Recognition: 2 theorem links
· Lean TheoremAnalogical Trajectory Transfer
Pith reviewed 2026-05-15 01:41 UTC · model grok-4.3
The pith
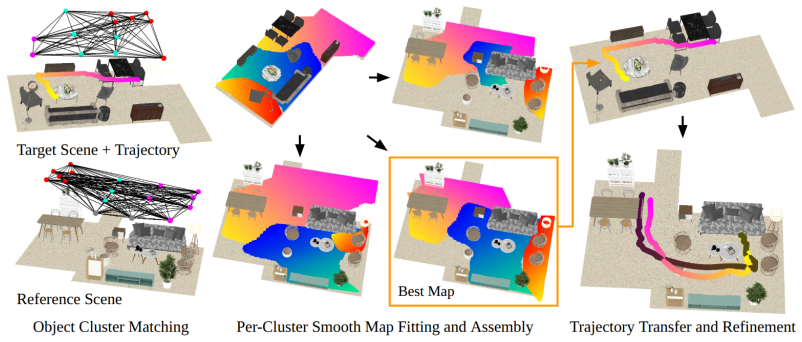
Scenes are partitioned into object-centric clusters whose cross-scene mappings are predicted hierarchically from 3D foundation features and then assembled and refined to transfer trajectories while preserving semantics and avoiding clashes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By partitioning each scene into object-centric clusters, estimating hierarchical smooth cross-scene mappings from 3D foundation-model features that capture both object and open-space context, combinatorially assembling the per-cluster maps, and refining the composite result to eliminate collisions and distortions, a semantically consistent and spatially coherent trajectory transfer is obtained without any per-scene training.
What carries the argument
Hierarchical smooth map prediction over object-centric clusters, using 3D foundation-model features to supply contextual information about object arrangements and open spaces, followed by combinatorial assembly and collision-refinement.
If this is right
- Trajectory transfer completes in approximately 0.6 seconds without any scene-specific training or manual tuning.
- The resulting transfers outperform baselines that rely on LLMs, VLMs, or scene-graph matching on both semantic fidelity and geometric coherence.
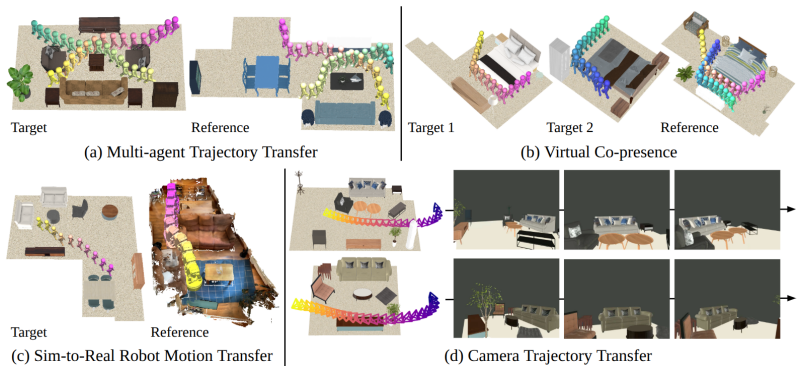
- The same pipeline directly supports virtual co-presence, multi-trajectory transfer, camera-path transfer, and human-to-robot motion transfer.
Where Pith is reading between the lines
- Because the method never trains on the target scenes, it could be applied on the fly to newly scanned or procedurally generated environments.
- The same cluster-wise decomposition might be reused to transfer other continuous quantities such as force fields or affordance maps.
- If stronger 3D foundation models become available, the same pipeline would immediately improve without any change to the assembly or refinement stages.
Load-bearing premise
The 3D foundation model features already encode enough information about object and open-space arrangements to produce accurate cross-scene mappings that keep both semantics and functionality intact.
What would settle it
A pair of scenes whose functional analogy is clear to humans yet whose 3D foundation features produce a transferred trajectory that intersects obstacles or violates functional constraints after refinement.
Figures






read the original abstract
We study analogical trajectory transfer, where the goal is to translate motion trajectories in one 3D environment to a semantically analogous location in another. Such a capacity would enable machines to perform analogical spatial reasoning, with applications in AR/VR co-presence, content creation, and robotics. However, even semantically similar scenes can still differ substantially in object placement, scale, and layout, so naively matching semantics leads to collisions or geometric distortions. Furthermore, finding where each trajectory point should transfer to has a large search space, as the mapping must preserve semantics and functionality without tearing the trajectory apart or causing collisions. Our key insight is to decompose the problem into spatially segregated subproblems and merge their solutions to produce semantically consistent and spatially coherent transfers. Specifically, we partition scenes into object-centric clusters and estimate cross-scene mappings via hierarchical smooth map prediction, using 3D foundation model features that encode contextual information from object and open-space arrangements. We then combinatorially assemble the per-cluster maps into an initial transfer and refine the result to remove collisions and distortions, yielding a spatially coherent trajectory. Our method does not require training, attains a fast runtime around 0.6 seconds, and outperforms baselines based on LLMs, VLMs, and scene graph matching. We further showcase applications in virtual co-presence, multi-trajectory transfer, camera transfer, and human-to-robot motion transfer, which indicates the broad applicability of our work to AR/VR and robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free approach to analogical trajectory transfer between semantically similar 3D scenes that may differ in layout, scale, and object placement. Scenes are partitioned into object-centric clusters; cross-scene mappings are estimated via hierarchical smooth map prediction that leverages 3D foundation model features encoding object and open-space context. Per-cluster maps are combinatorially assembled into an initial transfer and then refined to remove collisions and distortions, producing a spatially coherent result. The method is reported to run in ~0.6 s and to outperform LLM-, VLM-, and scene-graph-based baselines, with applications demonstrated in virtual co-presence, multi-trajectory transfer, camera transfer, and human-to-robot motion transfer.
Significance. If the experimental claims are substantiated, the work would offer a practical, training-free solution to a challenging problem in spatial analogical reasoning, with clear utility for AR/VR content creation and robotics. The decomposition strategy and reliance on off-the-shelf 3D foundation models are attractive because they avoid scene-specific training. The reported speed and breadth of applications strengthen the potential impact in computer vision and robotics venues.
major comments (2)
- [Abstract] Abstract and experimental section: the central claim of outperformance over LLM, VLM, and scene-graph baselines is stated without any quantitative tables, error metrics, ablation studies, or failure-case analysis visible in the manuscript. Because the contribution rests on these empirical results, their absence is load-bearing and prevents verification of the method's superiority.
- [Method] Method description (hierarchical smooth map prediction paragraph): the claim that 3D foundation model features supply 'contextual information from object and open-space arrangements' sufficient to produce functionality-preserving mappings is asserted without supporting analysis or counter-examples. No evidence is given that the embeddings reliably distinguish geometrically similar but functionally distinct configurations (e.g., narrow corridor vs. wide aisle), which directly affects the correctness of the subsequent combinatorial assembly and refinement steps.
minor comments (2)
- The runtime figure of 0.6 seconds is given without hardware specification, per-component timing breakdown, or comparison to baseline runtimes.
- Notation for the hierarchical map prediction and combinatorial assembly steps could be clarified with a concise pseudocode listing or explicit variable definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas where additional empirical support and analysis will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental section: the central claim of outperformance over LLM, VLM, and scene-graph baselines is stated without any quantitative tables, error metrics, ablation studies, or failure-case analysis visible in the manuscript. Because the contribution rests on these empirical results, their absence is load-bearing and prevents verification of the method's superiority.
Authors: We agree that the empirical claims require explicit quantitative support for verification. The submitted manuscript emphasized the method and qualitative demonstrations, but the revised version will expand the experimental section with quantitative tables reporting metrics including average trajectory error, collision rates, and functional preservation scores against the LLM, VLM, and scene-graph baselines. Ablation studies isolating the hierarchical mapping, combinatorial assembly, and refinement components, plus a dedicated failure-case analysis, will be added. revision: yes
-
Referee: [Method] Method description (hierarchical smooth map prediction paragraph): the claim that 3D foundation model features supply 'contextual information from object and open-space arrangements' sufficient to produce functionality-preserving mappings is asserted without supporting analysis or counter-examples. No evidence is given that the embeddings reliably distinguish geometrically similar but functionally distinct configurations (e.g., narrow corridor vs. wide aisle), which directly affects the correctness of the subsequent combinatorial assembly and refinement steps.
Authors: We thank the referee for this precise observation. While the foundation models are pretrained on diverse 3D data and their features are intended to capture contextual arrangements, we acknowledge the absence of direct supporting analysis. The revised manuscript will augment the method section with feature similarity visualizations and quantitative comparisons for geometrically similar yet functionally distinct pairs (e.g., narrow corridors vs. wide aisles). We will also discuss how these distinctions propagate to the combinatorial assembly and refinement stages, including counter-examples illustrating both successful mappings and cases corrected by refinement. revision: yes
Circularity Check
No circularity: derivation relies on external 3D foundation models and independent geometric steps
full rationale
The paper's chain decomposes the transfer task into clustering, hierarchical mapping via pretrained 3D features, combinatorial assembly, and collision-refinement. None of these steps are shown to reduce to fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations. The method explicitly states it requires no training and uses off-the-shelf foundation models whose embeddings are treated as independent inputs. No uniqueness theorems or ansatzes are smuggled via author citations, and no known empirical pattern is merely renamed. The central claim therefore remains non-circular by the paper's own presentation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D foundation model features encode contextual information from object and open-space arrangements sufficient for semantically consistent mappings
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we partition scenes into object-centric clusters and estimate cross-scene mappings via hierarchical smooth map prediction, using 3D foundation model features... combinatorially assemble the per-cluster maps... refine the result to remove collisions and distortions
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Object Graph Construction and Clustering... Graph-based Cluster Matching... Per-Cluster Smooth Map Fitting... Per-Cluster Smooth Map Assembly
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Kim, Junho and Choi, Changwoon and Jang, Hojun and Kim, Young Min , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
work page 2021
-
[2]
The Farthest Point Strategy for Progressive Image Sampling , volume =
Eldar, Yuval and Lindenbaum, Michael and Porat, Moshe and Zeevi, Yehoshua , year =. The Farthest Point Strategy for Progressive Image Sampling , volume =. IEEE Transactions on Image Processing , doi =
-
[3]
Eddy, William F. , title =. 1977 , issue_date =. doi:10.1145/355759.355766 , journal =
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
3d-front: 3d furnished rooms with layouts and semantics , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[5]
International Journal of Computer Vision (IJCV) , pages=
3d-future: 3d furniture shape with texture , author=. International Journal of Computer Vision (IJCV) , pages=
-
[6]
Why do children struggle on analogical reasoning tasks? Considering the role of problem format by measuring visual attention , author=. Acta Psychologica , volume=. 2022 , publisher=
work page 2022
-
[7]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year =
-
[8]
BERT: Pre-training of deep bidirectional transformers for language understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the Conference of the North A merican Chapter of the Association for Computational Linguistics (NAACL). 2019. doi:10.18653/v1/N19-1423
-
[9]
Proceedings of the Conference on Robot Learning (CoRL) , year=
Neural Attention Field: Emerging Point Relevance in 3D Scenes for One-Shot Dexterous Grasping , author=. Proceedings of the Conference on Robot Learning (CoRL) , year=
-
[10]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[11]
Representation Learning with Contrastive Predictive Coding , author=. ArXiv , year=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Exploring Simple Siamese Representation Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[13]
Proceedings of the International Conference on Machine Learning (ICML) , year =
A Simple Framework for Contrastive Learning of Visual Representations , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[14]
Big Self-Supervised Models are Strong Semi-Supervised Learners , url =
Chen, Ting and Kornblith, Simon and Swersky, Kevin and Norouzi, Mohammad and Hinton, Geoffrey E , booktitle =. Big Self-Supervised Models are Strong Semi-Supervised Learners , url =
-
[15]
and Leonidas Guibas and Or Litany
Saining Xie and Jiatao Gu and Demi Guo and Qi, Charles R. and Leonidas Guibas and Or Litany. PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding. Proceedings of the European Conference on Computer Vision (ECCV). 2020
work page 2020
-
[16]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume=
Convolutional hough matching networks for robust and efficient visual correspondence , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume=. 2023 , publisher=
work page 2023
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Transformatcher: Match-to-match attention for semantic correspondence , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[18]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
Learning 3d keypoint descriptors for non-rigid shape matching , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Learning SO (3)-Invariant Semantic Correspondence via Local Shape Transform , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[20]
Computer Graphics Forum , volume=
Neural semantic surface maps , author=. Computer Graphics Forum , volume=
-
[21]
ACM Transactions on Graphics (TOG) , volume=
Blended intrinsic maps , author=. ACM Transactions on Graphics (TOG) , volume=. 2011 , publisher=
work page 2011
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Neural surface maps , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[23]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
Robo-abc: Affordance generalization beyond categories via semantic correspondence for robot manipulation , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[24]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
Guided semantic flow , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Fcss: Fully convolutional self-similarity for dense semantic correspondence , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[26]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
Parn: Pyramidal affine regression networks for dense semantic correspondence , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[27]
Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , volume=
Recurrent transformer networks for semantic correspondence , author=. Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , volume=
-
[28]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , year=
Dctm: Discrete-continuous transformation matching for semantic flow , author=. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , year=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Misc210k: A large-scale dataset for multi-instance semantic correspondence , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Discobox: Weakly supervised instance segmentation and semantic correspondence from box supervision , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Probing the 3d awareness of visual foundation models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[32]
Clip-fields: Weakly supervised semantic fields for robotic memory , author=. Proceedings of the Workshop on Language and Robotics at the Conference on Robot Learning (CoRL) , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Emergent correspondence from image diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) , year=
Nice-slam: Neural implicit scalable encoding for slam , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) , year=
-
[35]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
work page 2021
-
[36]
Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , volume=
Neural matching fields: Implicit representation of matching fields for visual correspondence , author=. Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , volume=
-
[37]
Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year=
nerf2nerf: Pairwise registration of neural radiance fields , author=. Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
NeRF Analogies: Example-Based Visual Attribute Transfer for NeRFs , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[39]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Diffusion Model for Dense Matching , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[40]
Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year=
Neural descriptor fields: Se (3)-equivariant object representations for manipulation , author=. Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wei, Qiuhong Anna and Ding, Sijie and Park, Jeong Joon and Sajnani, Rahul and Poulenard, Adrien and Sridhar, Srinath and Guibas, Leonidas , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[42]
NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction , url =
Wang, Peng and Liu, Lingjie and Liu, Yuan and Theobalt, Christian and Komura, Taku and Wang, Wenping , booktitle =. NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction , url =
- [43]
-
[44]
Mathematics of Computation , year=
Scattered data interpolation: tests of some methods , author=. Mathematics of Computation , year=
-
[45]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[46]
Kiefer, J. and Wolfowitz, J. Stochastic Estimation of the Maximum of a Regression Function. Annals of Mathematical Statistics. 1952. doi:10.1214/aoms/1177729392
-
[47]
Gilad Baruch and Zhuoyuan Chen and Afshin Dehghan and Tal Dimry and Yuri Feigin and Peter Fu and Thomas Gebauer and Brandon Joffe and Daniel Kurz and Arik Schwartz and Elad Shulman , booktitle=. 2021 , url=
work page 2021
-
[48]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
SGAligner : 3D Scene Alignment with Scene Graphs , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[49]
Qianxu Wang and Haotong Zhang and Congyue Deng and Yang You and Hao Dong and Yixin Zhu and Leonidas Guibas , booktitle=. Sparse. 2024 , url=
work page 2024
-
[50]
Xie, Yaxu and Pagani, Alain and Stricker, Didier , booktitle =. 2024 , url =
work page 2024
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , month=
Open3DSG: Open-Vocabulary 3D Scene Graphs from Point Clouds with Queryable Objects and Open-Set Relationships , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , month=
-
[52]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Vision Transformers Need Registers , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[53]
Transactions on Machine Learning Research (TMLR) , year=
DINOv2: Learning Robust Visual Features without Supervision , author=. Transactions on Machine Learning Research (TMLR) , year=
-
[54]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Emerging Properties in Self-Supervised Vision Transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[55]
Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , year=
Emergent Correspondence from Image Diffusion , author=. Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[56]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[57]
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory , author =. 2022 , booktitle =
work page 2022
-
[58]
Proceedings of the Conference on Robot Learning (CoRL) , year=
Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation , author=. Proceedings of the Conference on Robot Learning (CoRL) , year=
-
[59]
Proceedings of the Conference on Robot Learning (CoRL) , year=
D ^3 Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Rearrangement , author=. Proceedings of the Conference on Robot Learning (CoRL) , year=
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[61]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[62]
Naval Research Logistics (NRL) , year=
The Hungarian method for the assignment problem , author=. Naval Research Logistics (NRL) , year=
-
[63]
Katta G. Murty , journal =. An Algorithm for Ranking all the Assignments in Order of Increasing Cost , year =
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Vector neurons: A general framework for so (3)-equivariant networks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[65]
Hyperpixel Flow: Semantic Correspondence with Multi-layer Neural Features , author=. ICCV , year=
-
[66]
SPair-71k: A Large-scale Benchmark for Semantic Correspondence , author=. ArXiv , year=
-
[67]
Jeon, Sangryul and Min, Dongbo and Kim, Seungryong and Choe, Jihwan and Sohn, Kwanghoon , title =. 2020 , isbn =. doi:10.1007/978-3-030-58604-1_38 , keywords =
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Telling Left from Right: Identifying Geometry-Aware Semantic Correspondence , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[69]
Proceedings of the Conference on Robot Learning (CoRL) , year=
Automated Creation of Digital Cousins for Robust Policy Learning , author=. Proceedings of the Conference on Robot Learning (CoRL) , year=
-
[70]
Seo, HyunA and Yi, Juheon and Balan, Rajesh and Lee, Youngki , title =. 2024 , booktitle =
work page 2024
-
[71]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). 2019
work page 2019
-
[72]
Moondream: A Tiny Vision Model , howpublished =. 2024
work page 2024
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Scaling up dynamic human-scene interaction modeling , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[74]
Umeyama, S. , journal=. Least-squares estimation of transformation parameters between two point patterns , year=
-
[75]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA), pp
Learning-based Relational Object Matching Across Views , author =. Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year =. doi:10.1109/ICRA48891.2023.10161393 , url =
-
[76]
Proceedings of the Conference on Robot Learning (CoRL) , year=
Open-TeleVision: Teleoperation with Immersive Active Visual Feedback , author=. Proceedings of the Conference on Robot Learning (CoRL) , year=
-
[77]
and Peluse, Patrick and Caldas, Luisa , booktitle=
Keshavarzi, Mohammad and Zollhoefer, Michael and Yang, Allen Y. and Peluse, Patrick and Caldas, Luisa , booktitle=. Synthesizing Novel Spaces for Remote Telepresence Experiences , year=
-
[78]
You, Yang and Lou, Yujing and Shi, Ruoxi and Liu, Qi and Tai, Yu-Wing and Ma, Lizhuang and Wang, Weiming and Lu, Cewu , journal=. 2022 , volume=. doi:10.1109/TPAMI.2021.3130590 , url =
-
[79]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
ASIC: Aligning Sparse Image Collections , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[80]
arXiv preprint arXiv:2403.19474 , year=
SG-PGM: Partial Graph Matching Network with Semantic Geometric Fusion for 3D Scene Graph Alignment and Its Downstream Tasks , author=. arXiv preprint arXiv:2403.19474 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.