Recognition: no theorem link
Intelligence Impact Quotient (IIQ): A Framework for Measuring Organizational AI Impact
Pith reviewed 2026-05-15 01:41 UTC · model grok-4.3
The pith
The Intelligence Impact Quotient combines novelty-weighted token stock with usage frequency, leverage, task complexity, and autonomy to yield comparable 0-1000 scores of AI integration depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Intelligence Impact Quotient (IIQ) is a composite metric that integrates a novelty-weighted, time-decayed token stock with usage frequency, a grace-period recency gate, organizational leverage, task complexity, and autonomy to produce both a raw Intelligence Adoption Index (IAI) and a normalized 0-1000 IIQ index, enabling comparison of AI integration depth across heterogeneous organizational contexts, together with sub-daily update rules and bounded interpretations for estimated efficiency and financial impact.
What carries the argument
The IIQ composite metric, which weights novelty-weighted and time-decayed token stock by usage frequency, organizational leverage, task complexity, and autonomy to quantify workflow integration depth.
If this is right
- Organizations gain a standardized 0-1000 scale that allows direct comparison of AI integration across units of different sizes and types.
- The metric separates frequent low-leverage prompting from autonomous, high-consequence AI-assisted work.
- Sub-daily update rules support continuous monitoring rather than periodic snapshots.
- Bounded estimates of efficiency and financial impact can be attached to the IIQ values.
- The framework is positioned for ongoing tracking of AI embedding in workflows, not as a measure of model capability.
Where Pith is reading between the lines
- Widespread use could shift organizational AI investment toward tools that raise autonomy and complexity levels rather than raw volume.
- The distinction between token quantity and weighted impact suggests that dashboards focused only on usage counts may overstate adoption quality.
- Correlation studies linking IIQ scores to measured productivity outcomes would provide an external test of the weighting choices.
- The same weighting logic could be adapted to track individual employee or team-level AI maturity trajectories over time.
Load-bearing premise
The chosen factors of novelty-weighted token stock, usage frequency, leverage, complexity, and autonomy together accurately quantify integration depth and impact without post-hoc fitting or external validation against real outcomes.
What would settle it
Longitudinal data from organizations that records actual productivity gains, cost savings, or workflow changes and shows no statistical correlation with computed IIQ scores would falsify the metric's claim to measure impact.
Figures

read the original abstract
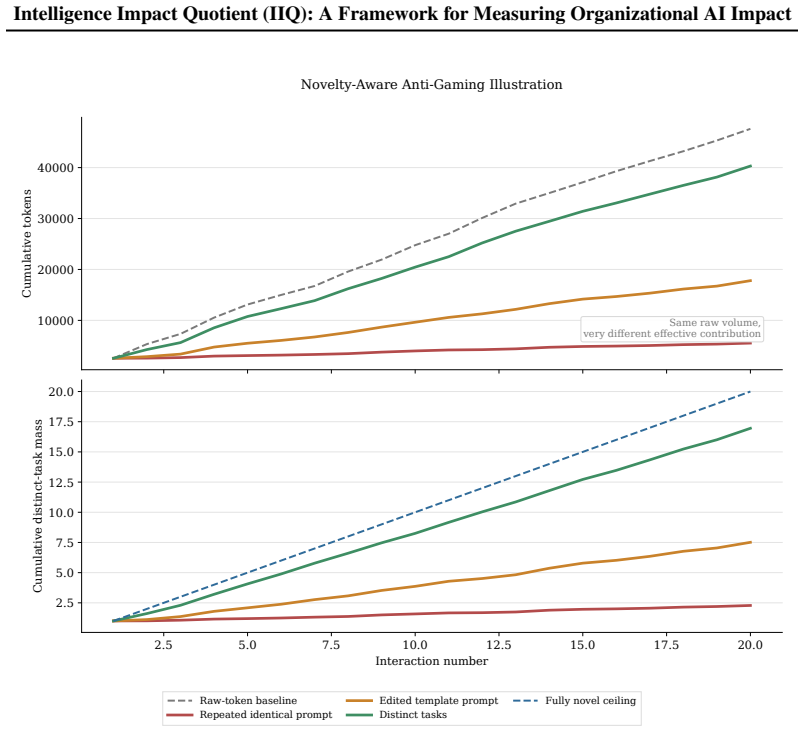
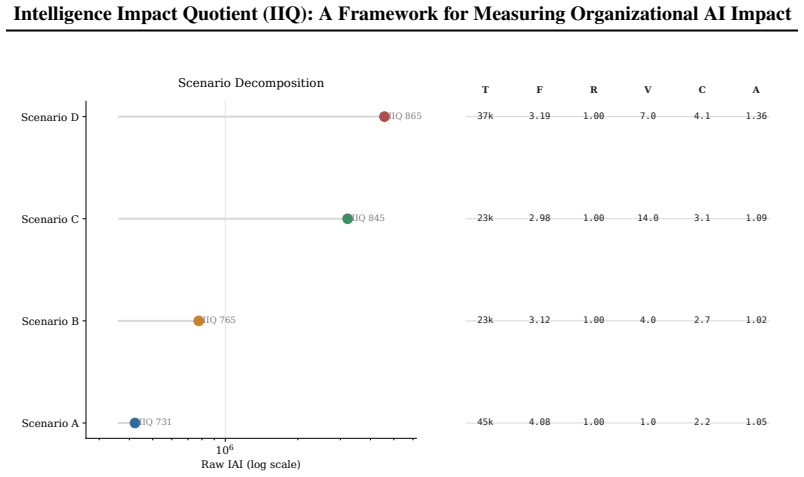
The Intelligence Impact Quotient (IIQ) is a composite metric intended to quantify the depth to which AI systems are integrated into organizational work and their impact. Rather than treating access counts or aggregate token volume as sufficient evidence of impact, IIQ combines a novelty-weighted, time-decayed token stock with usage frequency, a grace-period recency gate, organizational leverage, task complexity, and autonomy. The formulation produces a raw Intelligence Adoption Index (IAI) and a normalized 0-1000 IIQ index for comparison between heterogeneous users and units. We also derive sub-daily update rules and a bounded interpretation layer for estimated efficiency and financial impact. The paper positions IIQ as a deployment-oriented measurement framework: a formal proposal for tracking AI embedding in workflows, not a direct measure of model capability or a substitute for causal productivity evaluation. Synthetic scenarios illustrate how the revised metric distinguishes between frequent low-leverage use, semantically repetitive prompting, and more autonomous, higher-consequence AI-assisted work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Intelligence Impact Quotient (IIQ) as a composite metric to quantify the depth of AI integration into organizational workflows and its resulting impact. It defines a raw Intelligence Adoption Index (IAI) from novelty-weighted and time-decayed token stock, usage frequency, a grace-period recency gate, organizational leverage, task complexity, and autonomy; this is then normalized to a 0-1000 IIQ scale for cross-unit comparison. The manuscript also supplies sub-daily update rules and a bounded interpretation layer linking the index to estimated efficiency and financial impact. Synthetic scenarios are presented to show differentiation between low-leverage repetitive use and higher-autonomy, higher-consequence AI-assisted work. The work is framed explicitly as a deployment-oriented measurement framework rather than a validated causal instrument or model-capability benchmark.
Significance. If the chosen factors and functional form can be shown to correlate with observable productivity or outcome measures, IIQ could supply a practical, comparable index for tracking AI embedding that goes beyond raw token counts or access logs. The explicit sub-daily update rules and bounded interpretation layer are concrete engineering contributions that could be implemented directly in monitoring systems. At present, however, the absence of any empirical calibration or external validation leaves the metric as an untested modeling choice whose practical value cannot yet be assessed.
major comments (3)
- [Abstract / §3] Abstract and the central formulation (presumably §3): the IAI is defined directly as a linear or weighted combination of novelty-weighted token stock, usage frequency, leverage, complexity, and autonomy with no derivation, sensitivity analysis, or external benchmark supplied for the specific functional form or component weights. The claim that this combination 'quantifies integration depth and impact' therefore rests on definitional choice rather than demonstrated support.
- [§5] Synthetic scenarios section (presumably §5): the illustrative cases distinguish usage patterns only within the authors' own synthetic data; no regression against real productivity outcomes, error analysis, or hold-out validation is reported, so the scenarios cannot establish that IIQ tracks actual organizational impact.
- [Interpretation layer] Interpretation layer: the bounded mapping from IIQ to estimated efficiency and financial impact is presented without any grounding data or uncertainty quantification, making the downstream claims load-bearing yet unsupported.
minor comments (2)
- [Notation] Notation for the time-decay and grace-period parameters is introduced without an explicit table of symbols or default values, which would aid reproducibility.
- [Normalization] The normalization step from raw IAI to the 0-1000 IIQ scale is described at a high level; an explicit equation or pseudocode would clarify the exact scaling.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for noting the potential utility of the sub-daily update rules and bounded interpretation layer. The paper presents IIQ as a proposed framework for measuring organizational AI impact, explicitly not as a validated causal model. Below we respond point-by-point to the major comments, clarifying the definitional nature of the metric and committing to revisions that strengthen the manuscript's transparency regarding its scope and limitations.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and the central formulation (presumably §3): the IAI is defined directly as a linear or weighted combination of novelty-weighted token stock, usage frequency, leverage, complexity, and autonomy with no derivation, sensitivity analysis, or external benchmark supplied for the specific functional form or component weights. The claim that this combination 'quantifies integration depth and impact' therefore rests on definitional choice rather than demonstrated support.
Authors: We agree that the functional form is a definitional choice without derivation from data or sensitivity analysis. The manuscript frames this as a practical framework for deployment monitoring, where the components (novelty-weighted token stock, frequency, leverage, complexity, autonomy) are selected based on their relevance to integration depth. No external benchmark is supplied because the work does not claim to be a predictive model. We will add a new subsection in §3 explaining the rationale for the chosen form and weights, and include a limitations statement noting the lack of sensitivity analysis. revision: partial
-
Referee: [§5] Synthetic scenarios section (presumably §5): the illustrative cases distinguish usage patterns only within the authors' own synthetic data; no regression against real productivity outcomes, error analysis, or hold-out validation is reported, so the scenarios cannot establish that IIQ tracks actual organizational impact.
Authors: The synthetic scenarios are meant to illustrate the metric's behavior across different usage patterns within a controlled setting, not to validate its correlation with real impact. The paper states upfront that it is a measurement framework proposal and not a substitute for causal evaluation. We will revise §5 to explicitly describe the scenarios as illustrative and add text in the discussion section highlighting that empirical validation against productivity data is required in future work. revision: partial
-
Referee: [Interpretation layer] Interpretation layer: the bounded mapping from IIQ to estimated efficiency and financial impact is presented without any grounding data or uncertainty quantification, making the downstream claims load-bearing yet unsupported.
Authors: We accept that the interpretation layer lacks grounding data and uncertainty quantification. The mappings are provided as bounded, illustrative examples to aid interpretation rather than as data-driven estimates. In revision, we will qualify these claims more explicitly, add statements on the hypothetical nature of the efficiency and financial links, and include a note on the need for uncertainty quantification in applied use. revision: yes
Circularity Check
IIQ reduces to its definitional composite of author-chosen factors with no independent derivation shown
specific steps
-
self definitional
[Abstract]
"IIQ combines a novelty-weighted, time-decayed token stock with usage frequency, a grace-period recency gate, organizational leverage, task complexity, and autonomy. The formulation produces a raw Intelligence Adoption Index (IAI) and a normalized 0-1000 IIQ index for comparison between heterogeneous users and units."
The paper claims this combination quantifies depth of integration and impact, yet the IIQ value is computed directly from the listed inputs via the authors' chosen functional form. The output index is therefore identical to the definitional inputs by construction, with no separate derivation or benchmark establishing that these factors measure impact independently.
full rationale
The paper's central claim is that IIQ quantifies organizational AI impact via a specific combination of factors into IAI then normalized to 0-1000. This is presented as a formulation that produces the index, but the text supplies only the definitional equations and synthetic illustrations. No regression against outcomes, external validation, or first-principles derivation is exhibited, so the measure is equivalent to its input selection and weighting by construction. This matches self-definitional circularity at the core of the framework.
Axiom & Free-Parameter Ledger
free parameters (2)
- component weights
- time decay rate
axioms (1)
- domain assumption Novelty-weighted token usage combined with leverage and autonomy accurately reflects organizational AI impact depth
invented entities (2)
-
Intelligence Impact Quotient (IIQ)
no independent evidence
-
Intelligence Adoption Index (IAI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anthropic Economic Research. 2026. Anthropic Economic Index: New building blocks for understanding AI use. https://www.anthropic.com/research/economic-index-primitives
2026
-
[2]
Anthropic Economic Research. 2025. Anthropic Economic Index: AI's impact on software development. https://www.anthropic.com/research/impact-software-development
2025
-
[3]
Miles McCain et al. 2026. Measuring AI agent autonomy in practice. Anthropic. https://www.anthropic.com/research/measuring-agent-autonomy
2026
- [4]
-
[5]
Thomas Kwa, Ben West, Joel Becker, et al. 2025. Measuring AI Ability to Complete Long Tasks. METR. https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
2025
-
[6]
Siegel, Nitya Nadgir, and Arvind Narayanan
Sayash Kapoor, Benedikt Stroebl, Zachary S. Siegel, Nitya Nadgir, and Arvind Narayanan. 2024. AI Agents That Matter. arXiv preprint arXiv:2407.01502. https://arxiv.org/abs/2407.01502
-
[7]
Anders Humlum and Emilie Vestergaard. 2025. Still Waters, Rapid Currents: Early Labor Market Transformation under Generative AI. National Bureau of Economic Research Working Paper 33777. https://doi.org/10.3386/w33777
-
[8]
Lu Fang, Zhe Yuan, Kaifu Zhang, Dante Donati, and Miklos Sarvary. 2025. Generative AI and Firm Productivity: Field Experiments in Online Retail. arXiv preprint arXiv:2510.12049. https://doi.org/10.48550/arXiv.2510.12049
-
[9]
Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Sim \'o n Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, Natalie S. Kim, Patrick Chao, Samuel Miserendino, Gildas Chabot, David Li, Michael Sharman, Alexandra Barr, Amelia Glaese, and Jerry Tworek. 2025. GDPval: Evaluating AI Model Performance on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.