Recognition: 2 theorem links
· Lean TheoremKAP-CPD: Kernel Aggregation for Change-Point Detection in Dynamic Networks
Pith reviewed 2026-05-15 01:53 UTC · model grok-4.3
The pith
Aggregating multiple kernels allows change-point detection in dynamic networks to work across unknown change patterns without distributional assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
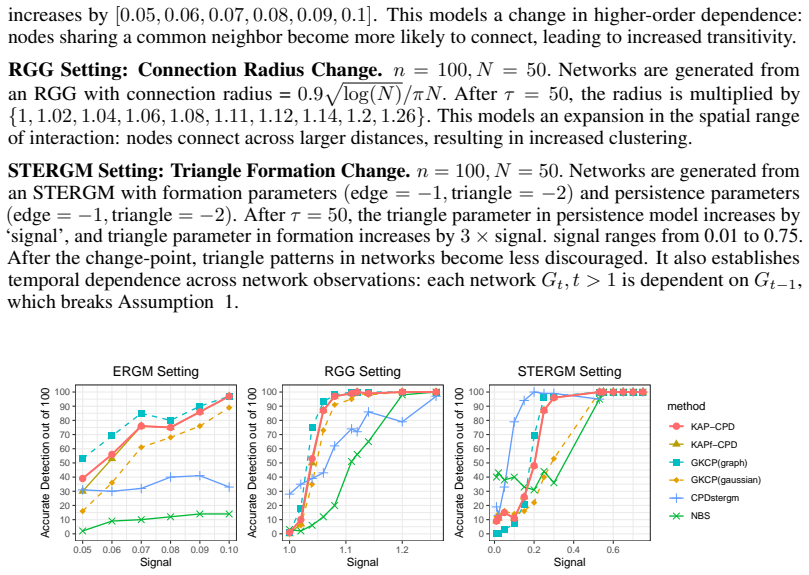
KAP-CPD aggregates information from multiple kernels to test for change points in sequences of dynamic networks. Unlike single-kernel approaches whose power drops when the kernel mismatches the actual change, the aggregated statistic retains sensitivity to diverse patterns such as edge probability shifts or structural breaks. The procedure requires no parametric assumptions on the network generating process and is evaluated on both simulated networks and real sequences from communication and functional connectivity data. An analytic fast variant called KAPf-CPD is developed to reduce computation time for long time series.
What carries the argument
The aggregation of change-point statistics computed from a collection of base kernels, which produces a combined test statistic that adapts to whichever kernel best matches the unknown change.
If this is right
- The test applies to many different network change types without requiring the analyst to guess the right kernel in advance.
- Detection power remains high even when the true change does not align with any single kernel.
- The analytic procedure scales the method to long sequences of networks where permutation testing becomes impractical.
- The same framework can be used on empirical data from social or biological networks with little parameter tuning.
Where Pith is reading between the lines
- Similar aggregation ideas could be tested in other nonparametric problems where the best kernel or bandwidth is uncertain.
- Data-driven weighting of the kernels, rather than equal aggregation, might further improve power in some settings.
- The approach could support online monitoring of streaming network data if the aggregation is made sequential.
Load-bearing premise
The chosen collection of kernels must include at least some members that respond strongly to whatever change pattern is actually present.
What would settle it
A simulation in which every kernel in the collection has near-zero power against a deliberately chosen network change, so that the aggregated test also shows no better than chance detection rates.
Figures


read the original abstract
Change-point detection in dynamic networks has received much attention due to its broad applications in social networks and biological systems. Kernel-based methods have shown strong potential for this problem. However, their performance can depend sensitively on the choice of kernel, and selecting an appropriate kernel is challenging when the underlying change pattern is unknown. Motivated by this challenge, we propose KAP-CPD, a new kernel-based testing framework for change-point detection in dynamic networks. KAP-CPD aggregates information from multiple kernels, allowing it to adapt to diverse change patterns. The proposed method does not assume specific underlying network distribution, and achieves strong empirical power across a wide range of network change scenarios. To improve scalability, we further develop a fast analytic testing procedure, KAPf-CPD, that substantially reduces computation time for long network sequences compared with permutation-based alternatives and current state-of-the-art methods. We evaluate our proposed framework through extensive simulations and real-world data on email communication networks and brain functional connectivity networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KAP-CPD, a kernel-based testing framework for change-point detection in dynamic networks that aggregates statistics from multiple kernels to adapt to unknown change patterns without assuming a specific network distribution. It further develops KAPf-CPD, a fast analytic procedure that reduces computation time relative to permutation tests. The method is evaluated via simulations across various network change scenarios and applied to real data on email communication networks and brain functional connectivity networks, with claims of strong empirical power and improved scalability.
Significance. If the aggregation step reliably retains power when individual kernels are misspecified, the work would address a practical limitation of kernel methods in network CPD and offer a distribution-free alternative suitable for social and biological applications. The scalability improvement in KAPf-CPD is a clear practical strength, and the breadth of simulation scenarios plus real-data examples provide useful empirical grounding. However, the absence of theoretical support for the aggregation limits the strength of the significance claim.
major comments (3)
- [Method section] The central aggregation procedure (described in the method section following the abstract) lacks any derivation of the null distribution or consistency result for the aggregated statistic. The abstract asserts a 'distribution-free property,' yet no analytic justification or asymptotic analysis is supplied to support this beyond the fast analytic approximation in KAPf-CPD.
- [Simulation studies] No minimax or worst-case power bound is given for the fixed kernel collection. The claim that aggregation 'adapts to diverse change patterns' therefore rests entirely on the finite simulation menu; if the true change lies outside the span of the chosen kernels (e.g., higher-order subgraph shifts), the procedure cannot recover power that each kernel individually lacks.
- [Simulation studies] The simulation design does not include explicit stress tests where all selected kernels are individually under-powered. Without such cases, the reported 'strong empirical power across a wide range' does not directly address the weakest assumption identified in the skeptic note.
minor comments (2)
- [Abstract] The abstract and method description should explicitly list the kernel families employed in the aggregation; this detail is needed to interpret both the simulation results and the real-data applications.
- [Figures] Figure captions for the simulation results should report the number of Monte Carlo replications and any error-bar construction method so that the claimed power advantages can be assessed for statistical significance.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript arXiv:2605.14463. We address each of the major comments below and outline the revisions we intend to make to strengthen the paper.
read point-by-point responses
-
Referee: [Method section] The central aggregation procedure (described in the method section following the abstract) lacks any derivation of the null distribution or consistency result for the aggregated statistic. The abstract asserts a 'distribution-free property,' yet no analytic justification or asymptotic analysis is supplied to support this beyond the fast analytic approximation in KAPf-CPD.
Authors: The 'distribution-free' property in the abstract refers to the absence of assumptions on the specific form of the network distribution (e.g., no parametric model such as stochastic block model is imposed). The testing procedure relies on a permutation-based approach for the aggregated statistic, which is valid under mild exchangeability conditions without requiring knowledge of the null distribution. For KAPf-CPD, the fast analytic procedure approximates this permutation distribution. We agree that a detailed derivation or asymptotic analysis for the aggregated statistic is not provided in the current manuscript. In the revised version, we will expand the method section to include a justification for the validity of the permutation test applied to the aggregated statistic and explicitly note the lack of asymptotic consistency results as a limitation of the current theoretical analysis. revision: partial
-
Referee: [Simulation studies] No minimax or worst-case power bound is given for the fixed kernel collection. The claim that aggregation 'adapts to diverse change patterns' therefore rests entirely on the finite simulation menu; if the true change lies outside the span of the chosen kernels (e.g., higher-order subgraph shifts), the procedure cannot recover power that each kernel individually lacks.
Authors: We concur that the adaptation property is demonstrated empirically through simulations rather than through theoretical minimax bounds. The kernel collection was selected to capture common change patterns in dynamic networks, such as shifts in edge density, community structure, and degree distributions. To address this concern, we will augment the simulation studies with additional scenarios involving higher-order subgraph changes and provide a discussion on the potential limitations when the change pattern falls outside the kernel span. However, deriving minimax bounds for the aggregated procedure is a substantial theoretical undertaking that lies beyond the scope of this work, which prioritizes the development and empirical validation of the practical method. revision: partial
-
Referee: [Simulation studies] The simulation design does not include explicit stress tests where all selected kernels are individually under-powered. Without such cases, the reported 'strong empirical power across a wide range' does not directly address the weakest assumption identified in the skeptic note.
Authors: We will incorporate new simulation experiments that explicitly test scenarios where each individual kernel has low power, to evaluate the performance of the aggregation procedure in these challenging cases. This addition will provide direct evidence regarding the robustness of KAP-CPD when the change pattern is not well-captured by any single kernel. revision: yes
- Providing a formal derivation of the null distribution or asymptotic consistency results for the aggregated statistic
- Establishing minimax or worst-case power bounds for the fixed kernel collection
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description introduce KAP-CPD as a novel aggregation of multiple kernels for change-point detection without distributional assumptions. No equations, fitted parameters, or derivation steps are shown that reduce by construction to inputs (e.g., no self-definitional quantities, no fitted inputs renamed as predictions, no load-bearing self-citations or ansatzes). The central claim rests on empirical power across scenarios rather than a closed tautological loop, making the chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Kernels are positive definite and can encode network similarity or difference information
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KAP-CPD aggregates information from multiple kernels... S(t) = [a(t)−Ea(t)]T Σ(t)−1 [a(t)−Ea(t)]... decomposition into ZWDiff, ZDDiff, ZWSum, ZDSum
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the scan statistic S∗=maxt S(t)... permutation procedure under Assumption 1 (exchangeability)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yuxuan Zhou, Shang Gao, Dandan Guo, Xiaohui Wei, Jon Rokne, and Hui Wang. A survey of change point detection in dynamic graphs.IEEE Transactions on Knowledge and Data Engineering, 37(3):1030–1048, 2025. doi: 10.1109/TKDE.2024.3523857
-
[2]
Bernhardt, Sara Larivière, Ezequiel Gleichgerrcht, Bernd J
Jessica Royer, Boris C. Bernhardt, Sara Larivière, Ezequiel Gleichgerrcht, Bernd J. V orderwül- becke, Serge Vulliémoz, and Leonardo Bonilha. Epilepsy and brain network hubs.Epilepsia, 63(3):537–550, March 2022. ISSN 1528-1167 0013-9580. doi: 10.1111/epi.17171. Place: United States. 9
-
[3]
Timo Bröhl, Thorsten Rings, Jan Pukropski, Randi von Wrede, and Klaus Lehnertz. The time-evolving epileptic brain network: concepts, definitions, accomplishments, perspec- tives.Frontiers in Network Physiology, V olume 3 - 2023, 2024. ISSN 2674-0109. doi: 10.3389/fnetp.2023.1338864. URL https://www.frontiersin.org/journals/ network-physiology/articles/10....
-
[4]
Ivor Cribben and Yi Yu. Estimating whole-brain dynamics by using spectral clustering.Journal of the Royal Statistical Society Series C: Applied Statistics, 66(3):607–627, 09 2016. ISSN 0035-9254. doi: 10.1111/rssc.12169. URL https://doi.org/10.1111/rssc.12169
-
[5]
Fangli Dong, Yong He, Tao Wang, Dong Han, Hui Lu, and Hongyu Zhao. Predicting viral exposure response from modeling the changes of co-expression networks using time series gene expression data.BMC Bioinformatics, 21(1):370, August 2020. ISSN 1471-2105. doi: 10.1186/ s12859-020-03705-0. URLhttps://doi.org/10.1186/s12859-020-03705-0
-
[6]
Upenn and mayo clinic’s seizure detection challenge
bbrinkm, sbaldassano, and Will Cukierski. Upenn and mayo clinic’s seizure detection challenge. https://kaggle.com/competitions/seizure-detection, 2014. Kaggle
work page 2014
-
[7]
Monika Bhattacharjee, Moulinath Banerjee, and George Michailidis. Change point estimation in a dynamic stochastic block model.Journal of Machine Learning Research, 21(107):1–59,
-
[8]
URLhttp://jmlr.org/papers/v21/18-814.html
-
[9]
Daren Wang, Yi Yu, and Alessandro Rinaldo. Optimal change point detection and localization in sparse dynamic networks.The Annals of Statistics, 49(1):203 – 232, 2021
work page 2021
-
[10]
Shankar Bhamidi, Jimmy Jin, and Andrew Nobel. Change point detection in network models: Preferential attachment and long range dependence.The Annals of Applied Probability, 28 (1):35 – 78, 2018. doi: 10.1214/17-AAP1297. URL https://doi.org/10.1214/ 17-AAP1297
-
[11]
Daniel Cirkovic, Tiandong Wang, and Xianyang Zhang. Likelihood-based inference for random networks with changepoints.IEEE Transactions on Network Science and Engineering, 13: 344–359, 2026. doi: 10.1109/TNSE.2025.3583550
-
[12]
Change point detection on a separable model for dynamic networks, 2025
Yik Lun Kei, Hangjian Li, Yanzhen Chen, and Oscar Hernan Madrid Padilla. Change point detection on a separable model for dynamic networks, 2025. URL https://arxiv.org/ abs/2303.17642
-
[13]
Laplacian change point detection for single and multi-view dynamic graphs.ACM Trans
Shenyang Huang, Samy Coulombe, Yasmeen Hitti, Reihaneh Rabbany, and Guillaume Rabusseau. Laplacian change point detection for single and multi-view dynamic graphs.ACM Trans. Knowl. Discov. Data, 18(3), January 2024. ISSN 1556-4681. doi: 10.1145/3631609. URLhttps://doi.org/10.1145/3631609
-
[14]
Hoseung Song and Hao Chen. Practical and powerful kernel-based change-point detection.IEEE Transactions on Signal Processing, 72:5174–5186, 2024. doi: 10.1109/TSP.2024.3479274
-
[15]
Fréchet change point detection.The Annals of Statistics, 48(6):3312 – 3335, 2020
Paromita Dubey and Hans-Georg Müller. Fréchet change point detection.The Annals of Statistics, 48(6):3312 – 3335, 2020
work page 2020
-
[16]
Doudou Zhou and Hao Chen. Asymptotic distribution-free change-point detection for modern data based on a new ranking scheme.IEEE Transactions on Information Theory, 71(8):6183– 6197, 2025. doi: 10.1109/TIT.2025.3575858
-
[17]
Graph-based change-point detection.The Annals of Statistics, 43(1):139 – 176, 2015
Hao Chen and Nancy Zhang. Graph-based change-point detection.The Annals of Statistics, 43(1):139 – 176, 2015. doi: 10.1214/14-AOS1269. URL https://doi.org/10.1214/ 14-AOS1269
-
[18]
Lynna Chu and Hao Chen. Asymptotic distribution-free change-point detection for multivariate and non-Euclidean data.The Annals of Statistics, 47(1):382 – 414, 2019. doi: 10.1214/ 18-AOS1691. URLhttps://doi.org/10.1214/18-AOS1691
-
[19]
Hoseung Song and Hao Chen. Asymptotic distribution-free changepoint detection for data with repeated observations.Biometrika, 109(3):783–798, 09 2022. ISSN 1464-3510. doi: 10.1093/biomet/asab048. URLhttps://doi.org/10.1093/biomet/asab048. 10
-
[20]
Deborah Sulem, Henry Kenlay, Mihai Cucuringu, and Xiaowen Dong. Graph similarity learning for change-point detection in dynamic networks.Machine Learning, 113:1–44, 2023. ISSN 1053-8119. doi: https://doi.org/10.1016/j.neuroimage.2021.117791. URL https: //doi.org/10.1007/s10994-023-06405-x
-
[21]
Xinxun Zhang, Pengfei Jiao, Mengzhou Gao, Tianpeng Li, Yiming Wu, Huaming Wu, and Zhidong Zhao. Vggm: Variational graph gaussian mixture model for unsupervised change point detection in dynamic networks.IEEE Transactions on Information Forensics and Security, 19: 4272–4284, 2024. doi: 10.1109/TIFS.2024.3377548
-
[22]
Change point detection in dynamic graphs with decoder-only latent space model
Yik Lun Kei, Jialiang Li, Hangjian Li, Yanzhen Chen, and OSCAR HERNAN MADRID PADILLA. Change point detection in dynamic graphs with decoder-only latent space model. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https:// openreview.net/forum?id=DVeFqV56Iz
work page 2025
-
[23]
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.Journal of Machine Learning Research, 13(25):723–773,
-
[24]
URLhttp://jmlr.org/papers/v13/gretton12a.html
-
[25]
Sylvain Arlot, Alain Celisse, and Zaid Harchaoui. A kernel multiple change-point algorithm via model selection.Journal of Machine Learning Research, 20(162):1–56, 2019. URL http://jmlr.org/papers/v20/16-155.html
work page 2019
-
[26]
Anirban Chatterjee and Bhaswar B. Bhattacharya. Boosting the power of kernel two-sample tests.Biometrika, 2023. URL https://api.semanticscholar.org/CorpusID: 257050555
work page 2023
-
[27]
MMD-fuse: Learning and combining kernels for two-sample testing without data splitting
Felix Biggs, Antonin Schrab, and Arthur Gretton. MMD-fuse: Learning and combining kernels for two-sample testing without data splitting. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id= JOkgEY9os2
work page 2023
-
[28]
Zhijian Zhou, Xunye Tian, Liuhua Peng, Chao Lei, Antonin Schrab, Danica J. Sutherland, and Feng Liu. DUAL: Learning diverse kernels for aggregated two-sample and independence testing. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[29]
URLhttps://openreview.net/forum?id=CVekdZDzLG
-
[30]
Multiple kernel learning algorithms.Journal of Machine Learning Research, 12(64):2211–2268, 2011
Mehmet Gönen and Ethem Alpaydin. Multiple kernel learning algorithms.Journal of Machine Learning Research, 12(64):2211–2268, 2011. URL http://jmlr.org/papers/v12/ gonen11a.html
work page 2011
-
[31]
Network representation learning: A survey.IEEE Transactions on Big Data, PP, 12 2017
Zhang Daokun, Jie Yin, Xingquan Zhu, and Chengqi Zhang. Network representation learning: A survey.IEEE Transactions on Big Data, PP, 12 2017. doi: 10.1109/TBDATA.2018.2850013
-
[32]
Efficient graphlet kernels for large graph comparison
Nino Shervashidze, SVN Vishwanathan, Tobias Petri, Kurt Mehlhorn, and Karsten Borgwardt. Efficient graphlet kernels for large graph comparison. In David van Dyk and Max Welling, editors,Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, volume 5 ofProceedings of Machine Learning Research, pages 488–495, Hilton C...
work page 2009
-
[33]
On graph kernels: Hardness results and efficient alternatives
Thomas Gärtner, Peter Flach, and Stefan Wrobel. On graph kernels: Hardness results and efficient alternatives. In Bernhard Schölkopf and Manfred K. Warmuth, editors,Learning Theory and Kernel Machines, pages 129–143, Berlin, Heidelberg, 2003. Springer Berlin Heidelberg. ISBN 978-3-540-45167-9
work page 2003
-
[34]
S.V .N. Vishwanathan, Nicol N. Schraudolph, Risi Kondor, and Karsten M. Borgwardt. Graph kernels.Journal of Machine Learning Research, 11(40):1201–1242, 2010. URL http: //jmlr.org/papers/v11/vishwanathan10a.html
work page 2010
- [35]
-
[36]
Generalized kernel two-sample tests.Biometrika, 111(3): 755–770, 11 2023
Hoseung Song and Hao Chen. Generalized kernel two-sample tests.Biometrika, 111(3): 755–770, 11 2023. ISSN 1464-3510. doi: 10.1093/biomet/asad068. URL https://doi. org/10.1093/biomet/asad068
-
[37]
igraphdata: A collection of network data sets for the ’igraph’ package, 2015
Gabor Csardi. igraphdata: A collection of network data sets for the ’igraph’ package, 2015. URL https://CRAN.R-project.org/package=igraphdata. R package version 1.0.1
work page 2015
-
[38]
Detecting change points in the large-scale structure of evolving networks
Leto Peel and Aaron Clauset. Detecting change points in the large-scale structure of evolving networks. InAAAI, 2014. URLhttps://arxiv.org/abs/1403.0989
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
Robert Marks. Enron timeline. https://www.bobm.net.au/teaching/BE/Enron/ timeline.html, Accessed: 2026-05-07
work page 2026
-
[40]
Daniele Zambon, Cesare Alippi, and Lorenzo Livi. Change-point methods on a sequence of graphs.IEEE Transactions on Signal Processing, 67(24):6327–6341, December 2019. ISSN 1941-0476. doi: 10.1109/tsp.2019.2953596. URL http://dx.doi.org/10.1109/TSP. 2019.2953596
-
[41]
Mmd aggregated two-sample test.Journal of Machine Learning Research, 24(194): 1–81, 2023
Antonin Schrab, Ilmun Kim, Mélisande Albert, Béatrice Laurent, Benjamin Guedj, and Arthur Gretton. Mmd aggregated two-sample test.Journal of Machine Learning Research, 24(194): 1–81, 2023. URLhttp://jmlr.org/papers/v24/21-1289.html
work page 2023
-
[42]
D. Siegmund and B. Yakir.The Statistics of Gene Mapping. Springer-Verlag, 2007. 12 A Illustrative example for comparing with other forms of kernel aggregation Most existing kernel-combination methods have been developed for two-sample or independence testing [24–26, 38]. To isolate the effect of the aggregation mechanism, we consider a fixed-split version...
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.