Recognition: no theorem link
OmniDrop: Layer-wise Token Pruning for Omni-modal LLMs via Query-Guidance
Pith reviewed 2026-05-15 01:32 UTC · model grok-4.3
The pith
Layer-wise token pruning inside the LLM decoder, guided by text queries, allows omni-modal models to process audiovisual inputs faster while maintaining or improving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniDrop is a training-free framework that progressively prunes audiovisual tokens within the LLM decoder layers instead of at the input level, using text queries for modality-agnostic guidance and a temporal diversity score to preserve context, resulting in improved performance and efficiency on multimodal tasks.
What carries the argument
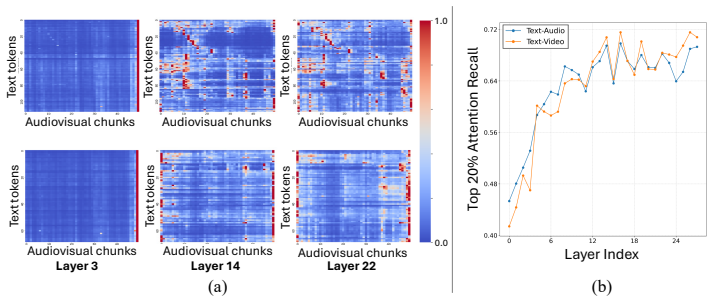
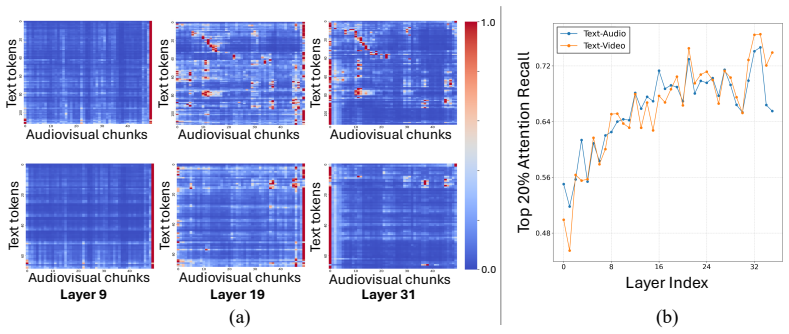
Layer-wise token pruning mechanism that uses query-guided attention scores to select tokens after early fusion, combined with a temporal diversity score for balanced retention.
If this is right
- Omni-modal LLMs can handle longer audiovisual inputs in real time.
- Prefill latency decreases by up to 40 percent across benchmarks.
- Memory usage drops by up to 14.7 percent.
- Accuracy improves by up to 3.58 points over existing pruning methods.
- Task-adaptive pruning works without retraining the model.
Where Pith is reading between the lines
- Early-layer fusion before pruning may be more effective than input-level methods for preserving cross-modal semantics.
- Query guidance could extend to other pruning strategies in multimodal models.
- Testing on tasks with conflicting text queries might reveal limits of the guidance approach.
Load-bearing premise
Text queries provide reliable guidance for identifying which audiovisual tokens are semantically important at different layers.
What would settle it
Measuring performance drop when text queries are deliberately mismatched to the audiovisual content on the same benchmarks.
Figures



read the original abstract
Omni-modal large language models have demonstrated remarkable potential in holistic multimodal understanding; however, the token explosion caused by high-resolution audio and video inputs remains a critical bottleneck for real-time applications and long-form reasoning. Existing omni-modal token compression methods typically prune tokens at the input embedding level, relying on audio-video similarity or temporal co-occurrence as proxies for semantic relevance. In practice, such assumptions are often unreliable. To address this limitation, we propose OmniDrop, a training-free, layer-wise token pruning framework that progressively prunes audiovisual tokens within the LLM decoder layers rather than at the input-level, allowing early layers to preserve sufficient omni-modal information fusion before aggressively removing tokens in deeper layers. We further utilize text queries as guidance for modality-agnostic and task-adaptive token pruning. We also introduce a temporal diversity score that encourages balanced token survival to preserve global temporal context. Experimental results across various audiovisual benchmarks demonstrate that OmniDrop outperforms all baselines by up to 3.58 points while reducing prefill latency by up to 40% and memory usage by up to 14.7%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniDrop, a training-free layer-wise token pruning framework for omni-modal LLMs. It performs progressive pruning of audiovisual tokens inside the decoder layers (after early cross-modal fusion) rather than at the input embedding stage, using text queries for modality-agnostic guidance and adding a temporal diversity score to maintain global context. The central claim is that this yields up to 3.58-point gains over baselines on audiovisual benchmarks while cutting prefill latency by up to 40% and memory by up to 14.7%.
Significance. If the experimental claims hold under rigorous validation, the work would be significant for efficient inference in long-context multimodal models, as a training-free, query-adaptive pruning strategy that exploits internal layer-wise fusion could reduce the token explosion problem without task-specific retraining.
major comments (2)
- [Abstract] Abstract: the performance numbers (3.58-point gains, 40% latency reduction, 14.7% memory reduction) are presented without any description of the exact benchmarks, baseline implementations, number of runs, or statistical tests. Because these numbers are the primary evidence for the central claim that query-guided layer-wise pruning outperforms prior input-level methods, the absence of this information is load-bearing.
- [Method] Method section (description of query-guided scoring): the manuscript states that text queries guide modality-agnostic pruning and introduces a temporal diversity term, yet provides neither the explicit formula for projecting query embeddings into per-layer token importance scores nor pseudocode showing how this score is combined with attention maps. Without this, it is impossible to verify whether the pruning criterion systematically discards query-independent but semantically relevant audiovisual structure, which is the weakest assumption identified in the approach.
minor comments (1)
- [Abstract] The abstract and introduction repeatedly use the phrase 'modality-agnostic and task-adaptive' without clarifying whether this is a design property or an empirical observation; a short clarifying sentence would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point-by-point below, indicating the revisions we will make to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance numbers (3.58-point gains, 40% latency reduction, 14.7% memory reduction) are presented without any description of the exact benchmarks, baseline implementations, number of runs, or statistical tests. Because these numbers are the primary evidence for the central claim that query-guided layer-wise pruning outperforms prior input-level methods, the absence of this information is load-bearing.
Authors: We agree that the abstract would be strengthened by additional context on the experimental setup. In the revised version, we will expand the abstract to name the specific audiovisual benchmarks, note that the gains are measured against input-level pruning baselines, and state that results are averaged over multiple runs (with full details, including standard deviations and significance tests, provided in Section 4). Given abstract length constraints, we will add a concise qualifier rather than exhaustive statistics. revision: partial
-
Referee: [Method] Method section (description of query-guided scoring): the manuscript states that text queries guide modality-agnostic pruning and introduces a temporal diversity term, yet provides neither the explicit formula for projecting query embeddings into per-layer token importance scores nor pseudocode showing how this score is combined with attention maps. Without this, it is impossible to verify whether the pruning criterion systematically discards query-independent but semantically relevant audiovisual structure, which is the weakest assumption identified in the approach.
Authors: We acknowledge that the current method description is high-level and would benefit from greater mathematical precision. In the revised manuscript, we will add the explicit formula for the query-guided per-layer importance scoring (including how the text query embedding is projected and combined with attention maps) as well as the temporal diversity term. We will also include pseudocode for the full layer-wise pruning procedure to enable verification that the criterion preserves semantically relevant structure. revision: yes
Circularity Check
No significant circularity in the proposed pruning framework
full rationale
The paper presents OmniDrop as a training-free procedural framework for layer-wise token pruning guided by text queries and a temporal diversity score. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the method's own inputs. The central claims rely on external benchmark validation rather than self-citations, self-definitions, or renamed empirical patterns. The derivation chain is self-contained as a set of algorithmic choices with independent experimental support.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Text queries provide reliable, modality-agnostic guidance for identifying semantically relevant audiovisual tokens.
- domain assumption Progressive pruning after initial cross-modal fusion in early layers preserves sufficient information for downstream performance.
Reference graph
Works this paper leans on
-
[1]
Divprune: Diversity-based visual token pruning for large multimodal models, 2025
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models, 2025
2025
-
[2]
Token merging: Your vit but faster, 2023
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster, 2023
2023
-
[3]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models, 2024
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models, 2024
2024
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024
2024
-
[6]
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Danial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Arushi Goel, et al. Nemotron 3 nano omni: Efficient and open multimodal intelligence.arXiv preprint arXiv:2604.24954, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models, 2026
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, Yuanxing Zhang, Jiaheng Liu, Qiang Liu, Pengfei Wan, and Liang Wang. Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models, 2026
2026
-
[8]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis, 2025
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis, 2025
2025
-
[9]
Vita-1.5: Towards gpt-4o level real-time vision and speech interaction, 2025
Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Haoyu Cao, Zuwei Long, Heting Gao, Ke Li, Long Ma, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, and Ran He. Vita-1.5: Towards gpt-4o level real-time vision and speech interaction, 2025
2025
-
[10]
Arc-hunyuan-video-7b: Structured video comprehension of real-world shorts, 2025
Yuying Ge, Yixiao Ge, Chen Li, Teng Wang, Junfu Pu, Yizhuo Li, Lu Qiu, Jin Ma, Lisheng Duan, Xinyu Zuo, Jinwen Luo, Weibo Gu, Zexuan Li, Xiaojing Zhang, Yangyu Tao, Han Hu, Di Wang, and Ying Shan. Arc-hunyuan-video-7b: Structured video comprehension of real-world shorts, 2025
2025
-
[11]
Echoingpixels: Cross-modal adaptive token reduction for efficient audio-visual llms, 2025
Chao Gong, Depeng Wang, Zhipeng Wei, Ya Guo, Huijia Zhu, and Jingjing Chen. Echoingpixels: Cross-modal adaptive token reduction for efficient audio-visual llms, 2025
2025
-
[12]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, June 2022
2022
-
[13]
Worldsense: Evaluating real-world omnimodal understanding for multimodal llms, 2026
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms, 2026
2026
-
[14]
Masked autoencoders that listen
Po-Yao Huang, Hu Xu, Juncheng Li, Alexei Baevski, Michael Auli, Wojciech Galuba, Florian Metze, and Christoph Feichtenhofer. Masked autoencoders that listen. In S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 28708–28720. Curran Associates, Inc., 2022
2022
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, YUCHENG LI, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. MInference 1.0: Accelerating pre-filling for long-context LLMs via dynamic sparse attention. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[17]
FastKV: Decoupling of Context Reduction and KV Cache Compression for Prefill-Decoding Acceleration
Dongwon Jo, Jiwon Song, Yulhwa Kim, and Jae-Joon Kim. Fastkv: Kv cache compression for fast long-context processing with token-selective propagation.arXiv preprint arXiv:2502.01068, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Dash: Dynamic audio-driven semantic chunking for efficient omnimodal token compression, 2026
Bingzhou Li and Tao Huang. Dash: Dynamic audio-driven semantic chunking for efficient omnimodal token compression, 2026
2026
-
[19]
Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025
Yadong Li, Jun Liu, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, et al. Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025
-
[20]
Agent- omni: Test-time multimodal reasoning via model coordination for understanding anything, 2025
Huawei Lin, Yunzhi Shi, Tong Geng, Weijie Zhao, Wei Wang, and Ravender Pal Singh. Agent- omni: Test-time multimodal reasoning via model coordination for understanding anything, 2025
2025
-
[21]
Speechprune: Context-aware token pruning for speech information retrieval, 2025
Yueqian Lin, Yuzhe Fu, Jingyang Zhang, Yudong Liu, Jianyi Zhang, Jingwei Sun, Hai "Helen" Li, and Yiran Chen. Speechprune: Context-aware token pruning for speech information retrieval, 2025
2025
-
[22]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024
2024
-
[23]
Active perception agent for omnimodal audio-video understanding, 2026
Keda Tao, Wenjie Du, Bohan Yu, Weiqiang Wang, Jian Liu, and Huan Wang. Active perception agent for omnimodal audio-video understanding, 2026
2026
-
[24]
Dycoke: Dynamic compression of tokens for fast video large language models, 2025
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models, 2025
2025
-
[25]
Efficient transformers: A survey
Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. ACM Computing Surveys, 55(6):1–28, 2022
2022
-
[26]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[27]
Omniagent: Long-video generation via cross-modal multi- agent orchestration, 2025
Zheng WEI, Mingchen Li, Zeqian Zhang, Ruibin Yuan, Pan Hui, Huamin Qu, James Evans, Maneesh Agrawala, and Anyi Rao. Omniagent: Long-video generation via cross-modal multi- agent orchestration, 2025
2025
-
[28]
Qwen2.5-omni technical report, 2025
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025
2025
-
[29]
Audio-centric video understanding benchmark without text shortcut, 2025
Yudong Yang, Jimin Zhuang, Guangzhi Sun, Changli Tang, Yixuan Li, Peihan Li, Yifan Jiang, Wei Li, Zejun Ma, and Chao Zhang. Audio-centric video understanding benchmark without text shortcut, 2025
2025
-
[30]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Who said in the video that ‘... ’?
Yan Zhao, Zhengxue Cheng, Junxuan Zhang, Dajiang Zhou, Qunshan Gu, Qi Wang, and Li Song. Omnizip: Learning a unified and lightweight lossless compressor for multi-modal data.arXiv preprint arXiv:2602.22286, 2026. 12 Appendices A Additional experimental details We follow the preprocessing settings of OmniZip [ 31] and DASH [ 18]. To handle the longer video...
-
[32]
Phase 1 (Preservation): Sincep init = 0, the mean retained ratio is constant:¯rphase1 =r 0 = 0.45
-
[33]
Phase 2 (Aggressive compression): To satisfy ¯R= 0.30, the required mean retained ratio for Phase 2 is: ¯rphase2 = 2 ¯R−¯rphase1 = 2(0.30)−0.45 = 0.15 Using a linear approximation of the geometric decay and Taylor expansion, the mean retained ratio of Phase 2 corresponds approximately to the ratio at midpoint of the Phase 2 (i.e.Layer 21, the 7-th layer i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.