Recognition: no theorem link
Dual-Latent Collaborative Decoding for Fidelity-Perception Balanced Image Compression
Pith reviewed 2026-05-15 01:45 UTC · model grok-4.3
The pith
Mixture of Decoder Experts coordinates scalar-quantized and vector-quantized latents to balance fidelity and perceptual quality across bitrates in learned image compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoDE treats the SQ branch as a fidelity-oriented expert and the VQ branch as a perception-oriented expert, coordinated through Expert-Specific Enhancement to preserve branch-specific references and Cross-Expert Modulation to enable selective complementary transfer during reconstruction, supporting both fidelity-anchored and perception-anchored decoding under a shared dual-stream bitstream.
What carries the argument
Mixture of Decoder Experts (MoDE) framework with Expert-Specific Enhancement (ESE) and Cross-Expert Modulation (CEM) modules that coordinate a scalar-quantized fidelity branch and a vector-quantized perception branch.
If this is right
- Enables a single model to support both fidelity-anchored and perception-anchored decoding paths from the same dual-stream bitstream.
- Maintains rate scalability from the scalar-quantized branch while recovering perceptual details from the vector-quantized branch at low rates.
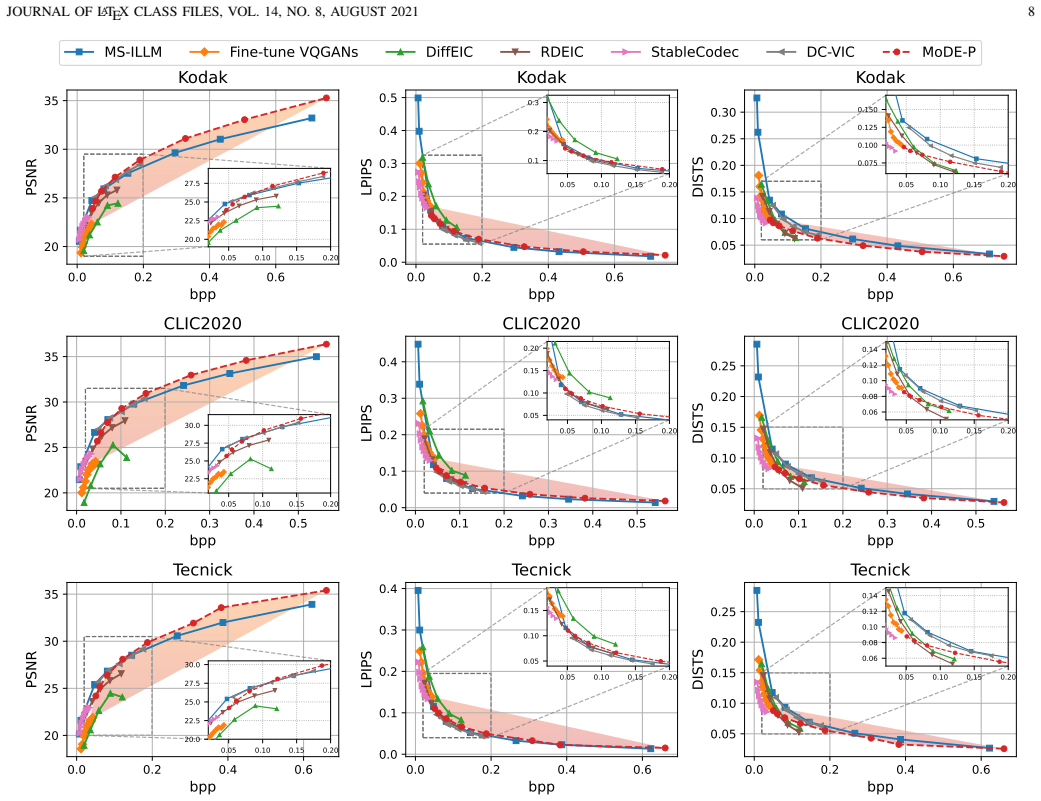
- Outperforms representative distortion-oriented, perception-oriented, generative, and dual-latent baselines across a wide bitrate range.
- Shows that decoder-side expert collaboration is sufficient to resolve latent-role conflicts without redesigning the encoder.
Where Pith is reading between the lines
- The same dual-branch coordination pattern could be tested on video compression where temporal consistency adds another conflicting requirement.
- If the modules generalize, hybrid latent systems might reduce the need for separate generative and distortion-optimized codecs in production pipelines.
- The approach suggests that explicit expert routing at decode time can substitute for more complex latent-space disentanglement techniques.
Load-bearing premise
The Expert-Specific Enhancement and Cross-Expert Modulation modules can coordinate the two branches to deliver consistent gains without introducing new artifacts or requiring per-dataset retuning.
What would settle it
A side-by-side comparison on a held-out test set showing that MoDE reconstructions exhibit new visible artifacts or smaller fidelity-perception gains than the strongest single-latent baseline at multiple low-bitrate operating points.
Figures







read the original abstract
Learned image compression (LIC) increasingly requires reconstructions that balance distortion fidelity and perceptual realism across a wide range of bitrates. However, most existing methods still rely on a single compressed latent representation to simultaneously carry structural details, semantic cues, and perceptual priors, requiring the same latent representation to serve multiple, potentially conflicting roles. This tension becomes evident across different latent paradigms: scalar-quantized (SQ) continuous latents provide rate-scalable fidelity but tend to lose perceptual details at low rates, while vector-quantized (VQ) discrete tokens preserve compact semantic cues but suffer from limited structural fidelity and bitrate scalability. To address this issue, we propose Mixture of Decoder Experts (MoDE), a dual-latent collaborative decoding framework that decomposes reconstruction responsibilities across complementary latent paradigms. Specifically, MoDE treats the SQ branch as a fidelity-oriented expert and the VQ branch as a perception-oriented expert, and coordinates them through two decoder-side modules: Expert-Specific Enhancement (ESE), which preserves branch-specific expert references, and Cross-Expert Modulation (CEM), which enables selective complementary transfer during reconstruction. The resulting framework supports selective cross-latent collaboration under a shared dual-stream bitstream and enables both fidelity-anchored and perception-anchored decoding. Extensive experiments demonstrate that MoDE achieves a more favorable fidelity-perception balance than representative distortion-oriented, perception-oriented, generative, and dual-latent baselines across a wide bitrate range, highlighting decoder-side expert collaboration as an effective design for wide-range fidelity-perception balanced LIC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Mixture of Decoder Experts (MoDE), a dual-latent collaborative decoding framework for learned image compression. It decomposes reconstruction across an SQ branch (fidelity-oriented expert) and a VQ branch (perception-oriented expert), coordinated by decoder-side Expert-Specific Enhancement (ESE) and Cross-Expert Modulation (CEM) modules under a shared dual-stream bitstream. The central claim is that this yields a more favorable fidelity-perception balance than distortion-oriented, perception-oriented, generative, and dual-latent baselines across a wide bitrate range.
Significance. If the empirical results hold, the work is significant for learned image compression because it shows that decoder-side collaboration between complementary latent paradigms can resolve the tension of assigning conflicting roles (structural fidelity vs. semantic/perceptual cues) to a single latent, without requiring parameter-free derivations or architectural overhauls.
major comments (1)
- [§5] §5 (Experiments): the claim that ESE and CEM coordinate SQ and VQ branches to produce consistent gains without new artifacts or per-dataset retuning is load-bearing for the central result, yet the manuscript provides no ablation isolating CEM's selective transfer from potential artifact introduction or retuning effects.
minor comments (3)
- [§3.2] §3.2: the notation for the dual-stream bitstream should explicitly define how the shared rate is allocated between SQ and VQ branches to avoid ambiguity in the rate-distortion curves.
- [Figure 4] Figure 4: the perceptual quality examples would benefit from side-by-side zoomed insets at the same spatial locations across methods to make visual differences clearer.
- [Related Work] Related Work: the discussion of prior dual-latent methods should include a direct comparison table of their architectural differences from MoDE.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation of minor revision. We address the single major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): the claim that ESE and CEM coordinate SQ and VQ branches to produce consistent gains without new artifacts or per-dataset retuning is load-bearing for the central result, yet the manuscript provides no ablation isolating CEM's selective transfer from potential artifact introduction or retuning effects.
Authors: We agree that an explicit ablation isolating CEM's selective transfer is necessary to fully substantiate the central claim. In the revised version we will add a targeted ablation (new Table/Figure in §5) that disables CEM while keeping ESE and the dual-stream bitstream fixed, compares against a non-selective fusion baseline, and reports both quantitative metrics and qualitative crops across multiple datasets and bitrates. This will directly show that CEM's gains arise from complementary transfer rather than artifact suppression or dataset-specific retuning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new architectural framework (MoDE) with decoder-side modules ESE and CEM for dual-latent collaboration between SQ and VQ branches. Claims rest on empirical comparisons to baselines across bitrates using standard metrics, without any equations, derivations, or self-citations that reduce performance gains to fitted parameters, self-defined quantities, or prior author results by construction. The central design is independently described and tested, making the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End-to-end optimized image compression,
Johannes Ball ´e, Valero Laparra, and Eero Simoncelli, “End-to-end optimized image compression,” inICLR, 2017
2017
-
[2]
Variational image compression with a scale hyperprior,
Johannes Ball ´e, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston, “Variational image compression with a scale hyperprior,” inICLR, 2018
2018
-
[3]
Joint autoregres- sive and hierarchical priors for learned image compression,
David Minnen, Johannes Ball ´e, and George Toderici, “Joint autoregres- sive and hierarchical priors for learned image compression,” inNeurIPS, 2018
2018
-
[4]
Energy compaction-based image compression using convolutional au- toencoder,
Zhengxue Cheng, Heming Sun, Masaru Takeuchi, and Jiro Katto, “Energy compaction-based image compression using convolutional au- toencoder,”TMM, 2019
2019
-
[5]
iwave: Cnn- based wavelet-like transform for image compression,
Haichuan Ma, Dong Liu, Ruiqin Xiong, and Feng Wu, “iwave: Cnn- based wavelet-like transform for image compression,”TMM, 2019
2019
-
[6]
Learned image compression with discretized gaussian mixture likeli- hoods and attention modules,
Zhengxue Cheng, Heming Sun, Masaru Takeuchi, and Jiro Katto, “Learned image compression with discretized gaussian mixture likeli- hoods and attention modules,” inCVPR, 2020
2020
-
[7]
Learned image compression with gaussian-laplacian-logistic mixture model and concatenated residual modules,
Haisheng Fu, Feng Liang, Jianping Lin, Bing Li, Mohammad Akbari, Jie Liang, Guohe Zhang, Dong Liu, Chengjie Tu, and Jingning Han, “Learned image compression with gaussian-laplacian-logistic mixture model and concatenated residual modules,”TIP, 2023
2023
-
[8]
Elic: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding,
Dailan He, Ziming Yang, Weikun Peng, Rui Ma, Hongwei Qin, and Yan Wang, “Elic: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding,” inCVPR, 2022
2022
-
[9]
Learned multi-resolution variable-rate image compression with octave-based residual blocks,
Mohammad Akbari, Jie Liang, Jingning Han, and Chengjie Tu, “Learned multi-resolution variable-rate image compression with octave-based residual blocks,”TMM, 2021
2021
-
[10]
Image compression with product quantized masked image modeling,
Alaaeldin El-Nouby, Matthew J Muckley, Karen Ullrich, Ivan Laptev, Jakob Verbeek, and Herv ´e J ´egou, “Image compression with product quantized masked image modeling,”TMLR, 2023
2023
-
[11]
Extreme image compression using fine-tuned vqgans,
Qi Mao, Tinghan Yang, Yinuo Zhang, Zijian Wang, Meng Wang, Shiqi Wang, Libiao Jin, and Siwei Ma, “Extreme image compression using fine-tuned vqgans,” inDCC, 2024
2024
-
[12]
Unifying generation and compression: Ultra-low bitrate image coding via multi- stage transformer,
Naifu Xue, Qi Mao, Zijian Wang, Yuan Zhang, and Siwei Ma, “Unifying generation and compression: Ultra-low bitrate image coding via multi- stage transformer,” inICME, 2024
2024
-
[13]
Generative latent coding for ultra-low bitrate image compression,
Zhaoyang Jia, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu, “Generative latent coding for ultra-low bitrate image compression,” inCVPR, 2024
2024
-
[14]
Neural discrete representation learning,
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu, “Neural discrete representation learning,” inNeurIPS, 2017
2017
-
[15]
Taming transformers for high-resolution image synthesis,
Patrick Esser, Robin Rombach, and Bjorn Ommer, “Taming transformers for high-resolution image synthesis,” inCVPR, 2021
2021
-
[16]
Maskgit: Masked generative image transformer,
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman, “Maskgit: Masked generative image transformer,” inCVPR, 2022
2022
-
[17]
Hybridflow: Infusing continuity into masked codebook for extreme low- bitrate image compression,
Lei Lu, Yanyue Xie, Wei Jiang, Wei Wang, Xue Lin, and Yanzhi Wang, “Hybridflow: Infusing continuity into masked codebook for extreme low- bitrate image compression,” inACM MM, 2024
2024
-
[18]
Dual- conditioned training to exploit pre-trained codebook-based generative model in image compression,
Shoma Iwai, Tomo Miyazaki, and Shinichiro Omachi, “Dual- conditioned training to exploit pre-trained codebook-based generative model in image compression,”IEEE Access, 2024
2024
-
[19]
Dlf: Extreme image compression with dual-generative latent fusion,
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Yuan Zhang, and Yan Lu, “Dlf: Extreme image compression with dual-generative latent fusion,” inICCV, 2025
2025
-
[20]
Improving statistical fidelity for neural image compression with implicit local likelihood models,
Matthew J Muckley, Alaaeldin El-Nouby, Karen Ullrich, Herv ´e J ´egou, and Jakob Verbeek, “Improving statistical fidelity for neural image compression with implicit local likelihood models,” inICML, 2023
2023
-
[21]
The unreasonable effectiveness of deep features as a perceptual metric,
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” inCVPR, 2018
2018
-
[22]
Generative adversarial nets,
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative adversarial nets,” inNeurIPS, 2014
2014
-
[23]
Generative adversarial networks for extreme learned image compression,
Eirikur Agustsson, Michael Tschannen, Fabian Mentzer, Radu Timofte, and Luc Van Gool, “Generative adversarial networks for extreme learned image compression,” inICCV, 2019
2019
-
[24]
High-fidelity generative image compression,
Fabian Mentzer, George Toderici, Michael Tschannen, and Eirikur Agustsson, “High-fidelity generative image compression,” inNeurIPS, 2020
2020
-
[25]
Multi-realism image compression with a conditional generator,
Eirikur Agustsson, David Minnen, George Toderici, and Fabian Mentzer, “Multi-realism image compression with a conditional generator,” in CVPR, 2023
2023
-
[26]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inICLR, 2017
2017
-
[27]
Scaling vision with sparse mixture of experts,
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, Andr ´e Susano Pinto, Daniel Keysers, and Neil Houlsby, “Scaling vision with sparse mixture of experts,” inNeurIPS, 2021
2021
-
[28]
Rethinking lossy compression: The rate-distortion-perception tradeoff,
Yochai Blau and Tomer Michaeli, “Rethinking lossy compression: The rate-distortion-perception tradeoff,” inICML, 2019
2019
-
[29]
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al., “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,”IJCV, 2020
2020
-
[30]
Kodak photocd dataset,
Rich Franzen, “Kodak photocd dataset,” 1999
1999
-
[31]
Work- shop and challenge on learned image compression (clic2020),
Toderici George, Shi Wenzhe, Timofte Radu, Theis Lucas, Balle Jo- hannes, Agustsson Eirikur, Johnston Nick, and Mentzer Fabian, “Work- shop and challenge on learned image compression (clic2020),” 2020
2020
-
[32]
Testimages: a large-scale archive for testing visual devices and basic image processing algorithms.,
Nicola Asuni, Andrea Giachetti, et al., “Testimages: a large-scale archive for testing visual devices and basic image processing algorithms.,” in STAG, 2014
2014
-
[33]
Image quality assessment: Unifying structure and texture similarity,
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli, “Image quality assessment: Unifying structure and texture similarity,”TPAMI, 2020
2020
-
[34]
Overview of the versatile video coding (vvc) standard and its applications,
Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J. Sullivan, and Jens-Rainer Ohm, “Overview of the versatile video coding (vvc) standard and its applications,”TCSVT, 2021
2021
-
[35]
Toward extreme image compression with latent feature guidance and diffusion prior,
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, and Jingwen Jiang, “Toward extreme image compression with latent feature guidance and diffusion prior,”TCSVT, 2025
2025
-
[36]
Rdeic: Accelerating diffusion-based extreme image compression with relay residual diffusion,
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, and Ajmal Mian, “Rdeic: Accelerating diffusion-based extreme image compression with relay residual diffusion,”TCSVT, 2025
2025
-
[37]
Stablecodec: Taming one-step diffusion for extreme image compression,
Tianyu Zhang, Xin Luo, Li Li, and Dong Liu, “Stablecodec: Taming one-step diffusion for extreme image compression,” inICCV, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.