Recognition: no theorem link
SceneForge: Structured World Supervision from 3D Interventions
Pith reviewed 2026-05-15 01:30 UTC · model grok-4.3
The pith
SceneForge generates consistent supervision for removal tasks by propagating explicit interventions through editable 3D scene states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
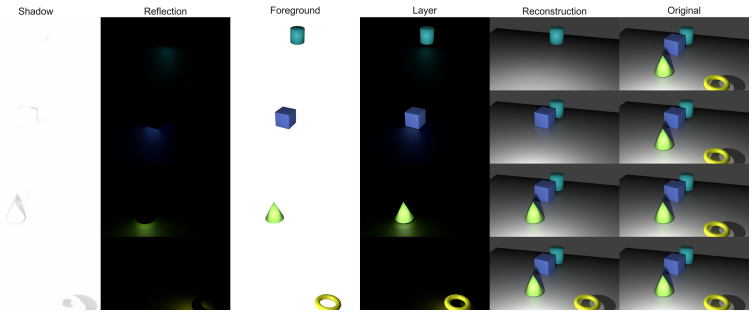
SceneForge is an intervention-driven framework that represents each scene as a persistent world containing semantic, geometric, and physical dependencies. Explicit interventions are applied to this shared state and their effects are propagated to produce aligned supervision signals such as counterfactual observations, multi-view renderings, and effect-aware outputs like shadows and reflections. The framework yields a licensing-clean indoor resource containing large numbers of counterfactual pairs and annotations from over 2K scenes, supporting both single-view and registered multi-view settings, and yields measurable gains in removal tasks when used under matched training budgets.
What carries the argument
SceneForge, an intervention-driven framework that models scenes as persistent worlds with dependencies and propagates explicit edits through those dependencies to render consistent supervision.
If this is right
- Incorporating SceneForge supervision raises quantitative and qualitative performance on object removal and scene removal across multiple benchmarks under matched training budgets.
- Supervision remains consistent with object structure and scene-level effects because it derives from a shared world state rather than image-space processing.
- The approach supplies aligned counterfactual observations, multi-view observations, and effect-aware signals such as shadows and reflections.
- The resulting resource covers diverse single-view and registered multi-view settings from over 2K scenes and provides a scalable foundation for intervention-consistent multimodal learning.
Where Pith is reading between the lines
- The same intervention-propagation mechanism could support additional tasks that require labels stable under edits, such as novel-view synthesis or physical property prediction.
- Practical use would hinge on measuring how much domain gap remains between the generated supervision and real captured images.
- If the dependency modeling holds, similar world-state supervision could reduce reliance on large-scale manual annotation for consistency-critical vision problems.
Load-bearing premise
That supervision generated from synthetic 3D interventions transfers effectively to real-world images and that the modeled scene dependencies accurately reflect real physical and geometric relationships.
What would settle it
A controlled experiment in which models trained with SceneForge supervision show no improvement over matched baselines when evaluated on held-out real images with ground-truth removal masks would falsify the central performance claim.
Figures














read the original abstract
Many multimodal learning tasks require supervision that remains consistent across edits, viewpoints, and scene-level interventions. However, such supervision is difficult to obtain from observation-level datasets, which do not expose the underlying scene state or how changes propagate through it. We present SceneForge, an intervention-driven framework that generates structured supervision from editable 3D world states. SceneForge represents each scene as a persistent world with semantic, geometric, and physical dependencies. By applying explicit interventions (e.g., object removal or camera variation) and propagating their effects through scene dependencies, SceneForge renders supervision that remains consistent with object structure and scene-level effects. This produces aligned outputs including counterfactual observations, multi-view observations, and effect-aware signals such as shadows and reflections, all derived from a shared world state rather than post hoc image-space processing. We instantiate SceneForge using Infinigen and Blender to construct a licensing-clean indoor supervision resource with a large number of counterfactual pairs and aligned annotations from over 2K scenes, covering both diverse single-view and registered multi-view settings. Under matched training budgets, incorporating SceneForge supervision improves both object removal and scene removal performance across multiple benchmarks in both quantitative and qualitative evaluation. These results indicate that modeling supervision as structured state transitions in editable worlds provides a practical and scalable foundation for intervention-consistent multimodal learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SceneForge, an intervention-driven framework that models scenes as persistent 3D worlds with semantic, geometric, and physical dependencies. Using Infinigen and Blender, it generates a licensing-clean indoor dataset from over 2K scenes containing counterfactual pairs, multi-view renders, and effect-aware signals (shadows, reflections). The central claim is that incorporating this structured supervision improves object removal and scene removal performance across multiple benchmarks under matched training budgets, with gains shown in both quantitative and qualitative evaluations.
Significance. If the empirical results hold, the work supplies a scalable route to supervision that respects scene-level state transitions rather than relying on post-hoc image edits. This could benefit multimodal tasks requiring edit consistency, such as inpainting or novel-view synthesis. The construction of a large, editable 3D supervision resource is a concrete asset that future work can build upon.
major comments (2)
- [Abstract and Experimental Results] The headline claim of performance gains on real or mixed benchmarks under matched budgets is load-bearing, yet the abstract supplies no numerical results, baselines, error bars, or ablation details. The experimental section must include these to allow assessment of whether gains arise from intervention consistency rather than increased data volume or regularization.
- [Method and Experiments] The synthetic-to-real transfer assumption is central: supervision generated from Infinigen/Blender interventions must accurately propagate real physical and geometric effects. No direct validation (real-image intervention ground truth, cross-domain ablation, or fidelity metrics) is described to confirm that modeled dependencies match actual scene physics rather than synthetic artifacts.
minor comments (2)
- [Abstract] The abstract refers to 'multiple benchmarks' without naming them; an explicit list would improve readability.
- [Dataset Construction] Clarify the precise count of counterfactual pairs, the distribution of intervention types, and how multi-view registration is performed across the 2K scenes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, with proposed revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The headline claim of performance gains on real or mixed benchmarks under matched budgets is load-bearing, yet the abstract supplies no numerical results, baselines, error bars, or ablation details. The experimental section must include these to allow assessment of whether gains arise from intervention consistency rather than increased data volume or regularization.
Authors: We agree that the abstract would benefit from explicit numerical results to support the claims. In the revised version, we will incorporate key quantitative findings from the experiments, including specific performance improvements on object removal and scene removal benchmarks under matched training budgets, along with references to the relevant baselines and ablations. The experimental section already contains ablations that control for data volume and regularization effects by comparing against non-intervention baselines with equivalent data quantities; we will ensure these are clearly highlighted with error bars from repeated runs to demonstrate that gains stem from intervention consistency. revision: yes
-
Referee: [Method and Experiments] The synthetic-to-real transfer assumption is central: supervision generated from Infinigen/Blender interventions must accurately propagate real physical and geometric effects. No direct validation (real-image intervention ground truth, cross-domain ablation, or fidelity metrics) is described to confirm that modeled dependencies match actual scene physics rather than synthetic artifacts.
Authors: We acknowledge the value of direct validation for the synthetic-to-real transfer. While we do not provide paired real-image intervention ground truth (due to the inherent difficulty of obtaining such data), our primary evaluations are conducted on real-world benchmarks, where the addition of SceneForge supervision yields measurable gains. This provides indirect evidence of effective transfer. In revision, we will add a dedicated discussion subsection on effect fidelity, including qualitative comparisons of rendered physical effects (e.g., shadows and reflections) against real scenes, and expand cross-domain analysis where possible. We will also explicitly note the absence of direct real intervention validation as a limitation. revision: partial
Circularity Check
No circularity: empirical framework with external benchmarks
full rationale
The paper introduces SceneForge as an intervention-driven supervision generator instantiated via external tools (Infinigen, Blender) on 2K+ scenes, then reports measured performance gains on object/scene removal benchmarks under matched training budgets. No equations, fitted parameters, or predictions are presented that reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The derivation chain consists of method description followed by independent empirical evaluation, making the work self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Editable 3D representations accurately capture and propagate semantic, geometric, and physical dependencies under interventions
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[2]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Meta-Sim: Learning to Generate Synthetic Datasets , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Kubric: A Scalable Dataset Generator , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Infinite Photorealistic Worlds Using Procedural Generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
ORIDa: Object-centric Real-world Image Composition Dataset , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
UltraEdit: Instruction-based Fine-Grained Image Editing at Scale , author=. The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[8]
ArXiv , year=
BlenderProc , author=. ArXiv , year=
-
[9]
2020 , note =
NVIDIA Omniverse , author =. 2020 , note =
2020
-
[10]
2020 , note =
CATER: A Diagnostic Dataset for Compositional Actions and Temporal Reasoning , author =. 2020 , note =
2020
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[12]
International Journal of Computer Vision , year =
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations , author =. International Journal of Computer Vision , year =
-
[13]
IEEE Conference on Computer Vision and Pattern Recognition , year=
Semantic Amodal Segmentation , author=. IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[14]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Amodal Instance Segmentation With KINS Dataset , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
InstructPix2Pix: Learning to Follow Image Editing Instructions , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Referring Image Editing: Object-Level Image Editing via Referring Expressions , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[17]
Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence , pages =
Deep Automatic Natural Image Matting , author =. Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence , pages =
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Referring Image Matting , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[19]
International Journal of Computer Vision , year =
Bridging Composite and Real: Towards End-to-End Deep Image Matting , author =. International Journal of Computer Vision , year =
-
[20]
Proceedings of the 29th ACM International Conference on Multimedia , year =
Privacy-Preserving Portrait Matting , author =. Proceedings of the 29th ACM International Conference on Multimedia , year =
-
[21]
Proceedings of the IEEE International Conference on Automation Science and Engineering , year =
One-Shot Shape-Based Amodal-to-Modal Instance Segmentation , author =. Proceedings of the IEEE International Conference on Automation Science and Engineering , year =
-
[22]
European Conference on Computer Vision , year =
Amodal Instance Segmentation , author =. European Conference on Computer Vision , year =
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Open-World Amodal Appearance Completion , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[24]
European Conference on Computer Vision , year =
Visual Relationship Detection with Language Priors , author =. European Conference on Computer Vision , year =
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Neural Motifs: Scene Graph Parsing with Global Context , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
AGQA: A Benchmark for Compositional Spatio-Temporal Reasoning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[27]
Matt Deitke and Eli VanderBilt and Alvaro Herrasti and Luca Weihs and Kiana Ehsani and Jordi Salvador and Winson Han and Eric Kolve and Aniruddha Kembhavi and Roozbeh Mottaghi , booktitle=. Proc
-
[28]
DiCarlo and Joshua B
Chuang Gan and Jeremy Schwartz and Seth Alter and Damian Mrowca and Martin Schrimpf and James Traer and Julian De Freitas and Jonas Kubilius and Abhishek Bhandwaldar and Nick Haber and Megumi Sano and Kuno Kim and Elias Wang and Michael Lingelbach and Aidan Curtis and Kevin Tyler Feigelis and Daniel Bear and Dan Gutfreund and David Daniel Cox and Antonio ...
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Habitat: A Platform for Embodied AI Research , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[30]
Proceedings of the European Conference on Computer Vision (ECCV) Workshops , year =
UnrealCV: Connecting Computer Vision to Unreal Engine , author =. Proceedings of the European Conference on Computer Vision (ECCV) Workshops , year =
-
[31]
European Conference on Computer Vision , year =
Playing for Data: Ground Truth from Computer Games , author =. European Conference on Computer Vision , year =
-
[32]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[33]
Proceedings of the 1st Annual Conference on Robot Learning , year =
CARLA: An Open Urban Driving Simulator , author =. Proceedings of the 1st Annual Conference on Robot Learning , year =
-
[34]
RORem: Training a Robust Object Remover with Human-in-the-Loop , year=
Li, Ruibin and Yang, Tao and Guo, Song and Zhang, Lei , booktitle=. RORem: Training a Robust Object Remover with Human-in-the-Loop , year=
-
[35]
Omnieraser: Remove objects and their effects in images with paired video-frame data,
OmniEraser: Remove Objects and Their Effects in Images with Paired Video-Frame Data , author =. arXiv preprint arXiv:2501.07397 , year =
-
[36]
2025 , eprint =
ROSE: Remove Objects with Side Effects in Videos , author =. 2025 , eprint =
2025
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[38]
Pexels Free Stock Photos , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.