magnitude.
What carries the argument
The rank-r identity-residual Hadamard family, in which each member weight is the shared base matrix multiplied elementwise by (1 plus a low-rank outer-product update).
Load-bearing premise
The added representational capacity and induced diversity will translate into practically useful predictive behavior rather than merely dataset-dependent variation.
What would settle it
A mathematical counter-example proving that the hypothesis class for r >= 2 is no larger than the rank-1 case, or an experiment in which sweeping r and sigma_init produces no measurable change in pairwise KL or member-level disagreement.
Figures



read the original abstract
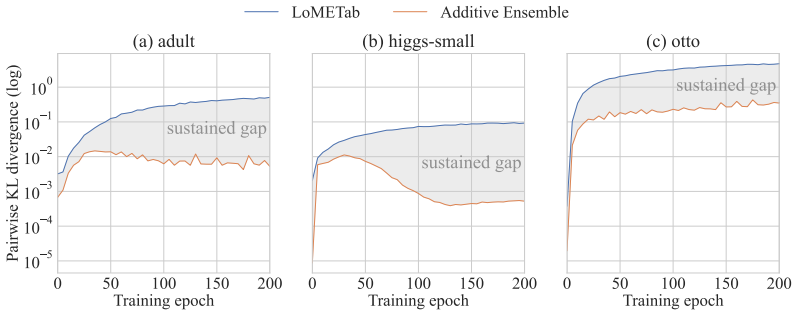
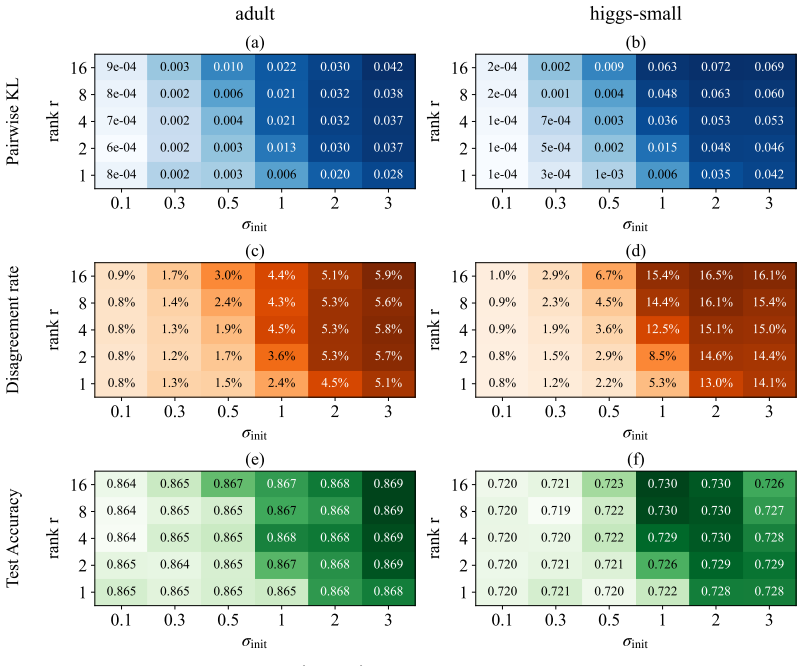
Recent tabular learning benchmarks increasingly show a tight performance cluster rather than a clear hierarchy among leading methods, spanning gradient boosted decision trees, attention-based architectures, and implicit ensembles such as TabM. As benchmark gains plateau, a complementary goal is to understand and control the mechanisms that make simple neural tabular models competitive. We propose LoMETab, a rank-$r$ generalization of multiplicative implicit ensembles. LoMETab lifts the rank-1 BatchEnsemble/TabM modulation to a rank-$r$ identity-residual Hadamard family by parameterizing each member weight as $W_k = W \odot (1 + A_kB_k^\top)$, where $W$ is shared and $(A_k, B_k)$ are member-specific low-rank factors. This exposes two practical diversity-control axes: the adapter rank $r$ and the initialization scale $\sigma_{\mathrm{init}}$, and we prove that for $r \ge 2$ this generalization strictly enlarges BatchEnsemble's hypothesis class. Empirically, we show that this added capacity manifests as measurable predictive diversity after training: on representative classification datasets, LoMETab sustains higher pairwise KL than an additive low-rank ablation, and $(r, \sigma_{\mathrm{init}})$ provides broad control over pairwise KL, varying by up to several orders of magnitude across configurations. The induced diversity is reflected in task-appropriate output-level measures: argmax disagreement for classification and ambiguity for regression, indicating that the control extends beyond pairwise KL to decision- and output-level member variation. Finally, experiments sweeping over adapter rank $r$ and initialization scale $\sigma_{\mathrm{init}}$ reveal that predictive performance is dataset-dependent over the $(r, \sigma_{\mathrm{init}})$ grid, supporting LoMETab as a controllable family of implicit ensembles rather than a fixed rank-1 construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoMETab, a rank-r generalization of multiplicative implicit ensembles (BatchEnsemble/TabM) for tabular deep learning. Each ensemble member weight is parameterized as W_k = W ⊙ (1 + A_k B_k^T) with shared W and member-specific low-rank factors of rank r. The central theoretical claim is a proof that for r ≥ 2 this strictly enlarges BatchEnsemble's hypothesis class. Empirically, the work shows that the pair (r, σ_init) controls predictive diversity, yielding higher pairwise KL than an additive low-rank ablation and measurable variation (up to orders of magnitude) in KL, argmax disagreement (classification), and ambiguity (regression); downstream accuracy is reported as dataset-dependent over the (r, σ_init) grid.
Significance. If the claims hold, the work supplies a theoretically grounded mechanism for enlarging and controlling diversity in implicit ensembles for tabular models, where benchmark gains have plateaued. The direct proof of hypothesis-class enlargement and the explicit empirical mapping from (r, σ_init) to diversity metrics constitute a clear advance over fixed rank-1 constructions, offering practitioners tunable axes without explicit ensembling.
minor comments (3)
- [§3] The proof of hypothesis-class enlargement (presumably in §3 or the appendix) would benefit from an explicit side-by-side statement of the function class realized by the rank-1 case versus the rank-r case, including the precise definition of the modulation map, to make the strict inclusion argument fully self-contained.
- [Table 1] Table 1 (or the main results table) reports performance as dataset-dependent but does not include a simple baseline comparison against a standard explicit ensemble of the same size; adding this column would strengthen the claim that the controllable diversity is practically useful.
- [§4.2] The description of the additive low-rank ablation used for the KL comparison is brief; a short paragraph or equation clarifying whether the ablation shares the same total parameter count as LoMETab would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of LoMETab and the recommendation for minor revision. The report does not list any specific major comments, which we take as confirmation that the central claims—the strict hypothesis-class enlargement for r ≥ 2 and the empirical controllability of diversity via (r, σ_init)—are clearly presented and supported.
Circularity Check
No significant circularity
full rationale
The paper's central theoretical step is an explicit set-theoretic comparison showing that the rank-r modulation W_k = W ⊙ (1 + A_k B_k^T) for r ≥ 2 strictly contains the rank-1 BatchEnsemble hypothesis class; this is a direct inclusion argument on function spaces and does not rely on any fitted parameter, self-referential definition, or prior result from the same authors. The empirical sections report measured pairwise KL, argmax disagreement, and ambiguity as functions of the controllable axes (r, σ_init) without claiming that any downstream performance quantity is predicted by construction from the inputs. No self-citation is used to justify uniqueness or to smuggle an ansatz, and the abstract explicitly notes dataset-dependence of accuracy, avoiding over-claim. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- adapter rank r
- initialization scale sigma_init
axioms (1)
- domain assumption The modulation W_k = W ⊙ (1 + A_k B_k^T) with low-rank A_k, B_k defines a valid weight matrix for each ensemble member.
Reference graph
Works this paper leans on
-
[1]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2019
work page 2019
-
[2]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2016
work page 2016
-
[3]
Masksembles for uncertainty estimation
Nikita Durasov, Timur Bagautdinov, Pierre Baque, and Pascal Fua. Masksembles for uncertainty estimation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[4]
On embeddings for numerical features in tabular deep learning
Yury Gorishniy, Ivan Rubachev, and Artem Babenko. On embeddings for numerical features in tabular deep learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[5]
TabR: Tabular deep learning meets nearest neighbors
Yury Gorishniy, Ivan Rubachev, Nikolay Kartashev, Daniil Shlenskii, Akim Kotelnikov, and Artem Babenko. TabR: Tabular deep learning meets nearest neighbors. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[6]
TabM: Advancing tabular deep learning with parameter-efficient ensembling
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. TabM: Advancing tabular deep learning with parameter-efficient ensembling. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://openreview.net/forum?id=Sd4wYYOhmY
work page 2025
-
[7]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2022
work page 2022
-
[8]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InInternational Conference on Machine Learning, pages 1321–1330. PMLR, 2017
work page 2017
-
[9]
Michelle Halbheer, Dominik Jan Mühlematter, Alexander Becker, Dominik Narnhofer, Helge Aasen, Konrad Schindler, and Mehmet Ozgur Turkoglu. LoRA-Ensemble: Efficient uncertainty modelling for self-attention networks.arXiv preprint arXiv:2405.14438, 2024. URL https: //arxiv.org/abs/2405.14438
-
[10]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. InProceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015
work page 2015
-
[11]
Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, Cam- bridge, 2nd edition, 2012
work page 2012
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInterna- tional Conference on Learning Representations (ICLR), 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
work page 2022
-
[13]
HiRA: Parameter-efficient hadamard high-rank adaptation for large language models
Qiushi Huang, Tom Ko, Zhan Zhuang, Lilian Tang, and Yu Zhang. HiRA: Parameter-efficient hadamard high-rank adaptation for large language models. InInternational Conference on Learning Representations (ICLR), 2025. URL https://openreview.net/forum?id= TwJrTz9cRS. Oral presentation. 10
work page 2025
-
[14]
Neural network ensembles, cross validation, and ac- tive learning
Anders Krogh and Jesper Vedelsby. Neural network ensembles, cross validation, and ac- tive learning. InAdvances in Neural Information Processing Systems, volume 7, pages 231–238. MIT Press, 1995. URL https://papers.nips.cc/paper_files/paper/1994/ hash/b8c37e33defde51cf91e1e03e51657da-Abstract.html
work page 1995
-
[15]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[16]
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakr- ishnan, Micah Goldblum, and Colin White. When do neural nets outperform boosted trees on tabular data? InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024
work page 2024
-
[17]
Obtaining well calibrated probabilities using Bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using Bayesian binning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015
work page 2015
-
[18]
Diversity matters when learning from ensembles
Giung Nam, Jongmin Yoon, Yoonho Lee, and Juho Lee. Diversity matters when learning from ensembles. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. URL https://openreview.net/forum?id=f_eOQN87eXc
work page 2021
-
[19]
CatBoost: Unbiased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. CatBoost: Unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[20]
TabReD: Analyzing pitfalls and filling the gaps in tabular deep learning benchmarks
Ivan Rubachev, Nikolay Kartashev, Yury Gorishniy, and Artem Babenko. TabReD: Analyzing pitfalls and filling the gaps in tabular deep learning benchmarks. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[21]
FiLM- Ensemble: Probabilistic deep learning via feature-wise linear modulation
Mehmet Ozgur Turkoglu, Alexander Becker, Hüseyin Anil Gündüz, Mina Rezaei, Bernd Bischl, Rodrigo Caye Daudt, Stefano D’Aronco, Jan Dirk Wegner, and Konrad Schindler. FiLM- Ensemble: Probabilistic deep learning via feature-wise linear modulation. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv.org/abs/ 2206.00050
-
[22]
BatchEnsemble: An alternative approach to efficient ensemble and lifelong learning
Yeming Wen, Dustin Tran, and Jimmy Ba. BatchEnsemble: An alternative approach to efficient ensemble and lifelong learning. InInternational Conference on Learning Representations (ICLR), 2020. URLhttps://openreview.net/forum?id=Sklf1yrYDr
work page 2020
-
[24]
URLhttps://arxiv.org/abs/2601.16936. 11 A Proof of Proposition 1 Notation.We write ⊙ for the Hadamard (element-wise) product, ⊘ for element-wise division, and 1 for the all-ones matrix (dimensions inferred from context). For brevity we write m:=d out and n:=d in. The hypothesis classes are: HBE = n W⊙(s kr⊤ k ) K k=1 :W∈R m×n, r k ∈R n, s k ∈R m o , H(r) ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.