Recognition: no theorem link
zSort: Stable Distribution Sort using Z-Score Partitioning
Pith reviewed 2026-05-15 02:15 UTC · model grok-4.3
The pith
zSort is a stable distribution sort using z-score partitioning that achieves up to 4.5x speedup over comparison-based stable sorts while matching unstable algorithms like Skasort on many inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
zSort consistently outperforms widely used comparison based stable sorting algorithms, achieving up to 3x-4.5x speedups, and a relatively better performance compared to LSD Radix, with larger gains on duplicate heavy and partially ordered inputs.
Load-bearing premise
The assumption that z-score based partitioning remains effective and avoids extreme worst-case behavior across all real-world input distributions without requiring additional safeguards or pass scaling.
Figures






read the original abstract
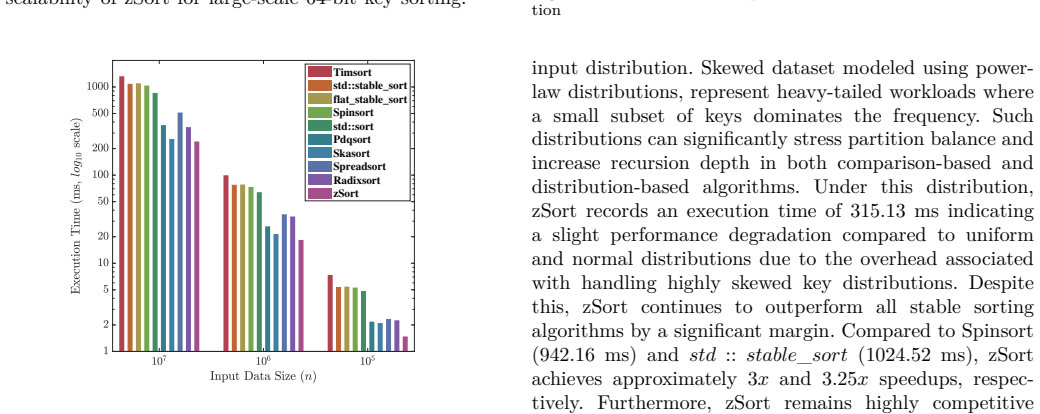
Sorting is a foundational primitive in modern data processing, influencing the execution speed of high-performance data pipelines. However, the algorithmic landscape is currently bifurcated by a pervasive "Stability Tax": practitioners must sacrifice either order preservation for high throughput or execution speed for stability. To address these limitations, this paper introduces, zSort, an adaptive z-score based distribution sorting algorithm that guarantees stability while avoiding pass complexity that scales with key-width. The performance of the proposed technique is evaluated using Microarchitectural analysis and experimental results. Microarchitectural analysis shows that zSort achieves a lower bad-speculation overhead (19.7%) than both stable baselines and several high-performance unstable algorithms and sustains a competitive IPC of 1.44. Empirical evaluation across diverse input distributions and datasets of up to 10^7 elements (64 bit) demonstrates that zSort consistently outperforms widely used comparison based stable sorting algorithms, achieving up to 3x-4.5x speedups, and a relatively better performance compared to LSD Radix, with larger gains on duplicate heavy and partially ordered inputs. Despite providing stability, zSort achieves comparable throughput as compared to high-performance unstable algorithms such as Skasort. It also maintains this performance on adaptive workloads where methods like Pdqsort typically excel and doesn't exhibit any extreme worst case. These results indicate that zSort substantially narrows the traditional performance gap between stable and unstable sorting and provides an efficient, stable sorting alternative.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces zSort, a stable distribution sorting algorithm based on z-score partitioning that assigns 64-bit keys to buckets using global mean and standard deviation. It claims to deliver stability without the key-width-dependent passes of radix sort, reporting up to 3x-4.5x speedups over stable comparison sorts, superior performance to LSD Radix on duplicate-heavy and partially ordered inputs, and throughput comparable to unstable algorithms such as Skasort. Microarchitectural measurements (IPC 1.44, bad-speculation 19.7%) and experiments on datasets up to 10^7 elements are presented to support the absence of extreme worst-case behavior.
Significance. If the empirical claims hold under broader validation, zSort would narrow the longstanding performance gap between stable and unstable sorting, offering a practical primitive for high-throughput data pipelines that require order preservation. The microarchitectural breakdown provides concrete insight into why the method sustains competitive IPC.
major comments (2)
- [§3] §3 (z-score partitioning procedure): No recurrence, probabilistic bound, or worst-case analysis is supplied for bucket sizes or recursion depth when the global mean/std is used on arbitrary, heavy-tailed, or adversarial 64-bit distributions. The abstract's assertion of 'no extreme worst case' therefore rests on an unverified assumption rather than a demonstrated invariant.
- [§5] §5 (Experimental Evaluation): Speedup figures and microarchitectural counters are reported without error bars, number of repetitions, or a precise description of how 'duplicate heavy' and 'partially ordered' inputs were generated. This omission prevents independent assessment of whether the observed 3x-4.5x gains are robust or sensitive to particular synthetic distributions.
minor comments (2)
- [Abstract] The abstract states 'relatively better performance compared to LSD Radix' without quantifying the margin or identifying the exact LSD variant and key-width configuration used.
- [§3] Notation for the z-score threshold and bucket assignment rule is introduced without an accompanying equation or pseudocode line number, making the partitioning step harder to reproduce from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to improve the manuscript's rigor and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (z-score partitioning procedure): No recurrence, probabilistic bound, or worst-case analysis is supplied for bucket sizes or recursion depth when the global mean/std is used on arbitrary, heavy-tailed, or adversarial 64-bit distributions. The abstract's assertion of 'no extreme worst case' therefore rests on an unverified assumption rather than a demonstrated invariant.
Authors: We acknowledge that the manuscript provides no formal recurrence, probabilistic bound, or worst-case analysis for bucket sizes or recursion depth. The claim of no extreme worst-case behavior is supported solely by empirical results on datasets up to 10^7 elements across diverse distributions. In revision we will add a dedicated discussion subsection on the expected statistical properties of z-score bucket assignment (including why heavy tails are mitigated by the global mean/std normalization) together with additional experiments using explicitly adversarial and heavy-tailed synthetic inputs. A complete theoretical worst-case analysis for arbitrary 64-bit keys is left as future work. revision: partial
-
Referee: [§5] §5 (Experimental Evaluation): Speedup figures and microarchitectural counters are reported without error bars, number of repetitions, or a precise description of how 'duplicate heavy' and 'partially ordered' inputs were generated. This omission prevents independent assessment of whether the observed 3x-4.5x gains are robust or sensitive to particular synthetic distributions.
Authors: We agree that the current experimental reporting lacks error bars, repetition counts, and precise input-generation details. In the revised manuscript we will (1) report all timing and IPC figures with error bars computed over 10 independent runs, (2) explicitly state the repetition count in the evaluation section, and (3) provide exact generation procedures (duplicate-heavy: 50 % keys drawn from a narrow normal distribution centered on the global mean; partially ordered: 75 % of the array sorted in increasing order with the remaining 25 % inserted uniformly at random). revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces zSort as a new adaptive distribution sorting algorithm based on z-score partitioning, with stability guarantees and empirical performance claims. No equations, derivations, or first-principles predictions are presented that reduce to fitted inputs, self-citations, or ansatzes. Performance results are reported as direct outcomes from benchmarks on datasets up to 10^7 elements across diverse distributions, without any claimed 'prediction' that is statistically forced by tuning on the same data. The absence of mathematical derivation chains means no load-bearing steps qualify under the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Z-score partitioning produces effective bucket distributions for the tested input classes without pathological cases
Reference graph
Works this paper leans on
-
[1]
Sorting it out in hardware: A state- of-the-art survey
Amir Jalilvand, Faeze S Banitaba, S Newsha Estiri, Sercan Ay- gun, and M Hassan Najafi. Sorting it out in hardware: A state- of-the-art survey. ACM Transactions on Design Automation of Electronic Systems, 30(4):1–31, 2025
work page 2025
-
[2]
Implementing sorting in database systems
Goetz Graefe. Implementing sorting in database systems. ACM Computing Surveys (CSUR), 38(3):10–es, 2006
work page 2006
-
[3]
https://sortbenchmark.org/ (ac- cessed Mar, 2026)
Sort Benchmark Home Page. https://sortbenchmark.org/ (ac- cessed Mar, 2026)
work page 2026
-
[4]
Choosing the” best” sorting algorithm for optimal energy consumption
Christian Bunse, Hagen Höpfner, Suman Roychoudhury, and Essam Mansour. Choosing the” best” sorting algorithm for optimal energy consumption. In International Conference on Software and Data Technologies, volume 1, pages 199–206. SCITEPRESS, 2009
work page 2009
-
[5]
Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, and Clifford Stein. Introduction to algorithms. MIT press, 2022
work page 2022
-
[6]
Blockquicksort: A voiding branch mispredictions in quicksort
Stefan Edelkamp and Armin Weiß. Blockquicksort: A voiding branch mispredictions in quicksort. ACM J. Exp. Algorithmics, 24, 2019
work page 2019
-
[7]
Orson RL Peters. Pattern-defeating quicksort. arXiv preprint arXiv:2106.05123, 2021
-
[8]
https://github.com/skarupke/ska_sort (accessed Mar, 2026)
SkaSort. https://github.com/skarupke/ska_sort (accessed Mar, 2026)
work page 2026
-
[9]
Engineering in-place (shared-memory) sorting algo- rithms
Michael Axtmann, Sascha Witt, Daniel Ferizovic, and Peter Sanders. Engineering in-place (shared-memory) sorting algo- rithms. ACM Transactions on Parallel Computing, 9(1):1–62, 2022
work page 2022
-
[10]
https://en.cppreference.com/w/cpp/ algorithm/stable_sort.html (accessed Mar, 2026)
Std: Stable Sort. https://en.cppreference.com/w/cpp/ algorithm/stable_sort.html (accessed Mar, 2026)
work page 2026
-
[11]
https://en.cppreference.com/w/cpp/algorithm/sort
Std: Sort. https://en.cppreference.com/w/cpp/algorithm/sort. html (accessed Mar, 2026)
work page 2026
-
[12]
https://www.boost.org/doc/libs/latest/libs/sort/ doc/html/index.html (accessed Mar, 2026)
Boost.Sort. https://www.boost.org/doc/libs/latest/libs/sort/ doc/html/index.html (accessed Mar, 2026)
work page 2026
-
[13]
Shashank Raj and Kalyanmoy Deb. Evosort: a genetic- algorithm-based adaptive parallel sorting framework for large- scale high performance computing. International Journal of Parallel, Emergent and Distributed Systems, pages 1–39, 2025
work page 2025
-
[14]
Cache-conscious sorting of large sets of strings with dynamic tries
Ranjan Sinha and Justin Zobel. Cache-conscious sorting of large sets of strings with dynamic tries. ACM J. Exp. Algorithmics, 9:1–32, 2005
work page 2005
-
[15]
The art of computer programming: Sorting and searching, volume 3
Donald E Knuth. The art of computer programming: Sorting and searching, volume 3. Addison-Wesley Professional, 1998
work page 1998
-
[16]
https://cassandra.apache.org/_/index
Apache Cassandra. https://cassandra.apache.org/_/index. html (accessed Mar, 2026)
work page 2026
-
[17]
https://www.mongodb.com/ (accessed Mar, 2026)
MongoDB. https://www.mongodb.com/ (accessed Mar, 2026)
work page 2026
-
[18]
A universally unique identifier (uuid) urn namespace
Paul Leach, Michael Mealling, and Rich Salz. A universally unique identifier (uuid) urn namespace. Technical report, 2005
work page 2005
-
[19]
Optimistic sorting and information theoretic complexity
Peter McIlroy. Optimistic sorting and information theoretic complexity. In Proceedings of the fourth annual ACM-SIAM Symposium on Discrete algorithms, pages 467–474, 1993
work page 1993
-
[20]
An experimental study of sorting and branch prediction
Paul Biggar, Nicholas Nash, Kevin Williams, and David Gregg. An experimental study of sorting and branch prediction. Journal of Experimental Algorithmics (JEA), 12:1–39, 2008
work page 2008
-
[21]
The influence of caches on the performance of sorting
Anthony LaMarca and Richard E Ladner. The influence of caches on the performance of sorting. Journal of Algorithms, 31(1):66–104, 1999
work page 1999
-
[22]
Spin Sort. https://github.com/boostorg/sort/blob/develop/ include/boost/sort/spinsort/spinsort.hpp (accessed Mar, 2026)
work page 2026
-
[23]
Flat Stable Sort. https://www.boost.org/doc/libs/1_68_0/ libs/sort/doc/papers/flat_stable_sort_eng.pdf (accessed Mar, 2026)
work page 2026
-
[24]
Spread Sort. https://www.boost.org/doc/libs/latest/libs/sort/ doc/html/sort/single_thread/spreadsort.html#sort.single_ thread.spreadsort.overview.intro (accessed Mar, 2026)
work page 2026
-
[25]
Intel® VTune™ Profiler. https://www.intel.com/content/ www/us/en/developer/tools/oneapi/vtune-profiler.html (accessed Mar, 2026)
work page 2026
-
[26]
A top-down method for performance analysis and counters architecture
Ahmad Yasin. A top-down method for performance analysis and counters architecture. In IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 35–44. IEEE, 2014. Hriday Jain is pursuing a Bachelor of Tech- nology (B.Tech) in Computer Science and Engineering at the School of Technology, Pan- dit Deendayal Energy Universi...
work page 2014
-
[27]
Very High- Order Solver Frameworks for Compressible Turbulent Mixing
His research focuses on biomedical signal processing, machine learning, digital health technologies, computer vision, and natural language processing. He has published extensively in reputed journals including IEEE Sensors Journal, IEEE JSAC, and IEEE Transactions on Parallel and Distributed Systems, and has contributed to several interna- tional conferen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.